将 ChatGPT 用于数据科学项目的指南
推荐:使用 NSDT场景编辑器 快速搭建3D应用场景
我们都知道 ChatGPT 的受欢迎程度以及人们如何使用它来提高生产力。但是,如果您是新手,则值得注册ChatGPT免费演示并尝试它所能做的一切。您还应该参加我们的 ChatGPT 简介课程,学习制作有效提示的最佳实践,并探索利用这一强大 AI 工具的常见业务用例。
在本教程中,我们将学习如何使用 ChatGPT 来处理端到端的数据科学项目。我们将使用各种提示来创建项目大纲、编写 Python 代码、进行研究和调试应用程序。此外,我们将学习编写有效的 ChatGPT 提示的技巧。
使用 ChatGPT 进行端到端数据科学项目
在项目中,我们将使用来自DataCamp Workspace的贷款数据,并围绕它规划数据科学项目。
ChatGPT 在这里完成了 80% 的工作,我们只需要掌握快速工程就可以让一切正确,为此,我们有令人惊叹的 ChatGPT 数据科学备忘单。它带有60 + ChatGPT提示,用于基于SQL,R和Python的数据科学任务。
项目规划
这是项目中最重要的部分,我们在其中查看可用资源和目标以提出最佳策略。
您可以转到 chat.openai.com 并发起新的聊天。之后,我们将提及可用的贷款数据集,并要求 ChatGPT 提出构建端到端通用投资组合项目的步骤。
提示:“我有一个由 9500 行和 14 列组成的贷款数据集:['credit.policy', 'purpose', 'int.rate', 'installment', 'log.annual.inc', 'dti', 'fico', 'days.with.cr.line', 'revol.bal', 'revol.util', 'inq.last.6mths', 'delinq.2yrs', 'pub.rec', 'not.full.paid']。你能列出我必须遵循的步骤来为我的投资组合开发一个端到端的项目吗?
我们确实拿到了清单,但是忘了提阶级失衡问题和项目目标,就是准确预测“贷款不还”。
更新提示:“请包括阶级不平衡问题,并准确预测贷款是否会偿还,而不是贷款是否偿还。
同样,我们对模型监控不感兴趣,我们希望构建一个Gradio应用程序并将其部署在Huggingface Spaces上。
更新提示:“我们将使用 Gradio 创建一个 Web 应用程序并将其部署到 Spaces 上,我们不会在生产中监控模型。

作者动图 |项目中涉及的步骤的最终列表
我们得到了一个包含 9 个步骤的列表,如上所示,并详细说明了我们应该如何处理每个步骤。
以下是我们将在本教程中遵循的任务列表:
- 数据清理和预处理。处理缺失值、将分类变量转换为数值变量、缩放/规范化数据以及处理数据中的任何异常值或异常。此外,您需要通过对少数阶级(未全额支付的贷款)进行过度抽样或对多数阶级(全额支付的贷款)进行过抽样来解决阶级不平衡问题。
- 探索性数据分析 (EDA)。浏览数据集以深入了解数据,例如变量的分布、变量之间的相关性以及识别数据中的任何模式。
- 特征工程。创建新特征或转换现有特征以提高模型的预测能力。
- 型号选择。尝试多种模型,例如决策树、随机森林、逻辑回归或支持向量机 (SVM)。
- 模型训练和评估。根据数据训练所选模型,并使用各种指标(如准确性、精度、召回率和 F1 分数)评估其性能。
- 超参数优化。微调所选模型的超参数以提高其性能。
- 使用 Gradio 创建 Web 应用程序。选择最佳模型后,您可以使用 Gradio 创建 Web 应用程序。
- 在空间上部署 Web 应用程序。使用 Gradio 创建 Web 应用程序后,您可以将其部署到 Spaces 上。
- 测试 Web 应用。测试它以确保它按预期工作。
探索性数据分析 (EDA)
探索性数据分析是关于数据操作、统计分析和数据可视化的。我们可以通过编写有关编写 Python 代码以在我们的数据集上进行探索性数据分析的后续提示来完成它。
后续提示:“请编写一个 Python 代码来加载并执行贷款数据集的探索性数据分析 (EDA)”
机器人将理解上下文,并提出带有注释和详细说明其工作原理的 Python 代码。

