多模态图像合成与编辑
由于信息在现实世界中以多种形式存在,多模态信息之间的有效交互和融合对于计算机视觉和深度学习研究中多模态数据的创建和感知起着关键作用。多模态图像合成与编辑由于具有强大的多模态信息交互建模能力,成为近年来的研究热点。多模态引导不是为网络训练提供明确的指导,而是为图像合成和编辑提供了直观、灵活的手段。另一方面,该领域也面临着多模态特征对齐等方面的挑战。这项survey综合了近年来多模态图像合成和编辑的进展,并根据数据模态和模型类型制定分类。首先介绍了图像合成和编辑的不同引导方式,然后根据其模型类型描述了多模态图像合成和编辑方法。然后,描述了基准数据集和评估指标以及相应的实验结果。最后,对当前的研究挑战和未来可能的研究方向提出了见解。
来自:Multimodal Image Synthesis and Editing: The Generative AI Era
项目:https://github.com/fnzhan/Generative-AI
目录
- 概述
- 模态基础
-
- 视觉引导
- 文本引导
- 音频引导
- 其他模态引导
- 方法
-
- GAN-based
-
- 条件GANs
- 无条件GAN的逆映射
- Diffusion-based
-
- 条件扩散模型
- 预训练扩散模型
- 自回归模型
-
- Vector Quantization
- 自回归建模
- NeRF-based
-
- Per-scene NeRF
- GAN-based NeRF
概述
人自然地能够根据一段视觉、文本或音频描述对场景进行成像。然而,由于固有的模态差距,深度神经网络的直观过程不太直接。这种视觉感知的模态差距可以归结为视觉线索与真实图像之间的模态内差距,以及非视觉线索与真实图像之间的跨模态差距。目标是模仿人类在现实世界中的想象力和创造力,多模态图像合成和编辑(MISE,Multimodal Image Synthesis and Editing)的任务提供了关于深度神经网络如何将多模态信息与图像属性关联起来的见解。
图像合成和编辑的目标是创造逼真的图像或编辑具有自然纹理的真实图像,这是一个趋势领域。在过去的几年里,由于生成式人工智能的进步,特别是深度生成模型和神经渲染取得了令人印象深刻的进步。为了实现可控的生成,一个热门的研究方向是在一定的引导下生成和编辑图像,如图1所示。通常,分割图(segmentation maps)、素描图(sketch maps)等视觉线索被广泛用于指导图像合成和编辑。除了视觉线索的模态内引导之外,文本text、音频audios和场景图scene graph等跨模态引导提供了一种更直观、更灵活的表达视觉方式。然而,在多模态图像合成和编辑中,如何有效地检索和融合不同模态数据中的异构信息是一个重大挑战。

- 图1:典型的引导类型包括视觉信息,如分割图、场景布局、草图、文本提示、音频信号、场景图、大脑信号和鼠标轨迹。
作为多模态图像合成的先驱,(从标题生成图像)表明循环变分自编码器可以根据图像标题生成新的视觉场景。随着生成对抗网络和扩散模型的蓬勃发展,多模态图像合成的研究得到了显著推进。从Conditional GANs发展而来的一系列GAN和扩散模型,通过加入多模态引导来调节生成,从各种多模态信号合成图像。这种条件生成范式相对简单,在SOTA方法中被广泛采用。另一方面,建立条件模型需要一个繁琐的训练过程,通常涉及较高的计算成本。因此,另一个研究方向是对MISE模型进行预训练,再通过对潜在空间进行操作来实现,方法包括反演,将引导函数应用于扩散过程,或者对扩散模型的潜在空间进行调整。
目前,GAN和扩散模型仍然广泛采用CNN架构,这阻碍了它们统一支持多模态输入。另一方面,随着Transformer的流行,它自然地允许各种多模态输入,在不同模态数据的生成方面取得了令人印象深刻的改进,例如语言、图像和音频。多模态引导和图像都可以用离散token的共同形式表示。例如,文本可以用token序列自然地表示,包括图像在内的视听引导也可以表示为token序列。有了这种统一的离散表示,多模态引导和图像之间的相关性可以通过基于transformer的自回归模型进行拟合。
大多数上述方法适用于2D图像,而没有考虑现实世界的3D场景。随着近年来神经渲染尤其是神经辐射场(neural Radiance Fields,NeRF)的发展,3D图像的合成与编辑越来越受到业界的关注。与2D图像的合成和编辑不同,3D MISE在合成和编辑过程中受到多视图数据和多视图一致性要求,因此面临更大的挑战。作为临时措施,可以使用预训练的2D基础模型(例如CLIP和Stable Diffusion)来驱动NeRF优化以进行视图合成和编辑。此外,GAN和扩散模型等生成模型可以与NeRF相结合,在2D图像上训练3D感知生成模型,其中可以通过开发Conditional NeRF或Inverting NeRF来执行MISE。
