NUWA论文阅读
论文链接:NUWA: Visual Synthesis Pre-training for Neural visUal World creAtion
文章目录
- 摘要
- 引言
- 相关工作
-
- 视觉自回归模型
- 视觉稀疏自注意
- 方法
-
- 3D数据表征
- 3D Nearby Self-Attention
- 3D编码器-解码器
- 训练目标
- 实验
-
- 实现细节
- 与SOTA比较
-
- T2I微调
- T2V微调
- V2V微调
- Sketch-to-Image (S2I) 微调
- Image Completion (I2I) zero-shot evaluation
- Text-Guided Image Manipulation (TI2I) zero-shot evaluation
- Sketch-to-Video (S2V) fine-tuning and Text-Guided Video Manipulation (TV2V) zero-shot evaluation
- 消融实验
- 结论
摘要
本文提出了一个统一的多模态预训练模型,称为NUWA,可以为各种视觉合成任务生成新的或操纵现有的视觉数据(即图像和视频)。为了在不同场景下同时覆盖语言、图像和视频,设计了一种3D Transformer编码器-解码器框架,该框架不仅可以将视频作为3D数据处理,还可以将文本和图像分别作为1D和2D数据处理。为了考虑视觉数据的性质,降低计算复杂度,提出了一种3D Nearby Attention(3DNA)机制。在8个下游任务上评估了N UWA。与几个强大的基线相比,NUWA在文本到图像生成、文本到视频生成、视频预测等方面取得了最先进的结果。此外,它还在文本引导的图像和视频处理任务上显示出令人惊讶的良好zero-shot能力。项目仓库是https://github.com/microsoft/NUWA。
引言
如今,网络的视觉化程度越来越高,图像和视频已经成为新的信息载体,并在许多实际应用中得到了应用。在此背景下,视觉合成成为一个越来越受欢迎的研究课题,其目的是为各种视觉场景构建能够生成新的或操纵现有视觉数据(即图像和视频)的模型。
自回归模型在视觉合成任务中发挥重要作用,因为与GANs相比,自回归模型具有明确的密度建模和稳定的训练优势。早期的视觉自回归模型,如PixelCNN、PixelRNN、Image Transformer、iGPT和Video Transformer,以“逐像素”的方式进行视觉合成。然而,由于其在高维视觉数据上的计算成本高,这种方法只能应用于低分辨率的图像或视频,并且难以扩大规模。
最近,随着VQ-VAE作为一种离散视觉标记方法的出现,高效大规模的预训练可以应用于图像(如DALL-E和CogView)和视频(如GODIVA)的视觉合成任务。尽管取得了巨大的成功,但这种解决方案仍然存在局限性——它们将图像和视频分开处理,并专注于生成其中任何一个。这限制了模型从图像和视频数据中获益。
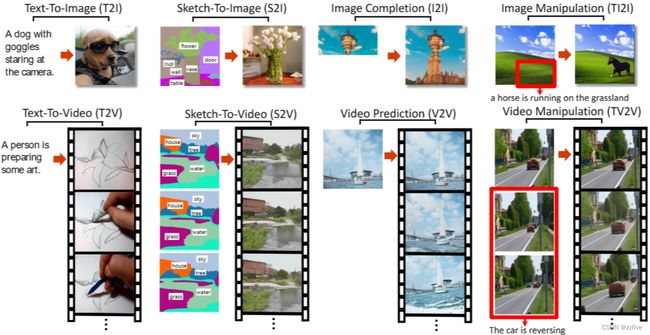
本文提出了一个统一的多模态预训练模型NUWA,旨在支持图像和视频的视觉合成任务,并进行了8个下游视觉合成实验,如图1所示。这项工作的主要贡献有三个方面:
- 提出NUWA,一个通用的3D Transformer 编码器-解码器框架,它同时涵盖语言,图像和视频,用于不同的视觉合成任务。它由一个以文本或视觉草图为输入的自适应编码器和一个由8个视觉合成任务共享的解码器组成
