Django打造大型企业官网-项目实战(四)
一、新闻相关功能
在项目实战三中,我们完成了新闻分类相关的一些功能,现在我们来完成新闻列表、发布新闻、编辑新闻、删除新闻的功能
1、发布新闻/编辑新闻 功能实现
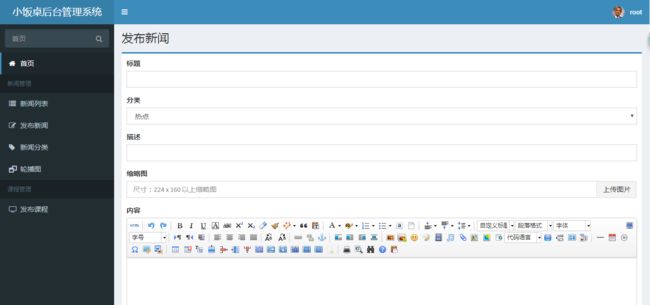
发布新闻、编辑新闻结合了 UEditor 富文本编辑器,关于UEditor编辑器使用,可参考随笔:https://www.cnblogs.com/Eric15/p/11022175.html
1)HTML前端代码:发布新闻/编辑新闻 共用
HTML代码 + UEditor 编辑器 + jQuery


{% extends 'crm/base.html' %}
{% block title %}
{% if news %}
编辑新闻
{% else %}
发布新闻
{% endif %}
{% endblock %}
{% block head %}
{# #}
{# #}
{% endblock %}
{% block content-header %}
{% if news %}
编辑新闻
{% else %}
发布新闻
{% endif %}
{% endblock %}
{% block content %}
{% endblock %}
{% block front-js %}
{% endblock %}
2)views:后端代码
发布新闻:
class AddNews(View): """新增新闻""" def get(self, request): categories = NewsCategory.objects.all() return render(request, 'crm/edit_news.html', {"categories": categories}) def post(self, request): news_form = NewsForm(request.POST) if news_form.is_valid(): # news_form.save() # 也可以直接用此种方法,如果是更新则不能用 title = news_form.cleaned_data.get('title') desc = news_form.cleaned_data.get('desc') thumbnail = news_form.cleaned_data.get('thumbnail') content = news_form.cleaned_data.get('content') category = news_form.cleaned_data.get('category') News.objects.create(title=title, desc=desc, thumbnail=thumbnail, content=content, category=category, author=request.user) return JsonResponse({'status': True, 'message': '恭喜!新闻已发布成功!'}) else: return JsonResponse({'status': False, 'message': '输入数据有误,新闻无法发布!'})
编辑新闻:
class EditNews(View): """编辑新闻""" def get(self, request, news_id): news = News.objects.get(id=news_id) categories = NewsCategory.objects.all() return render(request, 'crm/edit_news.html', {'news': news, 'categories': categories}) def post(self, request, news_id): news_obj = News.objects.filter(id=news_id).first() news_form = NewsForm(request.POST, instance=news_obj) if news_form.is_valid(): title = news_form.cleaned_data.get('title') desc = news_form.cleaned_data.get('desc') thumbnail = news_form.cleaned_data.get('thumbnail') content = news_form.cleaned_data.get('content') category = news_form.cleaned_data.get('category') News.objects.filter(id=news_id).update(title=title, desc=desc, thumbnail=thumbnail, content=content, category=category) return JsonResponse({"status": True, "message": "恭喜!新闻更新成功并完成发布!"}) else: return JsonResponse({"status": False, "message": "数据更改有误,新闻更新失败!"})
3)forms.py:发布新闻/编辑新闻 共用
from django import forms from news.models import News class NewsForm(forms.ModelForm): """新闻""" class Meta: # models中将author设置可为null,pub_time自动添加,因此我们可以不用另加 exclude 字段限制(剔除不需要的字段) model = News fields = "__all__"
4)urls.py:
from django.urls import path, re_path from crm import views urlpatterns = [ path("add_news/", views.AddNews.as_view(), name='add_news'), # crm 管理后台 新增新闻 path("add_news/upload_file", views.upload_file, name='upload_file'), # crm 管理后台 新增新闻[上传缩略图] re_path("edit_news/(\w+)/$", views.EditNews.as_view(), name='edit_news'), # crm 管理后台 编辑新闻 ]
5)缩略图上传相关js代码已经集成到 edit_news.html 中 ,后端代码如下:
@require_POST def upload_file(request): """新闻缩略图上传""" file = request.FILES.get('file') name = file.name with open(os.path.join(settings.MEDIA_ROOT, 'news', 'images', name), 'wb') as fp: # 图片保存路径 for chunk in file.chunks(): fp.write(chunk) url = request.build_absolute_uri(settings.MEDIA_URL+"news/"+"images/"+name) # url 返回给前端显示 return JsonResponse({"status": True, "url": url})
