阅读笔记:Zero-Effort Cross-Domain Gesture Recognition with Wi-Fi
摘要
为了推进领域无关的感知,一个在较低的信号级别的领域无关的特征是关键。提出Widar3.0,主要为了在较低的信号级别推导和估计手势的速度分布。开发了一个只需一次训练但是可以适应不同数据领域的模型。
1 引言
目前存在的方法的问题在于,每次换一个领域(domain)都需要在数据获取和模型重训练上做出额外的工作。
一个有前景但是有挑战性的方法就是开发只需在一个领域下训练一次,就能在任何地方使用的模型。我们的工作的关键想法在于将泛化能力向下移动到较低的信号水平,而不是在较高的模型层面。具体来说,是从原始领域相关的信号中,提取领域无关的特征,这些特征只反映手势本身。在此基础上,建立一个可解释的跨领域识别模型。
主要面临三个技术上的挑战:
- 过去使用的信号特征(比如振幅、相位、多普勒频移(DFS)),以及他们的统计数据(最大、最小、平均、分布参数),都是领域相关的这意味着即使是相同的手势,它们的值也会随着不同的位置、方向和环境而变化。
- 由于无线电信号只有几个连接,很难描述人类的手势和动作。例如,单个手势的动态轮廓仍然有数百个变量,这使得动态轮廓的估计成为一个高度欠定的问题。
- 第三,跨域泛化通常需要复杂的学习模型(例如,更深的网络、更多的参数、更复杂的网络结构和更复杂的损失函数),这些模型会减慢甚至阻碍训练,过度消耗训练数据,使模型更难以解释。
Widar和Widar2.0跟踪人体粗糙的运动状态,例如位置和速度,并且把人当成是一个点。而Widar3.0要识别复杂的手势以及多个身体部位。Widar3.0的关键组件是领域无关特征body-coordinate velocity profile(BVP),描述了 不同速度下的能量分布。我们观察到,不管在怎样的领域下,每种手势在身体坐标系中都有其独特的速度分布。为了估算BVP,我们从几个显著的速度分量中估算BVP,并进一步使用压缩感知技术来获得准确的估算。在此基础上,我们设计了一个学习模型来捕捉手势的时空特征并最终进行手势分类。我们在COTS Wi-Fi设备上实现了Widar3.0。
核心贡献有三点:
- 我们提出了一种新的领域无关的特征,BVP,捕捉人体姿态的身体坐标速度剖面在较低的信号水平。
- 在BVP特征基础上开发了一个one-fits-all模型以及一个充分利用BVP时空特征的学习模型。
- 准确率高。并且是第一个 zero-effort cross-domain gesture recognition via Wi-Fi
2 MOTIVATION
粗糙特征不能跨域。大多数识别方法从CSI提取粗糙的统计(波形)或物理特征(DFS、AoA,ToF)。然而由于人的不同位置和方向,以及多路径环境,同一个手势的特征可能有很大不同,影响识别。
用于粗跟踪的跨域运动特性。无设备跟踪方法在信号的物理特征和人体的运动状态之间建立定量关系,跨环境启用位置和速度测量。然而这些方法把人体看成一个点,而不足以识别包含多个肢体的复杂的手势。图3显示了一个简单拍手的光谱图,它包含两个主要的DFS成分,由两只手和几个次要成分组成。

跨域学习方法中潜在的特征。跨域学习方法中,例如迁移学习和对抗学习都潜在地从数据样本中产生特征。但是,这些工作需要额外的工作,从目标域收集数据样本,并在每次添加新的目标域时对分类器进行重新训练。
