MPI安装+CentOs6.5多机环境下MPI并行编程+MPI矩阵并行计算(超详细)
目录
- 实验内容
- 一、MPI的下载与安装(三台虚拟机都要配)
- 二、 运行MPI示例程序
-
- 1、配置NFS共享目录安装配置
-
- 1.1 服务端配置
- 1.2 客户端配置
- 2、运行test.cpp
- 3、运行mpi3.c
- 三、矩阵并行计算
实验内容
- 创建多进程,输出进程号和进程数
- 运行多进程并行例子程序
- 编程实现大规模向量/矩阵并行计算
一、MPI的下载与安装(三台虚拟机都要配)
1、在开始安装之前,先检查一下是否已经安装好了相应的编译器。
which gcc
which gfortran
2、安装MPICH之前,首先要在centos6.5上安装c编译器,(进入超级用户)使用指令安装如下:
yum install gcc ///安装GCC编译器(支持C编译)
yum install gcc-c++ ///安装G++编译器(支持C++编译)
3、(返回普通用户)将下载的程序安装包放在主机的某个文件夹下,在这里我新建了一个文件夹/home/lhc/mpi,文件压缩包放在mpi文件下.
使用pwd可以查看当前目录
文件压缩包名为:openmpi-1.6.5.tar.gz
4、新建一个文件夹,用于存放安装路径
mkdir /home/lhc/mpi/mpi-install
5、进入压缩文件夹的存放目录 cd /home/lhc/mpi,解压文件:tar -xzvf openmpi-1.6.5.tar.gz
6、系统配置
cd openmpi-1.6.5#进入解压后的文件夹内
若当前使用得Shell的辅助检索路径中没有设置当前目录,则应使用命令
./configure --prefix=/home/lhc/mpi/mpi-install
注:/home//lhc/mpi/mpi-install是安装路径
此外在配置过程可以指定编译器或选择用rsh或ssh(忽略)。
7.编译:make
8.安装:make install
9.设置路径:
普通用户安装,可以统一添加一条辅助检索路径。方法为修改用户目录下的:~/.bash_profile文件,运行:
vim ~/.bashrc
在适当位置修改和添加:
export PATH=/home/lhc/mpi/mpi-install/bin:$PATH
export INCLUDE=/home/lhc/mpi/mpi-install/include:$INCLUDE
export LD_LIBRARY_PATH=/home/lhc/mpi/mpi-install/lib:$LD_LIBRARY_PATH
保存退出之后 ,使用source这一命令执行一下就把新加的命令执行了。
source ~/.bashrc
我是先使用普通用户安装,然后再进入超级用户配置一下路径:
统一添加一条辅助检索路径。方法为修改vim /etc/profile文件在适当位置修改和添加:
export PATH=/opt/openmpi-1.6.5/bin:$PATH
export INCLUDE=/opt/openmpi-1.6.5/include:$INCLUDE
export LD_LIBRARY_PATH=/opt/openmpi-1.6.5/lib:$LD_LIBRARY_PATH
运行以下命令使修改生效:
source /etc/profile
继续修改:
vim /root/.bashrc
在适当位置修改和添加:
export PATH=/home/lhc/mpi/mpi-install/bin:$PATH
export INCLUDE=/home/lhc/mpi/mpi-install/include:$INCLUDE
export LD_LIBRARY_PATH=/home/lhc/mpi/mpi-install/lib:$LD_LIBRARY_PATH
执行生效:
source /root/.bashrc
10、使用下列命令来查看程序安装路径(普通和超级用户都能检测到才行,如果超级用户不能,那从超级用户上面第六步开始再试试)
which mpicc
which mpiexec
之后,用which来检验下配置的环境变量是否正确。如果显示了其路径,则说明安装顺利完成了。
查看mpi版本:
Mpiexec --version

11.单节点测试
使用mpi编程进入例程文件夹 cd examples
这时候,进入到最开始解压的文件夹中,到解压的文件夹内的examples文件夹中,测试一下hello是否能顺利运行。

