大数据从入门到精通(超详细版)之Hadoop详解
前言
嗨,各位小伙伴,恭喜大家学习到这里,不知道关于大数据前面的知识遗忘程度怎么样了,又或者是对大数据后面的知识是否感兴趣,本文是《大数据从入门到精通(超详细版)》的一部分,小伙伴们如果对此感谢兴趣的话,推荐大家按照大数据学习路径开始学习哦。
以下就是完整的学习路径哦。
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
大数据从入门到精通文章体系!!!!!!!!!!!!!!
↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑
推荐大家认真学习哦!!!
文章目录
- 前言
- 本文前言
- 什么是大数据?
- 大数据的运用
- Hadoop入门
本文前言
俗话说得好, "万事开头难 " ,学习这件事情也是一样的 。
所有的开始都是痛苦的 ,不止痛苦 ,而且枯燥 ,但是敢问能一直很舒服的提升自己呢 ,想要突破自我,必然需要经历一个从0到1的过程 ,送自己和大家一句话 :“长风破浪会有时,直挂云帆济沧海”
接下来正式开始大数据的学习,首先提出一个问题:
什么是大数据?
为了解答这个问题,我们需要首先搞懂,什么是数据?
官方的解释是这样的:
数据是对客观事物的逻辑归纳,是未经加工的原始素材。数据可以是连续的值,如声音、图像,这被称为模拟数据。数据也可以是离散的,如符号、文字,这被称为数字数据。而且,数据可以是有意义的符号、文字、数字符号的组合、图形、图像、视频、音频等,也可以是物理符号或这些物理符号的组合。
好像有点多了。。。

我总结成通俗易懂的话:只要能展示在电脑上的一切资源,都是数据。
我们平常使用微信,淘宝,QQ等等各种APP,这些都产生了各种数据,所以数据是无时无刻都会产生的。
接下来就回到正题:什么是大数据?
还是来一段官方的解释:
大数据(Big Data)是指规模庞大、复杂度高、增长速度快且难以使用传统数据管理和处理技术进行捕获、管理和处理的数据集合。
大数据通常具有以下特征:
- 大容量:大数据集合的规模很大,通常超出了单个计算机或传统数据库系统的存储和处理能力。这些数据可以是结构化数据(如关系型数据库中的表格数据),也可以是非结构化数据(如文本、图像、音频、视频等)。
- 多样性:大数据集合通常由多种类型和格式的数据组成。它们可能来自各种来源,包括传感器数据、社交媒体数据、日志文件、电子邮件、金融交易记录等。这些数据可能以结构化形式存在,也可能是半结构化或非结构化的。
- 高速度:大数据集合的生成速度非常快,需要能够实时或准实时地处理和分析数据。例如,物联网设备、移动应用程序和社交媒体等可以在短时间内产生大量数据。
- 价值潜力:大数据中蕴含着宝贵的信息和见解。通过对大数据进行分析,可以揭示隐藏的模式、趋势和关联关系,从而支持决策制定、市场营销、风险管理、产品优化等业务活动。
好像话更多了。。。
我们直接将其整合为一句:大数据是一种在获取、存储、管理、分析等方面大大超出了传统数据库软件工具能力范围的数据集合。
看得出,大数据就是数据超多!存储超快!操作超快!
我们现在知道了大数据的概念,现在我们需要知道大数据是如何使用的。
大数据的运用
在单台电脑的情况下,能够处理的数据是极其有限的,对于个人来说完全足够了。

但是对于公司企业来说,无论是数据规模还是数据处理速度来说,这些都是远远不够的,所以最简单粗暴的方式就是,多增加几台机器,共同处理任务。
多增加几台机器的方式确实解决了单台机器的数据量低的问题,但是还有一个问题没有解决,那就是速度问题,因为每个机器个跑个的,完全没有组织性,效率问题一直得不到解决,所以我们还**需要其他的东西来完成多台机器之间的协调,这就是Hadoop**。
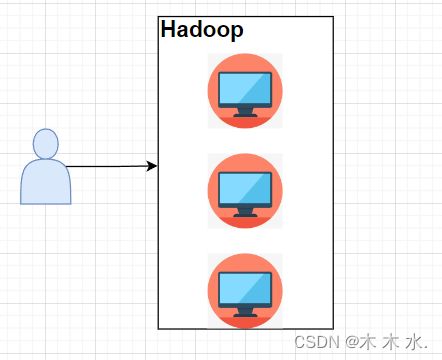
有了Hadoop,接下来用户的操作就仅仅在Hadoop操作界面就可以了,对于底层的其他细节,由Hadoop集群自己进行协调,同时存在Yarn这类的组件,提高分布式处理数据的能力等等。
接下来我们就介绍一下什么是Hadoop,Hadoop的组件有哪些?
Hadoop入门
Hadoop 是一个开源的分布式计算框架,用于存储和处理大规模数据集。它可以快速、可靠地处理大数据,并且具有高容错性。

这里讲个小故事,Hadoop的名字由来。
Hadoop图标旁边的小象其实是创始人 Doug Cutting 的儿子的玩具小象,该小象就叫作 Hadoop。
Doug Cutting 最初开发了一个称为 Nutch 的网络搜索引擎项目,而 Hadoop 则是作为 Nutch 项目的基础技术组件被开发出来的。当时,Doug Cutting 面临着处理大规模数据的需求,并需要一个可靠的、扩展性强的系统来处理这些数据,并且能够容忍硬件故障。因此,他开发了 Hadoop 分布式文件系统(HDFS)和 Hadoop MapReduce 框架,作为解决方案。
在选择一个名称时,Doug Cutting 决定以他儿子的玩具小象命名,意在表达一种可爱、有趣、可靠的形象,并且简单易记。因此,他将项目命名为 Hadoop,并在2006年将其作为开源项目发布。
Hadoop框架下包含着许多的组件,其中核心组件就三个:
-
Hadoop 分布式文件系统:
HDFS(Hadoop Distributed File System,HDFS)是 Hadoop 的分布式文件系统,设计用于存储超大规模数据集。它能够将数据拆分成多个块并分布在集群中的多个节点上进行存储,以提供高吞吐量和容错性。 -
Hadoop Yarn:
Hadoop Yarn(Yet Another Resource Negotiator)是 Hadoop 的集群资源管理系统。它负责集群中资源的分配和管理,以便更好地执行并行计算任务。Yarn 可以有效地管理集群中的计算资源,为不同的应用程序提供资源,并监控其执行情况。 -
Hadoop MapReduce:
Hadoop MapReduce是 Hadoop 的计算模型和编程框架。它用于将大数据集切分成小的数据块,并将这些数据块分发到集群中的多个节点上进行并行处理。MapReduce 模型由两个阶段组成:Map 阶段和 Reduce 阶段,用户可以根据需要自定义这两个阶段的操作逻辑。
除了上述核心组件,Hadoop 生态系统还包含了许多其他组件和工具,如:
- Hive:用于在 Hadoop 上执行类似于 SQL 的查询和分析的数据仓库工具。
- Pig:用于数据流转和分析的高层次脚本语言和运行环境。
- HBase:一个分布式、可扩展的 NoSQL 数据库,用于实时读写大量结构化数据。
- Spark:由 Apache 开发的快速、通用的集群计算系统,提供了更强大的内存计算能力和丰富的数据处理库。
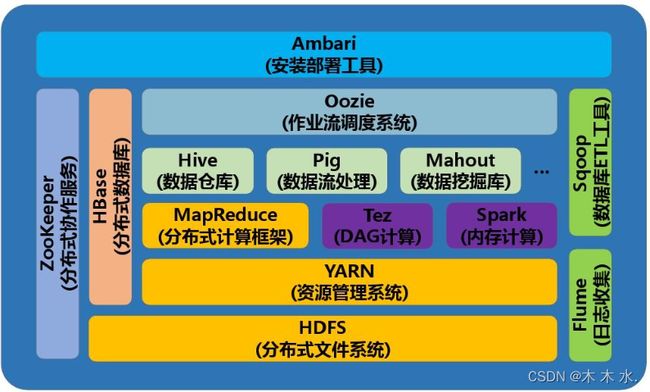
现在看着是不是很陌生呀,没关系的,接下来我们会渐渐深入学习Hadoop体系的每一个组件,成为大佬的路程是一步一步走完的。