HBase高级特性、rowkey设计以及热点问题处理
参考文章 : HBase高级特性、rowkey设计以及热点问题处理
在阐述HBase高级特性和热点问题处理前,首先回顾一下HBase的特点:分布式、列存储、支持实时读写、存储的数据类型都是字节数组byte[],主要用来处理结构化和半结构化数据,底层数据存储基于hdfs。
同时,HBase和传统数据库一样提供了事务的概念,但是HBase的事务是行级事务,可以保证行级数据的原子性、一致性、隔离性以及持久性。
布隆过滤器在HBase中的应用
布隆过滤器(Bloom Filter)是空间利用效率很高的数据结构,利用位数组表示一个集合,判断一个元素是否属于该集合。但存在一定的错误率,在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合,所以适用于能容忍一定错误率的场景下。
布隆过滤器是HBase的高级功能属性,它能够降低特定访问模式下的查询时间,但是会增加内存和存储的负担,是一种以空间换时间的典型应用,默认为关闭状态。
可以单独为每个列族单独启用布隆过滤器,可以在建表时直接指定,也可以通过使用HColumnDescriptor.setBloomFilterType对某个列族指定布隆过滤器。
目前HBase支持以下3种布隆过滤器类型:
NONE:不使用布隆过滤器(默认)
ROW:行键使用布隆过滤器过滤
ROWCOL;列键(row key + column family + qualifier)使用布隆过滤器过滤
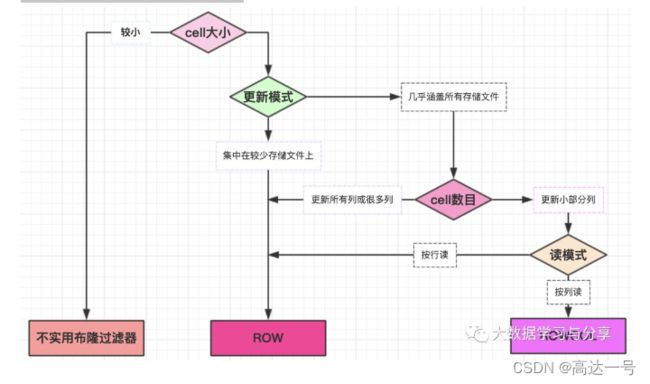
下图展示了何种情况下使用布隆过滤器,一般建议使用ROW模式,它在额外的存储空间开销和利用选择过滤存储文件提升性能方面做了很好的权衡,具体使用哪一种,要看具体的使用场景:
协处理器
HBase协处理器目前分为两种observer和endpoint,二者可以结合使用,都是运行在HBase服务端的。
1.observer
与RDBMS的触发器类似,运行客户端在操作HBase集群数据过程中,通过钩子函数在特定的事件(包括一些用户产生和服务期内部自动产生的事件)发生时做一些预处理(如插入之前做一些业务处理)和后处理(如插入之后做出响应等)的操作。
observer提供的几个典型的接口:
RegionObserver:处理数据修改事件。典型的应用场景就是用作处理HBase二级索引,如在put前在针对处理的数据生成二级索引,处理引擎可以通过MapReduce做,也可以将生成的二级索引存储在solr或者es中
MasterObserver:管理或DDL类型的操作,针对集群级的事件
WALObserver:提供针对WAL的钩子函数
2.endpoint
类似于RDBMS中的存储过程,可以通过添加一些远程过程调用来动态扩展RPC协议。允许扩展集群的能力,对客户端应用自定义开发新的运算命令,用户代码可以被部署到服务端
列族设计
一个列族在数据底层是一个文件,所以将经常一起查询的列放到一个列族中,同时尽可能创建较少数量的列族,且不要频繁修改,这样可以减少文件的IO、寻址时间,从而提高性能。
row key设计
HBase中rowkey可以唯一标识一行数据,在HBase查询的时候,主要以下两种方式:
get:指定rowkey获取唯一一条记录
scan:设置startRow和stopRow参数进行范围匹配
在设计row key时,首先要保证row key唯一,其次要考虑以下几个方面:
1.位置相关性
存储时,数据按照row key的字典顺序排序存储。设计row key时,要充分考虑排序存储这个特性,将经常一起读取的行存储放到一起。
2.row key长度
row key是一个二进制码流,可以是任意字符串,最大长度 64kb ,一般为10-100bytes,原因如下:
- 1)HBase数据的持久化文件hfile是按照Key Value存储的,如果row key过长,当存储的数量很大时,仅row key就会占据很大空间,会极大影响hfile存储效率
- 2)row key设计过长,memstore缓存到内存的数据就会相对减少,检索效率低
3.row key散列性
row key是按照字典顺序存储的,如果row key按照递增或者时间戳递增生成,那么数据可能集中存储在某几台甚至某一台region server上,导致某些region server的负载非常高,影响查询效率,严重了可能导致region server宕机。
因此,可以将row key的一部分由程序生成散列数字,将row key打散,均匀分布在HBase集群中的region server上,具体分为以下几种处理方式:
1)反转
通过反转固定长度或数字格式的row key,将row key中经常变化的部分(即相对比较随机的部分)放在前面,这种方式的弊端就是失去了rowkey的有序性。
最常用的就是,用户的订单数据存储在HBase中,利用手机号后4位通常是随机的的特性,以用户的手机号反转再根据业务场景加上一些其他数据拼成row key或者是仅仅使用反转后的手机号作为row key,从而避免以手机号固定开头导致的热点问题。
2)加盐
并非密码学中的加盐,而是通过在row key加随机数前缀,前缀种类数应和你想使数据分散到不同的region的数量保持一致。
3)哈希散列方式
利用一些哈希算法如MD5,生成哈希散列值作为row key的前缀,确保region所管理的start-end rowkeys范围尽可能随机。
HBase热点问题及处理
HBase中热点问题其实就是数据倾斜问题,由于数据的分配不均匀,如row key设计的不合理导致数据过多集中于某一个或某几个region server上,会导致这些region server的访问压力,造成性能下降甚至不能够提供对外服务。
还有就是,在默认一个region的情况下,如果写操作比较频繁,数据增长太快,region 分裂的次数会增多,比较消耗资源。
主要通过两种方式相结合,row key设计(具体参考上文)和预分区。
这里主要说一下预分区,一般两种方式:
1.建表时,指定分区方式。
如create 't1', 'f1', SPLITS => ['10', '20', '30', '40']
2.通过程序生成splitKeys,程序中建表时指定splitKeys
但这两种方式也并非一劳永逸,因为数据是不断地增长的,已经划分好的分区可能承载不了更多的数据,就需要进一步split,但随之带来的是性能损耗。所以我们还要规划好数据增长速率,定期观察维护数据,根据实际业务场景分析是否要进一步分区,或者极端情况下,可能要重建表做更大的预分区然后进行数据迁移。