作者动图 |用于 EDA 的 Python 代码
- 将数据集加载并显示为 Pandas 数据帧。

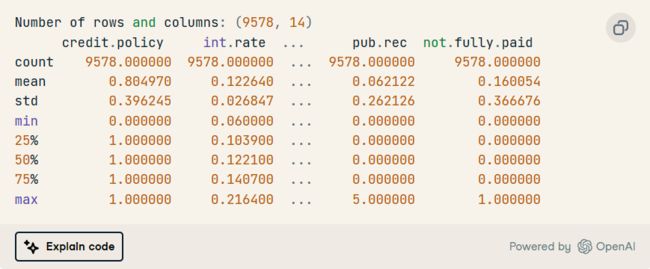
2. 显示数值变量的行数和列数以及统计摘要。
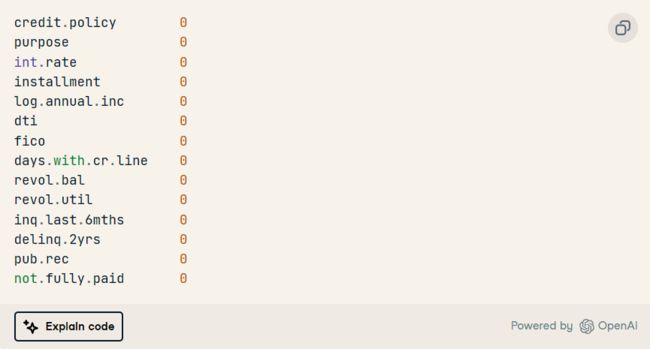
3. 在每列中显示缺失值。正如我们所看到的,我们没有。