- 在框架中提出了一个3D Nearby Attention(3DNA)机制,以考虑空间和时间轴的局域性特征。3DNA不仅降低了计算复杂度,而且提高了生成结果的视觉质量
- 与几个强大的基线相比,NUWA在文本到图像生成、文本到视频生成、视频预测等方面取得了最先进的结果。此外,NUWA不仅在文本引导的图像处理上,而且在文本引导的视频处理上都表现出令人惊讶的良好的zero-shot能力
相关工作
视觉自回归模型
本文提出的方法遵循了基于自回归模型的视觉综合研究思路。早期的视觉自回归模型以“逐像素”的方式进行视觉合成。然而,由于建模高维数据时计算成本高,这种方法只能应用于低分辨率的图像或视频,并且难以扩大规模。
最近,基于VQ-VAE的视觉自回归模型被提出用于视觉合成任务。通过将图像转换为离散的视觉标记,这些方法可以对文本到图像生成(如DALL-E和CogView)、文本到视频生成(如GODIVA)和视频预测(如LVT和VideoGPT)进行高效和大规模的预训练,生成的图像或视频的分辨率更高。然而,这些模型都没有由图像和视频一起训练。但是直观的是,这些任务可以从两种类型的视觉数据中受益。
与这些工作相比,NUWA是一个统一的自回归视觉合成模型,由覆盖图像和视频的视觉数据进行预训练,可以支持各种下游任务。本文验证了不同预训练任务的有效性。此外,在NUWA中使用VQ-GAN代替VQ-VAE进行视觉标记化,实验结果显示可以获得更好的生成质量。
视觉稀疏自注意
如何处理自注意力带来的平方的复杂度问题是另一个挑战,特别是对于高分辨率图像合成或视频合成这样的任务。
与NLP类似,稀疏注意机制已经被探索来缓解视觉合成的这个问题。Latent Video Transformer和Scaling Autoregressive Video Models将视觉数据分割成不同的部分(或块),然后对合成任务执行分块稀疏关注。然而,这些方法分别处理不同的块,并没有建模它们之间的关系。DALL-E、GODIVA提出在视觉合成任务中使用轴向稀疏注意力机制,即沿着视觉数据表示的轴线进行稀疏注意力计算。这种机制使得训练非常高效,并且对大规模预训练模型(如DALL-E、CogView和GODIVA)非常友好。然而,由于在自注意力中使用的有限上下文,可能会损害生成的视觉内容的质量。Generating Long Sequences with Sparse Transformers、Stand-Alone Self-Attention in Vision Models提出在视觉合成任务中使用局部稀疏注意力,这使得模型能够看到更多的上下文。但这些工作只用于图片领域。
与这些工作相比,NUWA提出了一种3D nearby attention,它扩展了局部稀疏注意,将两幅图像覆盖到视频中。本文中验证了在视觉生成中,局部稀疏注意优于轴向稀疏注意。
方法
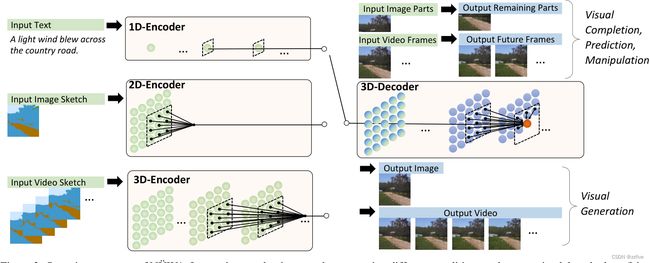
3D数据表征
为了涵盖所有文本、图像和视频,将所有类型数据视为tokens,并定义一个统一的 3D 符号 X ∈ R h × w × s × d X ∈ R^{h×w×s×d} X∈Rh×w×s×d,其中 h h h和 w w w分别表示空间轴(高度和宽度)上的tokens数, s s s表示时间轴中的tokens数, d d d是每个token的维度。下文介绍如何得到不同模态的统一表示。
