python_元组和字符串
目录
- 一、元组
-
- 打包和解包
- 二、字符串
-
- 2.1 回文数测试
- 2.2 常用的大小写字母换来换去的方法
- 2.3 左中右对齐的方法
- 2.4 查找方法
- 2.5 替换方法
- 2.6 判断方法
- 2.7 截取方法
- 2.8 拆分和拼接
- 2.9 格式化字符串的方法
-
- 2.9.1 [align]选项: 指定对齐方式
- 2.9.2 [type]选项
- 2.9.3 [#]选项
- 2.9.4 f-字符串
一、元组
元组与列表的区别:
列表-[元素1,元素2,…]
元组-[元素1,元素2,…]
-
元组不可修改,元组小括号可省略。
-
元组也支持切片,切片是将目标对象中的元素以某种特定组合导出,而非修改对象本身。

-
元组不支持修改,所以只有count() index()方法。
-
没有元组推导式,元组不支持修改!

打包和解包
打包:生成一个元组,也称为元组的打包。
解包:适用于任何类型,赋值号左边的变量名数量 = 右侧序列的元素数量。
前后数量不一致,可使用 " * " 将后面所有值赋给c。

python的多重赋值,其实是先将元组进行打包,然后再解包的过程。

元组并不是固若金汤的,元组中的元素虽然是不可变的,但如果元组中的元素指向一个可变的列表,依然可以修改列表里的内容。

二、字符串
2.1 回文数测试
1.回文数测试:

2.2 常用的大小写字母换来换去的方法
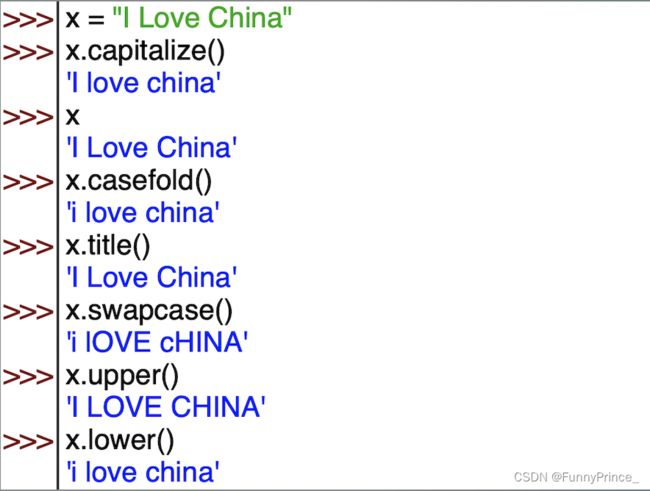
capitalize(): 首字母大写,其余小写。返回的并不是原字符串,因为字符串是不可变的对象,只是按照此规则生成一个新的字符串。
casefold(): 所有字母都小写,除了英语字母外,还可以处理其他语言。
title(): 每个单词的首字母都变大写,其余字母小写。
swapcase(): 大小写翻转。
upper(): 所有字母大写。
lower(): 所有字母小写,只能处理英文字母。
2.3 左中右对齐的方法
center(width, fillchar=' '): 居中,fillchar填充字符默认空格。
ljust(width, fillchar=' '): 左对齐,用空格补齐。
rjust(width, fillchar=' '): 右对齐。
zfill(width'): 用0填充左侧,数据报表可用。
width用来指定字符串的宽度,若指定的宽度 <= 原字符串,无对齐,原字符串输出。

2.4 查找方法
count(sub[, start[, end]]): count方法用于查找sub参数指定的子字符串在字符串中出现的次数。
find(sub[, start[, end]]): 用于定位sub参数指定的子字符串在字符串中的索引下标值,从左往右找。
rfind(sub[, start[, end]]): 从右往左找。找不到返回-1
index(sub[, start[, end]]): 同上,找不到抛异常。
rindex(sub[, start[, end]]): 同上。

2.5 替换方法
expandtabs([tabsize = 8]): 使用空格替换制表符,并返回新的字符串,参数是指定一个tab等于多少个空格。
replace(old, new, count=-1): 返回一个将所有old参数指定的子字符串,替换成new参数指定的新字符串,count参数指定替换次数。默认count = -1,不指定则替换全部。
translate(table): 返回一个根据table参数转换后的新字符串。需使用str.maketrans(x[, y[, z]])方法来获取table。


