网站独立访客数UV的统计--Flink实现
问题描述:统计每一小时的网站独立访客数UV(Unique Visitor)
问题背景:这是尚硅谷大数据技术之电商用户行为数据分析的一道例题,属于海量数据去重问题。武晟然老师讲授的方法是,自定义布隆过滤器进行UV统计。受到老师的启发,并结合多篇网络文章,本文给出了 ①Flink自带的布隆过滤器 ②Redis整合布隆过滤器 两种方法,进行UV去重统计。
数据集:UserBehavior.csv
1. Flink自带布隆过滤器进行UV统计
package com.atguigu.networkflowanalysis
import java.lang
import java.text.SimpleDateFormat
import com.atguigu.networkflowanalysis.UserBehavior
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.shaded.guava18.com.google.common.hash.{BloomFilter, Funnels}
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
/**
* @Author liu
* @Date 2023-03-20
*/
object UvWithFlinkBloom {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
val inputStream: DataStream[String] = env.readTextFile("D:\\ideaIU-2020.1.2\\IdeaProject\\UserBehaviorAnalysis\\NetworkFlowAnalysis\\src\\main\\resources\\UserBehavior.csv")
val resultStream: DataStream[String] = inputStream
.map(line => {
val dataArr: Array[String] = line.split(",")
UserBehavior(
dataArr(0).toLong,
dataArr(1).toLong,
dataArr(2).toInt,
dataArr(3),
dataArr(4).toLong
)
})
.filter(_.behavior == "pv")
.assignAscendingTimestamps(_.timestamp * 1000L)
.map(data=>("key",data.userId))
.keyBy(_._1)
.timeWindow(Time.hours(1))
.aggregate(new AggregateFunction[(String, Long), (Long, BloomFilter[lang.Long]), Long] {
override def createAccumulator() = (0, BloomFilter.create(Funnels.longFunnel(), 100000000, 0.01))
override def add(value: (String, Long), accumulator: (Long, BloomFilter[lang.Long])) = {
var uvCount: Long = accumulator._1
val bloom: BloomFilter[lang.Long] = accumulator._2
if (!bloom.mightContain(value._2)) {
bloom.put(value._2)
uvCount += 1
}
(uvCount, bloom)
}
override def getResult(accumulator: (Long, BloomFilter[lang.Long])) = accumulator._1
override def merge(a: (Long, BloomFilter[lang.Long]), b: (Long, BloomFilter[lang.Long])) = ???
}, new ProcessWindowFunction[Long, String, String, TimeWindow] {
override def process(key: String, context: Context, elements: Iterable[Long], out: Collector[String]): Unit = {
out.collect("窗口=" + sdf.format(context.window.getStart) + "~" + sdf.format(context.window.getEnd) + "\tUvCount=" + elements.iterator.next())
}
})
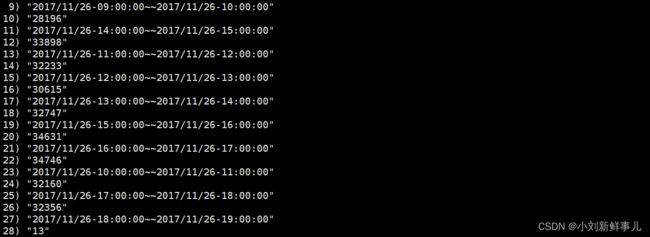
resultStream.print()
env.execute()
}
}
2. Redis整合布隆过滤器进行UV统计
前置准备:Redis-5.0.8集群环境集成布隆过滤器
引入依赖:
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
<version>3.0.0-m1version>
dependency>
<dependency>
<groupId>com.redislabsgroupId>
<artifactId>jrebloomartifactId>
<version>2.2.2version>
dependency>
启动Redis集群:
[xiaokang@hadoop01 ~]$ redis-cluster-start.sh
代码编写:
package com.atguigu.networkflowanalysis
import java.text.SimpleDateFormat
import java.util
import com.atguigu.networkflowanalysis.UserBehavior
import io.rebloom.client.ClusterClient
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
import redis.clients.jedis.{HostAndPort, JedisPoolConfig}
/**
* @Author liu
* @Date 2023-03-20
*/
case class UserBehavior(
userId: Long,
itemId: Long,
categoryId: Int,
behavior: String,
timestamp: Long
)
object UvWithRedisBloomCluster {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val inputStream: DataStream[String] = env.readTextFile("D:\\ideaIU-2020.1.2\\IdeaProject\\UserBehaviorAnalysis\\NetworkFlowAnalysis\\src\\main\\resources\\UserBehavior.csv")
val dataStream: DataStream[UserBehavior] = inputStream.map(line => {
val dataArr: Array[String] = line.split(",")
UserBehavior(
dataArr(0).toLong,
dataArr(1).toLong,
dataArr(2).toInt,
dataArr(3),
dataArr(4).toLong
)
}).filter(_.behavior == "pv")
.assignAscendingTimestamps(_.timestamp * 1000L)
dataStream
.map(data => ("key", data.userId))
.keyBy(_._1) //全部分到同一个组
.timeWindow(Time.hours(1))
.trigger(new MyTrigger())
.process(new ProcessWindowFunction[(String, Long), String, String, TimeWindow] {
var hostAndPortSet: util.HashSet[HostAndPort] = _
var config: JedisPoolConfig = _
var clusterClientBf: ClusterClient = _
var count: String = _
var sdf: SimpleDateFormat=_
override def open(parameters: Configuration) = {
hostAndPortSet = new util.HashSet[HostAndPort]()
hostAndPortSet.add(new HostAndPort("192.168.50.181", 7001))
hostAndPortSet.add(new HostAndPort("192.168.50.181", 7002))
hostAndPortSet.add(new HostAndPort("192.168.50.182", 7001))
hostAndPortSet.add(new HostAndPort("192.168.50.182", 7002))
hostAndPortSet.add(new HostAndPort("192.168.50.183", 7001))
hostAndPortSet.add(new HostAndPort("192.168.50.183", 7002))
config = new JedisPoolConfig()
config.setMaxTotal(50)
config.setMaxIdle(10)
config.setMinIdle(5)
config.setMaxWaitMillis(10000)
clusterClientBf = new ClusterClient(hostAndPortSet, config)
sdf= new SimpleDateFormat("yyyy/MM/dd-HH:mm:ss")
}
override def process(key: String, context: Context, elements: Iterable[(String, Long)], out: Collector[String]): Unit = {
val windowStart: String = sdf.format(context.window.getStart)
val windowEnd: String = sdf.format(context.window.getEnd)
val windowRange=windowStart+"~~"+windowEnd
if (!clusterClientBf.exists(windowRange)) {
clusterClientBf.createFilter(windowRange, 100000000, 0.1)
}
val curValue: String = elements.iterator.next()._2.toString
if (!clusterClientBf.exists(windowRange, curValue)) {
clusterClientBf.add(windowRange, curValue)
count = clusterClientBf.hget("uv", windowRange)
if (count != null) {
clusterClientBf.hset("uv", windowRange, (count.toLong+1).toString)
}else{
clusterClientBf.hset("uv", windowRange, 1L.toString)
}
}
}
})
env.execute()
}
}
class MyTrigger() extends Trigger[(String, Long), TimeWindow] {
//每来一个数据的时候要做什么操作
override def onElement(element: (String, Long), timestamp: Long, window: TimeWindow, ctx: Trigger.TriggerContext): TriggerResult = {
TriggerResult.FIRE_AND_PURGE //计算和清空
//FIRE //计算
//PURGE //清空
//CONTINUE //两者都不做
}
//系统时间有进展的时候要做什么操作
override def onProcessingTime(time: Long, window: TimeWindow, ctx: Trigger.TriggerContext): TriggerResult = TriggerResult.CONTINUE
//收到Watermark的时候,有Watermark改变的时候,要做什么操作
override def onEventTime(time: Long, window: TimeWindow, ctx: Trigger.TriggerContext): TriggerResult = TriggerResult.CONTINUE
override def clear(window: TimeWindow, ctx: Trigger.TriggerContext): Unit = {}
}
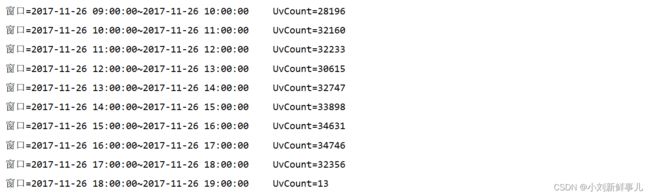
查看结果:
[xiaokang@hadoop01 ~]$ redis-cli -c -p 7001
127.0.0.1:7001> hgetall uv