文本自然是离散的,遵循 Transformer,使用小写字节对编码 (BPE) 将它们标记化并将它们嵌入到 R 1 × 1 × s × d R^{1×1×s×d} R1×1×s×d 中。使用占位符 1,因为文本没有空间维度。
图像自然是连续的像素。输入高度为H、宽度W和通道C的原始图像 I ∈ R H × W × C I∈R^{H×W ×C} I∈RH×W×C,VQ-VAE训练一个可学习的码本,在原始连续像素和离散标记之间建立桥梁,由以下公式(1)、(2)表示:
z i ( l ) = arg min j ∣ ∣ E ( ( I ) i − B j ∣ ∣ 2 , (1) z_{i}^{(l)}=\underset{j}{\arg \min}||E((I)_{i}-B_{j}||^{2}, \tag{1} zi(l)=jargmin∣∣E((I)i−Bj∣∣2,(1)
I ^ = G ( B [ z ] ) , (2) \hat{I}=G(B[z]), \tag{2} I^=G(B[z]),(2)
其中 E E E是一个编码器,将 I I I编码为 h × w h×w h×w个网格特征 E ( I ) ∈ R h × w × d B E(I) \in R^{h×w×d_{B}} E(I)∈Rh×w×dB, B ∈ R N × d B B \in R^{N×d_{B}} B∈RN×dB是一个具有 N N N个视觉tokens的可学习码本, E ( I ) E(I) E(I)中的每个网格都是从 B B B中计算相似度找到最相近的token搜索而来。搜索的结果 z ∈ { 0 , 1 , . , N − 1 } h × w z ∈ \{0, 1,., N − 1\}^{h×w} z∈{0,1,.,N−1}h×w由 B B B嵌入并由解码器 G G G重构回 I ^ \hat{I} I^。VQ-VAE的训练损失可表示为公式 (3):
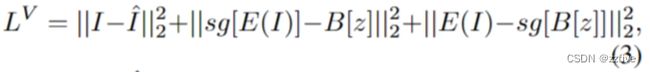
其中 ∣ ∣ I − I ^ ∣ ∣ 2 2 ||I-\hat{I}||^2_2 ∣∣I−I^∣∣22严格约束 I I I和 I ^ \hat{I} I^之间的精确像素匹配,限制了模型的泛化能力。最近,VQ-GAN通过添加感知损失和GAN损失来增强VQ-VAE训练,以缓解 I I I和 I ^ \hat{I} I^之间的精确约束,并专注于高级语义匹配,如公式(4) 、(5)所示:
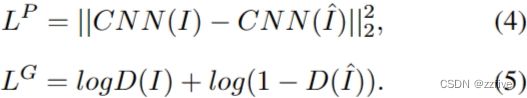
经过VQ-GAN的训练,最终使用 B [ z ] ∈ R h × w × 1 × d B[z]∈R^{h×w×1×d} B[z]∈Rh×w×1×d作为图像的表示,使用占位符1,因为图像没有时间维度。
视频可以被视为图像的时间延伸,最近的作品如videopt和VideoGen将VQ-VAE编码器中的卷积从2D扩展到3D,并训练视频特定的表示。然而,这不能为图像和视频共享一个共同的代码本。本文证明了简单地使用二维VQ-GAN对视频的每帧进行编码也可以生成时间一致性视频,同时从图像和视频数据中受益。结果表示为 R h × w × s × d R^{h×w×s×d} Rh×w×s×d,其中 s s s表示帧数。