3 WIDAR3.0概述

Widar3.0是一个跨域的手势识别系统,使用现成的Wi-Fi设备。如图5所示,监控区域周围部署了多个无线链接。在接收端接收到用户在监控区域内产生的无线信号,并对其CSI测量进行记录和预处理,以消除幅值噪声和相位偏移。
Widar3.0有两个主要模块:BVP生成模块和手势识别模块。
一旦接收到处理好地CSI series,Widar3.0将其划分成小的片段,并且通过BVP生成模块对每个CSI片段生成BVP。Widar3.0先产生三个中间结果:DFS谱以及人的方向和位置信息。DFS谱是通过对CSI series的时频分析来评估的。方向和位置信息是由运动跟踪方法来计算的。在此基础上,Widar3.0应用提出的基于压缩感知的优化方法来估计每个CSI段的BVP。然后输出BVP系列,用于后续的手势识别。
手势识别模块使用了深度学习网络。使用BVP series作为输入,Widar3.0对每个BVP和整个系列进行规范化,以删除实例和人员的无关变量。然后规范化后的BVP series被输入到时空DNN中。首先DNN使用卷积层提取在每个BVP中的高层次的空间特征。然后采用递归层对BVPs间的互特征进行时间建模。最后,DNN的输出指示用户执行的手势的类型。原则上,Widar3.0实现了零功跨域手势识别,只需要一次DNN网络训练,但可以直接适应尽可能多的新域。
BODY-COORDINATE VELOCITY PROFILE
直观地看,人类活动在涉及的所有身体部位都有独特的速度分布,可以作为活动指标。在人所反映的信号的所有参数(即ToF、AoA、DFS和衰减)中,DFS最能体现速度分布的信息。不幸的是,DFS还与人的位置和方向高度相关。
4.1CSI的多普勒表示
现成的Wi-Fi设备描绘的CSI描述了在室内环境中数据包到达时间 t t t和子载波频率 f f f时的多径效应:

其中 L L L是路径数, a l a_l al和 τ l \tau_l τl是第 l l l条路径的复数衰减和传播延迟。 ϵ ( f , t ) ϵ(f,t) ϵ(f,t)是由时序对准偏移,采样频率偏移和载波频率偏移引起的相位误差。
通过用相应的DFS表示多径信号的相位,可以将CSI变换为:

其中其中常数 H s H_s Hs是DFS为零的所有静态信号(例如LoS信号)的总和, P d P_d Pd是DFS为非零的动态信号的集合(例如目标反射的信号)。
通过在同一Wi-Fi NIC上计算两个天线的CSI的共轭乘法,并滤除带外噪声和准静态偏移,可以去除随机偏移,并且仅保留具有非零DFS的重要多径分量。 进一步应用短期傅立叶变换可在时域和多普勒频域上产生能量分布。单个链接的频谱图的一个示例如图3所示。我们将频谱图中的每个快照表示为DFS谱。 具体来说,DFS谱,D是维数为 F × M F\times M F×M的矩阵,其中 F F F是频域中采样点的数量, M M M是收发器链路的数量。 基于来自多个链接的DFS谱,我们可以推导与域无关的BVP。
4.2 从DFS到BVP
一个人执行手势时,他的身体部位(例如,两只手,两只手臂和躯干)以不同的速度运动。 结果,这些身体部位反射的信号会经历各种DFS,这些DFS叠加在接收器上并形成相应的DFS轮廓。 如第2节所述,尽管DFS曲线包含手势的信息,但它也非常特定于域。 相反,在人的身体坐标系中在物理速度上的功率分布仅与手势的特性有关。 因此,为了消除域的影响,从DFS曲线中导出了BVP。
