扩散模型实战(二):扩散模型的发展
推荐阅读列表:
扩散模型实战(一):基本原理介绍
扩散模型从最初的简单图像生成模型,逐步发展到替代原有的图像生成模型,直到如今开启 AI 作画的时代,发展速度可谓惊人。下面介绍一下2D图像生成相关的扩散模型的发展历程,具体如下:
- 开始扩散:基础扩散模型的提出与改进;
- 加速生成:采样器;
- 刷新纪录:基于显式分类器引导的扩散模型;
- 引爆网络:基于 CLIP ( Contrastive Language - Image Pretraining ,对比语言﹣图像预处理)的多模态图像生成;
- 再次"出图":大模型的"再学习"方法﹣ DreamBooth 、 LoRA 和 ControlNet ;
- 开启 AI 作画时代:众多商业公司提出成熟的图像生成解决方案。
1)开始扩散:基础扩散模型的提出与改进
在图像生成领域,最早出现的扩散模型是 DDPM (于2020年提出)。DDPM 首次将"去噪"扩散概率模型应用到图像生成任务中,奠定了扩散模型在图像生成领域应用的基础,包括扩散过程定义、噪声分布假设、马尔可夫链计算、随机微分方程求解和损失函数表征等,后面涌现的众多扩散模型都是在此基础上进行了不同种类的改进。
2)加速生成:采样器
虽然扩散模型在图像生成领域取得了一定的成果,但是由于其在图像生成阶段需要迭代多次,因此生成速度非常慢(最初版本的扩散模型的生成速度甚至长达数分钟),这也是扩散模型一直受到诟病的原因。在扩散模型中,图像生成阶段的速度和质量是由采样器控制的,因此如何在保证生成质量的前提下加快采样是一个对扩散模型而言至关重要的问题。
论文"Score-Based Generative Modeling through Stochastic Differential Equations"证明了 DDPM 的采样过程是更普遍的随机微分方程,因此只要能够更离散化地求解该随机微分方程,就可以将1000步的采样过程缩减至50步、20步甚至更少的步数,从而极大地提高扩散模型生成图像的速度,如图2-1所示。针对如何更快地进行采样这一问题,目前已经涌现了许多优秀的求解器,如 Euler、SDE、DPM-Solver++和Karras等,这些加速采样方法也是扩散模型风靡全球至关重要的推力。

图2-1 DPM-Solver++在20步采样内实现从“一碗水果”到“一碗梨”的图像编辑
3)刷新纪录:基于显式分类器引导的扩散模型
2021年5月以前,虽然扩散模型已经被应用到图像生成领域,但它实际上在图像生成领域并没有"大红大紫",因为早期的扩散模型在所生成图像的质量和稳定性上并不如经典的生成模型 GAN ( Generative Adversarial Network ,生成对抗网络),真正让扩散模型开始在研究领域"爆火"的原因是论文" Diffusion Models Beat GANs on Image Synthesis "的发表。OpenAl 的这篇论文贡献非常大,尤其是该文介绍了在扩散过程中如何使用显式分类器引导。
更重要的是,这篇论文打败了图像生成领域统治多年的 GAN ,展示了扩散模型的强大潜力,使得扩散模型一举成为图像生成领域最火的模型,如图2-2所示。

图2-2 扩散模型超越GAN的图像生成示例(左图为BigGAN-deep模型的结果,右图为OpenAI扩散模型的结果)
4)引爆网络:基于 CLIP 的多模态图像生成
CLIP 是连接文本和图像的模型,旨在将同一语义的文字和图片转换到同一个隐空间中,例如文字"一个苹果"和图片"一个苹果"。正是由于这项技术和扩散模型的结合,才引起基于文字引导的文字生成图像扩散型在图像生成领域的彻底爆发,例如 OpenAI 的 GLIDE 、 DALL - E 、 DALL -E2(基于 DALL -E2生成的图像如图2-3所示), Google 的 Imagen 以及开源的 Stable Diffusion ( Stable Diffusion v2扩散模型的主页如图2-4示)等,优秀的文字生成图像扩散模型层出不穷,给我们带来无尽的惊喜。

图2-3 基于DALL-E2生成的“拿着奶酪的猫”
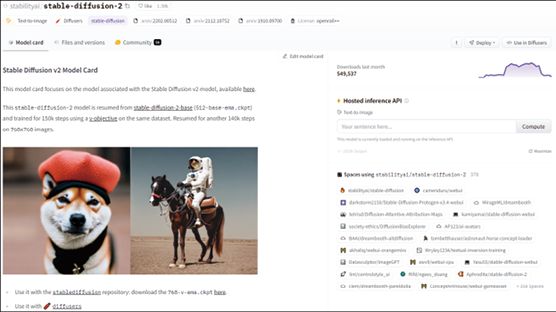
图2-4 Hugging Face的Stable Diffusion v2扩散模型的主页
5)再次"出图":大模型的"再学习"方法﹣DreamBooth 、 LoRA 和 ControlNet
自从扩散模型走上大模型之路后,重新训练一个图像生成扩散模型变得非常昂贵。面对数据和计算资源高昂的成本,个人研究者想要入场进行扩散模型的相关研究已经变得非常困难。
但实际上,像开源的 Stable Diffusion 这样的扩散模型已经出色地学习到非常多的图像生成知识,因此不需要也没有必要重新训练类似的扩散模型。于是,许多基于现有的扩散模型进行"再学习"的技术自然而然地涌现,这也使得个人在消费级显卡上训练自己的扩散模型成为可能。DreamBooth 、 LoRA 和 ControlNet 是实现大模型"再学习"的不同方法,它们是针对不同的任务而提出的。
DreamBooth 可以实现使用现有模型再学习到指定主体图像的功能,只要通过少量训练将主体绑定到唯一的文本标识符后,就可以通过输入文本提示语来控制自己的主体以生成不同的图像,如图2-5所示。

图2-5 使用 DreamBooth 将小狗嵌入图像中并生成不同场景下的小狗
LoRA 可以实现使用现有模型再学习到自己指定数据集风格或人物的功能,并且还能够将其融入现有的图像生成中。Hugging Face 提供了训练 LoRA 的 UI 界面,如图2-6所示。
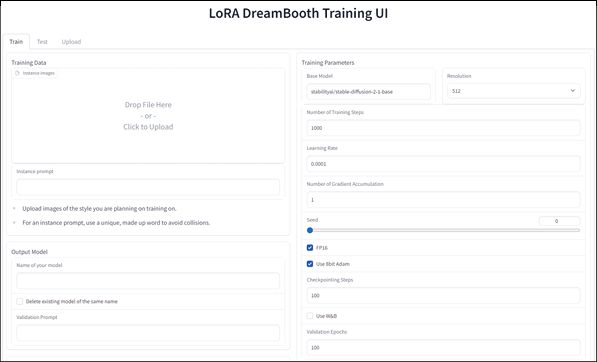
图2-6 Hugging Face 提供的 LoRA 训练界面
ControlNet 可以再学习到更多模态的信息,并利用分割图、边缘图等功能更精细地控制图像的生成。第7章将对 ControlNet 进行更加细致的讲解。
6)开启 AI 作画时代:众多商业公司提出成熟的图像生成解决方案
图像生成扩散模型"爆火"之后,缘于技术的成熟加上关注度的提高以及上手简易等,网络上的扩散模型"百花齐放",越来越多的人开始使用扩散模型来生成图像。
众多提供成熟图像生成解决方案的公司应运而生。例如,图像生成服务提供商 Midjourney 实现了用户可以通过 Midjourney 的 Discord 频道主页(如图2-7所示)输入提示语来生成图像,也可以跟全世界的用起分享和探讨图像生成的细节。此外通过 Stability Al 公司开发的图像生成工具箱 DreamStudio (如图2-8所示),用户既可以使用提示语来编辑图像,也可以将其 SDK 嵌入自己的应用或者作为 Photoshop 播件包当然, Photoshop 也有自己的基于扩散模型的图像编辑工具库 Adobe Firefly (如图2-9所示),用户可以基于 Photoshop 传统的选区等精细控制功能来更高效地生成图像。
图2-7 Midjourmey 的 Discora 频道主页

图2-8 Stability Al公司开发的DreamStudio

图2-9 Adobe的图像编辑工具库 Adobe Firefly
百度公司推出了文心一格 AI 创作平台(如图2-10所示),而阿里巴巴达摩院也提出了自己的通义文生图大模型等。除了头部企业以外,一些创业公司也开始崭露头角,退格网络推出的 Tiamat 图像生成工具已获多轮投资,由该工具生成的精美概念场景图像登陆上海地铁广告牌。北京毛线球科技有限公司开发的6pen Art 图像生成 APP (如图2-11所示)将图像生成带到手机端,使用户在手机上就能体验 AI 作画。

图2-10 百度公司的文心一格 AI 创作平台
图2-11 6pen Art 图像生成 APP
众多的服务商致力于以最成熟、最简单的方式让大众能够通过输入文字或图片的方式生成想要的图像,真正开启了 AI 作画时代。