4. 可视化目标变量“not.full.paid”的分布


5. 可视化变量之间的相关性。
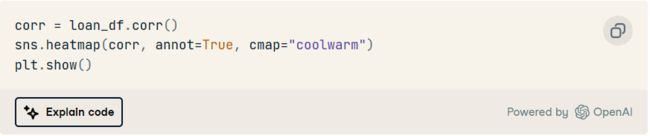

6. 了解贷款用途分布。


7. 了解按贷款用途划分的利率分布。
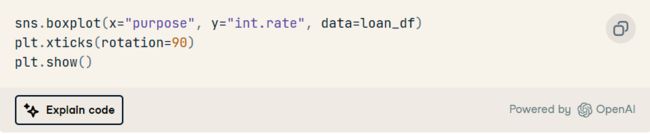

特征工程
我们将执行特征工程以简化预处理任务,而不是预处理和清理数据。
后续提示:“编写 Python 代码执行特征工程”
我们确实得到了正确的解决方案,但它包含不相关的代码,因此我们必须编写更新提示来修改代码。
更新提示:“仅添加特征工程部分。
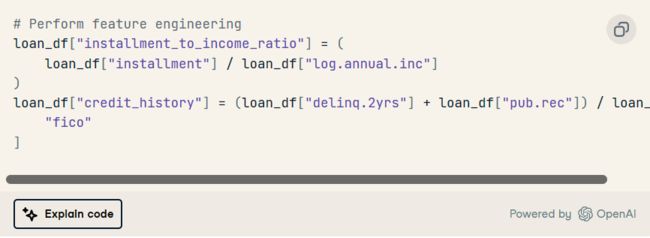
ChatGPT提出了两个新功能:“installment_to_income_ratio”和“credit_history”。
预处理和平衡数据
同样,ChatGPT知道项目的背景。我们不必再次解释一切。因此,我们将简单地要求它编写一个 Python 代码来清理和预处理数据。
后续提示:“现在编写一个python代码来清理和预处理数据集”
- 删除不必要的列并将分类变量转换为数字变量。
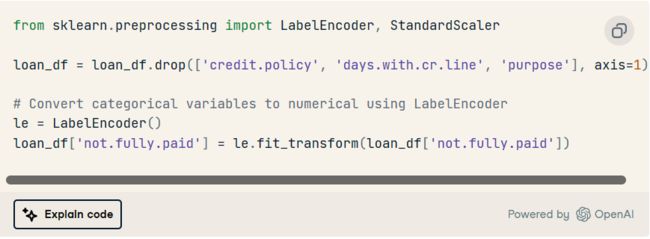
2. 使用标准缩放器缩放数值要素。
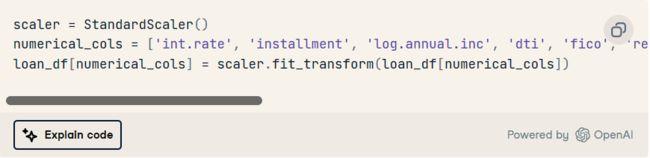
3. 使用 imblearn 的过采样方法处理类不平衡。
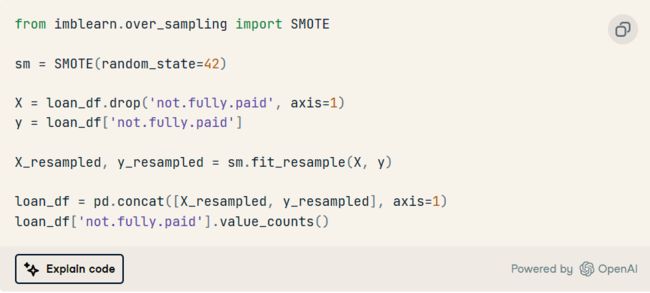
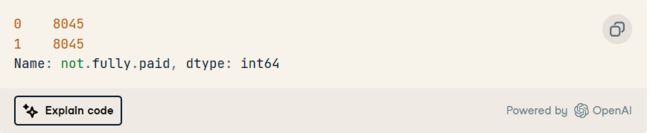
正如我们所看到的,我们已经成功地平衡了班级。
型号选择
在这一部分中,我们要求 ChatGPT 为模型选择任务训练各种模型的数据。
后续提示:“编写用于模型选择的后续 python 代码。尝试决策树、随机森林、逻辑回归或支持向量机 (SVM)。注意:仅包括模型选择部分。
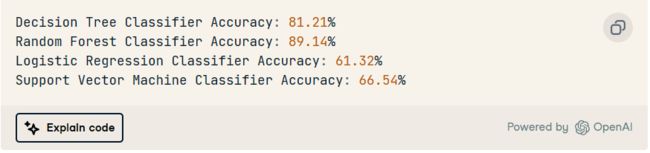
它生成了 Python 脚本,用于将数据集拆分为训练和测试,并在指定模型上训练数据集以显示准确性指标。
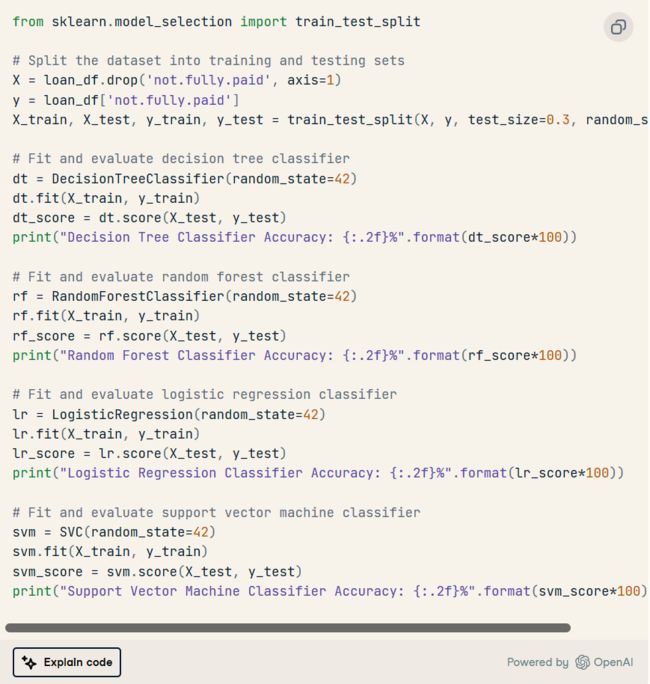
随机森林算法的性能明显优于其他模型。
超参数调优和模型评估
我们将选择性能更好的模型并进行模型评估。我们指定使用准确性、精度、召回率和 F1 分数作为指标和交叉验证,以确保模型的稳定性。
后续提示:“选择 RandomForestClassifier 并编写用于模型评估的 python 代码。使用准确性、精度、召回率和 F1 分数作为指标和交叉验证,以确保模型不会过度拟合训练数据。
我们将更新 Python 以添加超参数调优任务并保存性能最佳的模型。
更新提示:“在上面的代码中还包括超参数调优并保存性能最佳的模型”
代码的最终版本使用 GridSearchCV 进行具有五个交叉验证拆分的超参数优化,并使用 f1 指标进行评估以查找最佳超参数。
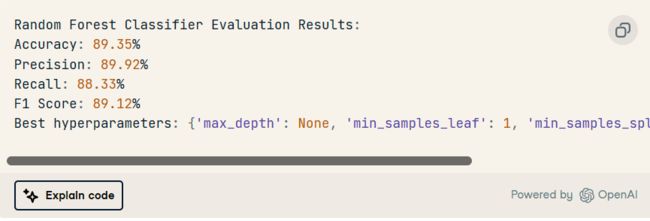
之后,ChatGPT 自动添加代码,在测试集上选择最佳模型进行模型评估,并显示性能最佳的超参数。