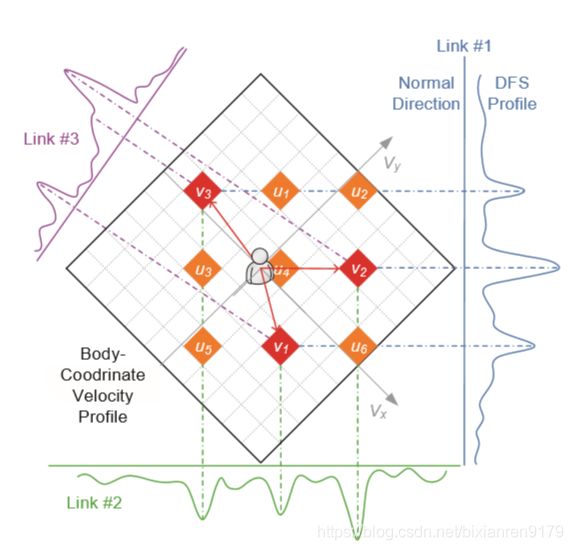
BVP的主要思想如图6所示。一个BVP V量化为维数为 N × N N\times N N×N的离散矩阵,其中 N N N为体坐标各轴上分解的速度分量可能值的个数。我们建立了以人的位置为原点的局部人体坐标, x x x轴正方向与人的朝向一致。估计人的位置和朝向的方法将在4.4节中讨论。目前假定人的全局位置和朝向是已知的。然后将已知的无线收发器的全局位置转换为局部体坐标。因此,下面推导中使用的所有位置和方向都默认在局部体坐标中。假设第 i i i个链接的接收器和发送器的坐标分别是![]()
那么,人体周围的任何速度分量 v ⃗ = ( v x , v y ) \vec{v}=(v_x,v_y) v=(vx,vy),都会将其信号功率贡献给某个频率分量,标记为 f ( i ) ( v ⃗ ) f^{(i)}(\vec{v}) f(i)(v),在第 i i i个链接的DFS曲线中

其中, a x ( i ) {a_x}^{(i)} ax(i)和 a y ( i ) {a_y}^{(i)} ay(i)是由发射机和接收机的位置决定的系数:
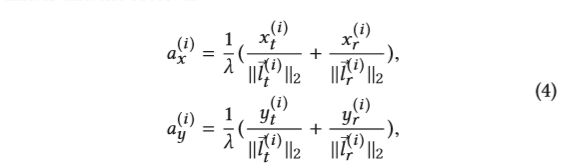
这里 λ \lambda λ是Wi-Fi信号的波长。由于在计算DFS曲线之前,零DFS的静态分量已经滤掉了,只有人所反映的信号才会被保留。此外,当人靠近Wi-Fi链接时,只有一次反射的信号才具有明显的幅度。因此,公式3适用于手势识别场景。从几何角度看,公式3表示二维速度矢量 v v v投影在一条方向矢量为 d ( i ) = ( − a y ( i ) , a x ( i ) ) ) d^{(i)}=(-{a_y}^{(i)},{a_x}^{(i)})) d(i)=(−ay(i),ax(i)))。假设该人处于椭圆曲线上,其焦点是第 i i i条链路的发送器和接收器,则 d ( i ) d^{(i)} d(i)实际上是该人所在位置的椭圆的法线方向。 图6显示了一个示例,其中人生成了三个速度分量 v j ⃗ , j = 1 , 2 , 3 \vec{v_j},j = 1,2,3 vj,j=1,2,3,并且在三个链接的DFS曲线上投影了速度分量。
由于系数 a x ( i ) {a_x}^{(i)} ax(i)和 a y ( i ) {a_y}^{(i)} ay(i)仅取决于第 i i i条链路的位置,因此BVP在第 i i i条链路上的投影关系是固定的。 具体来说,可以定义分配矩阵 A F × N 2 ( i ) A^{(i)}_{F\times N^2} AF×N2(i):

这里 f j f_j fj是DFS曲线中的第 j j j个频率采样点, v ⃗ k \vec{v}_k vk是矢量化的BVP V的第 k k k个元素对应的速度分量。因此第 i i i个链接的DFS曲线和BVP的关系可以建模为:
![]()
其中 c ( i ) c^{(i)} c(i)为反射信号传播损耗引起的比例因子。
4.3 BVP估计