二、django-rest -framework 实现:首页展示新闻文章篇数,通过点击 '加载更多',异步加载更多文章篇数
原理:根据前端传递的页码,目前指定一页显示两篇文章,每点击一次 '加载更多' 则加载多一页的文章(即两篇),后端拿到页码,获取相应的文章数据并序列化传回给前端。传统做法:News.objects.all().value()[start:end],获取到的是字典类型(最外层还是QuerySet)对象,可序列化后传递到前端使用。但这种方式碰到带有外键字段的会有所缺陷,即外键字段只能获取到相应的外键id,如外键关联作者,获取到的只有id数值:author_id: 2 ,而外键关联的作者其他数据并不能获取到。
此时,可以使用django-rest -framework 来实现后端数据无损序列化。
关于django-rest-framework 可参考链接:https://www.cnblogs.com/Eric15/articles/9532648.html
1、虚拟环境下安装 django-rest-framework
pip install djangorestframework
2、在settings.py/INSTALLED_APP 中注册:
记得 makemigrations 、migrate 生成表数据
INSTALLED_APPS = [ '…', 'rest_framework', ]
3、使用django-rest-framework 下的serializers 序列化
后端代码相关
1)序列化 serializers.py:
# user/serializers.py from rest_framework import serializers from users.models import UserProfile class UserSerializer(serializers.ModelSerializer): class Meta: model = UserProfile fields = ('id', 'mobile', 'username', 'email', 'employee', 'is_active') # news/serializers.py from rest_framework import serializers from news.models import News,NewsCategory, Comment, Banner from users.serializers import UserSerializer class NewsCategorySerializer(serializers.ModelSerializer): class Meta: model = NewsCategory fields = ('id', 'name') class NewsSerializer(serializers.ModelSerializer): category = NewsCategorySerializer() author = UserSerializer() class Meta: model = News fields = ('id', 'title', 'desc', 'thumbnail', 'pub_time', 'category', 'author')
2)views.py:
from django.http import JsonResponse from xfz.settings import ONE_PAGE_NEWS_COUNT, INDEX_CATEGORY_COUNT from news.models import News, NewsCategory from news.serializers import NewsSerializer def news_list(request): # 通过 p 参数,来指定要获取第几页的数据, 通过新闻分类category_id获取该分类下新闻数据 # p category_id 参数是通过查询字符串的方式传递过来的:/news/list/?p=2&category_id=1 page = int(request.GET.get('p', 1)) # 分类为0是,表示不进行任何分类,直接按照时间倒序排序,在models.py中已经默认新闻数据按倒序排序 category_id = int(request.GET.get("category_id", 0)) start = (page - 1) * ONE_PAGE_NEWS_COUNT end = start + ONE_PAGE_NEWS_COUNT if category_id == 0: # 不考虑新闻分类限制 newses = News.objects.select_related('category', 'author').all()[start:end] else: newses = News.objects.select_related('category', 'author').filter(category__id=category_id)[start:end] serializer = NewsSerializer(newses, many=True) data = serializer.data # 序列化后数据保存在serializers.data中 return JsonResponse({"status": True, "data": data}) # 转换成json格式
3)urls.py:
from django.urls import path from . import views urlpatterns = [ path("news_list/", views.news_list, name='news_list'), # 新闻列表 ]
4)前端html代码:包括功能→ 时间日期过滤器、点击'加载更多' 加载更多文章、点击'新闻分类'如'热点' 加载更多热点相关新闻
{% load news_filters %}
"en">
"UTF-8">
{% block title %}小饭桌{% endblock %}
"stylesheet" href="{% static 'css/news/index.min.css' %}">
class="header">
class="container">
class="nav">
class="daohangtiao">
- if request.path|slice:'5' == '/news' %}class="active"{% endif %} >"{% url 'index' %}">资讯
- if request.path|slice:'8' == '/courses' %}class="active"{% endif %} >class="chuangyeketang" href="{% url 'course' %}">创业课堂
