ParNet :NON-DEEP NETWORKS——12层网络
论文地址:https://arxiv.org/pdf/2110.07641.pdf https://arxiv.org/pdf/2110.07641.pdf 代码地址:https://github.com/imankgoyal/NonDeepNetworkshttps://github.com/imankgoyal/NonDeepNetworks
https://arxiv.org/pdf/2110.07641.pdf 代码地址:https://github.com/imankgoyal/NonDeepNetworkshttps://github.com/imankgoyal/NonDeepNetworks

深度是深度神经网络的标志。但更多的深度意味着更多的计算和更高的延迟。这就引出了一个问题——有没有可能建立高性能的“非深度”神经网络?本文证明了可以。为此,作者使用并行子网,而不是一层层的堆叠。这有助于在保持高性能的同时有效地降低深度。通过利用并行子结构,取得了非常好的性能:ImageNet的80.7% ,CIFAR10的96%,CIFAR100的81%,MS-COCO的48%。作者分析了设计的缩放规则,并展示了如何在不改变网络深度的情况下提高性能。最后,我们提供了非深度网络如何用于构建低延迟识别系统的概念证明。
ParNet中的一个关键的设计选择是使用并行子网(parallel subnetworks)。不是按顺序排列层,而是在平行的子网中排列层。
ParNet不仅帮助我们回答关于大深度必要性的科学问题,而且提供了实际优势。由于并行的子结构,ParNet可以在多个处理器上轻松地并行化。我们发现ParNet可以有效地并行化,并且在速度和精度方面都优于ResNets。请注意,尽管处理单元之间的通信引入了额外的延迟,但这还是可以实现的。这表明,在未来,可能有专门的硬件来进一步减轻通信延迟,类似parnet的架构可以用于创建极其快的识别系统。
作者还研究了ParNet的缩放规则。具体来说,他们证明了ParNet可以通过增加宽度、分辨率和分支的数量来有效地缩放,同时保持深度恒定。ParNet的性能并不饱和,并随着计算吞吐量的增加而增加。这表明,通过进一步增加计算量,人们可以在保持小深度(∼10)和低延迟的同时获得更高的性能。
本文贡献:
- 作者首次表明,一个深度只有12层的神经网络可以在非常有竞争力的基准上实现高性能(在ImageNet上达到80.7%,在CIFAR10上达到96%,在CIFAR100上达到81%)。