2.6 判断方法
startswith(prefix[, start[, end]]): 判断参数指定的子字符串是否出现在字符串的起始位置。[ 表示可选参数,后面为索引开始和结束的位置,左闭右开。
endswith(prefix[, start[, end]]): 判断参数指定的子字符串是否出现在字符串的结束位置。
istitle(): 判断是否都以大写字母开头,其余小写。
isupper(): 判断是否都是大写。
islower(): 判断是否都为小写。
isalpha(): 判断字符串是否都由字母组成。空格不为字母,会加入判断。
isspace(): 判断是否为一个空白字符串。\n, 空格,tab。
isprintable(): 判断字符串中是否所有字符都是可打印的。\n 不是可打印字符,转义字符不可被打印。
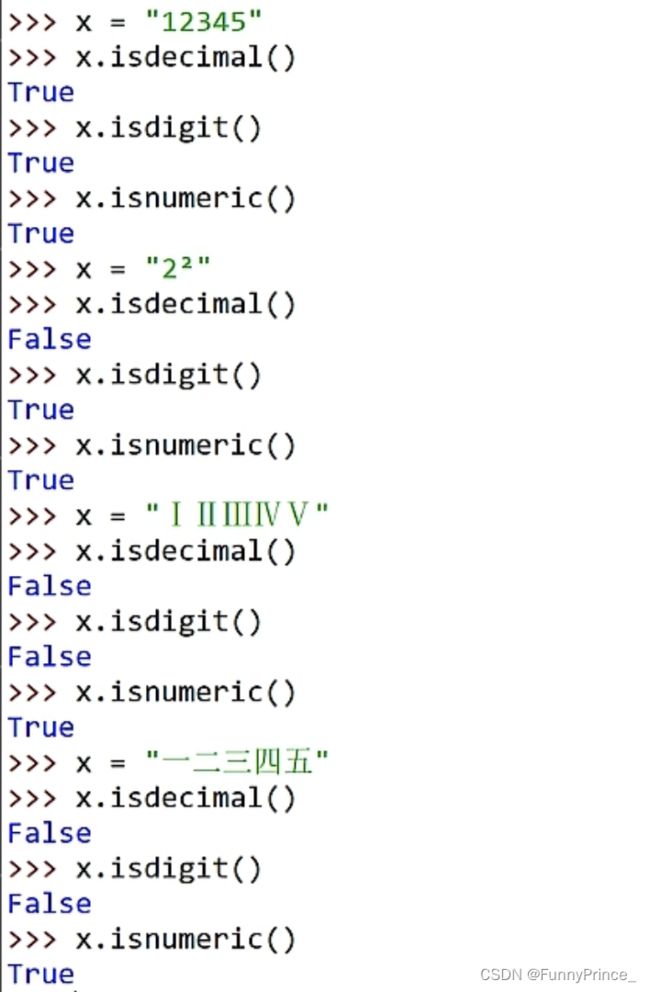
isdecimal(): 只支持纯数字。
isdigit(): 所有字符都是数字。
isnumeric(): 任何形式的数字都可。
isalnum(): 只要isalpha(), isdecimal(), isdigit(), isnumeric()其中任意一个方法返回true,结果则为true。
isidentifier(): 判断字符串是否是合法的python标识符
tips:
在python中连续调用多个方法,从左到右依次进行调用,即先调用upper()方法将字符串全部转换成大写字母的新字符串,再调用isupper()方法进行判断。

isalpha(): 判断字符串是否都由字母组成。空格不为字母,会加入判断。
isspace(): 判断是否为一个空白字符串。\n, 空格,tab。
isprintable(): 判断字符串中是否所有字符都是可打印的。\n 不是可打印字符,转义字符不可被打印。

isdecimal(): 只支持纯数字。
isdigit(): 所有字符都是数字。
isnumeric(): 任何形式的数字都可。
isalnum(): 只要isalpha(), isdecimal(), isdigit(), isnumeric()其中任意一个方法返回true,结果则为true。
isidentifier(): 判断字符串是否是合法的python标识符