- class="qiyefuwu" href="#">企业服务
- if request.path|slice:'8' == '/payinfo' %}class="active"{% endif %} >"{% url 'payinfo' %}">付费资讯
- if request.path|slice:'7' == '/search' %}class="active"{% endif %} >"{% url 'search' %}">搜索
class="auth-box">
{% if request.user.is_authenticated%}
class="auth-login">
class="personal">
class="user">
class="current-user">{{ request.user }}
class="top-down"> "{% static 'images/auth/top_down.png' %}"/>
class="touxiang">
"{% static 'images/auth/top_down.png' %}"/>
class="touxiang">![]() "45" height="45" src="{{ MEDIA_URL }}{{ request.user.image }}"/>
class="userdetail">
class="personal-info">
"45" height="45" src="{{ MEDIA_URL }}{{ request.user.image }}"/>
class="userdetail">
class="personal-info">
![]() "60" height="60" src="{{ MEDIA_URL }}{{ request.user.image }}"/>
class="user-info">
"60" height="60" src="{{ MEDIA_URL }}{{ request.user.image }}"/>
class="user-info">
{{ request.user }}
{{ request.user.employee }}111
class="personal-center">
{% if request.user.is_staff %}
class="personcenter" href="{% url 'crm_index' %}">后台管理系统
{% endif %}
class="fr" href="{% url 'auth_logout' %}">退出
{% else %}
class="personal-p">
{% endif %}
{% block body %}
class="main">
class="wrapper">
{% block left-content %}
class="main-content-wrapper">
class="banner-group" id="banner-group">
class="banner-ul" id="banner-ul">
-
"#">
"{% static 'images/banners/lunbo_2.jpeg' %}" alt="">
-
"#">
"{% static 'images/banners/lunbo_3.jpg' %}" alt="">
-
"#">
"{% static 'images/banners/lunbo_4.jpg' %}" alt="">
-
"#">
"{% static 'images/banners/lunbo_5.png' %}" alt="">
class="left-btn btn">‹
class="right-btn btn">›
class="news-list-group">
class="news-inner">
class="list-tab">
- "news-category-val" data-category="0" {% if category_id == 0 %}class="active"{% endif %} οnclick="categoryAction(this)">"javascript:void(0)">最新资讯
{% for news_category in news_categories %}
- "news-category-val" data-category="{{ news_category.id }}" {% if category_id == news_category.id %}class="active"{% endif %} οnclick="categoryAction(this)">"javascript:void(0)">{{ news_category.name }}
{% endfor %}
class="news-list">
{% for news in news_list %}
-
class="news-group">
class="title">
"{% url 'news_detail' news.id %}">{{ news.title }}
class="desc">
{{ news.desc }}
class="more">
class="category">{{ news.category }}
class="pub-time">{{ news.pub_time|time_since }}
class="author">{{ news.author }}
{% endfor %}
class="load-more-group">
{% endblock %}
{% block right-wrapper %}
class="sidebar-wrapper">
class="platform-group">
class="online-class">
class="class-title">关注小饭桌
class="focus-group">
class="left-group">
- class="zhihu">
"#" target="_blank">小饭桌创业课堂
- class="weibo">
"#" target="_blank">小饭桌创业课堂
- class="toutiao">
"#" target="_blank">小饭桌
class="right-group">
class="desc">扫码关注小饭桌微信公众平台xfz008
class="hot-news-group">
class="online-class">
class="class-title">热门推荐
class="hot-list-group">
-
class="left-group">
class="title">
"#">王健林卖掉进军海外首个项目:17亿售伦敦ON...
class="more">
class="category">"#">深度报道
class="pub-time">1小时前
-
class="left-group">
class="title">
"#">王健林卖掉进军海外首个项目:17亿售伦敦ON...
