【OpenCV/C++】KNN算法识别数字的实现原理与代码详解
KNN算法识别数字
-
- 一、KNN原理
-
-
- 1.1 KNN原理介绍
- 1.2 KNN的关键参数
-
- 二、KNN算法识别手写数字
-
-
- 2.1 训练过程代码详解
- 2.2 预测分类的实现过程
-
- 三、KNN算法识别印刷数字
-
-
- 2.1 训练过程
-
一、KNN原理
1.1 KNN原理介绍
KNN算法,即K最近邻算法,顾名思义其原理是当要预测一个新的值x的时候,根据离他最近的K个点大多属于什么类别来判断x属于哪个类别。
zzzzMing -大数据技术-深入浅出KNN算法
K=3时,x最近的三个图形包括两个三角形、一个圆形,因为2>1,所以x更有可能是三角形。
K=5时,x最近的五个图形包括两个三角形、三个圆形,因为3>2,所以x更有可能是圆形。
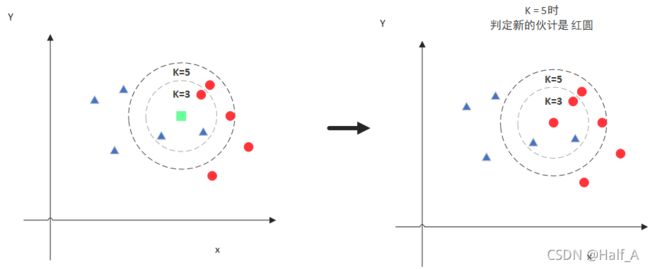
同理类比到图像识别方面,使用KNN算法前我们需要有大量的训练样本,并且知道每个样本所属的类别。(例如大量的数字图片,并且知道每个图片代表数字几)。当我们要识别数字时,本质上就是在训练样本中找与要识别的图像最接近的K个样本,然后统计出K个样本中出现最多的数字是哪个,那就是要识别的数字。
1.2 KNN的关键参数
① 寻找多少最近邻样本 - K的选择
K值决定着图像识别过程中,寻找的最近邻的图像个数,由上面的例子可以看出,选择不同的K,识别结果可能完全不同,因此K值是KNN算法中最关键的参数之一,它直接影响着模型的性能。
K值如果过小,那么此时识别结果就会很受样本质量的影响。如果训练样本存在某些错误或噪音,而寻找最近邻样本时正好找到了这些项,那么识别结果一定是错的,而增大K值,多寻找样本,会有效降低样本噪音的影响。
K值如果过大,假设K值等于训练样本数,那么无论要识别的图片是什么,识别结果都是样本中最多的那个类别。
那么K值应该如何选择呢?理论上来说K值与识别准确率的关系是存在一个极值的,可以通过多次实验,根据结果选择一个最好的K值。(例如K=3时准确率72;K=5时准确率91;K=8时准确率81,那么选择K=5会是一个相对较好的选择)
② 如何判断“接近”程度 - 距离的计算
距离计算函数一般使用曼哈顿距离或欧氏距离。
曼哈顿距离就是样本特征每一个维度的差值之合。(对应于图像,就是两图像每个像素做差)
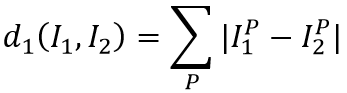
欧式距离是样本特征在每一个维度上差值的平方和的根。
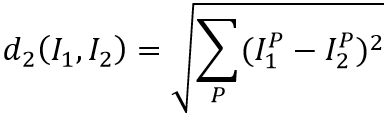
二、KNN算法识别手写数字
KNN算法识别手写数字的源程序 - 点此下载
注:只包括KNN算法部分,关于图片ROI区域截取请参考《一文详解opencv摄像头数字识别》
2.1 训练过程代码详解
首先,我们要获得训练样本。OpenCV安装目录中给我们提供了手写数字的样本图片opencv\sources\samples\data\digits.png。这个图片中每个数字有5x100个样本,并且每个数字所占的像素均为20x20,因此可以从这个图片中提取我们需要的训练样本。
我们按列裁剪样本图片,每裁剪一个样本,就将其添加到data中,并同时将对应的数字添加到lable中。这样一来,我们就获得了图片和数字一一对应的data和lable数据。
Mat img = imread("E:/Program/OpenCV/vcworkspaces/knn_test/images/data/digits.png");
Mat gray;
cvtColor(img, gray, COLOR_BGR2GRAY);
int b = 20;
int m = gray.rows / b; //原图为1000*2000
int n = gray.cols / b; //裁剪为5000个20*20的小图块
Mat data, labels; //特征矩阵
for (int i = 0; i < n; i++)
{
int offsetCol = i * b; //列上的偏移量
for (int j = 0; j < m; j++)
{
int offsetRow = j * b; //行上的偏移量
//截取20*20的小块
Mat tmp;
gray(Range(offsetRow, offsetRow + b), Range(offsetCol, offsetCol + b)).copyTo(tmp);
//reshape 0:通道不变 其他数字,表示要设置的通道数
//reshape 表示矩阵行数,如果设置为0,则表示保持原有行数不变,如果设置为其他数字,表示要设置的行数
data.push_back(tmp.reshape(0, 1)); //序列化后放入特征矩阵
labels.push_back((int)j / 5); //对应的标注
}
}
利用这个训练样本就可以创建KNN模型了。
如果需要测试模型的识别准确度,可以从刚才获得的5000个样本中,选择前3000个样本作为训练数据,后2000个作为测试数据。用KNN模型计算测试数据的在样本中的识别正确情况。
