分布式计算引擎理解
前言
在理解完《SQL执行过程》之后,数据存储和数据计算分离的想法。例如外界现在很流行的newSql-Tidb,存储采用了KV模式,计算则采用Spark.
MR计算模型
MapReduce最早是由Google公司研究提出的一种面向大规模数据处理的并行计算模型和方法。也可以说它是:“分布式计算的始祖”。
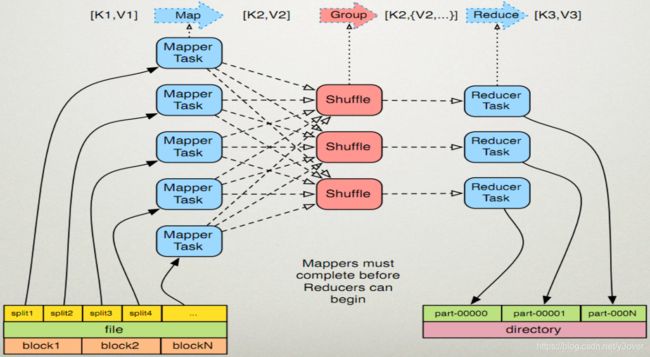
计算流程是:输入分片 —> map阶段 —> combiner阶段(可选) —> shuffle阶段 —> reduce阶段
输入分片(input split)
在进行map计算之前,mapreduce会根据输入文件计算输入分片,每个输入分片针对一个map任务。
- 关于 mapreduce分片算法为:
假如我们设定hdfs的块的大小是64mb,输入有三个文件,大小分别是3mb、65mb和127mb,那么mapreduce会把3mb文件分为一个输入分片,65mb则是两个输入分片而127mb也是两个输入分片.换句话说我们可以通过合并小文件做输入分片调整,那么就不会有5个map任务,而且每个map执行的数据大小不均的情况发生。- 关于读取其它数据源:
例如mysql,先将mysql数据读取到hdfs上,然后通过以上分片算法分片
map阶段
map操作都是本地化操作也就是在数据存储节点上进行,负责将当前存储节点上的数据,整理成K,V格式。要程序员编写。
K,V格式:
- K:存储用于关键的字段信息(类似于sql中, join的条件字段)
- V:其它数据信息 (类似于sql中,整行)
combiner阶段
combiner阶段是程序员可选择的,combiner其实也是一种reduce操作。它是map运算的后续操作,主要是在map计算出中间文件前做一个简单的合并重复key值的操作。例如我们对文件里的单词频率做统计,map计算时候如果碰到一个hadoop的单词就会记录为1,但是这篇文章里hadoop可能会出现n多次,那么map输出文件冗余就会很多,因此在reduce计算前对相同的key做一个合并操作,那么文件会变小,这样就提高了宽带的传输效率,毕竟hadoop计算力宽带资源往往是计算的瓶颈也是最为宝贵的资源,但是combiner操作是有风险的,使用它的原则是combiner的输入不会影响到reduce计算的最终输入,例如:如果计算只是求总数,最大值,最小值可以使用combiner,但是做平均值计算使用combiner的话,最终的reduce计算结果就会出错。
combine时一个本地化的reduce操作,对相同的key做一个合并操作,提高带宽的利用率
shuffle阶段
将map的输出作为reduce的输入的过程就是shuffle了,这个是mapreduce优化的重点地方。
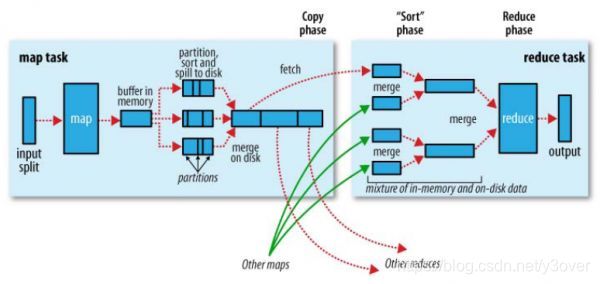
- 每个 Map 任务的计算结果都会写入到本地文件系统
map写入磁盘的过程十分的复杂,内存开销是很大的,map在做输出时候会在内存里开启一个环形内存缓冲区,这个缓冲区专门用来输出的,默认大小是100mb,并且在配置文件里为这个缓冲区设定了一个阀值,默认是0.80,如果缓冲区的内存达到了阀值的80%时候,这个守护线程就会把内容写到磁盘上,这个过程叫spill
- 等Map任务快要计算完成的时候,MapReduce 计算框架会启动 shuffle 过程.在 Map 任务进程调用一个 Partitioner 接口,对 Map 产生的每个
- MapReduce 框架默认的 Partitioner 用 Key 的哈希值对 Reduce任务数量取模,相同的 Key 一定会落在相同的 Reduce 任务 ID 上
- 如果reduce对顺序有要求,可以定义每个partition的边界,大的数据到一个Reduce,后序只要把各个reduce的结果相加就行。可能会导致每个partition上分配到的记录数相差很大,hadoop提供了采样器帮我们预估整个边界,以使数据的分配尽量平均。
-
Reduce 任务进程对收到的数据进行排序和合并,相同的 Key 放在一起,组成一个 传递给 Reduce 执行
-
如果我们定义了combiner函数,那么排序前还会执行combiner操作。1步骤中的数据结点,也会进行2,3步骤的模拟。产生结果后再继续2,3步骤。
reduce阶段
针对shuffle阶段准备好的输入开始计算。
用MR实现left-join
我们要把数据库的数据存储和计算进行分离。假如计算引挚选用MR.怎么做呢?