- 展示了如何利用ParNet中的并行结构用于快速、低延迟的推理。
- 研究了ParNet的尺度规则,并证明了恒定深度的有效尺度。

网络结构:
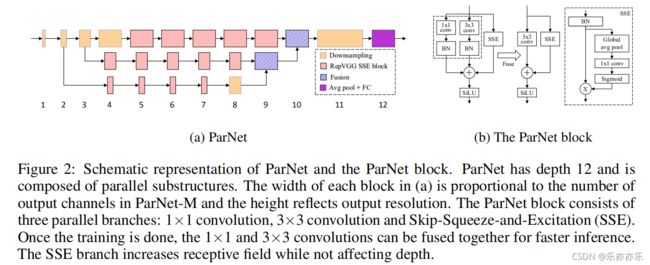
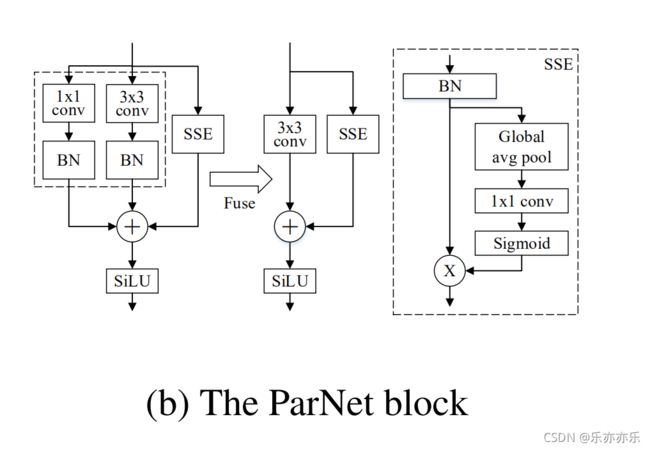
ParNet由并行的子结构组成,它们以不同的分辨率处理特征。作者将这些并行的子结构称为流。来自不同流的特征在网络的后期阶段被融合,这些融合的特征被用于下游任务。
Sigmoid Weighted Liner Unit(SiLU)
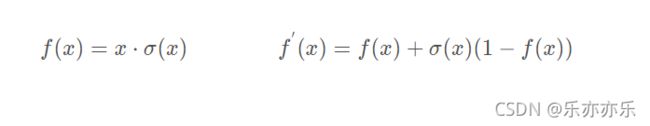
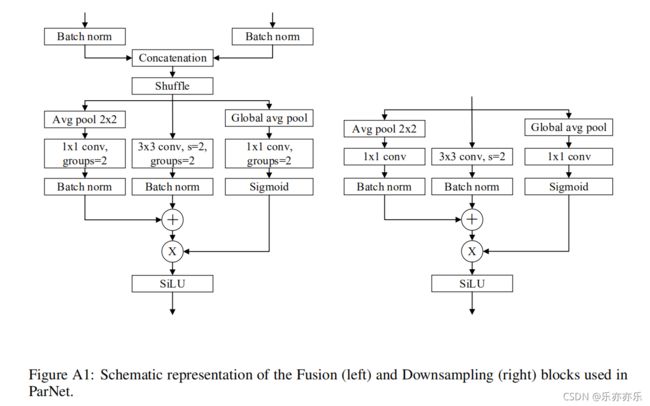
DOWNSAMPLING AND FUSION BLOCK
除了RepVGG-SSE(它的输入与输出具有相同尺寸)外,ParNet还包含一个下采样与融合模块。降采样块降低了分辨率并增加了宽度,以启用多尺度处理,而Fusion块结合了来自多个分辨率的信息。如下图所示:
-
下采样模块:它用于降低分辨率提升宽度以促进多尺度处理。它同样跳过连接分支,它添加了一个与卷积并行的单层SE模块(Global avg pool 、1x1 conv、Sigmoid ),此外还在卷积分支添加了2D平均池化(Avg pool 2x2)。
-
融合模块:它用于融合不同分辨率的信息。它类似于下采样模块但包含额外的concat层。除了concat外,它的输入通道数更多。因此,为降低参数量,我们采用g=2的分组卷积。
NETWORK ARCHITECTURE
网络结构如下图所示:
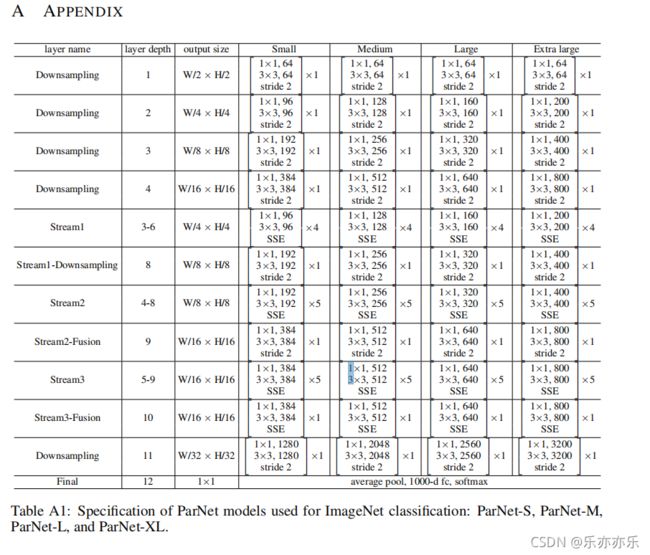
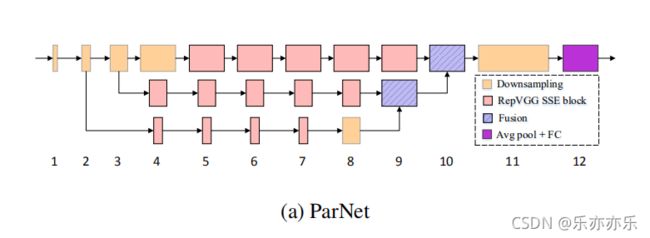
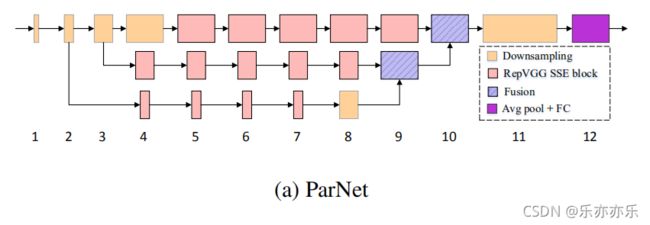 图2a显示了用于ImageNet数据集的ParNet模型的示意图。初始层由一系列降采样块(Downsampling)组成。下采样块2、3和4的输出分别被送到流1、2和3。根据实验,发现3是给定参数预算的最佳流数(表10)。每个流都由一系列的RepVGG-SSE block 块组成,这些块以不同的分辨率处理这些特性。然后使用 Fusion 连接将来自不同流的特征进行融合。最后,将输出传递到深度11的降采样块。详细结构上图TableA1.