对于图像草图,将它们视为具有特殊通道的图像。一个图像分割矩阵 R H × W R^{H×W} RH×W,其中每个值表示像素的类的值可以以 one-hot 方式 R H × W × C R^{H×W ×C} RH×W×C查看,其中 C C C是分割类的数量。通过训练一个额外的VQ-GAN进行图像草图,最终得到嵌入的图像表示 R h × w × 1 × d R^{h×w×1×d} Rh×w×1×d。类似地,对于视频草图,表示是 R h × w × s × d R^{h×w×s×d} Rh×w×s×d。
3D Nearby Self-Attention
基于之前的 3D 数据表示定义了一个统一的 3D Nearby SelfAttention (3DNA) 模块,支持自注意力和交叉注意力。首先给出公式(6)中3DNA的定义,并在公式(7) ~(11)中引入详细的实现:
Y = 3 D N A ( X , C ; W ) , (6) Y=3DNA(X,C;W), \tag{6} Y=3DNA(X,C;W),(6)
其中 X ∈ R h × w × s × d i n X \in R^{h×w×s×d^{in}} X∈Rh×w×s×din和 C ∈ R h ′ × w ′ × s ′ × d i n C \in R^{h^{'}×w^{'}×s^{'}×d^{in}} C∈Rh′×w′×s′×din是3D数据表征。如果 C = X C = X C=X,3DNA表示对目标 X X X的自注意力计算,如果 C ≠ X C≠X C=X,3DNA是目标 X X X在条件 C C C下的交叉注意力计算。 W W W表示可学习矩阵。从 X X X下的坐标 ( i , j , k ) (i, j, k) (i,j,k)开始引入 3DNA。通过一个线性映射,在条件 C C C下对应的坐标 ( i ′ , j ′ , k ′ ) (i^{'},j^{'},k^{'}) (i′,j′,k′)是 ( ⌊ i h ′ h ⌋ , ⌊ j w ′ w ⌋ , ⌊ k s ′ s ⌋ ) (\lfloor i\frac{h^{'}}{h} \rfloor,\lfloor j\frac{w^{'}}{w} \rfloor,\lfloor k\frac{s^{'}}{s} \rfloor) (⌊ihh′⌋,⌊jww′⌋,⌊kss′⌋)。然后,以 ( i ′ , j ′ , k ′ ) (i^{'},j^{'},k^{'}) (i′,j′,k′)为中心,宽度,高度,时间范围为 e w , e h , e s ∈ R + e^w, e^h, e^s∈R^+ ew,eh,es∈R+的局部邻域定义如公式(7)所示:
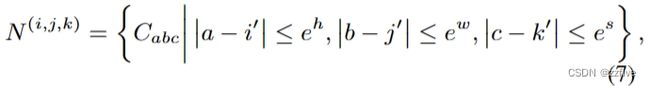
其中 N i , j , k ∈ R e h × e w × e s × d i n N^{i,j,k} \in R^{e^h×e^w×e^s×d^{in}} Ni,j,k∈Reh×ew×es×din是条件 C C C的子张量,由 ( i , j , k ) (i, j, k) (i,j,k)需要关注的相应附近信息组成。伴随三个可学习权值 W Q 、 W K 、 W V ∈ R d i n × d o u t W^Q、W^K、W^V∈R^{d^{in} ×d^{out}} WQ、WK、WV∈Rdin×dout,位置 ( i , j , k ) (i, j, k) (i,j,k)的输出张量如公式(8) ~(11)所示:
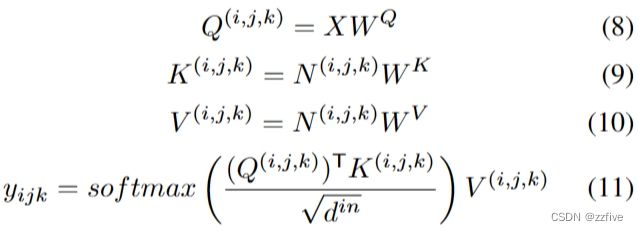
