【DETR】
https://tianfeng.space/
前言
论文 代码
DETR(Data-efficient Image Transformer)是一种用于目标检测任务的深度学习模型。它与传统的目标检测方法不同,采用了Transformer架构,将目标检测问题转化为一个序列到序列的问题。以下是DETR模型的一些关键特点:
-
Transformer架构: DETR采用了Transformer架构,这是一种用于自然语言处理的架构,但在DETR中被用于图像处理。这种架构允许模型同时处理整个图像,而不是传统的滑动窗口或区域提议方法。
-
序列到序列:DETR将目标检测问题建模为一个序列到序列的问题,其中输入序列是图像的嵌入表示,输出序列是目标的嵌入表示。这种方法允许模型根据图像上的所有信息来预测目标。
-
位置嵌入: DETR引入了位置嵌入,用于指示目标在图像中的位置。这些位置嵌入与目标的嵌入结合起来,帮助模型预测目标的位置。
-
多头注意力: 模型使用多头自注意力机制,允许它关注不同位置的图像信息以预测目标的位置和类别。
-
无需锚框:与传统的目标检测方法不同,DETR不需要使用锚框(anchor boxes)或区域提议网络(Region Proposal Network)。它直接从输入图像中x生成目标框,这使得模型更简洁和易于训练。
框架解读
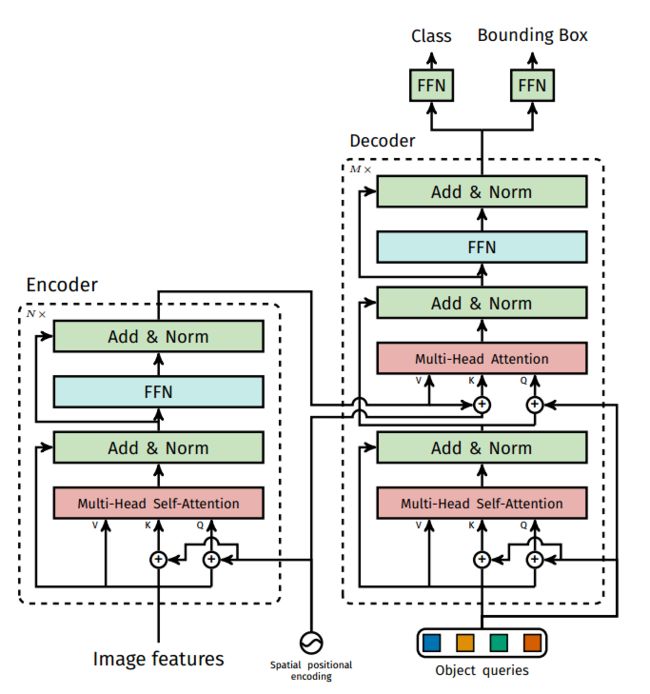
基本思想
使用ResNet作为backbone提取图片特征,同时会使用一个1*1的卷积进行降维。因为transformer的编码器模块只处理序列输入,所以后续还需要把CNN特征展开为一个序列。
先来个CNN得到各Patch作为输入,再套transformer做编码和解码编码路子跟VIT基本一样,重在在解码,直接预测100个坐标框。CNN 的特征提取部分没有什么可以说的,目标检测的图一般比较大,那么直接上 Transformer 计算上吃不消,所以先用 CNN 进行特征提取并缩减尺寸,再使用 Transformer 是常规操作。
DETR使用的典型值是C = 2048和H,W = H0 / 32,W0 / 32;C=2048 是每个 token 的维度,还是比较大,所以先经过一个 1 × 1 的卷积进行降维,然后再输入 Transformer Encoder 。此时自注意力机制在特征图上进行全局分析,因为最后一个特征图对于大物体比较友好,那么在上面进行 Self-Attention 会便于网络更好的提取不同位置不同大物体之间的相互关系的联系,然后位置编码是被每一个 Multi-Head Self-Attention 前都加入了的。
将ResNet提取的特征图转成特征序列后,图像就失去了像素的空间分布信息,所以Transformer就引入位置编码。把特征序列和位置编码序列拼接起来,作为编码起的输入。