我们有一个稳定的模型,准确率为 89.35。精度和召回率相似。
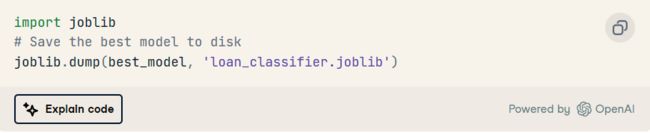
最后,我们将使用 joblib 保存模型。
可以在 DataCamp 工作区中找到包含输出的源代码。
使用 Gradio 创建 Web 应用程序
现在是最有趣的部分。我们将仅使用提示来创建完全可自定义的 Web 应用程序,该应用程序将接受数字输入并使用机器学习模型显示结果。
ChatGPT 已经知道上下文,所以我们需要让它为贷款数据分类器编写一个 Gradio Web 应用程序。
后续提示:“编写 Python 代码以创建用于贷款数据分类器的 Gradio Web 应用程序。我们不使用列['credit.policy', 'days.with.cr.line', 'purpose']。
要求 ChatGPT 只包含 Gradio 应用程序部分,而不是训练,然后包含推理脚本。
更新提示:“只需包含 gradio 应用程序部分。
我们得到的代码显示预测类概率,我们希望显示分类标签。
更新提示:“修改代码以显示分类而不是类概率。
运行代码后,我们看到了多个警告和错误。您可以通过向 ChatGPT 提及错误来改进它。
我们需要了解 ChatGPT 的局限性。它是在一个旧数据集上训练的,如果你希望它使用最新的API更新代码,你会碰壁。相反,我们必须阅读 Gradio 文档并手动更新代码。
失败提示:“使用 gradio.components 中的组件更新 Gradio 代码”
在 Gradio 应用程序中,我们正在加载保存的模型并从用户那里获取输入以显示模型预测。
通过阅读 Gradio 文档了解 Gradio 的工作原理。

您可以将上述代码保存在“app.py”文件中,并通过在终端中运行“python app.py”脚本在浏览器中启动应用程序。

作者动图 |贷款审批分类器应用
尽管我们的应用程序运行良好,但 ChatGPT 完全错过了我们缩放了数字特征。因此,您可以返回并保存标准标量参数,而不是要求更新代码。

