YOLOv5如何训练自己的数据集
文章目录
- 前言
- 1、数据标注说明
- 2、定义自己模型文件
- 3、训练模型
- 4、参考文献
前言
本文主要介绍如何利用YOLOv5训练自己的数据集
1、数据标注说明
以生活垃圾数据集为例子
- 生活垃圾数据集(YOLO版)
- 点击这里直接下载本文生活垃圾数据集
生活垃圾数据集组成:
【有害垃圾】:电池(1 号、2 号、5 号)、过期药品或内包装等;
【可回收垃圾】:易拉罐、小号矿泉水瓶;
【厨余垃圾】:小土豆、切过的白萝卜、胡萝卜,尺寸为电池大小;
【其他垃圾】:瓷片、鹅卵石(小土豆大小)、砖块等。
YOLO数据有三个要点
- images,存放图片
- labes,对应Images图片的标签
- data_txt, 划分images图片的数据集,形成三个txt
文件结构:
----data\
|----classes.txt # 标签种类
|----data-txt\ # 数据集文件集合
| |----test.txt
| |----train.txt
| |----val.txt
|----images\ # 数据集图片
| |----test\
| | |----fimg_23.jpg
| | |----fimg_38.jpg
| | |----.....
| |----train\
| | |----fimg_1.jpg
| | |----fimg_2.jpg
| | |----.....
| |----val\
| | |----fimg_4.jpg
| | |----fimg_6.jpg
| | |----.....
|----labels\ # yolo标签
| |----test\
| | |----fimg_23.txt
| | |----fimg_38.txt
| | |----.....
| |----train\
| | |----fimg_1.txt
| | |----fimg_2.txt
| | |----.....
| |----val\
| | |----fimg_4.txt
| | |----fimg_6.txt
| | |----.....
|----waste-classification.yaml # 数据集配置文件
2、定义自己模型文件
1、定义yolov5网络模型文件
如 models/yolov5l.yaml
# YOLOv5 by Ultralytics, GPL-3.0 license
# Parameters
nc: 4 # number of classes 类别,这里的类别一共四种
depth_multiple: 0.33 # model depth multiple ,模型宽度
width_multiple: 0.50 # layer channel multiple ,通道数
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
2、在data/目标下,定义自己数据集的配置文件
如data/waste-classification.yaml
train: data/data-txt/train.txt
val: data/data-txt/val.txt
test: data/data-txt/test.txt
# Classes
nc: 4 # number of classes
names: ['recyclable waste', 'hazardous waste','kitchen waste','other waste'] # class names
3、训练模型
1、激活python环境
conda activate reid-pytorch # 这里我是激活reid-pytorch环境
2、在服务器上训练自己的模型
# 注意,这里是linux服务器上训练命令
# nohup 是后台运行,--batch-size 每次送入的图片数, --epochs 训练多少轮 --cfg 模型配置 --data 数据集配置
# --weights 以哪个权重训练 --device 在那个显卡上训练(这里一共有四张显卡) > 重定向,将训练的结果输出到myout.file,方便查看
nohup python train.py --batch-size 16 --epochs 200 --cfg models/yolov5s.yaml --data data/waste-classification.yaml --weights weights/yolov5s.pt --device 0,1,2,3 > myout.file 2>&1 &
# 如果是本地电脑上训练,直接在pycharm的train.py添加上述参数,直接训练
--batch-size 16 --epochs 200
--cfg models/yolov5s.yaml
--data data/waste-classification.yaml
--weights weights/yolov5s.pt
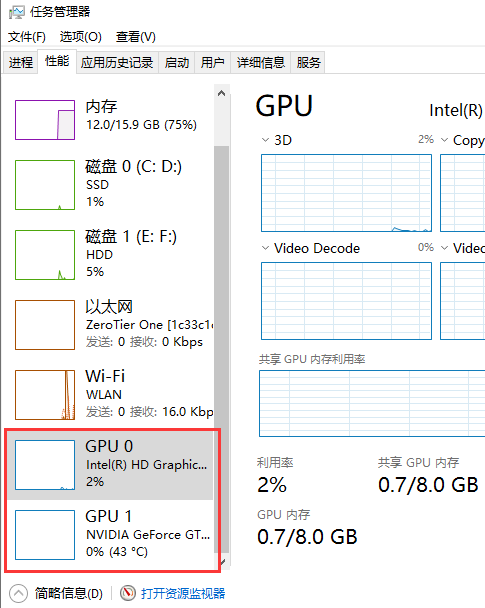
--device 0 # 采用显卡0进行训练


查看自己电脑显卡情况
4、参考文献
- YOLOv5s网络模型讲解(一看就会)
- 生活垃圾数据集(YOLO版)
- 双向控制舵机(树莓派版)