模态基础
每个信息源都可以称为一种模态。例如,人有触觉、听觉、视觉和嗅觉,信息的媒介包括语音、视频、文字等。在图像合成和编辑方面,将模态引导分为视觉引导、文本引导、音频引导和其他模态引导。
视觉引导
视觉引导由于其固有的空间和信息传递能力,在MISE领域引起了广泛关注,值得注意的是,它将特定的图像属性封装在像素空间中。视觉引导的这一特性促进了图像合成过程中的交互式操作和精确处理,这对于实现预期结果至关重要。作为像素级的引导,它可以无缝地集成到图像生成过程中。常见的视觉引导类型包括分割图segmentation maps,关键点keypoints,素描sketch,边缘edge,涂鸦scribbles,场景布局scene layouts,如图1所示。此外,也有研究探讨了深度图dep填好map、法线图normal mao、迹线图trace map等条件下的图像合成。视觉引导可以通过使用预训练的模型(例如,分割模型,深度预测器depth predictor,姿态预测器pose predictor),应用算法(例如,Canny edges,Hough lines)或依靠人工(例如,手动注释,人工涂鸦)来获得。通过修改视觉引导元素,如分割图,我们可以直接将图像合成技术用于各种图像编辑任务,其展示了视觉引导在MISE领域的通用性。
视觉引导编码:视觉线索在二维像素空间中表示,可以解释为特定类型的图像,从而允许通过许多图像编码策略,如CNN和Transformer直接编码。由于编码后的特征在空间上与图像特征对齐,可以通过朴素拼接、SPADE、交叉注意机制等方式平滑地整合到网络中。
文本引导
与视觉引导相比,文本引导提供了一种更通用、更灵活的方式来表达和描述视觉概念。这是因为文本可以捕捉到广泛的思想和细节,而这些思想和细节可能不容易通过其他方式传达。文本描述可能是模棱两可的,并且可以进行多种解释。这既是挑战,也是机遇。因为可能会存在大量准确代表文本的图像,另一方面又使预测结果变得更加困难。文本-图像合成任务(text-to-image synthesis task)旨在生成清晰、逼真的图像,并与相应的文本引导具有高度的语义相关性。值得注意的是,文本和图像是不同类型的数据,我们很难从一种数据学习到另一种数据的准确和可靠的映射。整合文本引导的技术,如表征学习,在文本引导图像合成和编辑中起着至关重要的作用。
文本引导编码:从文本描述中学习表示是一项非常重要的任务。有许多传统的文本表示,如Word2Vec和Bag-of-Words。随着深度神经网络的普及,RNN和LSTM被广泛采用对文本进行编码。随着预训练模型在自然语言处理领域的发展,一些研究也在探索利用BERT等大规模预训练语言模型进行文本编码。值得注意的是,对比语言-图像预训练(Contrast Language-Image Pre-training,CLIP)利用大量的图像-文本对进行训练,通过学习图像的和相应标题的对齐来产生文本嵌入,并已被广泛用于文本编码。
音频引导
与文本和视觉引导不同,音频引导提供了可用于生成动态或顺序视觉内容的时间信息。与文本或视觉引导相比,音频信号与图像之间的关系往往更抽象。例如,与特定动作或环境相关的音频可能暗示但不明确定义视觉内容(声音可以带有情感基调和微妙的背景,而这些在文本或视觉输入中并不能体现)。因此,音频引导的MISE提供了一个有趣的挑战,将音频信号解释为视觉内容。这涉及到理解和建模声音和视觉元素之间的复杂相关性,这已经在talking-face generation中进行了探索,其目标是在给定音频输入的情况下创建真实的面部说话动画。
音频引导编码:通过对给定视频用CNN提取视频截图的特征,再通过LSTM生成音频序列的特征。此外,输入音频片段也可以由一系列其他特征表示,这些特征可以是谱图(spectrograms)、fBanks、Mel-Frequency Cepstral系数(MFCCs)和预训练SoundNet模型的隐藏层输出。在talking-face generation中,Action Units也被广泛采用,将驱动音频转换为连贯的视觉信号,用于talking-face生成。
其他模态引导
场景图:场景图将场景表示为有向图,其中节点是对象,边表示对象之间的关系。以场景图为条件的图像生成允许对明确的对象关系进行推理,并合成具有复杂场景关系的图像。引导的场景图可以通过GNN进行编码,该网络预测对象边界框以产生场景布局。例如,Vo等人提出预测对象之间的关系单元,并将其转换为视觉布局(visual layout)。