其中 ( i , j , k ) (i, j, k) (i,j,k)位置查询并收集 C C C中对应的附近信息。此也能处理 C = X C =X C=X的情况, ( i , j , k ) (i, j, k) (i,j,k)只查询自身附近的位置。3NDA不仅将完全注意的复杂度从 O ( ( h w s ) 2 ) O((hws)^2) O((hws)2)降低到 O ( ( h w s ) ( e h e w e s ) ) O ((hws) (e^he^we^s)) O((hws)(ehewes)),而且表现出了优越的性能。
3D编码器-解码器
基于 3DNA 构建 3D 编码-解码器。为了在 C ∈ R h ′ × w ′ × s ′ × d i n C ∈ R^{h^′ ×w^′ ×s^′ ×d^{in}} C∈Rh′×w′×s′×din的条件下生成目标 Y ∈ R h × w × s × d o u t Y ∈ R^{h×w×s×d^{out}} Y∈Rh×w×s×dout, Y Y Y和 C C C的位置编码由三个不同的可学习词汇表更新,分别考虑高度、宽度和时间轴,如公式(12)、(13)所示:
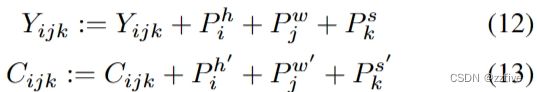
然后,将条件 C C C输入到一个编码器中,该编码器具有 L L L个3DNA层的堆栈,以对自注意相互作用进行建模,第 l l l层如公式(14)所示:
![]()
同样,解码器也由 L L L个3DNA 层的堆叠而成。解码器在生成结果上计算自注意力,在生成结果和条件之间的计算交叉注意力。第 l l l层计算如公式(15)所示:
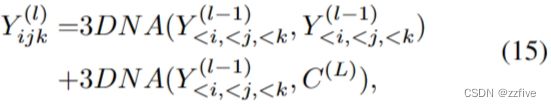
其中 < i , < j , < k < i, < j, < k <i,<j,<k表示当前生成的tokens。初始令牌 V 0 , 0 , 0 ( 1 ) V^{(1)}_{0,0,0} V0,0,0(1)是在训练阶段学习的特殊 < b o s > < bos > <bos>token。
训练目标
在文本到图像 (T2I)、视频预测 (V2V) 和文本到视频 (T2V) 三个任务上训练模型。三个任务的训练目标是交叉熵,分别在公式(16)中表示为三个部分所示:
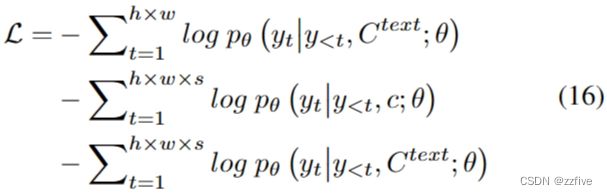
对于T2I和T2V任务, C t e x t C^{text} Ctext表示文本条件。对于V2V任务,由于没有文本输入,改为获得特殊单词“None”的恒定 3D 表示 c c c。 θ θ θ为模型参数。
实验
首先在三个数据集上对NUWA进行预训练:用于文本到图像(T2I)生成的Conceptual Captions数据集,包括290万文本到图像对;用于视频预测(V2V)的Moments in Time数据集,包括727K条视频;用于文本到视频(T2V)生成的VATEX数据集,包括241K条文本到视频对。
实现细节
