Understanding and Building an Object Detection Model from Scratch in Python翻译
原文链接:https://www.analyticsvidhya.com/blog/2018/06/understanding-building-object-detection-model-python/
介绍:
当我们看到一幅图像时,我们的大脑会立即识别其中包含的物体。另一方面,机器识别这些物体需要大量的时间和训练数据。但是随着硬件和深度学习的发展,计算机视觉领域变得更加简单和直观。
以下面的图片为例。该系统能够以极高的精度识别图像中的不同物体。
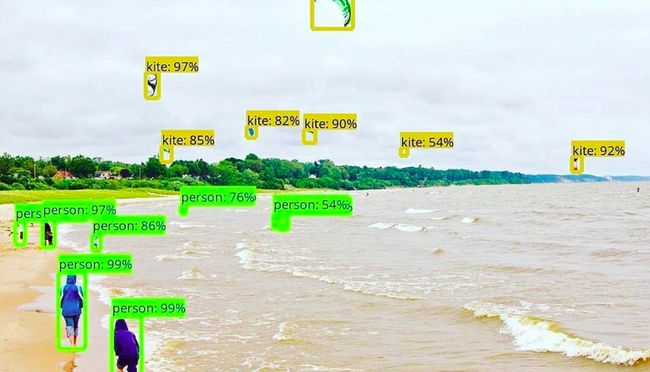 目标检测技术在各个不同的行业得到了迅速的应用。它帮助自动驾驶汽车安全行驶,在拥挤的地方探测暴力行为,协助运动队分析和完成报告,确保制造过程中零件的质量控制,以及许多其他事。而这些只是物体检测技术所能做的皮毛而已!
目标检测技术在各个不同的行业得到了迅速的应用。它帮助自动驾驶汽车安全行驶,在拥挤的地方探测暴力行为,协助运动队分析和完成报告,确保制造过程中零件的质量控制,以及许多其他事。而这些只是物体检测技术所能做的皮毛而已!
在这篇文章中,我们将了解什么是目标检测,并了解几个不同的方法可以被用来解决这个领域的问题。然后我们将深入研究用Python构建我们自己的目标检测系统。在本文的最后,您将有足够的知识来独自应对不同的目标检测挑战!
注意:本教程假设你了解深度学习的基础知识,并且以前解决过简单的图像处理问题。如果你还没有或需要复习,我建议你先阅读以下文章:
- Fundamentals of Deep Learning – Starting with Artificial Neural Network
翻译:https://blog.csdn.net/Stella_CYT/article/details/114254771 - Deep Learning for Computer Vision – Introduction to Convolution Neural Networks
翻译:https://blog.csdn.net/Stella_CYT/article/details/114259231 - Tutorial: Optimizing Neural Networks using Keras (with Image recognition case study)
目录
1.什么是目标检测
2.可以用来解决目标检测问题的不同方法
3.获取技术:如何使用ImageAI库构建目标检测模型
1.什么是目标检测?
在我们开始构建一个先进的模型之前,让我们首先尝试理解什么是目标检测。让我们(假设)为自动驾驶汽车建立一个行人检测系统。假设你的车捕捉到了一个像下面这样的图像。你如何描述这张照片?
 这张照片基本上描绘了我们的车在一个广场附近,有几个人在我们的车前面过马路。由于交通标志并不清晰可见,汽车的行人检测系统应该准确识别出人们在哪里行走,这样我们就可以避开他们。
这张照片基本上描绘了我们的车在一个广场附近,有几个人在我们的车前面过马路。由于交通标志并不清晰可见,汽车的行人检测系统应该准确识别出人们在哪里行走,这样我们就可以避开他们。
那么,汽车系统能做些什么来确保这一点呢?它所能做的是在这些人周围创建一个边界框,这样系统就可以精确定位这些人在图像中的位置,然后相应地决定走哪条路,以避免任何意外。
 我们在目标识别方面的目标有两个方面:
我们在目标识别方面的目标有两个方面:
识别图像中的所有对象及其位置
过滤出我们注意的对象
2.可以用来解决目标检测问题的不同方法
既然我们知道问题是什么,那么有什么可能的方法来解决它呢?在本节中,我们将介绍一些可用于检测图像中目标的技术。我们将从最简单的方法开始,并从那里找到我们的解决方案。
方法1:直接方法(分而治之)
我们可以使用的最简单的方法就是,把图像分为四部分。
左上部分

右上部分

左下部分

右下部分

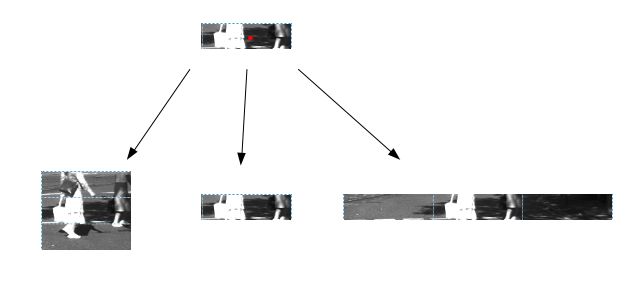
现在,下一步是将这些部分中的每一部分输入到图像分类器中。这将为我们提供一个输出,即图像的该部分是否有行人。如果是,则在原始图像中标记该部分。输出近似下图:
 对于我们的初次尝试来说,这是一个很好的方法,但我们正在寻找一个更准确和精确的系统。它需要识别整个对象(或者在本例中是一个人),因为只定位对象的一部分可能会导致灾难性的结果。
对于我们的初次尝试来说,这是一个很好的方法,但我们正在寻找一个更准确和精确的系统。它需要识别整个对象(或者在本例中是一个人),因为只定位对象的一部分可能会导致灾难性的结果。
方法2:增加分割数量
之前的系统运行得很好,但我们还能做什么呢?我们可以通过成倍增加我们输入到系统中的标记框的数量来改进它。我们的输出应该是这样的:
 这各方法有利有弊。当然,我们的解决方案似乎比之前的直接方法好一点,但是它充满了大量估计同一事物的边界框。这是一个问题,我们需要一个更结构化的方法来解决我们的问题。
这各方法有利有弊。当然,我们的解决方案似乎比之前的直接方法好一点,但是它充满了大量估计同一事物的边界框。这是一个问题,我们需要一个更结构化的方法来解决我们的问题。
方法3:采取结构化的分割
为了以更结构化的方式构建我们的目标检测系统,我们可以遵循以下步骤:
步骤1:将图像分成10×10的网格,如下所示:

步骤2:定义每个块状区域的质心
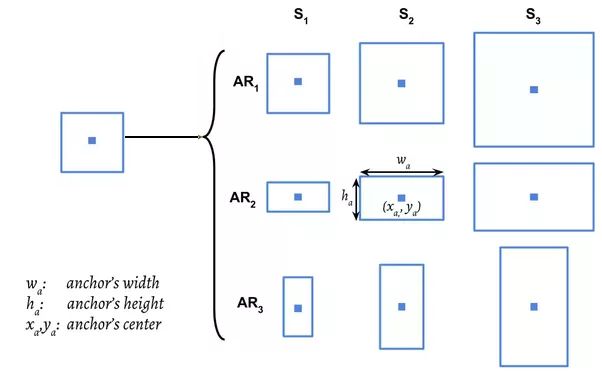
步骤3:对于每个质心,取三个不同宽高比的区域:
 步骤4:把所有组合成的区域放入图像分类器,得到预测结果
步骤4:把所有组合成的区域放入图像分类器,得到预测结果
那么最终的输出是什么样子的呢?当然更具条理–请看下面:

但我们可以进一步改进。继续读下去,另一种方法会产生更好的结果。
方法4:更高的效率
我们看到的前一种方法在很大程度上是可以接受的,但是我们可以构建一个比这更高效的系统。你能建议怎么做吗?在我的脑海里,我可以提出一个优化。如果我们考虑方法3,我们可以做两件事来改进我们的模型。
1.增加网格数量:用20x20代替10x10的网格

2.提取更多不同宽高比的区域:
在这里,我们可以从一个质心取下9个形状,即3个不同高度的正方形块和6个不同高度的垂直和水平矩形块。这将为我们提供不同的宽高比。
这也有利有弊。当然,这两种方法都将帮助我们进入更精细的层次。但它会产生大量必须通过图像分类模型的区域。
我们所能做的是,选择性地提取区域,而非把所有区域组合都输入图像分类器。例如,我们可以构建一个中间分类器,该分类器尝试预测该区域是否实际具有背景,或者是否可能包含对象。这将成倍地减少我们的图像分类模型必须看到的区域块。
我们可以做的另一个优化是减少提供相同信息的预测。我们再来看看方法3的输出:

如你所见,两个边界框预测基本上是同一个人的。我们可以选择其中任何一个。因此,为了做出预测,我们考虑所有提供相同信息的边界框,然后选择其中最有可能探测到某个人的框。
到目前为止,所有这些优化都给了我们相当不错的预测。我们手上几乎都有牌,但你能猜出少了什么吗?当然是深度学习!
方法5:使用深度学习进行特征选择并构建端到端方法
深度学习在目标检测领域有着巨大的潜力。你觉得我们应该在哪里以及如何利用它解决我们的问题呢?我在下面列出了几种方法:
1.我们不需要从原始图像中提取区域,而是通过神经网络对原始图像进行降维。
2.我们也可以使用神经网络来选取待预测的区域。
3.我们可以加强深度学习算法,使预测尽可能接近原始的边界框。这将确保算法提供更紧密和更精细的边界框预测。
现在,我们不需要训练不同的神经网络来解决每个问题,我们可以采用一个单独的深层神经网络模型来尝试解决所有的问题。这样做的好处是,一个神经网络的每个较小的组成部分将有助于优化同一个神经网络的其他部分。这将有助于我们共同训练整个深度模型。
我们的输出将为我们提供迄今为止看到的所有方法中最好的性能,与下图有些类似。在下一节中,我们将看到如何使用Python创建这个深度神经网络。

3.获取技术:如何使用ImageAI库构建目标检测模型
既然我们知道了什么是目标检测以及解决问题的最佳方法,那就让我们来构建我们自己的目标检测系统吧!我们将使用ImageAI,一个python库,它支持用于计算机视觉任务的最先进的机器学习算法。
运行一个目标检测模型来获得预测是相当简单的。我们不必通过复杂的安装脚本,就可以开始了。我们甚至不需要GPU来生成预测!我们将使用ImageAI库来获得我们在方法5中看到的输出预测。我强烈建议你使用下面的代码,因为这将使你从本节中获得最多的知识。
请注意,你需要在创建对象检测模型之前安装系统。一旦在本地系统中安装了Anaconda,就可以开始以下步骤了。
步骤1:
使用python3.6创建Anaconda环境。
conda create -n retinanet python=3.6 anaconda
步骤2:
激活环境并安装必要的软件包。
source activate retinanet
conda install tensorflow numpy scipy opencv pillow matplotlib h5py keras
步骤3:
安装ImageAI
pip install https://github.com/OlafenwaMoses/ImageAI/releases/download/2.0.1/imageai-2.0.1-py3-none-any.whl
步骤4:
现在下载生成预测所需的预训练模型。这个模型是基于RetinaNet的(后面的一篇文章的主题)。点击链接下载-https://github.com/OlafenwaMoses/ImageAI/releases/download/1.0/resnet50_coco_best_v2.0.1.h5
步骤5:
将下载的文件复制到当前工作文件夹。
步骤6:
从这个链接https://cdn.analyticsvidhya.com/wp-content/uploads/2018/06/I1_2009_09_08_drive_0012_001351-768x223.png下载图片。将图像命名为image.png。
步骤7:
打开jupiter notebook(在终端输入jupyter notebook)并运行以下代码:
from imageai.Detection import ObjectDetection
import os
execution_path = os.getcwd()
detector = ObjectDetection()
detector.setModelTypeAsRetinaNet()
detector.setModelPath( os.path.join(execution_path , "resnet50_coco_best_v2.0.1.h5"))
detector.loadModel()
custom_objects = detector.CustomObjects(person=True, car=False)
detections = detector.detectCustomObjectsFromImage(input_image=os.path.join(execution_path , "image.png"), output_image_path=os.path.join(execution_path , "image_new.png"), custom_objects=custom_objects, minimum_percentage_probability=65)
for eachObject in detections:
print(eachObject["name"] + " : " + eachObject["percentage_probability"] )
print("--------------------------------")
这将创建一个名为image_new.png的修改过的图像文件,其中包含图像的边界框。
步骤8:
用以下代码打印图像:
from IPython.display import Image
Image("image_new.png")
总结
在本文中,我们学习了什么是目标检测,以及创建目标检测模型背后的逻辑。我们还了解了如何使用ImageAI库构建用于行人检测的目标检测模型。
只需稍微调整一下代码,就可以轻松地转换模型以解决自己的目标检测难题。如果你确实使用上述方法解决了此类问题,请在下面的评论中告诉我!