脑信号:将大脑信号作为一种合成或重建视觉图像的方式,为理解大脑活动和促进脑机接口提供了一种令人兴奋的方式。近年来,一些研究探索了如何利用功能磁共振成像(fMRI,functional magnetic resonance imaging)生成图像。例如,Fang等人解码来自视觉皮层的形状和语义表示,然后通过GAN融合它们以生成图像;Lin等人提出将fMRI信号映射到预训练StyleGAN的潜在空间中,实现条件生成;Takagi和Nishimoto(High-resolution image reconstruction with latent diffusion models from human brain activity)通过将每个成分映射到不同的大脑区域,定量地解释预训练LDM(High-resolution image synthesis with latent diffusion models,Stable Diffusion)中的每个成分。
鼠标轨迹:为了实现对图像内容的精确和灵活的操作,鼠标轨迹最近在MISE中成为一种流行的引导。具体来说,用户只需点击鼠标就可以在图像中选择一组“handle points”和“target points”。这里旨在通过将这些handle points转向各自的target points来编辑图像。这种创新的鼠标轨迹引导方法使图像能够以令人印象深刻的精度进行变形,并促进对各种属性(如姿态、形状和一系列类别的表情)的操作。点运动可以通过基于光流或生成器特征上移位的patch loss的预训练Transformer集成来监督编辑。
方法
我们将MISE的方法大致分为五类:基于GAN的方法、自回归方法、基于扩散的方法、基于NeRF的方法和其他方法。下面简要总结了四种主要方法的优缺点,代表性文献如表1所示。在这里,首先讨论基于GAN的方法,这些方法通常依赖于GAN及其inversion。然后综合讨论了目前流行的基于扩散的方法和自回归方法。然后介绍用于3D MISE的NeRF,随后提出了几种在多模态导引下的图像合成和编辑方法。最后比较和讨论了不同生成体系结构的优缺点。
GAN 逆映射(inversion)把给定图像映射到预训练 GAN 模型的 latent space,以便生成器可以从 latent space 重建图像。 作为一种连接真假图像域的新兴技术,GAN Inversion 在使用预训练 GAN 模型(例如 StyleGAN 和 BigGAN)进行真实图像编辑方面,发挥着至关重要的作用。

- 表1:不同模型类型对于MISE任务的优缺点。
GAN-based
基于GAN的方法已经被广泛应用于各种MISE任务,无论是conditional GANs,或pre-trained unconditional GANs。对于conditional GANs,可以直接在生成器中加入多模态条件来指导生成过程。对于预训练的无条件GAN,GAN Inversion通常通过在潜在空间中操作隐编码来执行各种MISE任务。
条件GANs
条件生成对抗网络(Conditional Generative Adversarial Networks,CGANs)是流行的GAN架构的扩展,它允许生成具有特定特征或属性的图像。CGANs的关键思想是将生成过程置于附加信息的条件下,例如MISE任务中的多模态引导。这是通过向生成器和鉴别器网络提供额外的信息作为额外的引导来实现的。然后生成器学习生成样本,不仅欺骗鉴别器,而且匹配指定的条件信息。近年来,一系列设计显著提高了CGANs在MISE中的性能。
条件合并 Condition Incorporation:为了引导生成过程,有必要将多模态条件有效地纳入网络,如图2所示。通常,多模态引导可以统一编码为一维特征,一维特征可以与网络中的特征相连接。对于与目标图像在空间上对齐的视觉引导,可以将条件直接编码为二维特征,为生成或编辑提供精确的空间引导。然而,当存在非常不同的视角或严重变形时,编码的2D特征很难捕捉到引导图像和真实图像之间复杂的场景结构关系。在这种情况下,可以使用注意力对齐引导图像和目标图像。此外,单纯地用深度网络编码视觉引导是次优的,因为部分引导信息容易在归一化层中丢失。因此,引入空间自适应反归一化(spatial -adaptive de-normalization,SPADE)可以有效加入引导特征。
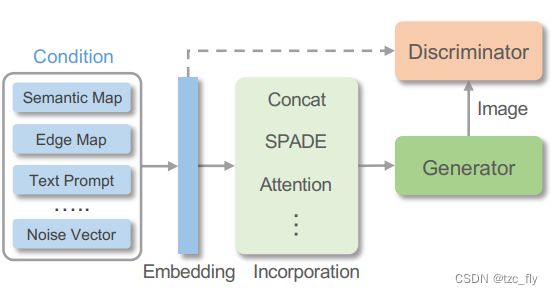
- 图2:条件GANs的条件合并机制。
补充内容:关于SPADE

- 在"Batch Normalization"中,计算所有样本在两个空间维度上每个单独通道的均值和方差。

- 在"Instance Normalization"中,计算两个空间维度上每个单独样本的每个单独通道的均值和方差。

- 在"Layer Normalization"中,计算所有通道和两个空间维度上每个单独样本的均值和方差。