图2a显示了用于ImageNet数据集的ParNet模型的示意图。初始层由一系列降采样块(Downsampling)组成。下采样块2、3和4的输出分别被送到流1、2和3。根据实验,发现3是给定参数预算的最佳流数(表10)。每个流都由一系列的RepVGG-SSE block 块组成,这些块以不同的分辨率处理这些特性。然后使用 Fusion 连接将来自不同流的特征进行融合。最后,将输出传递到深度11的降采样块。详细结构上图TableA1.

对于CIFAR10和CIFAR100,我们增加了网络的宽度,同时将分辨率保持在32,流的数量保持在3。对于ImageNet,通过改变所有的三个维度来进行实验。如图3所示:
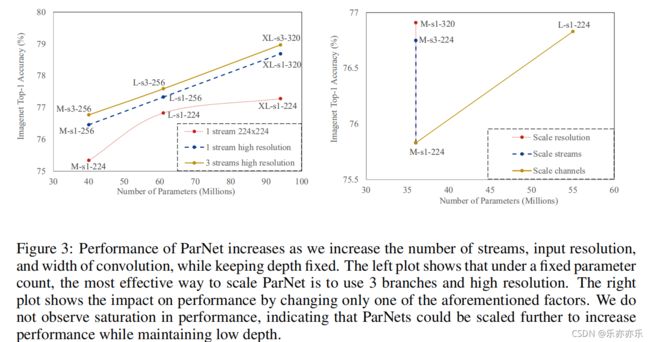
实验结果:

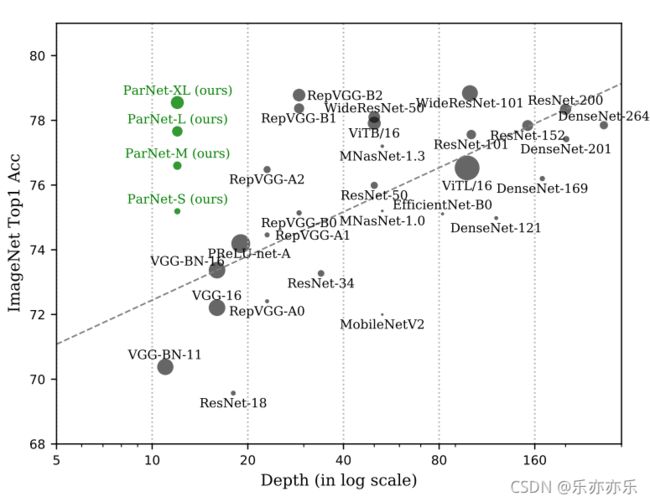
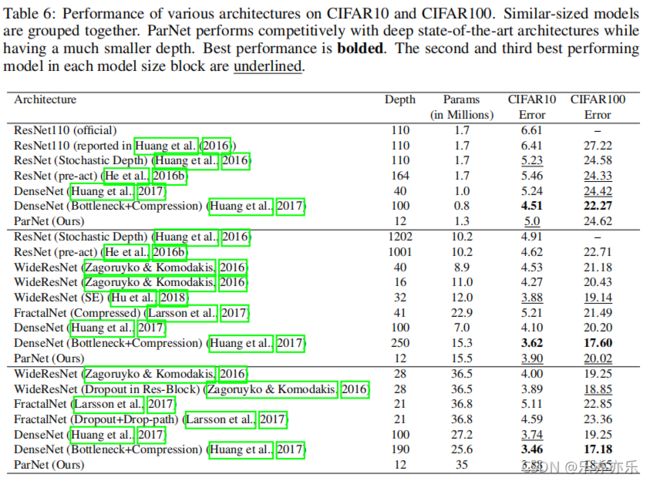
深度仅为12的ParNet取得了非常高的性能;ParNet-S具有比ResNet34更高的性能、更低的参数量;ParNet-L具有比ResNet50更高的性能;ParNet-XL具有与ResNet101相当的性能,同时深度仅为其1/8。