按前文介绍设置文本、图像和视频的3D表示的大小,如下所示。对于文本,3D表示的大小为 1 × 1 × 77 × 1280 1 × 1 × 77 × 1280 1×1×77×1280。对于图像,三维表示的尺寸为 21 × 21 × 1 × 1280 21 × 21 × 1 × 1280 21×21×1×1280。对于视频,3D表示的大小为 21 × 21 × 10 × 1280 21 × 21 × 10 × 1280 21×21×10×1280,从2.5 fps的视频中采样10帧。尽管默认的视觉分辨率为 336 × 336 336 × 336 336×336,但对不同的分辨率进行预训练,以便与现有模型进行比较。对于图像和视频的VQ-GAN模型,公式(1)中网格特征 E ( I ) E(I) E(I)的大小为 441 × 256 441 × 256 441×256,码本 B B B的大小为 12 , 288 12,288 12,288。
不同的稀疏程度用于不同的模态。对于文本,设置 ( e w , e h , e s ) = ( 1 , 1 , ∞ ) (e^w, e^h, e^s) = (1, 1, ∞) (ew,eh,es)=(1,1,∞),其中 ∞ ∞ ∞表示全文始终用于注意力。对于图像和图像草图, ( e w , e h , e s ) = ( 3 , 3 , 1 ) (e^w, e^h, e^s) = (3, 3, 1) (ew,eh,es)=(3,3,1)。对于视频和视频草图, ( e w , e h , e s ) = ( 3 , 3 , 3 ) (e^w, e^h, e^s) = (3, 3, 3) (ew,eh,es)=(3,3,3)。
在 64 个 A100 GPU 上预训练两周,公式(14)中的层 L L L设置为24,使用Adam优化器,学习率为 1 e − 3 1e-3 1e−3,批量大小为128,预热 5% ,总共 50M 步。最终的预训练模型共有 870M 参数。
与SOTA比较
T2I微调
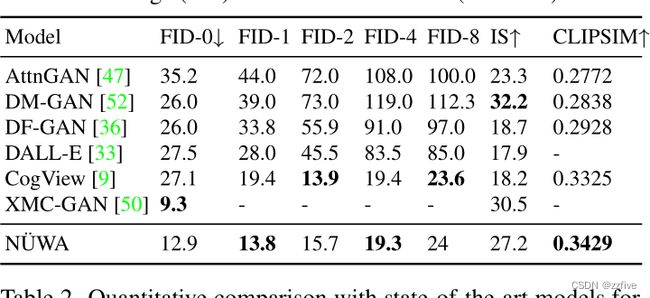
对MSCOCO数据集上的NUWA进行了定量比较(见表1),定性比较(见图3)。遵循DALL-E设置,分别使用模糊FID评分(FID-k)和Inception score (IS)来评估质量和多样性;同时按照GODIVA,使用CLIPSIM指标,该指标结合了CLIP模型来计算输入文本与生成图像之间的语义相似度。为了公平比较,所有模型都使用 256 × 256 256 × 256 256×256的分辨率。为每个文本生成60幅图像,并通过CLIP选择最佳图像。表1中,NUWA显著优于CogView,其FID-0为12.9,CLIPSIM为0.3429。尽管XMC-GAN报告了9.3的显著FID分数,但本文发现与XMC-GAN论文中完全相同的样本相比,NUWA生成的图像更真实(见图3)。特别是在最后一个例子中,男孩的脸部清晰,气球也正确生成。
T2V微调
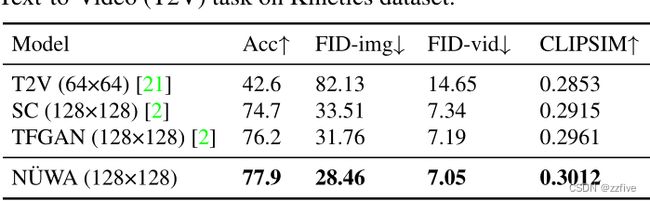
在Kinetics数据集上对NUWA进行了定量比较(见表2),定性比较(见图4)。遵循TFGAN,使用FID-img和FID-vid指标上评估视觉质量,在生成视频的标签准确性上评估语义一致性。如表2所示,NUWA在上述所有指标上都达到了最佳性能。图4展示了基于未见文本“playing golf at swimming pool”或“running on the sea”等生成视频的强大zero-shot能力。
V2V微调
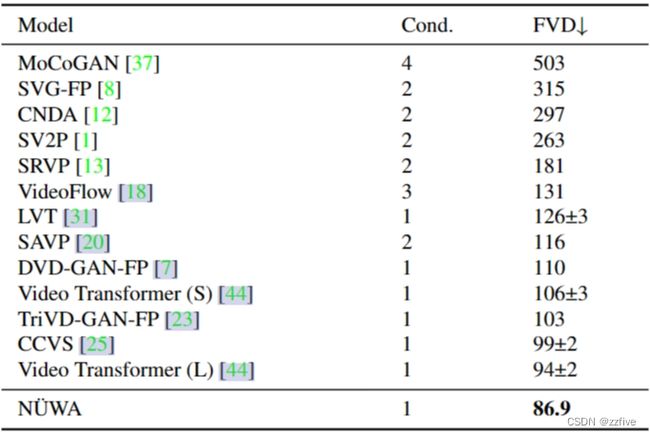