来自:https://becominghuman.ai/all-about-normalization-6ea79e70894b
上面的归一化为无约束的归一化,因为不需要额外的数据。SPADE为有约束的归一化,比如需要视觉引导中的分割图。
参考图像分类中的BatchNormalization,每当网络使用到一层BatchNormalization时,会需要学习两个参数 γ , β \gamma ,\beta γ,β,这两个参数是两个向量(每个向量有channle个元素),因为对特征图归一化后,再进行适当的特征缩放与平移,张量的值会变得有利于网络的计算。

- 其中,normalization即为经过归一化后的张量,在SPADE中, γ , β \gamma,\beta γ,β是通过分割图编码得到的。
模型结构:对于GAN来说,条件生成高分辨率图像具有挑战性,并且计算成本很高。从粗到细的结构通过将生成的图像或特征从低分辨率逐步细化到高分辨率,有助于解决这些问题。通过先生成粗糙的图像或特征,然后对其进行细化,生成器网络可以专注于捕获图像的整体结构,然后再转向精细的细节,从而提高训练效率和生成质量。不仅是生成器,许多判别器网络也在多个分辨率水平下运行,以有效区分高分辨率图像并避免潜在的过拟合。
另一方面,由于场景可以用不同的语言表达来描述,因此无论表示方式如何,生成具有一致语义的图像都是一个重大挑战。多篇研究采用双生成分支的连体结构,方便语义对齐。在两个分支的条件下,可以采用对比损失来最小化正对(两个文本提示描述同一场景)之间的距离,最大化负对(两个文本提示描述不同场景)之间的距离。
损失设计:除了GAN中固有的对抗损失外,人们还探索了各种其他损失项来实现高保真条件生成。对于在空间上与ground-truth图像对齐的条件输入,已经证明感知损失perceptual loss能够通过最小化生成图像与ground-truth之间的感知特征距离来显著提高生成质量。此外,与前面描述的循环结构相关,循环一致性损失cycle-consistency loss被适当地施加以强制条件一致性。然而,循环一致性损失对条件生成的限制太大,因为它假设两个域之间存在双向关系。因此,一些研究致力于探索单向翻译,绕过循环一致性的约束。随着对比学习的出现,一些研究探索通过噪声对比估计最大化正对的互信息,以在视觉引导或文本到图像生成的非配对图像生成中保留内容。除了对比损失外,三元组损失也被用于提高文本等跨模态引导的条件一致性。
无条件GAN的逆映射
大规模GANs在高分辨率、高保真的无条件图像合成方面取得了显著进展。通过预训练的GANs,一系列研究探索将给定图像反演回GAN的潜在空间,这被称为GAN逆映射(inversion)。具体来说,预训练的GAN学习从潜在空间到真实图像的映射,而GAN的反演将图像映射回潜在空间,这是通过将隐编码输入预训练的GAN中,通过优化重建图像来实现的。通常,重建指标是基于 l 1 , l 2 l_{1},l_{2} l1,l2,即感知损失或LPIPS(The Unreasonable Effectiveness of Deep Features as a Perceptual Metric)。利用得到的隐编码,我们可以重建原始图像,并在隐空间中进行逼真的图像处理。就MISE而言,跨模态图像处理可以通过根据其他模态的指导操作或生成隐编码来实现。
显示跨模态对齐:利用其他模态引导的一个方向是将图像和跨模态输入(如语义图、文本)的嵌入映射到一个共同的嵌入空间,如图3a所示。例如,TediGAN为每个模态训练一个编码器来提取嵌入,并应用相似度损失将它们映射到潜在空间。然后,可以进行潜操作(如潜混合),将图像隐编码编辑为其他模态的嵌入,实现跨模态的图像操作。然而,由于不同模态之间的异质性,将多模态数据映射到公共空间是不容易的,这可能导致劣质的图像生成。
隐式跨模态监督:另一项研究旨在通过定义生成结果之间的一致性损失来指导合成或编辑,而不是将引导模态明确地映射到潜在空间中。例如,Jiang等人提出通过预训练的细粒度属性预测器来优化图像潜在编码,该预测器可以检查编辑后的图像与文本描述的一致性。然而,属性预测器是专门为带有细粒度属性注释的人脸编辑而设计的,因此很难推广到其他场景。最近发布的一种大规模预训练模型,对比语言图像预训练(contrast Language-Image Pre-training,CLIP)在多模态合成和操作中显示出巨大的潜力,它通过对比学习从超过400M的文本-图像对中学习联合视觉语言表征。