整体网络架构
DETR 分为四个部分,首先是一个 CNN 的 backbone,Transformer 的 Encoder,Transformer 的 Decoder,最后的预测层 FFN。
DETR使用传统的CNN主干网络来学习输入图像的2D表示。该模型对其进行扁平序列化(大的卷积核和步长使其变成一个个patch,并行展开输入Encoder),并在将其传递到转换器编码器之前用位置编码对其进行补充。然后,转换器解码器将少量固定数量的学习位置嵌入作为输入,我们称之为对象查询,并额外处理编码器输出。我们将解码器的每个输出嵌入传递到共享前馈网络(FFN),该网络预测检测(类和边界框)或“无对象”类。(论文预测100框)
object queries是核心,让它学会怎么从原始特征找到是物体的位置
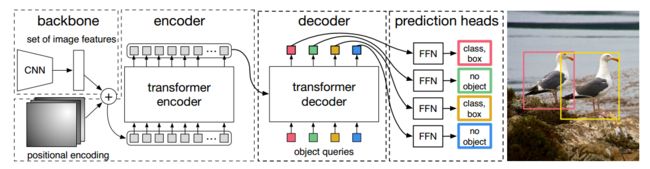
Encoder完成的任务
得到各个目标的注意力结果,准备好特征,等解码器来选秀

Decoder
输出层就是100个object queries预测编码器,解码器首先随机初始化object queries(0+位置编码,),先自己self attention学习一下;然后用解码器学到的q去查询编码的KV,通过多层让其学习如何利用输入特征。
输出的匹配
GT只有两个,但是预测的恒为100个,怎么匹配呢?匈牙利匹配完成,按照LOSS最小的组合,剩下98个都是背景。集合到集合的预测看起来非常直接,但是在训练的过程就会遇到一个问题,就是如何把预测出来的100个框与ground truth做匹配,然后得到损失。DETR就非常暴力,直接利用pd(predicttion)与gt(ground truth)按照最小权重做一对一匹配,剩余的框全部当做背景处理。
此权重的构成:
分类损失:这里分类损失是由直接softmax的值取出来的。举个例子:预测100个目标框,每个目标框有92个候选类别,经softmax输出后有out,shape=(100,92)。根据groundtruth的target标签假设(有20个),根据这些类别值直接作为索引值筛选出每个预测目标框的类别以及概率,最后剩下了=(100,20)的softmax的值。也就是说只把图片内存在的类别作为交叉熵损失的选择,然后用softmax来作为损失,由于1是常数,直接进行了一个省略。目标框的损失是将预测的目标框,与gt中每个目标框做L1损失,假设gt有20个目标框,就会产生200*20个损失值。同上,求IOU并取负做损失,损失加权求和作为总损失。
然后利用匈牙利匹配出目标框,将预测框的索引值和对应位置的gt目标狂的索引配对输出。其余的就直接抛弃。
该算法实现预测值与真值之间最优的匹配,并且是一一对应,不会多个预测值匹配到同一个ground truth上,这样就无需NMS后处理了。假设预测结果是N个,那么标注信息也要是N个,假设N=6,但真实标签2个,剩下的4个(标注如果小于N就用无物体信息去填充)标注信息都是用无类别来填充。
注意力起到的作用
这个注意力挺有意思,能不被遮挡,照样可以学出来(注意颜色)
细节
decoder中的位置肯定最重要了,这个得学习才行;每层都预测(Auxiliary);100个预测框之间可以相互通信,训练用了多个卡,
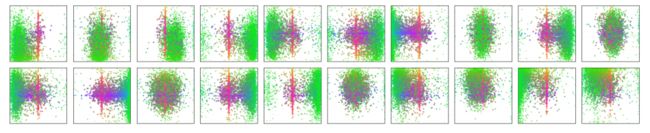
100个框各自要干啥
论文中可视化了其中20个,绿色是小物体,红蓝是大物体基本描述了各个位置都需要关注,而且它们还是各不相同的
额外证明
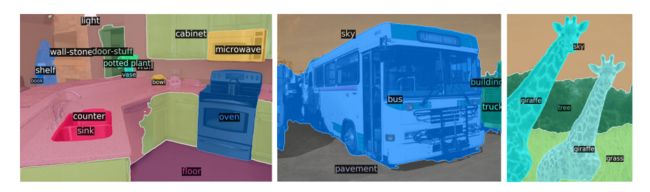
transformer不仅在检测领域好使,分割里照样行(感觉就像是让一群人去做分割,每个人做其中一块,最后合并一起)

简单使用
环境配置
下载代码
git clone https://github.com/facebookresearch/detr.git
下载pytorch和torchvision必须的
conda install -c pytorch pytorch torchvision
安装scipy和pycocotools
conda install cython scipy
pip install -U 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'
数据集下载
https://cocodataset.org/#download
也提供网盘链接:https://pan.baidu.com/s/1RM_9Eip_-94eJtL23fEM5Q
提取码:icnt
分别为标注文件,训练集和测试集
path/to/coco/
annotations/ # annotation json files
train2017/ # train images
val2017/ # val images
模型训练
python -m torch.distributed.launch --nproc_per_node=8 --use_env main.py --coco_path /path/to/coco
模型评估
python main.py --batch_size 2 --no_aux_loss --eval --resume https://dl.fbaipublicfiles.com/detr/detr-r50-e632da11.pth --coco_path /path/to/coco