由图6可知,仅使用前两个链接(蓝色和绿色),三个速度分量会在每个DFS曲线文件中创建三个功率峰值。 但是,当我们恢复BVP时,有9个速度分量候选,即 v j , j = 1 , 2 , 3 v_j,j = 1,2,3 vj,j=1,2,3和 u k , k = 1 , ⋅ ⋅ ⋅ 6 u_k,k = 1,···6 uk,k=1,⋅⋅⋅6。 并且可以轻松找到另一种解决方案,即 u 1 , u 3 , u 6 {u_1,u_3,u_6} u1,u3,u6,这意味着两个链接不够。
通过添加第三个链接(紫色),如果在第三个DFS曲线中没有投影重叠,则不管存在多少速度分量,它都能够以高概率解决歧义。 但是,当投影重叠时,添加第三个甚至更多链接可能无法解决歧义。 例如,假设图6中的第三个链接与它们的轴平行,并且投影有三个重叠(即{u1,v2},{v3,u4,u6}和{u3,v1}),则模棱两可的解{u1,u3,u6}仍然无法解决。 但是,由于对速度分量的分布以及链节的方向有严格的要求,所以这种歧义几乎不会发生。此外,我们可以通过添加更多链接来进一步降低歧义的可能性。
通过观察BVP的稀疏性并验证从多个链路恢复BVP的可行性,我们采用压缩感知的思想并将BVP的估计公式化为 l 0 l_0 l0优化问题。

这里 M M M是WIFI链接的数量。速度分量数目的稀疏性由术语 η ∣ ∣ V ∣ ∣ 0 \eta||V||_0 η∣∣V∣∣0强制,其中η表示稀疏系数,而 ∣ ∣ . ∣ ∣ 0 ||.||_0 ∣∣.∣∣0是非零速度分量的数目。
EMD(·,·)是两个分布之间的运土距离[。选择EMD而不是欧氏距离主要有两个原因。首先,BVP的量化引入了近似误差,即速度分量到DFS bin的投影可能接近于真实的速度分量。这种量化误差可以通过EMD来消除,EMD考虑了bin之间的距离。其次,BVP和DFS曲线之间存在未知的尺度因子,使得欧式距离不适用。
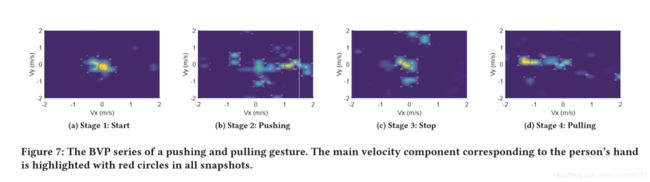
图7显示了一个推拉手势解决的BVP系列示例。手的主导速度分量和臂的耦合速度分量可以被清晰地观察到。
4.4 位置和方向
需要人的位置和方向来计算BVP。人做动作之前的移动,能够帮助计算出他的位置和方向。Widar3.0使用了现有的被动跟踪系统来确定位置和方向,如LIFS、IndoTrack、Widar2.0。
5 识别机制

设计DNN学习模型来挖掘BVP series的时空特征。图8显示了所提出的学习模型的总体结构。BVP series首先进行了归一化处理,之后才输入到学习模型中。
5.1 BVP归一化处理
虽然BVP在理论上只与手势有关,但有两个实际因素可能会影响其作为手势指示符的稳定性。首先,由于传输功率的调整,BVP的总功率可能会发生变化。第二,在实践中,不同的人所做的同一类型的手势可能具有不同的时间长度和移动速度。此外,即使是同一个人执行的实例也可能略有不同。因此,为了保持学习模型的简单性,有必要去除这些不相关的因素。
对于信号功率变化,Widar3.0通过调整BVP元素的和到1,来对每个BVP中的元素值进行归一化。对于变差,widar3.0使BVP series沿时域归一化。具体来说,Widar3.0首先设置手势的标准时间长度,用 t 0 t_0 t0表示。然后,对于时间长度为 t t t的手势,Widar3.0将其BVP series扩展到 t 0 t_0 t0。测量操作背后的假设是每个身体部位的距离保持不变。因此,为了改变BVP系列的时间长度,Widar3.0首先将BVP中所有速度分量的坐标乘以引述 t / t 0 t/t_0 t/t0,然后将该序列重采样到原始BVP序列的采样率。归一化后,结果只与手势相关。
5.2 空间特征提取
BVP数据类似于图片序列。每个BVP描述了在足够短的时间间隔内,功率相对于物理速度的分布。连续的BVP series说明了在某种动作下,分布是如何变化的。因此,为了充分理解派生的BVP数据,可以直观地从每个BVP中提取空间特征,然后对整个系列的时间依赖关系进行建模。
CNN是提取空间特征并压缩数据的有效技术,并且适合于处理单个BVP。BVP series,表示为V,是一个 N × N × T N\times N\times T N×N×T的张量,这里T是BVP snapshots的数量。过程如图8的Spatial Feature Extraction部分所示。
5.3 时间建模
使用RNN,因为可以建模复杂的temporal dynamics of sequences。我们这里选择GRU作为RNN单元,因为它可以和LSTM在序列建模上表现相当,但是参数更少并且更好训练。
具体地,Widar3.0选择单层GRU来建模时间关系。将CNN的输出输入到GRUs中,生成一个128维向量。在此基础上,增加了一个dropout层进行正则化,并利用具有交叉熵损失的softmax分类器进行类别预测。
6 评价
6.1 实验方法

Implementation.由1个发送器和至少3个接收器组成。所有接收器都是商用迷你电脑,配备有Intel 5300无线网卡。并且安装了Linux CSI Tool来记录CSI数据。设备设置维工作在monitor mode,在165信道5.825GHZ。发射器激活一个天线并且以1000个包每秒的速度传播WIFI包。接收器启动放置在一条直线上的三根天线。在MATLAB和Keras上运行。在三个不同环境的房间进行实验,如图9所示。
Evaluation setup.为了充分挖掘Widar3.0的表现,我们在手势识别上实施了全面的实验,我们在三个室内场景中进行试验:一个布置了桌子和椅子的空教室,一个宽阔的大厅和一个有沙发和桌子的办公室。图9显示了大体的场景特点和感知区域。图10展示了一个设备布置和区域配置的典型例子,这是一个2mX2m的区域。2mX2m的区域是实施手势识别的典型设置。我们假定只有手势实施者在感知区域内
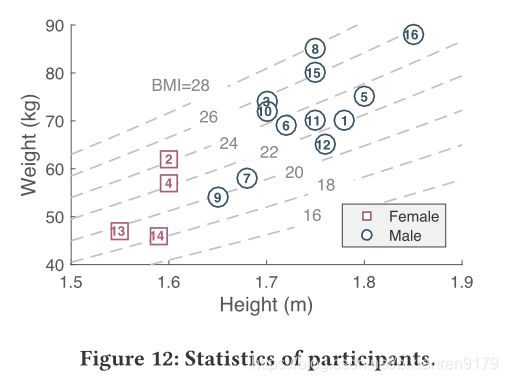
图10典型的设备的部署。由于移动的实体会引入噪声反射信号,进而导致目标手势的DFS配置文件准确性降低,我们假设只有手势执行者在感应区域中。除了两个接收器和一个发射器被布置在感知区域的角上,其他四个接收器可以被布置在感知区域外的随意的位置。如4.3节所提到的,理论上设备的布置几乎不对Widar3.0产生影响。所有的设备都放在110cm高的地方,这样不同身高的用户都可以展示手势。总共16个志愿者(12位男性和4位女性),身高在155cm~185cm之间,参与了这个实验。志愿者的细节信息如图12所示。
Dataset我们在每一个感知区域从五个位置和五个方向采集了手势数据,如图10所示。采集了两类数据。具体地说,第一个数据集由人机交互的常用手势组成,包括pushing and pulling, sweeping, clapping, sliding, drawing circle and drawing zigzag,这四个手势的简图如图11所示。这个数据集包括12000个手势样本(16 users × 5 positions × 5 orientations × 6 gestures × 5 instances)。第二个数据集是为了研究更加复杂的手势。两个志愿者(一个男性和一个女性)在水平的方向画了0~9的数字,总共包括5000样本(2 users × 5 positions × 5 orientations × 10 gestures × 10 instances) 。
Prerequisites Acquisition. 用户的位置和方向是计算BVP的先决条件。
6.2 总的准确率
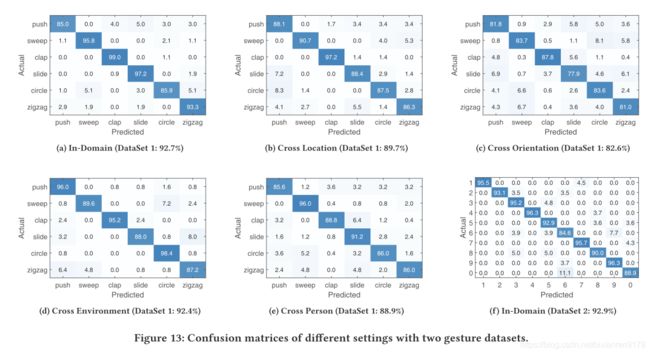
考虑到所有领域因素,Widar3.0的整体准确性达到92.7%,其中在1号会议室收集的90%和10%的数据分别用于训练和测试。 图13a显示了数据集1中6个手势的混淆矩阵,而Widar3.0的所有手势均获得了超过85%的一致高精度。 我们还通过添加“未知”类手势进行实验。 除上述6种手势外,志愿者还需要执行任意手势。 总体准确度下降到90.1%,Widar3.0可以以87.1%的准确度区分未知类别。 原因如下。 一方面,来自“未知”类的手势在某种程度上可能与预定义的手势相似。 另一方面,收集的“未知”手势仍然受到限制。 我们相信,如果我们引入其他过滤机制或修改学习模型以解决“新颖性检测”问题,则可以进一步改善结果。
图13b,13c,13d和13e进一步显示了考虑每个特定域因子的混淆矩阵。 对于每个域因子,我们计算所有域实例中的一个用于测试而其余域实例用于训练的情况的平均准确性。 还提供了所有手势的平均准确度,可以看出,Widar3.0在不同的域中均实现了一致的高性能,这证明了其跨域识别的能力。
我们观察到在域内和跨域情况下,“pushing and pulling”,“drawing circle”和“drawing zigzag”手势通常对应较低的精度。 尽管“pushing and pulling”手势是所有手势中最简单的一种,但它只是在用户躯干之前执行,因此很可能从某些链接的角度被阻止,这会导致BVP估算的准确性降低,如图所示 在以下实验中(第6.5节)。 当用户执行手势“drawing circle”或“drawing zigzag”时,轨迹在垂直方向上会有很大变化。 但是,Widar3.0设计为仅在水平面中提取BVP,导致两个手势的信息丢失,并且降低了识别精度。
Case study现在,我们检查Widar3.0是否仍然可以很好地用于更复杂的手势识别任务。 在本案例研究中,志愿者在水平面上绘制数字0〜9,总共收集了5,000个样本。 我们将数据集按9:1的比例随机分为训练和测试。 如图13f所示,Widar3.0的8个手势达到了90%以上的令人满意的结果,平均准确度为92.9%。
6.3跨域评估
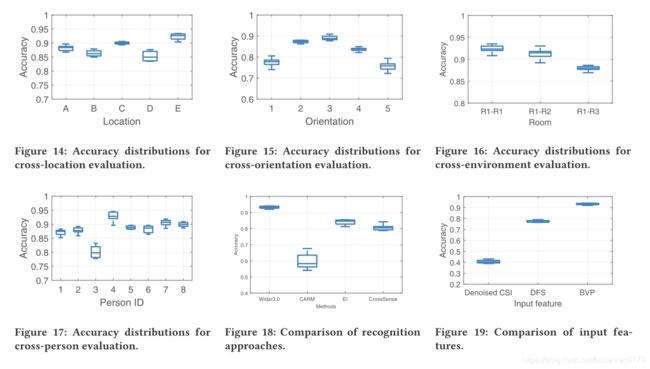
现在,我们评估Widar3.0在不同领域因素(包括环境,人员多样性以及人员的位置和方向)上的总体性能。 为了评估每个领域因素,我们保持其他领域因素不变,并对数据集执行留一法交叉验证。 根据精度的均值和方差,系统性能如图14-17所示。
Location independence该模型是在Room1的随机4个位置,所有5个方向和8个人的BVP上进行训练的。 并且将在同一房间的最后一个位置收集的数据用于测试。 如图14所示,所有未参与训练的位置的平均准确度都在85%以上。 通过将位于感应区域中心的位置e作为目标域,Widar3.0可获得92.3%的最佳性能。 当在位置d处收集测试数据集时,准确度下降到85.3%,因为在较长的传播距离之后,人体反射的无线信号会变弱,这会导致BVP的准确性降低。 另外,BVP是根据人反射的信号建模的。 如位置b的结果所示,如果此人碰巧将手臂穿过任何链接的视线路径,则准确性将略有下降。
Orientation sensitivity在这个实验中,我们选取每个方向作为目标域,其他四个方向作为源域。图15展示了对方向2,3,4,准确率保持在80%以上。与最好的目标方向3相比,1&5方向的效果下降了10%以上。 原因是手势可能会在这两个方向上被人体遮挡,并且用于BVP生成的有效无线链接数量会减少。 但是,对于通用手势识别应用程序(例如,TV控制),可以合理地假设,当用户面对电视时,他的方向与大多数无线设备相差不大,可以将足够多的无线设备用于准确的手势识别。
Environment diversity跨环境的准确性是跨域识别性能的另一个重要标准。 在本实验中,将在1号房间中收集的手势样本用作训练数据集,并将在3个房间中收集的三组手势样本用作测试数据集。 如图16所示,尽管不同房间的准确度略有下降,但即使环境完全改变,平均准确度仍可以保留87%以上。 简而言之,Widar3.0在不同环境下均具有强大的功能。
Person variety从不同人员收集的数据可能因其行为方式不同而有所差异。 Widar3.0合并了BVP规范化以缓解此问题。 为了评估Widar3.0在不同用户上的性能,我们在来自7个人的每种组合的数据集上训练模型,然后使用静止人的数据进行测试。 图17显示,在7个人中,准确率保持在85%以上。 第6.5节进一步研究了用于训练识别模型的人员数量的影响。
6.4方法比较
本节比较了具有不同方法,学习功能和学习网络结构的跨域识别能力。 在实验中,训练和测试数据集分别在1号室和2号室中收集。
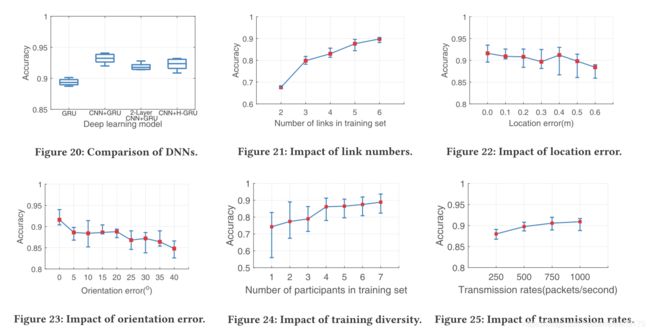
Comparison with the state-of-the-arts works. 我们将Widar3.0与几种替代的最新技术方法(CARM [44],EI [20]和CrossSense [50])进行了比较,其中后两种方法对于跨域识别是可行的。具体而言,CARM使用DFS profile作为学习功能并采用HMM模型。 EI包含一个对抗网络,专门训练损失,以额外利用目标域中未标记数据的特征。 CrossSense提出了一种基于ANN的漫游模型,以将信号特征从源域转换为目标域,并采用多个专家模型进行手势识别。图18显示了四种方法的系统性能。 Widar3.0使用最新的跨域学习方法EI和CrossSense可获得更好的性能,并且不需要来自新域的额外数据或模型重新训练。相比之下,CARM的特征和学习模型都没有跨域功能,这是其识别精度明显较低的主要原因。
Comparison of input features. 我们将原始CSI测量中的三种具有不同抽象级别的功能类型进行比较,即将经过去噪的CSI,DFSprofile和BVP输入到CNN-GRU混合深度学习模型中,类似于Widar3.0。 具体而言,去噪后的CSI大小为18(6个接收器的天线数)×30(子载波数)×T(时间采样数),DFS profile的形状为6(接收器数) ×F(多普勒频率数样本)×T(时间样本数)。
如图19所示,BVP的性能优于去噪后的CSI和DFS,准确度分别提高了52%和15%。 BVP的性能提高归因于其对收发器布局变化的抵抗力,但是这可能会显着影响其他两种类型的功能。
Comparison of learning model structures. 进一步比较了不同的深度学习模型和系统性能。如图20所示。具体而言,与仅捕获时间相关性的简单GRU模型相比,CNN-GRU混合模型将准确性提高了大约5%。 前一个模型受益于每个BVP快照中具有代表性的高级空间特征。 此外,我们还将BVP馈入到两个卷积层的CNN-GRU混合模型和CNN-Hierarchical-GRU模型中。 结果表明,更复杂的深度学习模型不能提高性能,这表明不同手势的BVP足够明显,可以通过简单但有效的分类器进行区分。
6.5 参数学习
Impact of link numbers. 在上述实验中,部署了6个链接以更准确地估算BVP。 本节研究链接数量对系统性能的影响。 如图21所示,随着链接数量从6个减少到3个,精度逐渐降低,但是当仅使用两个链接时,精度会下降很多。 主要原因是考虑到第4.3节中提到的歧义,某些BVP只能通过2个链接才能正确恢复,并且某些位置或方向的手势由于阻塞而无法完全捕获。
Impact of location and orientation estimation error.
由基于Wi-Fi的运动跟踪系统提供的定位和方向通常分别具有大约几分米和20度的误差。 因此,有必要了解这些错误如何影响Widar3.0的性能。 具体来说,我们记录位置和方向的地面真相,并计算执行手势时的错误。 一方面,如图22所示,当位置误差在40 cm以内时,总体精度保持在90%以上,但随着误差的进一步增加而下降。 另一方面,图23显示总体精度随着方向偏差的增加而逐渐下降。 尽管跟踪误差会对Widar3.0的性能产生负面影响,但考虑到实际的位置和方向误差,我们认为现有的运动跟踪工作仍可以提供可接受的精度的位置和方向结果。
Impact of training set diversity. 该实验研究了训练数据集中的志愿者数量如何影响绩效。 具体来说,从1到7数量不等的志愿者参与收集训练数据集,并且使用另一个新人的数据来测试Widar3.0。 图24显示,当训练人数从7变为1时,平均手势识别准确度从89%降低到74%。原因有两个。 首先,由于培训数据集由较少的志愿者提供,因此深度学习模型的培训程度将降低。 其次,即使我们采用了BVP规范化,测试人员和培训人员之间的行为差异也会被放大。 通常,Widar3.0承诺在训练集中有4名以上的人员能达到85%以上的准确性。
Impact of transmission rates. 由于Widar3.0需要通过分组传输来进行手势识别,因此正常的通信流程可能会受到干扰。 因此,我们评估了具有不同CSI传输速率的Widar3.0的性能。 我们以每秒1,000个数据包的初始传输速率收集CSI测量值,并将CSI系列下采样到750 Hz,500 Hz,250 Hz。 图25显示,当采样率降至250Hz时,精度略有降低约4%,并且在所有情况下均保持超过85%。 此外,Widar3.0可以使用较短的数据包进一步减少对通信的影响,因为只有CSI测量才可用于识别任务。