在强大的预训练CLIP的基础上,Bau等人定义了一个基于CLIP的语义一致性损失,以优化绘制区域内的潜在编码,使恢复的内容与给定文本对齐。类似地,StyleClip和StyleMC使用CLIP表示之间的余弦相似性来监督文本引导操作,如图3b所示。标准CLIP损失的一个已知问题是,模型倾向于通过向图像添加无意义的像素级扰动来欺骗CLIP分类器。为此,Liu等人提出AugCLIP评分对标准CLIP评分进行鲁棒化;StyleGAN-NADA提出了一种方向性CLIP loss,用于对齐源文本-图像对和目标文本-图像对之间的CLIP空间方向。它还直接使用文本条件对预训练的生成模型进行微调,以进行域适应。此外,Yu等人引入了基于CLIP的对比度损失,用于鲁棒优化和反事实图像处理。
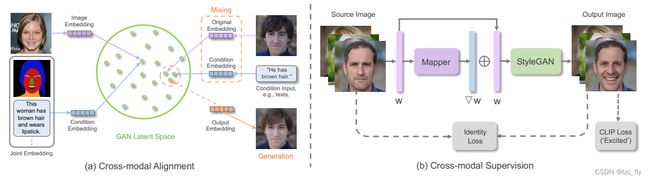
- 图3:用于MISE的GAN反演架构包括 a跨模态对齐 和 b跨模态监督。
- 跨模态对齐将图像和条件嵌入到GAN的潜在空间中(例如StyleGAN),旨在将它们的嵌入拉得更近。然后,可以混合图像和条件嵌入以执行多模态图像生成或编辑。
- 跨模态监督将源图像反转为隐编码,并训练Mapper网络产生残差,残差被添加到隐编码中以产生目标编码,从目标编码中,预训练的StyleGAN生成由CLIP和identity loss评估的图像。CLIP用于从图像生成文本,在输出层面看CLIP生成文本和提示文本的距离,identity loss用于判断两个face是不是同一个人。
Diffusion-based
近年来,诸如去噪扩散概率模型denoising diffusion probistic models,即DDPMs等扩散模型在生成图像方面取得了巨大的成功。DDPMs是一种由正向扩散过程和反向扩散过程组成的隐变量模型。前向过程是一个马尔可夫链,在 t = 1 , . . . , T t=1,...,T t=1,...,T时,对隐变量 x t x_{t} xt进行顺序采样,加入噪声。前向过程中的每一步都是高斯转换 q ( x t ∣ x t − 1 ) = N ( 1 − β t x t − 1 , β t I ) q(x_{t}|x_{t-1})=N(\sqrt{1-\beta_{t}}x_{t-1},\beta_{t}I) q(xt∣xt−1)=N(1−βtxt−1,βtI),其中 { β t } t = 0 T \left\{\beta_{t}\right\}_{t=0}^{T} {βt}t=0T为固定的或者可学习的方差schedule。反向过程 q ( x t − 1 ∣ x t ) q(x_{t-1}|x_{t}) q(xt−1∣xt)由另一个高斯转换参数化 p ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ ( x t ) , σ t 2 I ) p(x_{t-1}|x_{t})=N(x_{t-1};\mu(x_{t}),\sigma_{t}^{2}I) p(xt−1∣xt)=N(xt−1;μ(xt),σt2I)。 μ ( x t ) \mu(x_t) μ(xt)可以分解为 x t x_t xt和噪声近似模型 ϵ θ ( x t , t ) ϵ_θ(x_t, t) ϵθ(xt,t)的线性组合,可以通过优化学习。在训练了 ϵ ( x , t ) ϵ(x, t) ϵ(x,t)之后,DDPMs的采样过程可以通过反向扩散过程来实现。
与变分自编码器、流模型、自回归模型和GANs相比,最新的研究(Diffusion models beat gans on image synthesis)证明了更高质量的图像合成性能。为了在提供的引导下实现图像的生成和编辑,文献中广泛研究了利用预训练模型(利用引导函数)和从头开始训练条件模型。引导函数法的缺点是需要额外的引导模型,导致训练管道复杂。
条件扩散模型
为了运行MISE任务,可以通过将条件信息直接集成到去噪过程中来制定条件扩散模型。近年来,一系列的设计使得条件扩散模型的性能得到了显著的提高。
条件合并:作为一种通用框架,通常采用条件特定编码器将多模态条件投影到嵌入向量中,并进一步合并到模型中,如图4所示。特定条件的编码器可以与模型一起学习,也可以直接从预训练的模型中借用。通常,CLIP 是 DALL-E 2 中采用的文本嵌入的常用选择。此外,通用的大型语言模型(如T5)预训练的文本语料库在编码用于图像合成的文本方面也显示出显著的有效性,Imagen验证了这一点。通过条件嵌入,可以采用多种机制将其纳入扩散模型。具体来说,可以将条件嵌入直接地连接或添加到扩散时间步嵌入中。在LDM(Stable Diffusion)中,条件嵌入通过交叉注意机制映射到扩散模型的中间层。为了充分利用条件信息进行语义图像合成,Wang等人提出通过空间自适应归一化加入视觉引导,从而提高生成图像的质量和语义一致性。ControlNet的目标不是从零开始加入条件来训练扩散模型,而是将条件加入到预训练的扩散模型中以实现可控生成。为了保持预训练模型实现快速收敛,设计了一个"零卷积"来结合引导,其中卷积权值从零逐渐学习到优化参数。
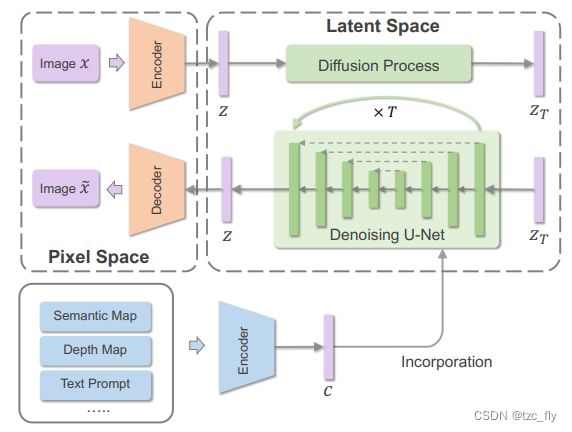
- 图4:条件扩散模型的总体框架。有了一定的潜在表征模型,扩散过程通过反转在指定引导(如分割图、深度图和文本)条件下的正向扩散过程来建模潜在空间。
潜在空间扩散:为了使扩散模型能够在有限的计算资源上进行训练,同时保持其质量和灵活性,一些研究探索在学习的潜在空间中进行扩散过程,如图4所示。通常,可以使用自编码模型来学习在感知上等同于图像空间的潜在空间。另一方面,学习到的潜在空间可能伴随着不希望的高方差,这突出了对潜在空间正则化的需求。作为一种常见的选择,KL散度可以用于将潜在空间正则化到标准正态分布。此外,VQGAN可以直接学习离散潜空间,该潜空间可以通过VQ-Diffusion中的离散扩散过程建模。
模型架构:Ho等人引入了扩散模型的U-Net架构,该架构可以将CNN的归纳偏置纳入扩散过程。尽管U-Net结构在SOTA扩散模型中被广泛采用,但Chahal表明,基于Transformer的LDM可以产生与基于U-Net的LDM相当的性能,并伴随着通过多头注意力自然合并的多模态条件。另一方面,与直接生成最终图像不同,DALL-E 2提出了一种两阶段结构,即从CLIP潜在空间中的文本生成中间图像嵌入。然后,应用图像嵌入来调节扩散模型以生成最终图像,从而提高生成图像的多样性。此外,还探索了其他一些架构,包括通过组成一组扩散模型来生成图像的组合架构、由多个具有共享参数或约束的扩散过程组成的多扩散架构、基于检索的扩散模型等。
预训练扩散模型
另一种研究方法不是昂贵地重新训练扩散模型,而是在适当的监督下指导去噪过程,或者以较低的成本对模型进行微调,如图5所示。
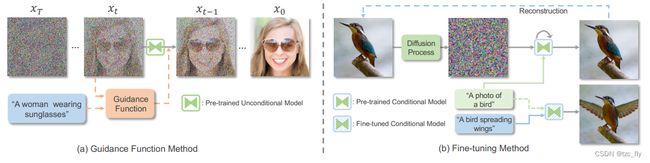
- 图5:典型框架的预训练扩散模型的MISE任务,包括引导函数方法和微调方法。
引导函数方法:作为早期的探索,Dhariwal等人使用分类器引导来增强预训练的扩散模型,该模型可以扩展到使用各种引导来实现条件生成。特别的,结合引导的反向过程 p ( x t − 1 ∣ x t ) p(x_{t-1}|x_{t}) p(xt−1∣xt)可以写为 p ( x t − 1 ∣ x t , y ) p(x_{t-1}|x_{t},y) p(xt−1∣xt,y),其中 y y y为提供的引导,最终的扩散采样过程可重写为: x t − 1 = μ ( x t ) + σ t 2 ∇ x t l o g p ( y ∣ x t ) + σ t ϵ , ϵ ∼ N ( 0 , I ) x_{t-1}=\mu(x_{t})+\sigma_{t}^{2}\nabla_{x_{t}}log\thinspace p(y|x_{t})+\sigma_{t}\epsilon,\thinspace\thinspace\epsilon\sim N(0,I) xt−1=μ(xt)+σt2∇xtlogp(y∣xt)+σtϵ,ϵ∼N(0,I)其中, l o g p ( y ∣ x t ) log\thinspace p(y|x_{t}) logp(y∣xt)被称为引导函数,表示 x t x_t xt与引导 y y y之间的一致性,可以用余弦相似度和L2距离等相似度度量来表示。由于相似度通常是在特征空间上计算的,因此可以采用预训练的CLIP作为图像编码器和文本引导的条件编码器,如图5a所示。然而,图像编码器将噪声图像作为输入,而CLIP在干净图像上进行训练。因此,可以执行CLIP的自监督微调,以强制从干净图像和带噪图像中提取的特征之间对齐(More control for free! image synthesis with semantic diffusion guidance)。
为了控制生成与引导的一致性,可以引入一个参数 γ γ γ来缩放引导梯度,如下所示: x t − 1 = μ ( x t ) + σ t 2 γ ∇ x t l o g p ( y ∣ x t ) + σ t ϵ , ϵ ∼ N ( 0 , I ) x_{t-1}=\mu(x_{t})+\sigma_{t}^{2}\gamma\nabla_{x_{t}}log\thinspace p(y|x_{t})+\sigma_{t}\epsilon,\thinspace\thinspace\epsilon\sim N(0,I) xt−1=μ(xt)+σt2γ∇xtlogp(y∣xt)+σtϵ,ϵ∼N(0,I)显然,该模型将更加关注梯度尺度较大的引导。
微调方法:在微调方面,MISE可以通过修改潜在编码或调整预训练的扩散模型来实现,如图5b所示。为了使无条件预训练的模型适应文本引导的编辑,首先通过前向扩散过程将输入图像转换为隐空间。然后对反向路径上的扩散模型进行微调,以生成由目标文本和CLIP损失驱动的图像。对于预训练条件模型(通常以文本为条件),类似于GAN逆映射,文本潜在嵌入或扩散模型可以微调以重建少量图像。然后将得到的文本嵌入或微调模型应用于在新的上下文中生成相同的对象。然而,这些方法通常会极大地改变原始图像的布局。由于观察图像空间布局与每个单词之间关系的关键在于交叉注意层,因此Prompt-to-Prompt提出通过操纵交叉注意图来保留原始图像中的部分内容。
自回归模型
在GPT于自然语言建模进步的推动下,自回归模型已经成功地应用于图像生成,将扁平的图像序列视为离散的token。生成图像的可信性表明,自回归模型能够适应像素和高级属性之间的空间关系。与CNN相比,Transformer模型自然地统一支持多模态输入,并且已经提出了一系列研究来探索基于Transformer的自回归模型的多模态图像合成。总体而言,MISE的自回归模型管道包括矢量量化阶段,以产生统一的离散表示并实现数据压缩,以及自回归建模阶段,该阶段以光栅扫描顺序建立离散token之间的依赖关系,如图6所示。
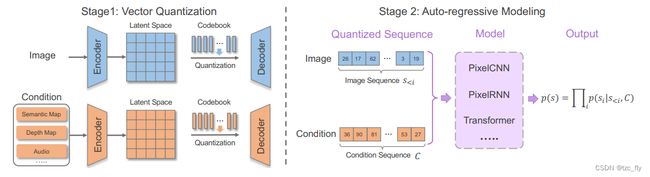
- 图6:MISE任务的典型自回归方法框架。首先进行量化阶段,通过VQ-GAN重建原始图像或条件(如语义映射)来学习离散和压缩表示,然后进行自回归建模阶段,以捕获离散序列的依赖性。
Vector Quantization
直接将所有图像像素作为序列使用Transformer进行自回归建模在内存消耗方面是昂贵的,因为Transformer中的自注意力机制会产生二次方的内存成本。因此,图像的压缩和离散表示对于自回归图像合成和编辑至关重要。有研究采用k-means方法对RGB像素值进行聚类,以降低输入维数。然而,k-means聚类只是在序列长度不变的情况下降低了维数。因此,由于序列长度的代价呈二次增长,自回归模型仍然难以处理高分辨率输入。为此,采用矢量量化VAE(Vector Quantised VAE,VQVAE)学习离散和压缩图像表示。VQ-VAE由一个编码器、一个特征量化器和一个解码器组成。图像被送入编码器学习连续表示,通过特征量化器将特征分配给最近的codebook entry进行量化。然后,解码器从量化特征重构原始图像,以学习离散图像表示。由于分配的codebook entry不可微,通常采用重参数化技巧来近似梯度。
损失函数:为了获得重建图像的质量,可以将对抗损失和感知损失结合起来进行图像重建。通过额外的对抗损失和感知损失,与原始像素损失相比,图像质量得到了明显改善。此外,为了强调某些区域的重建质量,可以在某些预训练模型的激活上使用特征匹配损失,例如人脸嵌入网络,可以提高人脸区域的重建质量。
网络架构:卷积神经网络是VQ-VAE中学习离散图像表示的常用结构。最近,Yu等人用ViT取代了基于卷积的结构。随着扩散模型的出现,基于扩散模型的解码器也被探索用于学习具有优异重建质量的离散图像表示。另一方面,多尺度量化结构被证明可以通过同时包含低水平像素和高水平token或分层潜在编码来提高生成性能。
自回归建模
自回归建模是一种适应序列依赖的代表性范例,遵循概率链式规则。序列中每个token的概率取决于所有先前的预测,从而产生作为条件分布乘积的序列的联合分布: p ( x ) = ∏ t = 1 n p ( x t ∣ x 1 , x 2 , . . . , x t − 1 ) = ∏ t = 1 n p ( x t ∣ x < t ) p(x)=\prod_{t=1}^{n}p(x_t|x_1,x_2,...,x_{t-1})=\prod_{t=1}^{n}p(x_{t}|x_{
NeRF-based
神经辐射场(neural Radiance fields,NeRF)通过参数化3D场景的颜色和密度,在新视图合成方面取得了令人印象深刻的性能。具体而言,NeRF采用全连接神经网络,将空间位置 ( x , y , z ) (x, y, z) (x,y,z)与相应的观看方向 ( θ , ϕ ) (θ, ϕ) (θ,ϕ)作为输入,体积密度与相应的发射亮度作为输出。为了从隐式3D表示中渲染2D图像,使用数值积分器进行可微体渲染,以近似难以处理的体积投影积分。
Per-scene NeRF
与原始的NeRF模型一致,per-scene NeRF旨在优化和表示由图像或某些预训练模型监督的单个场景。
图像监督:通过配对引导和相应的视图图像,NeRF可以在引导条件下进行训练,以实现MISE。例如,AD-NeRF通过在具有一个目标人音轨的视频序列上训练神经辐射场来实现高保真的talking-head合成。AD-NeRF直接将音频特征馈送到隐式函数中以产生动态NeRF,该动态NeRF通过体渲染进一步用于合成伴随音频的高保真talking-face视频。然而,匹配的条件图像数据和多视图图像通常是不可获得的或昂贵的,这阻碍了该方法的广泛应用。
预训练模型监督:无需依赖多视图图像或配对数据,可以采用某些预训练模型从头开始优化NeRF,如图7a所示。例如,可以利用预训练的CLIP来实现文本驱动的3D感知图像合成,通过优化NeRF,根据CLIP模型呈现具有目标文本描述的多视图图像。AvatarCLIP也采用了类似的基于CLIP的方法来实现zero-shot文本驱动的三维角色生成和动画。最近,随着扩散模型的蓬勃发展,预训练的2D扩散模型显示出巨大的潜力,可以驱动生成高保真的3D场景,用于不同的文本提示,如DreamFusion。具体而言,基于概率密度的2D扩散模型可以作为生成先验,通过梯度下降优化随机初始化的三维神经场,这样它的2D渲染就能在目标条件下获得高分。
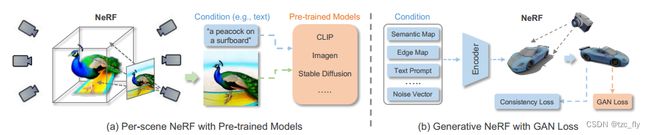
- 图7:per-scene Nerf和生成式Nerf。
DreamFusion
NeRF使用神经网络表示一个物体,即把一个3D对象参数化。一个场景下的不同角度图像提供给模型作为输入,然后优化NeRF以恢复该特定场景的几何形状,能够从未观察到的角度合成该场景的新视图。NeRF的回顾如下:
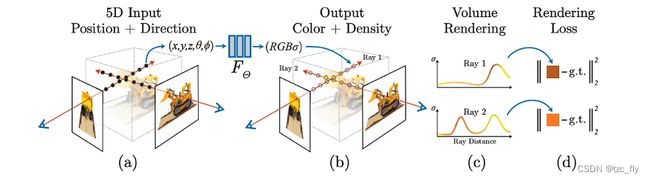
- NeRF场景表示和可微分渲染过程。我们通过沿着相机的光线采样5D坐标(位置和观察方向,采样点为图a的黑点),将这些信息输入 F Θ F_Θ FΘ生成颜色和体积密度(图b的采样点),使用体渲染技术将这些值合成图c即2D图像。该渲染函数是可微的,因此我们可以通过最小化合成图像和GT观测图像之间的error来优化场景表示(图d)。
动机:3D对象的获取方式主要由Blender和Maya3D等建模软件手工设计,这个过程需要耗费大量的时间和专业知识。text-image已经很成功,text-3D的数据极度稀缺,导致该领域没有进展,所以DreamFusion希望借助CLIP和扩散模型的能力结合NeRF来实现text生成3D。
DreamFusion = Diffusion model + NeRF
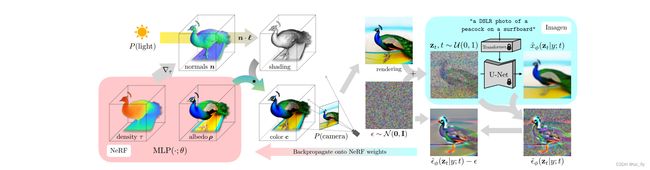
- DreamFusion根据自然语言标题生成3D对象,比如:“a DSLR photo of a peacock on a surfboard.”。场景由一个神经辐射场表示,该场随机初始化。NeRF用MLP参数化了体积密度和颜色。从一个随机的相机中渲染。为了更新NeRF的参数(从随机3D模型优化到文本提示的3D模型),DreamFusion对渲染进行扩散建模,并使用(冻结的)Imagen模型进行重建,以预测注入的噪声 ϵ ^ ϕ ( z t ∣ y ; t ) \widehat{\epsilon}_{\phi}(z_{t}|y;t) ϵ ϕ(zt∣y;t)。这包含了应该提高保真度的结构,但是是高方差的。减去注入的噪声会产生一个低方差的更新方向梯度,该梯度通过渲染过程反向传播,以更新NeRF的MLP参数。
DreamFusion不需要3D训练数据,也不需要修改图像扩散模型,其引入了一种基于概率密度蒸馏的损失,可以使用2D扩散模型作为先验。通过梯度下降优化随机初始化的3D模型(NeRF),使其从随机角度进行的2D渲染达到低损失。
DreamFusion的工作方式:
给定标题,DreamFusion 使用称为 Imagen 的文本到图像生成模型来优化 3D 场景。其中提出了分数蒸馏采样,这是一种通过优化损失函数从扩散模型生成样本的方法。SDS 允许在任意参数空间(例如 3D 空间)中优化样本,只要能够可微地映射回图像即可。使用NeRF的 3D 场景参数化来定义这种可微映射。单独的 SDS 可以产生合理的场景外观,但 DreamFusion 添加了额外的正则化器和优化策略来改进几何形状。训练后的 NeRF 是连贯的,具有高质量的法线、表面几何形状和深度。
GAN-based NeRF
在生成式NeRF中,场景由相应隐空间中的隐编码指定。GRAF是第一个引入GAN框架,通过采用多尺度基于patch的判别器对辐射场进行生成训练的研究。最近有很多努力致力于改进生成式NeRF,例如GIRAFFE,在特征级别引入体渲染,并以可控的方式分离对象实例。
在条件生成NeRF中,场景由三维位置和给定条件的组合指定,如图7b所示。根据GAN或扩散模型中的集成策略,可以将条件集成到NeRF中。例如,使用预训练的CLIP模型来提取条件视觉和文本特征以约束NeRF。同样,pix2pix3D编码指定的视觉引导来生成用于场景表示。