在表3中定量比较了BAIR Robot Pushing数据集上的NUWA。Cond.表示预测未来帧的帧数。为了公平比较,所有模型都使用 64 × 64 64×64 64×64分辨率。尽管只给出一帧作为条件(Cond.),但NUWA仍然显著地将最先进的FVD分数从94±2推到86.9。
Sketch-to-Image (S2I) 微调
图5中定性地比较了MSCOCO stuff上的NUWA。与Taming-Transformers和SPADE相比,NUWA生成了各种各样的真实巴士,即使是公共汽车窗口的反射也清晰可见。

Image Completion (I2I) zero-shot evaluation
在图6中以zero-shot的方式对NUWA进行定性比较。给定塔的上半部分图片,与Taming Transformers相比,NUWA对塔的下半部分表现出了更丰富的想象,包括建筑、湖泊、花、草、树、山等。

Text-Guided Image Manipulation (TI2I) zero-shot evaluation
在图7中以zero-shot的方式对NUWA进行了定性比较。与Paint By Word相比,NUWA显示出强大的操作能力,在不改变图像其他部分的情况下,生成高质量的与文本一致性高的结果。例如,在第三排,由NUWA生成的蓝色消防车更加逼真,而后面的建筑则没有变化。这得益于对各种视觉任务的多任务预训练所学习到的真实世界的视觉模式。另一个优势是NUWA的推理速度,几乎50秒生成图像,而Paint By Words在推理过程中需要额外的训练,大约需要300秒才能收敛。

Sketch-to-Video (S2V) fine-tuning and Text-Guided Video Manipulation (TV2V) zero-shot evaluation
开放域S2V和TV2V是本文首次提出的任务。由于没有比较,将在消融研究中讨论。录中提供了更详细的比较,包括人工评估的样本。
消融实验
表4的上述部分显示了不同VQ-VAE (VQ-GAN)设置的有效性。在ImageNet和OpenImages上进行了实验。 R R R表示原始分辨率, D D D表示离散标记的数量。压缩率记作 F x F_x Fx,其中 x x x是 R \sqrt{R} R除以 D \sqrt{D} D的商。比较表4的前两行,VQ-GAN显示出明显优于VQ-VAE的初始化距离(FID)和结构相似矩阵(SSIM)得分。比较第2-3行,发现离散tokens的数量是导致更高视觉质量的关键因素,而不是压缩率。虽然第2行和第4行具有相同的压缩率F16,但它们的FID评分不同,分别为6.04和4.79。因此,重要的不仅是对原始图像进行了多少压缩,还包括使用了多少离散的tokens来表示图像。这符合认知逻辑,用一个token来表示人脸太模糊了。实际上,发现162个离散的tokens通常会导致较差的性能,特别是对于人脸,而322个标记表现出最佳性能。然而,更多的离散tokens意味着更多的计算,特别是对于视频。最终在预训练中使用了一个折衷方法:212个令牌。通过在Open Images数据集上的训练,进一步将212版本的FID分数从4.79提高到4.31。
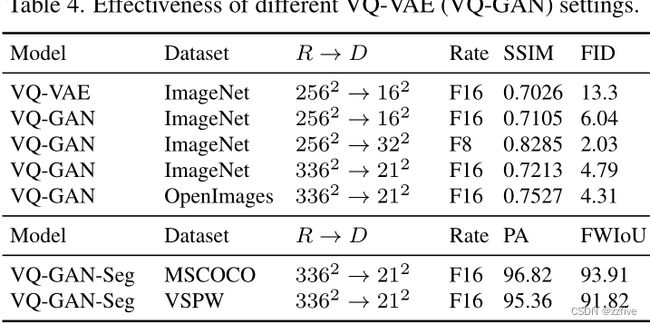
表4的下一部分显示了草图VQGAN的性能。MSCOCO上的VQ-GAN-Seg训练用于素描到图像(S2I)任务,VQ-GAN-Seg训练用于VSPW上的VQ-GAN-Seg训练用于素描到视频(S2V)任务。所有骨干网络在像素精度(PA)和频率加权交联(FWIoU)方面都表现出良好的性能,这表本文模型中使用的3D草图表示质量很好。图8还显示了 336 × 336 336×336 336×336图像和草图的一些重构样本。