判断一个字符串是否为python保留标识符,eg: if, for, while等关键字,可以使用keyword模块的iskeyword函数来实现。

tips: 使用模块需先导入。
2.7 截取方法
lstrip(chars=None): 左侧不留白,chars默认为None,即空白,可设置为其他想要的。
rstrip(chars=None): 右侧不留白
strip(chars=None): 左右两侧不留白
按照单个字符为单位进行匹配去剔除,从左侧lstrip开始剔除所有含指定字符串的每个字符,直到左侧lstrip开头不是以指定字符串开始为止。

removeprefix(prefix): 指定删除的前缀
removesuffix(suffix): 指定删除的后缀

2.8 拆分和拼接
partition(sep): 将字符串以参数指定的分隔符进行切割,并将切割后的结果返回一个三元组。
三个元组:中间是指定的分隔符,左侧元素是分隔符左侧的内容,右侧元素是分隔符右侧的内容
rpartition(sep): 从右往左。
split(sep=None, maxsplit=-1): sep默认情况按照空格切分,可通过参数指定分隔符。maxsplit指定分割次数,默认-1,表示找到分隔符就切开。
rsplit(sep=None, maxsplit=-1): 从右往左。
splitlines(keepends=False): 将字符串按行进行分割,将结果以列表的形式返回。keepends指定结果是否要包含这个换行符。
join(iterable): 字符串作为分隔符使用,构成字符串的每一个子字符串是放在join方法的参数里边的,可以用列表或元组包裹起来。
join使用 “.” 和 “^” 作为分隔符,进行拼接字符串。

将两个China字符串进行拼接:

join效率非常高!!
2.9 格式化字符串的方法
格式化字符串:使用一对 " {} " 来表示替换字段,即在原字符串中占一个坑位,真正的内容放在format方法的参数中。
参数中的字符串将会被当作元组的元素来对待,所以{}中写入数字,表示下标索引。同一个索引值,可以被引用多次。
也可使用关键字参数,此时顺序不重要。
2.9.1 [align]选项: 指定对齐方式
[[fill]align][sign][#][0][width][grouping_option][.precision][type]
" : " 冒号左边是位置或者关键字索引,右边是格式化选项。
0表示为数字类型启用感知正负号的0填充效果,只对数字有效。
也可设置指定填充符号

2.9.2 [type]选项
[[fill]align][sign][#][0][width][grouping_option][.precision][type]
适用于整数的情况:

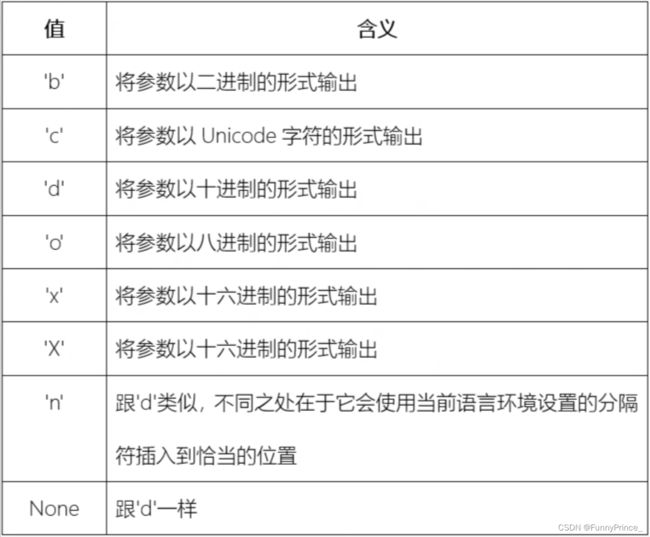

适用于浮点数和复数的情况:
使用 " , " 作为千位分隔符,如果位数不足,千位分隔符不显示。
对于[type]设置为’f’ 或 ‘F’ 的浮点数来说,是限定小数点
后显示多少个数位。
对于[type]设置为’g’ 或 ‘G’ 的浮点数来说,是限定小数点前后一共显示多少个数位。
对于非数字类型来说,限定的是最大字段的大小。
对于整数来说,则不允许使用[.precision]选项。
非数字类型,如字符串,截取前六位。
精度选项不允许应用在整数上。

python支持通过关键字参数来设置选项的值
2.9.3 [#]选项
[#] 表示参数以二进制、八进制或十六进制在字符串中输出时,会自动追加一个前缀。

2.9.4 f-字符串
f-string是format的一个语法糖,简化了格式化字符串的操作,并且带来了性能上的提升,适用于python3.6之后。

使用:去掉format,在字符串前面➕ f 或 F,作为前缀。