摘要:在本文中,我们将讨论为深度学习模型搜索最佳超参数集合的动机和策略,并演示如何在FloydHub上来完成任务。学习本文之后,这将会在深度学习工作中为你自动化寻找最佳配置的过程。
与机器学习模型不同,深度学习模型里面充满了各种超参数。而且,并非所有参数都能对模型的学习过程产生同样的贡献。考虑到这种额外的复杂性,在一个多维空间中找到合适的参数变量成为了挑战。幸运的是,我们有不同的策略和工具可以解决搜索问题。
每一位研究人员都希望在现有的资源条件下,找到最佳的模型。通常情况下,他们会在开发的最后阶段尝试一种搜索策略,这可能会有助于改进他们辛辛苦训练出来的模型。
此外,在半自动/全自动深度学习过程中,超参数搜索也是的一个非常重要的阶段。
超参数到底是什么?
让我们从最简单的定义开始,超参数是在构建机器/深度学习模型时可以转动的旋钮。或者这样解释,超参数是开始训练之前,用预先确定的值来手动设置的所有训练变量。
我们应该都会认可Learning Rate和Dropout Rate是超参数。但是模型设计的变量呢?这些变量包括嵌入值、网络层数、激活函数等等,我们应该把这些变量视为超参数吗?
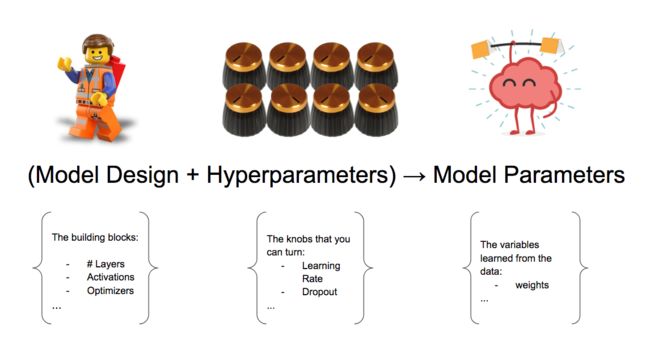
模型设计变量+超参数→模型参数
那么,从训练过程中获得的参数,以及从数据中获得的变量应该如何考虑呢?这被称为模型参数,我们将把它们排除在超参数集之外。
请看下图,举例说明在深度学习模型中变量的分类。
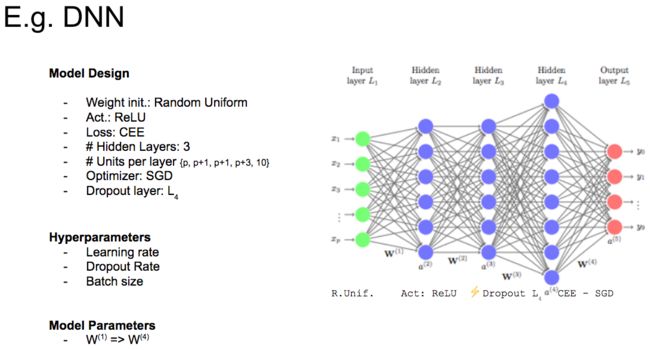
变量分类实例
下一个问题****: ****搜索代价巨大
寻找超参数的最佳配置,面临的挑战是寻找超参数是一个消耗巨大的工作。
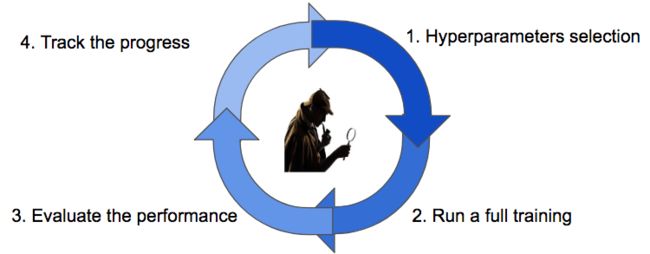
超参数搜索周期
我们从配置的猜测开始,需要等到一个完整的训练结束,来获得对相关指标的实际评估,之后是跟踪搜索过程的进度,最后根据搜索策略,选择新的猜测。
策略讨论
我们有四种主要的策略用于寻找最佳配置。
试错法(Babysitting)
网格搜索(Grid Search)
随机搜索(Random Search)
贝叶斯优化(Bayesian Optimization)
Babysitting
在研究领域,Babysitting也被称为“试错法”。100%手工操作,被大家广泛采用。
流程非常简单:比如学生设计了一个实验后,遵循学习过程的所有步骤(从数据收集到特征图映射的可视化),然后在超参数上依次迭代直到时间终止。

如果你学习过deeplearning.ai的课程,那么你肯定对吴恩达教授的熊猫工作流程很熟悉。
这种方法非常有教育意义。但是,在一个团队或者一个公司里,这种方法并不适用,因为数据科学家的时间是非常宝贵的。
这就给我们提出了一个问题:“有没有更好的方法来利用我们的时间?”
当然有,我们可以通过定义超参数搜索的自动策略来优化时间!
网格搜索
网格搜索,是一种简单尝试所有可能配置的方法。
它的工作流程是这样的:
定义一个N维的网格,其中每一个映射都代表一个超参数,例如,n=(learning_rate, dropout_rate, batch_size)
对于每个维度,定义可能的取值范围: 例如,batch_size = [4, 8, 16, 32, 64, 128, 256]
搜索所有可能的配置,等待结果以建立最佳配置: 例如,C1= (0.1, 0.3, 4) ->acc = 92%,C2= (0.1, 0.35, 4) ->acc = 92.3%···
下图说明了一个简单的二维网格搜索的Dropout Rate和Learning Rate。
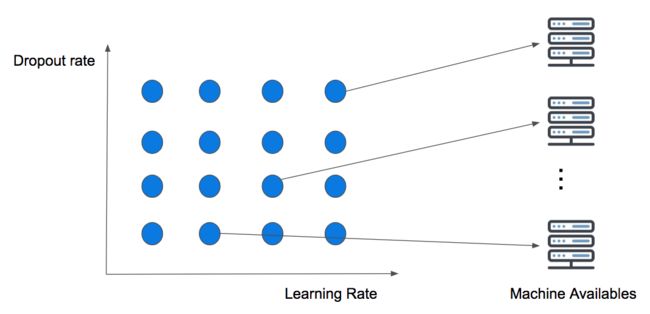
并行执行两个变量的网格搜索
这种策略没有考虑到计算背景,但这意味着可用的计算资源越多,那么同时可以尝试的猜测就会越多。它的痛点被称为维度灾难,意思是我们增加的维度越多,搜索就会变得越困难,最终导致策略失败。
当维度小于或等于4时,常用这种方法。但是在实践中,即使保证最后找到最佳配置,它仍然不可取,而是应该使用随机搜索。
你可以使用FloydHub的Workspace在配置完整的云主机上运行下面的代码(使用Scikit-learn和Keras进行网格搜索):
随机搜索
几年前,Bergstra和Bengio发表了一篇论文,论证了网格搜索的效率低下。
网格搜索和随机搜索之间唯一的区别在于策略周期的第一步:随机搜索在配置空间上随机选择点。
请看下图:
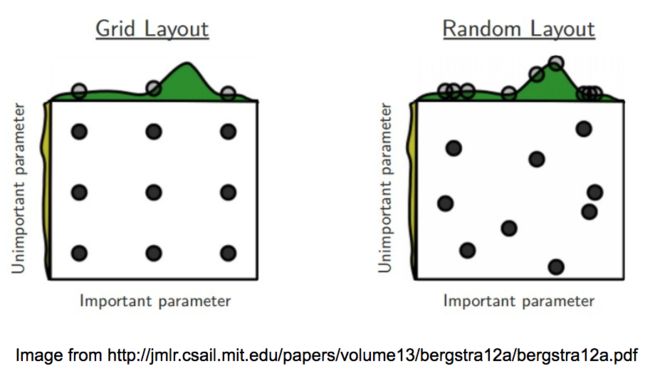
网格搜索vs随机搜索
通过在两个超参数空间上搜索最佳配置来对比这两种方法,并假定一个参数比另一个参数更重要。深度学习模型,如前面所说,实际上包含许多超参数,通常研究者知道哪些对训练影响最大。
在网格搜索中,即使我们已经训练了9个模型,但给每个变量只使用了3个值,然而,在随机搜索中,多次选择相同变量的可能性微乎其微。如果用第二种方法,那么就会给每个变量使用9个不同的值来训练9个模型。
上图中,从每个布局顶部的空间搜索可以看出,使用随机搜索更广泛地研究了超参数空间,这将帮助我们在较少的迭代中找到最佳配置。
总之,如果搜索空间包含3到4个维度,则不要使用网格搜索。相反,使用随机搜索,则会为每个搜索任务提供了一个非常好的基线。

网格搜索与随机搜索的利弊
你可以使FloydHub的Workspace在配置完整的云主机上运行下面的代码:
# Load the dataset X, Y = load_dataset() # Create model for KerasClassifierdefcreate_model(hparams1=dvalue, hparams2=dvalue, ... hparamsn=dvalue): # Model definition ... model = KerasClassifier(build_fn=create_model) # Specify parameters and distributions to sample from hparams1 = randint(1, 100) hparams2 = ['elu', 'relu', ...]... hparamsn = uniform(0, 1) # Prepare the Dict for the Search param_dist =dict(hparams1=hparams1, hparams2=hparams2, ... hparamsn=hparamsn) # Search in action!n_iter_search = 16 # Number of parameter settings that are sampled. random_search =RandomizedSearchCV(estimator=model, param_distributions=param_dist, n_iter=n_iter_search,n_jobs=, cv=, verbose=) random_search.fit(X, Y) # Show the results print("Best: %f using %s" % (random_search.best_score_, random_search.best_params_)) means =random_search.cv_results_['mean_test_score'] stds =random_search.cv_results_['std_test_score'] params = random_search.cv_results_['params']for mean, stdev, param in zip(means, stds, params): print("%f (%f) with: %r" % (mean,stdev, param))
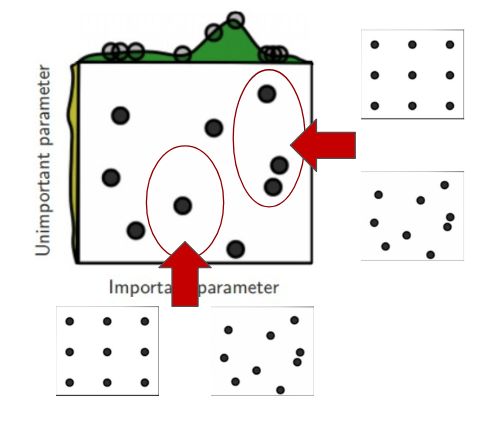
另外,当你为每个维度设置空间时,为每个变量设定正确的尺度是非常重要的。

批量大小和Learning Rate的通用比例空间
例如,使用批量大小的值作为2的幂指数,并且在日志中对Learning Rate进行抽样是很常见的。
放大
另一个很常见的做法是,在一定次数的迭代中,从上面的一个布局开始,然后通过在每个变量范围内进行更密集的采样,甚至使用相同或不同的搜索策略开始新的搜索,从而放大到一个子空间。
还有一个问题:独立猜测。
不幸的是,网格搜索和随机搜索有一个共同的缺点:“每个新的猜测都独立于之前的运行!”
相比之下,Babysitting的优势就显现出来了。Babysitting之所以有效,是因为研究者有能力利用过去的猜测,将其作为改进下一步工作的资源,来有效地推动搜索和实验。
贝叶斯优化
贝叶斯策略建立了一个代理模型,试图从超参数配置中预测我们所关注的度量指标。在每一次的迭代中,我们对代理会变得越来越有信心,新的猜测会带来新的改进,就像其它搜索策略一样,它也会等到耗尽资源的时候终止。

贝叶斯优化工作流程
高斯过程
我们可以将高斯过程定义为学习从超参数配置到度量映射的替代过程。它不仅产生一个预测值,而且还会给我们一个不确定性的范围。
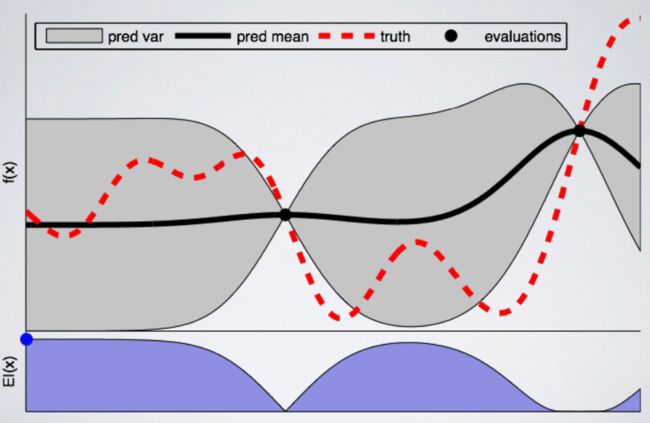
2个点的高斯过程
在上图中,我们在单个变量上(在横轴上)遵循高斯过程优化的第一步,在这个例子中,可以代表Learning Rate或Dropout Rate。在纵轴上,我们将某个度量指标绘制成单个超参数的函数。由于我们正在寻找尽可能低的值,所以可以把它看作是损失函数。
图中黑线代表了训练出来的模型,红线是真实值,也就是我们正在试图学习的函数。黑线代表我们对真实值函数假设的平均值,而灰色区域表明空间中相关的不确定性或方差。正如我们看到的,点周围的不确定性减少了,因为我们对这些点周围的结果非常有信心,因为我们已经在这里训练了模型。而在信息较少的区域,不确定性会增加。
现在已经定义了起点,我们准备好选择下一个变量来训练模型。为此,需要定义一个采集函数,它会告诉我们在哪里采样下一个配置。
在这个例子中,如果我们使用不确定性区域中的配置,则函数将寻找尽可能低的值。上图中的蓝点显示了下一次训练所选择的点。
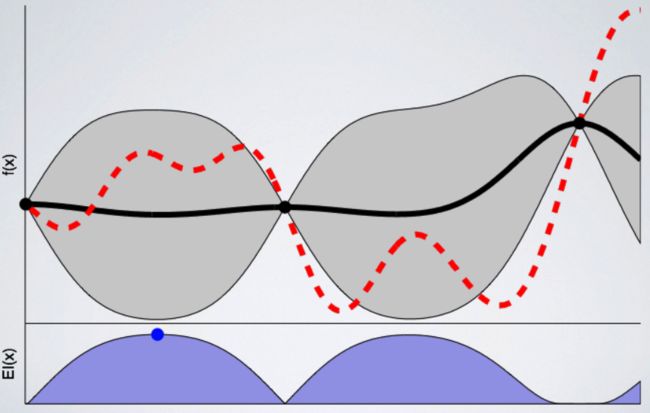
3个点的高斯过程
我们训练的模型越多,代理对下一个采样的点就越有信心。下图是8次训练后的模型:
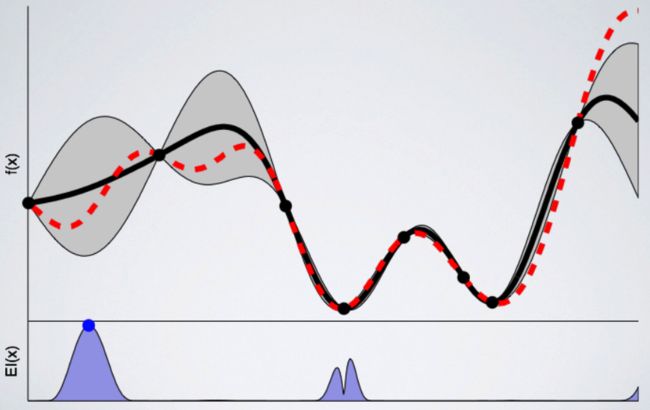
8个点的高斯过程
高斯过程属于一类称为基于序列模型的优化(SMBO)的算法。正如刚刚看到的,这些算法为搜索最佳超参数配置提供了非常好的基准。但是,就像每种工具一样,它们都有缺点:
按照定义,这个过程是循序渐进的;
它只能处理数字参数;
如果训练表现不佳,它不提供任何机制来停止训练;
你可以使用FloydHub的Workspace在配置完整的云主机上运行下面的代码:
下图总结了我们所涉及的内容,了解每个策略的优缺点:
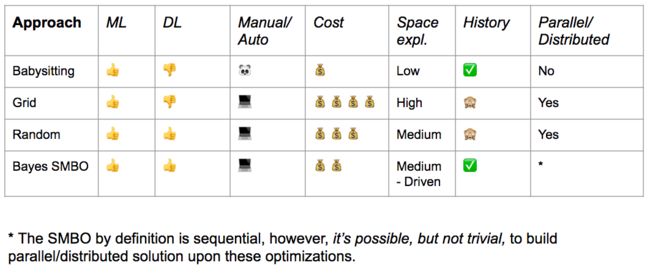
总结
只要资源没有限制,贝叶斯SMBO可能是最好的选择,但还应该考虑建立一个随机搜索的基准。
如果你还处于学习或者初级阶段,那么选择Babysitting。即使从空间搜索的角度来看不切实际,也是一种可行的方法。
如果训练表现不佳,这些策略都不会提供节省资源的机制,只能等到计算结束。
早停的力量

“早停”不仅是一种规则化技术,而且在训练方向不正确时,它会提供防止资源浪费的机制。
下图是最常用的停止标准:
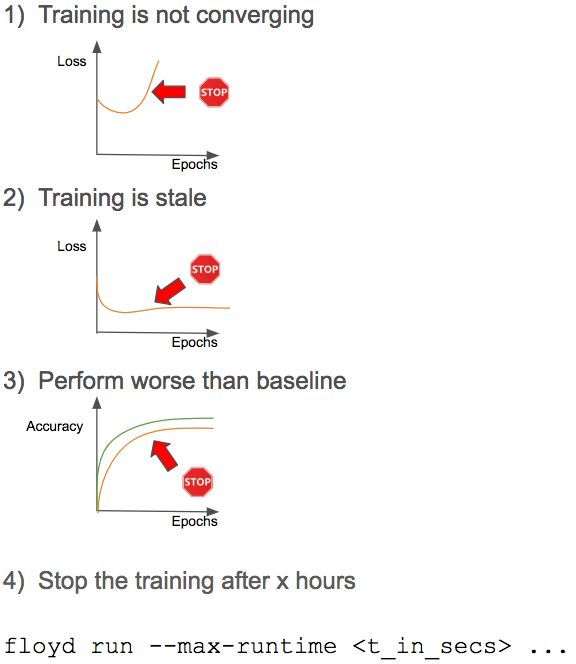
停止标准
前三个标准不用多说,所以大家集中看最后一个标准。
通常情况下,根据实验类别来限定训练时长,这可以对团队内部的资源进行优化。通过这种方式,我们能够分配更多的资源给最有希望的实验。
这些标准可以在Babysitting过程中手动应用,或者通过在最常见框架中提供的钩子/回调组件将这些规则集成到实验中:
Keras提供了一个很好的“早停”功能,甚至更好的回调组件。由于Keras最近被集成在Tensorflow中,你能在Tensorflow代码中使用回调组件;
Tensorflow提供了训练钩子,可能不像Keras回调(或tf.keras API)那么直观,但是它们提供了对执行状态的更多控制;
目前,Pytorch还没有提供回调组件,但是这个功能可能会随着新版本一起发布;
fast.ai库也提供了回调功能,不过目前还没提供任何类型的文档;
Ignite(Pytorch的高级库)提供类似于keras的回调,虽然还在开发阶段;
在FloydHub上管理实验
FloydHub的最大特性之一是,当使用不同的超参数集时能够比较正在训练的模型。
下图显示了FloydHub项目中的任务列表。可以看到,该用户正在使用任务消息,突出显示在这些任务中使用的超参数。
另外,还可以看到每个任务的训练度量指标,并提供了一个快速浏览,以帮助你了解哪些任务表现的最好,以及使用的机器类型和总的训练时间。
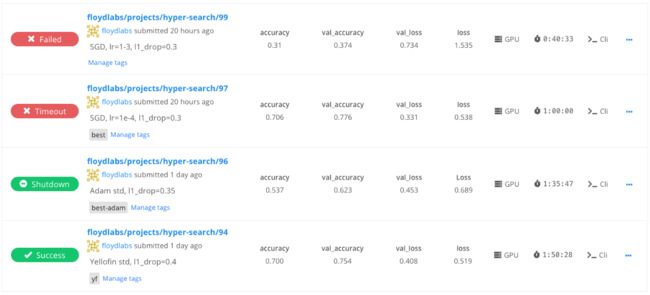
FloydHub的dashboard为你提供了一种简便的方式来比较在超参数搜索中的训练任务,而且是实时更新的。我们的建议是为每一个任务创建一个不同的FloydHub项目,这样,你就可以更容易地组织工作和团队合作。
训练度量指标
如上所述,你可以轻松地在FloydHub上发布与工作相关的训练度量指标。当你在FloydHub的dashboard上查看任务时,可以很容易地为每个指标找到相应的实时图表。这个特性并不是要取代Tensorboard,而是由所选择的超参数配置来突出训练的状态。
例如,如果你正在Babysitting训练的过程中,那么训练度量指标肯定会帮你确定和应用停止标准。
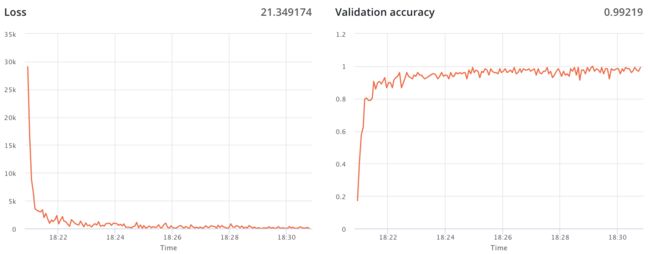
训练度量指标
本文作者:【方向】
阅读原文
本文为云栖社区原创内容,未经允许不得转载。
作者:阿里云云栖社区
链接:https://www.jianshu.com/p/30cfc3c14d9a
來源:
著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。