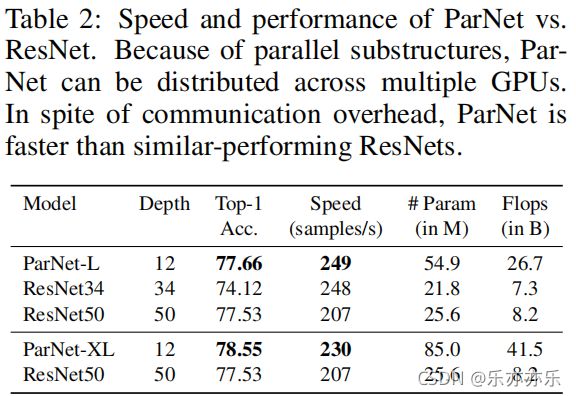
相比ResNet34与ResNet50,ParNet-L具有更快的速度、更高的精度;相比ResNet50,ParNet-XL具有更快的速度、更高的精度。这就意味着:可以采用ParNet替代ResNet以均衡推理速度-参数量-flops等 因素。
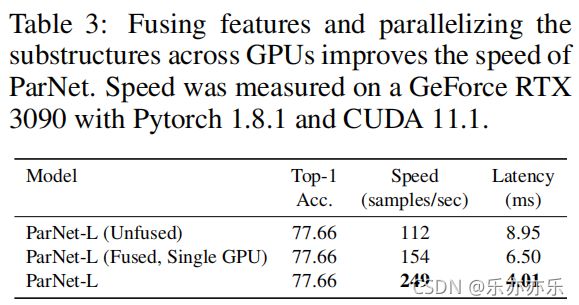
三个ParNet的三个变种:unfused、fused以及多GPU。从中可以看到:ParNet可以跨GPU高效并行以达成更快推理 。这里的实现结果是在通讯负载约束下得到,也就是说:通过特定的硬件减少通讯延迟可以进一步提升推理速度 。
在目标检测上的结果:
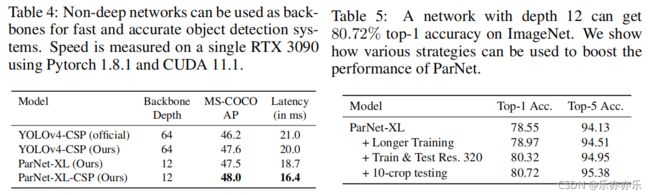
上图给出了ParNet作为骨干时在MS-COCO检测任务上的性能对比,可以看到:相比基线模型,ParNet具有更快的推理速度,更高的性能 。这说明:非深度网络可以用于构建快速目标识别系统 。
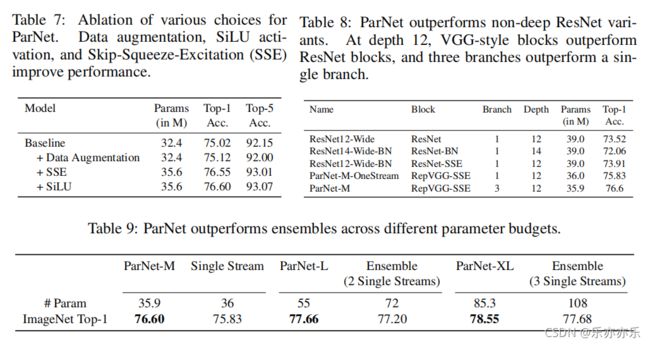
消融实验: