spark sql的行转列
起因
日常应用中,我们经常会使用到把行转成列的功能,以NBA球队的球员薪资记录作为例子,表中的每一条记录表示球队在某一年支付的员工薪资记录。
| team | year | salary |
|---|---|---|
| Laker | 2019 | 2000w |
| Laker | 2020 | 3000w |
| Cleveland | 2019 | 3000w |
| Cleveland | 2020 | 5000w |
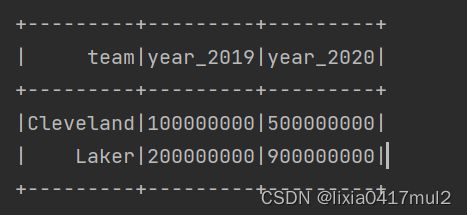
我们希望行转列成以下结构:
| team | year_2019 | year_2020 |
|---|---|---|
| Laker | 2000w | 3000w |
| Cleveland | 3000w | 5000w |
这样行列转换后我们就可以清晰的看出每个球队特定年份的总薪资支出了
如何实现行转列
方式一 聚合函数() + case when的方式
from pyspark import SparkConf
from pyspark.sql import SparkSession
import traceback
from pyspark.sql.types import IntegerType
appname = "test" # 任务名称
master = "local" # 单机模式设置
'''
local: 所有计算都运行在一个线程当中,没有任何并行计算,通常我们在本机执行一些测试代码,或者练手,就用这种模式。
local[K]: 指定使用几个线程来运行计算,比如local[4]就是运行4个worker线程。通常我们的cpu有几个core,就指定几个线程,最大化利用cpu的计算能力
local[*]: 这种模式直接帮你按照cpu最多cores来设置线程数了。
'''
# spark_driver_host = "10.0.0.248"
try:
# conf = SparkConf().setAppName(appname).setMaster(master).set("spark.driver.host", spark_driver_host) # 集群
conf = SparkConf().setAppName(appname).setMaster(master) # 本地
spark = SparkSession.builder.config(conf=conf).getOrCreate()
sc = spark.sparkContext
team_source = [("Laker","2019", 2*10000*10000), ("Laker","2020", 6*10000*10000),
("Laker", "2020", 3 * 10000 * 10000),
("Cleveland","2019", 1*10000*10000), ("Cleveland","2020", 3*10000*10000),
("Cleveland","2020", 2*10000*10000)]
rdd = sc.parallelize(team_source)
df = spark.createDataFrame(rdd, "team: string, year: string, salary: int")
df.createOrReplaceTempView("basketball")
# 方式一: 聚合函数 + case when
df2 = spark.sql("""
select team, max(case when year = 2019 then totalSalary else 0 end) as year_2019,max(case when year = 2020 then totalSalary else 0 end) as year_2020 from (
select team,year,sum(salary) as totalSalary from basketball group by team,year
) as a group by team
""")
df2.show()
spark.stop()
print('计算成功!')
except:
traceback.print_exc() # 返回出错信息
print('连接出错!')
方式二 pivot语法(spark2.4才支持)
from pyspark import SparkConf
from pyspark.sql import SparkSession
import traceback
from pyspark.sql.types import IntegerType
appname = "test" # 任务名称
master = "local" # 单机模式设置
'''
local: 所有计算都运行在一个线程当中,没有任何并行计算,通常我们在本机执行一些测试代码,或者练手,就用这种模式。
local[K]: 指定使用几个线程来运行计算,比如local[4]就是运行4个worker线程。通常我们的cpu有几个core,就指定几个线程,最大化利用cpu的计算能力
local[*]: 这种模式直接帮你按照cpu最多cores来设置线程数了。
'''
# spark_driver_host = "10.0.0.248"
try:
# conf = SparkConf().setAppName(appname).setMaster(master).set("spark.driver.host", spark_driver_host) # 集群
conf = SparkConf().setAppName(appname).setMaster(master) # 本地
spark = SparkSession.builder.config(conf=conf).getOrCreate()
sc = spark.sparkContext
team_source = [("Laker", "2019", 2 * 10000 * 10000), ("Laker", "2020", 6 * 10000 * 10000),
("Laker", "2020", 3 * 10000 * 10000),
("Cleveland", "2019", 1 * 10000 * 10000), ("Cleveland", "2020", 3 * 10000 * 10000),
("Cleveland", "2020", 2 * 10000 * 10000)]
rdd = sc.parallelize(team_source)
df = spark.createDataFrame(rdd, "team: string, year: string, salary: int")
df.createOrReplaceTempView("basketball")
# 方式二: pivot
df2 = spark.sql(
"""select * from (select team,year,sum(salary) as totalSalary from basketball group by team,year) pivot (max(totalSalary) for year in ('2019' as year_2019, '2020' as year_2020)) """)
df2.show()
spark.stop()
print('计算成功!')
except:
traceback.print_exc() # 返回出错信息
print('连接出错!')
对于pivot的sql语法来说,聚合的列包括除了转置列和聚合函数内之外的所有列.
两种方式得到的结果如下所示: