改进YOLOv5:添加EMA注意力机制
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 新建EMA.py文件
- 修改yolo.py文件
-
- 1.导入EMA.py
- 2.修改parse_model
- 修改yaml文件(yolov5s为例)
- 参考
前言
本文主要介绍一种在YOLOv5-7.0中添加EMA注意力机制的方法。EMA注意力机制原论文地址,有关EMA注意力机制的解读可参考文章。
新建EMA.py文件
在yolov5的models文件中新建一个名为EMA.py文件,将下述代码复制到EMA.py文件中并保存。
import torch
from torch import nn
class EMA(nn.Module):
def __init__(self, channels, factor=8):
super(EMA, self).__init__()
self.groups = factor
assert channels // self.groups > 0
self.softmax = nn.Softmax(-1)
self.agp = nn.AdaptiveAvgPool2d((1, 1))
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
self.gn = nn.GroupNorm(channels // self.groups, channels // self.groups)
self.conv1x1 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=1, stride=1, padding=0)
self.conv3x3 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=3, stride=1, padding=1)
def forward(self, x):
b, c, h, w = x.size()
group_x = x.reshape(b * self.groups, -1, h, w) # b*g,c//g,h,w
x_h = self.pool_h(group_x)
x_w = self.pool_w(group_x).permute(0, 1, 3, 2)
hw = self.conv1x1(torch.cat([x_h, x_w], dim=2))
x_h, x_w = torch.split(hw, [h, w], dim=2)
x1 = self.gn(group_x * x_h.sigmoid() * x_w.permute(0, 1, 3, 2).sigmoid())
x2 = self.conv3x3(group_x)
x11 = self.softmax(self.agp(x1).reshape(b * self.groups, -1, 1).permute(0, 2, 1))
x12 = x2.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hw
x21 = self.softmax(self.agp(x2).reshape(b * self.groups, -1, 1).permute(0, 2, 1))
x22 = x1.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hw
weights = (torch.matmul(x11, x12) + torch.matmul(x21, x22)).reshape(b * self.groups, 1, h, w)
return (group_x * weights.sigmoid()).reshape(b, c, h, w)
修改yolo.py文件
1.导入EMA.py
在yolo.py文件开头导入EMA.py,代码如下:
from models.EMA import EMA
代码放在yolo.py位置如下图所示:

2.修改parse_model
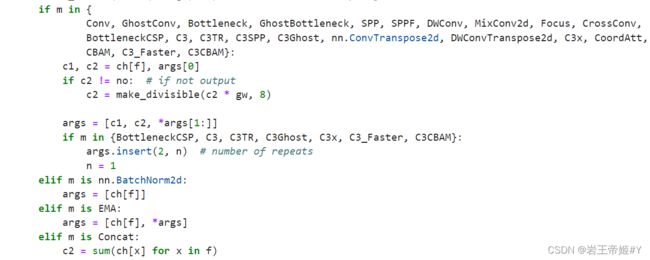
这里主要是添加通道参数,再添加一个elif,把EMA添加进去,代码如下:
elif m is EMA:
args = [ch[f], *args]
添加上述代码的位置可参考下图:
修改yaml文件(yolov5s为例)
# YOLOv5 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, EMA, [8]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 15], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 11], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
上述代码将EMA注意力机制模块加在backbone层中最后C3模块后面,SPPF模块前面,仅供参考,具体添加位置要根据个人数据集的不同合理的添加。
[-1, 1, EMA, [8]], #-1代表连接上一层通道数,1是个数,8是EMA所需的参数(factor=8)
说明:因为在yolo.py文件parse_model函数中修改了通道参数,因此在yaml文件中无需添加通道参数,只需添加EMA函数所需的其他参数。在backbone中添加一层注意力机制模块,因此后续的层数都要加一,在head层中做如下改动。
[[-1, 15], 1, Concat, [1]], #未改动前的第14层,在经过上述改动后改为15
[[-1, 11], 1, Concat, [1]], #未改动前的第10层,在记过上述改动后改为11
[[18, 21, 24], 1, Detect, [nc, anchors]], #17,20,23层改为18,21,24
运行train.py文件可以在输出终端窗口看到上图网络结构,可以看到在第9层已经成功添加EMA注意力机制模块。
from n params module arguments
0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 2 115712 models.common.C3 [128, 128, 2]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 3 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 1182720 models.common.C3 [512, 512, 1]
9 -1 1 41216 models.EMA.EMA [512, 8]
10 -1 1 656896 models.common.SPPF [512, 512, 5]
11 -1 1 131584 models.common.Conv [512, 256, 1, 1]
12 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
13 [-1, 6] 1 0 models.common.Concat [1]
14 -1 1 361984 models.common.C3 [512, 256, 1, False]
15 -1 1 33024 models.common.Conv [256, 128, 1, 1]
16 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
17 [-1, 4] 1 0 models.common.Concat [1]
18 -1 1 90880 models.common.C3 [256, 128, 1, False]
19 -1 1 147712 models.common.Conv [128, 128, 3, 2]
20 [-1, 15] 1 0 models.common.Concat [1]
21 -1 1 296448 models.common.C3 [256, 256, 1, False]
22 -1 1 590336 models.common.Conv [256, 256, 3, 2]
23 [-1, 11] 1 0 models.common.Concat [1]
24 -1 1 1182720 models.common.C3 [512, 512, 1, False]
25 [18, 21, 24] 1 16182 models.yolo.Detect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
YOLOv5sEMA summary: 222 layers, 7063542 parameters, 7063542 gradients, 16.2 GFLOPs
参考
https://www.bilibili.com/video/BV1s84y1775U/?spm_id_from=333.788&vd_source=f83457e2adc10b543ae4c742fba1e3b2
https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/131347981