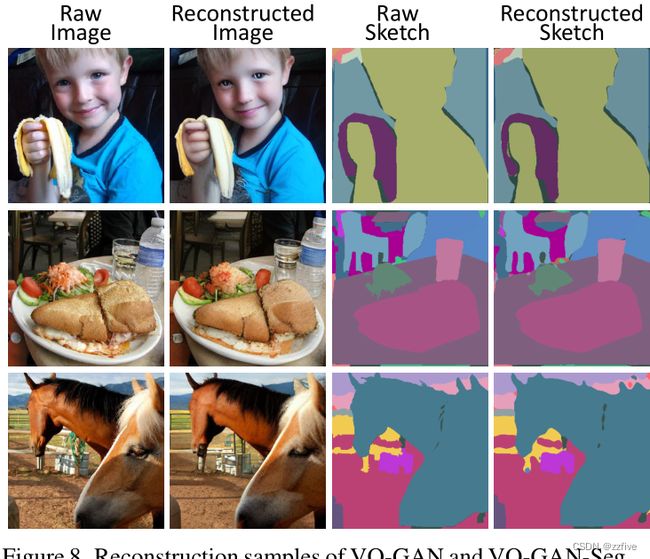
表5显示了文本到视频(T2V)生成任务的多任务预训练效果。本文研究了一个具有挑战性的数据集,MSR-VTT,具有自然描述和真实世界的视频。与只训练单一T2V任务(第1行)相比,同时训练T2V和T2I任务(第2行)将CLIPSIM从0.2314提高到0.2379。这是因为T2I有助于在文本和图像之间建立联系,从而有助于T2V任务的语义一致性。相比之下,T2V和V2V(第3行)的训练使FVD得分从52.98提高到51.81。这是因为V2V有助于学习一种常见的无条件视频模式,因此有助于T2V任务的视觉质量。作为NUWA的默认设置,在所有三个任务上进行训练可以达到最佳性能。
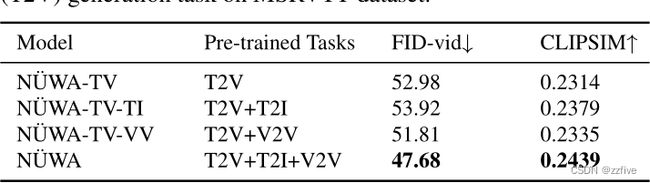
表6显示了在VSPW数据集上,3D Nearby Attention对Sketch-to-Video (S2V)任务的有效性。本文之所以研究S2V任务,是因为该任务的编码器和解码器都输入了3D视频数据。为了评估S2V的语义一致性,提出了一种名为Detected PA的新度量,它使用语义分割模型对生成的视频的每一帧进行分割,然后计算生成的片段与输入视频草图之间的像素精度。最后一行的默认NUWA设置,nearby编码器和nearby解码器,可以实现最佳的FID-vid和检测到的PA。如果将编码器或解码器中的任何一个替换为full attention,则性能会下降,这表明关注附近的条件和附近生成的结果比简单地考虑所有信息要好。在两层比较了邻近稀疏和轴向稀疏。首先,邻近稀疏的计算复杂度为 O ( ( h w s ) ( e h e w e s ) ) O ((hws) (e^he^we^s)) O((hws)(ehewes)),轴对称稀疏注意力为 O ( ( h w s ) ( h + w + s ) ) O ((hws) (h + w + s)) O((hws)(h+w+s))。对于生成长视频(更大的视频),nearby-sparse算法的计算效率更高。其次,在视觉生成任务中,邻近稀疏比轴稀疏具有更好的性能,这是因为邻近稀疏关注包含空间轴和时间轴相互作用的“nearby”位置,而轴稀疏则单独处理不同轴,只考虑同一轴上的相互作用。
图9显示了本文提出的一个新任务,称之为“文本引导视频操作(TV2V)”。TV2V的目标是改变一个视频的未来,从一个选定的帧开始,以文本为指导。所有的采样从第二帧开始改变视频的未来。第一行显示的是原始视频帧,一个潜水员在水里游泳。将“The diver is swimming to the surface”输入到NUWA的编码器中,并提供第一视频帧后,NUWA成功生成了第二行潜水员向水面游去的视频。第三行显示了另一个成功的样本,让潜水员游到底部。如果想让潜水员飞向天空呢?第四行显示,NUWA也可以做到,潜水员像火箭一样向上飞行。
结论
本文提出NUWA作为一个统一的预训练模型,可以为8个视觉合成任务生成新的或操纵现有的图像和视频。这里做出了一些贡献,包括:
- 同时覆盖文本,图像和视频的通用3D编码器/解码器框架
- 考虑了空间轴和时间轴的邻近特征的邻近-稀疏注意机制
- 8项综合任务的综合实验