data.convertTo(data, CV_32F); //uchar型转换为cv_32f
int samplesNum = data.rows;
int trainNum = 500;
Mat trainData, trainLabels;
trainData = data(Range(0, trainNum), Range::all()); //前3000个样本为训练数据
trainLabels = labels(Range(0, trainNum), Range::all());
//使用KNN算法
int K = 5;
Ptr<TrainData> tData = TrainData::create(trainData, ROW_SAMPLE, trainLabels);
model = KNearest::create();
model->setDefaultK(K);
model->setIsClassifier(true);
model->train(tData);
//预测分类
double train_hr = 0, test_hr = 0;
Mat response;
// compute prediction error on train and test data
for (int i = 0; i < samplesNum; i++)
{
Mat sample = data.row(i);
float r = model->predict(sample); //对所有行进行预测
//预测结果与原结果相比,相等为1,不等为0
r = std::abs(r - labels.at<int>(i)) <= FLT_EPSILON ? 1.f : 0.f;
if (i < trainNum)
train_hr += r; //累积正确数
else
test_hr += r;
}
test_hr /= samplesNum - trainNum;
train_hr = trainNum > 0 ? train_hr / trainNum : 1.;
printf("accuracy: train = %.1f%%, test = %.1f%%\n",
train_hr * 100., test_hr * 100.);
2.2 预测分类的实现过程
训练样本制作完毕后,预测分类就非常简单了,将要识别的图像读取进来,进行二值化处理,然后调整大小到与样本图片一样大(20x20)。将处理好的图片push到test中,就可以直接使用刚才创建的KNN模型进行预测了。
//预测分类
Mat img = imread("E:/Program/OpenCV/vcworkspaces/knn_test/images/test/4.jpg");
cvtColor(img, img, COLOR_BGR2GRAY);
//threshold(src, src, 0, 255, CV_THRESH_OTSU);
imshow("Image", img);
resize(img, img, Size(20, 20));
Mat test;
test.push_back(img.reshape(0, 1));
test.convertTo(test, CV_32F);
int result = model->predict(test);
cout << "识别数字:" << result << endl;
三、KNN算法识别印刷数字
KNN算法识别印刷数字的源程序 -点此下载
注:只包括KNN算法部分,关于图片ROI区域截取请参考《一文详解opencv摄像头数字识别》
2.1 训练过程
识别印刷体数字与识别手写数字的原理相同,只是训练样本有区别。这里我制作了1000张不同字体的训练样本,加载方式例如:
//训练结果不存在,重新训练
int add_image_num = 1000; //扩充训练数据的文件夹个数
int filenum = 0;
Mat data, labels; //特征矩阵
for (int i = 0; i < add_image_num; i++)
{
Mat addimg = imread("E:/Program/OpenCV/vcworkspaces/knn_test/images/data/" + to_string(filenum) + ".jpg");
cvtColor(addimg, addimg, COLOR_BGR2GRAY);
//threshold(src, src, 0, 255, CV_THRESH_OTSU);
resize(addimg, addimg, Size(20, 20));
data.push_back(addimg.reshape(0, 1)); //序列化后放入特征矩阵
labels.push_back((int)((filenum++) % 10)); //对应的标注
}
训练样本加载完毕后,使用与上面相同的方式创建KNN模型,然后进行预测识别即可。