什么是模糊测试?

背景:近年来,随着信息技术的发展,各种新型自动化测试技术如雨后春笋般出现。其中,模糊测试(fuzz testing)技术开始受到行业关注,它尤其适用于发现未知的、隐蔽性较强的底层缺陷。这里,我们将结合AFL开源工具,对模糊测试的基本概念和流程进行说明。
01 模糊测试的定义
模糊测试的核心思想是,根据一定的规则,自动或半自动生成的随机数据,然后将产生的数据输入到程序中,并监视程序是否有异常出现,以发现可能的程序错误,如内存泄漏、系统崩溃、未处理的异常等。
当一个模糊测试生成器开始启动并运行后,它将自己寻找漏洞,并不需要人工干预,非常有助于发现传统测试方法或手动审计无法检测到的缺陷。
模糊测试包括几个基本的测试步骤:确定被测系统->给定输入->生成测试用例->灌入用例进行测试->监控目标程序情况->输出崩溃日志。

图一:模糊测试流程
02 测试用例生成算法
模糊测试用例的生成算法主要有两种:
1)基于变异:根据已知数据样本,通过变异的方法生成新的测试用例;
例如对一个图片文件进行变异,用户需要提供一个相应格式的图片文件,变异生成器会基于该图片进行变异。著名的开源模糊测试工具AFL就是基于变异生成用例。
2)基于生成:根据已知的协议或接口规范,建模并生成测试用例;
某些程序可能对输入有严格的规则要求,例如必须是SQL语句、或者给定的协议规范等。测试引擎需要在测试前预先学习对应的语法语义规则,对其进行建模,在此基础上才能变异出有效的测试用例。
03 测试工具介绍
当前已经有很多开源的模糊测试工具,其中使用较为广泛的是AFL(American Fuzzy Lop),由谷歌工程师迈克尔·扎里斯基(Michal Zalewski)开发,该项目已经由Github托管。
在执行前,需要对被测程序源码进行插桩
(instrumentation),以获知被测程序的运行信息。在执行过程中,它通过记录输入样本的代码覆盖率,从而调整输入样本以提高覆盖率,增加发现漏洞的概率。其工作流程大致如下:
从源码编译程序时进行插桩,以记录代码覆盖率;
选择一些输入文件,作为初始测试集加入输入队列;
将队列中的文件按一定的策略进行“突变”;
如果经过变异文件更新了覆盖范围,则将其保留添加到队列中;
上述过程一直循环进行,期间触发crash的文件会被记录下来。
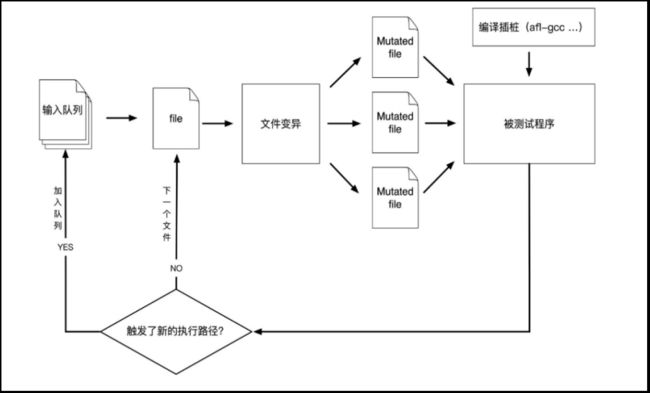
图二:AFL模糊测试的基本流程
AFL的优点是可以轻松部署,配置相对简单,测试效率相对较高。原生的AFL仅适配于C/C++程序的测试,不过目前已经衍生出很多分支,用于适配其他语言的模糊测试,如针对JAVA程序的Kelinci等。
04 用例变异方式
AFL是采用遗传算法,基于变异生成的测试用例,变异的主要类型有下面这几种:
· Bit flip,按位翻转,1变为0,0变为1
· Arithmetic,整数加/减算术运算
· Interest,把一些特殊内容替换到原文件中
· Dictionary,把自动生成或用户提供的token替换或插入到原文件中
· Havoc,又称“大破坏”,是前面几种变异的组合
· Splice,又称“绞接”,将两个文件拼接起来得到一个新文件
AFL需要一些初始输入数据(也称种子文件)作为模糊测试的起点,这些输入可以是毫无意义的数据。AFL通过上述方式自动确定文件的格式和结构。当输入队列中的全部文件都完成变异测试,则完成了一个Cycle(周期),如果用户不停止执行,种子文件将会不断变异下去。
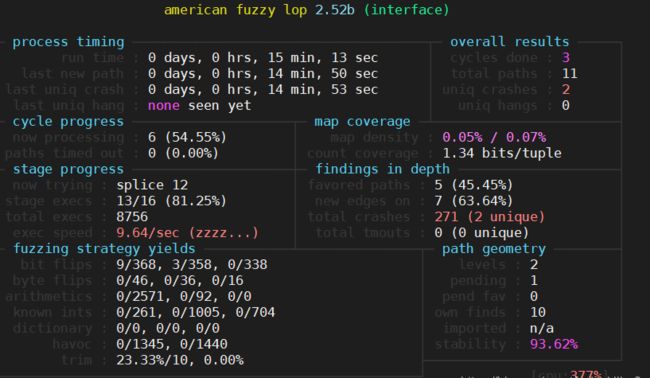
图三:AFL监控台,显示当前为Cycle 6, Splice 12阶段
扎里斯基曾经给出一个有趣的例子,对djpeg(一个Linux系统上的图像处理程序)进行模糊测试,在仅初始输入“hello”字符串的情况下,最后凭空生成了大量jpeg的图像。
综上所述,我们简要介绍了模糊测试的概念以及开源工具AFL的测试流程,欢迎持续关注。
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!