class="more">
class="category">"#">深度报道
class="pub-time">1小时前
{% endblock %}
{% endblock %}
三、django-debug-toolbar 使用介绍
django_debug_toolbar 是django的第三方工具包,给django扩展了很多便利的调试功能。包括查看执行的sql语句、db查询次数、request、headers、调试概览等
界面:

1、虚拟环境下安装:
pip install django_debug_toolbar
2、settings.py中配置:
1)INSTALLED_APPS 注册:
需要注意的是,debug_toolbar要放在django.contrib.staticfiles 之后,当然不要理解为紧跟着django.contrib.staticfiles后面,只要在后面即可
INSTALLED_APPS = [ # ... 'django.contrib.staticfiles', # ... 'debug_toolbar', # 这个 ]
2)Middleware 中间件配置:
MIDDLEWARE_CLASSES = [ # ... 'debug_toolbar.middleware.DebugToolbarMiddleware', # ... ]
在settings中的MIDDLEWARE配置’debug_toolbar.middleware.DebugToolbarMiddleware’,我们要把django-debug-toolbar这个中间件尽可能配置到最前面,但是,必须要要放在处理编码和响应内容的中间件后面,比如我们要是使用了GZipMiddleware,就要把DebugToolbarMiddleware放在GZipMiddleware后面。
如下图,我没有使用到处理编码和响应内容的中间件后面,所以直接放在了最前面

3)配置 IP 地址
我们需要在settings.py文件中配置INTERNAL_IPS,只有访问这里面配置的ip地址时, Debug Toolbar才是展示出来。因为我们一般都是本地开发,所以,直接配置为127.0.0.1就可以了
# settings.py INTERNAL_IPS = ("127.0.0.1",)
3、url路由配置:
urlpatterns = [ "…" ] if settings.DEBUG: # 只有在debug 模式下,才能使用django-debug-toolbar import debug_toolbar urlpatterns.append(path("__debug__/", include(debug_toolbar.urls)))
简单配置后,我们启动项目,前端界面就会显示一个 DjDt 图标,用于 django-debug-toolbar 调试:

点击 DjDT 图标,展开详细信息:

4、django-debug-toolbar 面板介绍
- Versions :代表是哪个django版本
- Timer : 用来计时的,判断加载当前页面总共花的时间
- Settings : 读取django中的配置信息
- Headers : 当前请求头和响应头信息
- Request: 当前请求的想信息(视图函数,Cookie信息,Session信息等)
- SQL:查看当前界面执行的SQL语句
- StaticFiles:当前界面加载的静态文件
- Templates:当前界面用的模板
- Cache:缓存信息
- Signals:信号
- Logging:当前界面日志信息
- Redirects:当前界面的重定向信息
自定义django-debug-toolbar面板:
# settings.py DEBUG_TOOLBAR_PANELS = [ # 代表是哪个django版本 'debug_toolbar.panels.versions.VersionsPanel', # 用来计时的,判断加载当前页面总共花的时间 'debug_toolbar.panels.timer.TimerPanel', # 读取django中的配置信息 'debug_toolbar.panels.settings.SettingsPanel', # 看到当前请求头和响应头信息 'debug_toolbar.panels.headers.HeadersPanel', # 当前请求的想信息(视图函数,Cookie信息,Session信息等) 'debug_toolbar.panels.request.RequestPanel', # 查看SQL语句 'debug_toolbar.panels.sql.SQLPanel', # 静态文件 'debug_toolbar.panels.staticfiles.StaticFilesPanel', # 模板文件 'debug_toolbar.panels.templates.TemplatesPanel', # 缓存 'debug_toolbar.panels.cache.CachePanel', # 信号 'debug_toolbar.panels.signals.SignalsPanel', # 日志 'debug_toolbar.panels.logging.LoggingPanel', # 重定向 'debug_toolbar.panels.redirects.RedirectsPanel',
可通过在settings.py 中自定义 DEBUG_TOOLBAR_PANELS 面板选项,在前端DrDTV面板中展示我们所需要的面板信息
5、debug_toolbar 配置项:
默认为如下选项,不写则按如下默认,可根据需要调整
# settings.py CONFIG_DEFAULTS = { # Toolbar options 'DISABLE_PANELS': {'debug_toolbar.panels.redirects.RedirectsPanel'}, 'INSERT_BEFORE': '