编译运行:
一般情况下,管理结点只进行程序编译与提交任务,不建议在管理结点运行计算程序,下面为测试mpich是否安装成功,使用管理节点单个节点运行MPI程序。
mpicc -o hello_c hello_c.c
mpiexec -np 4 ./hello_c

二、 运行MPI示例程序
首先要实现三台虚拟机免密登录,在之前已经实现,这里不做陈述(注意只有root才能免密登录、必要)
1、配置NFS共享目录安装配置
服务端:master(192.168.75.130)
客户端:slave1(192.168.75.129)、slave2(192.168.75.131)
1.1 服务端配置
1、查看是否已经安装nfs(以下配置都在root用户,三台机子都在)
rpm -qa |grep nfs
2、没有安装则进行安装(root用户)
yum -y install nfs-utils rpcbind
3、创建共享目录,一般在根目录下进行创建
mkdir /home/lhc/mpi/cloud
服务端与客户端两者文件位置与名称应一致,方便后续运行mpi
4、配置/etc/exports
vim /etc/exports
输入
/home/lhc/mpi/cloud *(rw,sync,no_root_squash)
可用此行代替以下两行,*代表所有节点,建议使用上面一行
/home/lhc/mpi/cloud 192.168.75.129(rw,sync,no_root_squash)
/home/lhc/mpi/cloud 192.168.75.131(rw,sync,no_root_squash)
no_root_squash:当登录NFS主机使用共享目录的使用者是root时,其权限将被转换成为匿名使用者,通常它的UID与GID都会变成nobody身份。
root_squash;如果登录NFS主机使用共享目录的使用者是root,那么对于这个共享的目录来说,它具有root的权限。
5、重启nfs服务(第一次跳过此行,如遇到错误修改上面文件时,使用此重启服务):
service nfs restart
6、启动服务并设置开机启动
service rpcbind start
service nfs start
chkconfig --level 2345 rpcbind on
chkconfig --level 2345 nfs on
1.2 客户端配置
1、查看是否已经安装nfs
rpm -qa |grep nfs
2、没有安装则进行安装(root用户)
yum -y install nfs-utils rpcbind
3、查看服务端共享目录
showmount -e 192.168.75.130

5、挂载共享目录(需现在相同本地文件夹mpi内创建相同文件夹cloud)到本地,并测试
mount -t nfs 192.168.75.130:/home/lhc/mpi/cloud /home/lhc/mpi/cloud
df -h 查看是否挂载成功

6、设置开机自动挂载
vim /etc/fstab
输入
192.168.75.130:/home/lhc/mpi/cloud /home/lhc/mpi/cloud nfs defaults 0 0
2、运行test.cpp
默认将编译成功的可执行文件(本案例文件名为test.cpp)置于共享文件夹cloud中,移动至该目录下执行:
mpic++ test.cpp -o test
mpirun -np 4 -host slave1,slave2 ./test
其中:
–np 4:表明调用4个进程
–host slave1,slave2:指定两台机器的IP别名
运行vim /etc/hosts,给IP地址赋别名(此文件应该在实现免密登录时就已经设置过此文件)

运行结果:

test.cpp:
#include 3、运行mpi3.c
另一个例子程序,命名为mpi3,程序如下:
#include "mpi.h"
#include 将其保存在共享文件夹cloud中,移动至该目录下执行:
mpicc mpi3.c -o mpi3
mpirun -np 5 ./mpi3
此时是测试单机运行,没有问题:
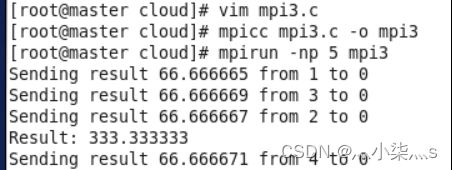
接下来测试分配给多机运行:
用一个hostfile文件来为两节点指定slot数量:
vim hostfile
在打开的新文件里输入:
slave1 slots=5
Slave2 slots=5
保存并退出,执行指定了hostfile的mpirun:
mpirun -host slave1,slave2 --hostfile hostfile -np 10 mpi3
三、矩阵并行计算
mpic++ martrix.cpp -o martrix
mpirun -np 8 -host slave1,slave2 ./martrix 300 200 400
#include