之后,使用 joblib 在您的应用程序中加载标量。

那么,我们为什么要手动执行此操作?如果你要求 ChatGPT 修改一行,它可能会修改整个代码甚至变量名称。
是的,ChatGPT并不完美,它永远不会取代开发人员。
在空间上部署 Web 应用程序
您可以简单地要求ChatGPT教您在Hugging Face Spaces上部署gradio应用程序的简单方法,它将列出必要的步骤。
提示:“如何将 gradio 应用程序部署到拥抱面孔空间。
- 转到拥抱脸网站,然后单击左上角的个人资料图片以选择“新空间”选项。

图片来源:作者
- 添加名称和许可证类型以创建应用程序存储库。
- 单击“文件和版本”选项卡> + 添加文件>“上传文件”以在存储库中添加文件。
- 拖动 app.py、模型和缩放器文件,然后单击“将更改提交到主”按钮,然后使用提交消息保存提交。类似于 Git。

图片来源:作者
如果您遇到运行时错误,那是因为您忘记添加 requirements.txt 文件。选择“文件和版本”选项卡> + 添加文件>创建一个新文件,并添加文件名和 Python 库以及如下所示的版本。

图片来源:作者
你的应用已准备就绪。您可以使用滑块更改输入并预测客户是否应该获得贷款。
您可以在kingabzpro的拥抱面部空间上尝试现场演示。

编写有效聊天 GPT 提示的提示
在将其用于现实生活中的项目时,快速工程是棘手的。我们需要了解我们可以做什么或我们必须介入以纠正 ChatGPT 的规则。
以下是有关如何在不影响项目的情况下改善 ChatGPT 体验的一些提示。
- 始终写出清晰简洁的提示。确保在开始时详细解释您需要什么的所有内容。
- 创建项目的历史记录。ChatGPT 是一个聊天机器人,因此为了有效地理解上下文,您需要建立历史记录。
- 继续努力。没有标准的提示编写方式。您需要从基本提示开始,并通过编写后续更新提示来不断改进套装。
- 提及代码错误。如果在本地计算机上运行代码并引发错误,请尝试在后续提示中提及该错误。ChatGPT将立即从错误中吸取教训,并提出更好的解决方案。
- 手动进行更改。ChatGPT 是在旧数据上进行训练的,如果你期望它提出这个想法或新的 API 命令,你会失望的。尽可能尝试对代码进行手动更改,因为生成的代码并不完美。
- 将其用于常见任务。如果您要求常见任务,则使用 ChatGPT 成功的机会更大。
- 用它来学习新东西。始终要求 ChatGPT 解释新事物或“如何做”教程。它将为您提供完成工作的简单步骤列表。如果您有学习障碍,这将非常有帮助。
如果您对 ChatGPT 和 OpenAI API 感兴趣,请注册参加网络研讨会:OpenAI API 和 ChatGPT 入门。您将学习如何使用 OpenAI API 等执行语言和编码生成任务。
结论
开发贷款审批分类器是将 ChatGPT 用于数据科学项目的众多示例之一。我们可以使用它来生成合成数据、运行 SQL 查询、创建数据分析报告、进行机器学习研究等等。生成式人工智能将继续存在,它将使我们的生活更轻松。您无需在项目上花费数周和数月的时间,而是可以在数小时内开发、测试和部署数据科学应用程序。
在本教程中,我们学习了使用 ChatGPT 进行项目规划、数据分析、数据清理和预处理、模型选择、超参数优化以及创建和部署 Web 应用程序。
使用ChatGPT有一个问题。您需要具有统计分析和Python编码的经验,才能理解项目中的不同任务;没有它,你就是盲目行走。通过参加 Python 数据科学家职业轨迹开始您的数据科学之旅,并获得成功成为数据科学家所需的职业建设技能。
原文链接:将 ChatGPT 用于数据科学项目的指南 (mvrlink.com)