Hive就是基于MR和HDFS思想实现的
假设对如下2张表做leftjoin
factory表:
factoryname addressed
Beijing Red Star 1
Shenzhen Thunder 3
Guangzhou Honda 2
Beijing Rising 1
Guangzhou Development Bank 2
Tencent 3
Back of Beijing 1
address表:
addressID addressname
1 Beijing
2 Guangzhou
3 Shenzhen
4 Xian
取出两个表中共同列作为map中的key,同时需要标识每个列所在的表,供在reduce中拆分
//汇聚所有addressID相同的
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String path = ((FileSplit)context.getInputSplit()).getPath().getName();//获取文件名
String line = value.toString();
StringTokenizer st = new StringTokenizer(value.toString());
String[] tmp = line.split(" +");
if(tmp.length ==2){
String first = tmp[0];
String second = tmp[1];
if(path.equals("factory")){
if(first.equals("factoryname")) return;
k.set(second);
v.set(first+"1");
}else if(path.equals("address")){
if(second.equals("addressname")) return;
k.set(first);
v.set(second+"2");
}
context.write(k,v);
}
}
//以factory为主表拆分
protected void reduce(Text key, Iterable<Text> value,Context context)
throws IOException, InterruptedException {
List<String> factory = new ArrayList<String>();
List<String> address = new ArrayList<String>();
for(Text val : value){
String str = val.toString();
String stf = str.substring(str.length()-1);
String con = str.substring(0,str.length()-1);
int flag = Integer.parseInt(stf);
if(flag == 1){
factory.add(con);
}else if(flag ==2){
address.add(con);
}
}
for(int i=0;i<factory.size();i++){
k.set(factory.get(i));
for(int j=0;j<address.size();j++){
v.set(address.get(j));
context.write(k, v);
}
}
}
Spark RDD模型
上面的MR模型,M给我们提供了并行操作,shuffle+R给我们提供了汇聚操作。我们是否可以把我们常用的操作[filter,limt,sort]等操作,分别用MR的2操作实现。然后依次串联起来执行就行。
类似于《java Stream流操作》, spark框架引入了RDD框架
RDD 实质上是一种更为通用的迭代并行计算框架,用户可以显示控制计算的中间结果,然后将其自由运用于之后的计算。RDD 操作分为窄依赖和宽依赖。窄依赖是指父 RDD 的每个分区都只被子 RDD 的一个分区所使用。宽依赖是指父 RDD 的每个分区都被多个子 RDD 的分区所依赖。
- 窄依赖: map、filter、union 等操作
- 宽依赖: groupByKey、reduceByKey 等操作

通过RDD,创建逻辑计划(DAG)
用户提交的计算任务是一个系列RDD。
- 遇到窄依赖操作,则划分到同一个执行阶段(Stage )
- 遇到宽依赖操作,则划分一个新的执行阶段(Stage )。
后面的 Stage 需要等待所有的前面的 Stage 执行完之后才可以执行,这样 Stage 之间根据依赖关系就构成了一个大粒度的 DAG。
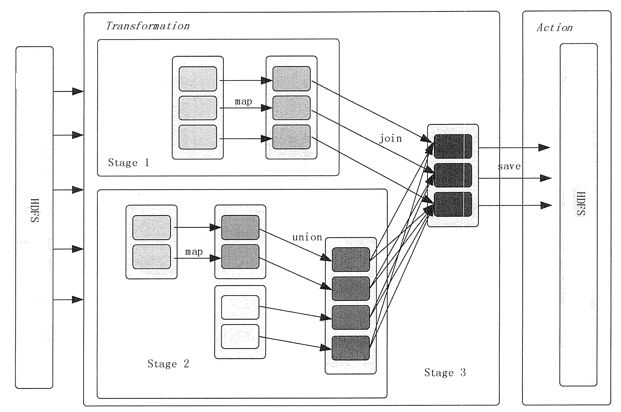
调度执行
把DAG提交下集群,集群根据DAG计划,创建任务,最终得到想要的数据。
批处理计算与流处理
在大数据处理领域,批处理任务与流处理任务一般被认为是两种不同的任务
- 流处理系统,其节点间数据传输的标准模型是:当一条数据被处理完成后,序列化到缓存中,然后立刻通过网络传输到下一个节点,由下一个节点继续处理。
- 批处理系统,其节点间数据传输的标准模型是:当一条数据被处理完成后,序列化到缓存中,并不会立刻通过网络传输到下一个节点,当缓存写满,就持久化到本地硬盘上,当所有数据都被处理完成后,才开始将处理后的数据通过网络传输到下一个节点。
这两种数据传输模式是两个极端,对应的是流处理系统对低延迟的要求和批处理系统对高吞吐量的要求。
Spark相对于MR 在计算模弄上进行优化。但对于input,shuffle的数据方式没有太大改变。仍处于批处理方式。
Spark streaming 则是通一块一块的读取数据模拟出流处理系统的概念
Flink的执行引擎采用了一种十分灵活的方式,同时支持了这两种数据传输模型。Flink以固定的缓存块为单位进行网络数据传输,用户可以通过缓存块超时值指定缓存块的传输时机。如果缓存块的超时值为0,则Flink的数据传输方式类似上文所提到流处理系统的标准模型,此时系统可以获得最低的处理延迟。如果缓存块的超时值为无限大,则Flink的数据传输方式类似上文所提到批处理系统的标准模型,此时系统可以获得最高的吞吐量。同时缓存块的超时值也可以设置为0到无限大之间的任意值。缓存块的超时阈值越小,则Flink流处理执行引擎的数据处理延迟越低,但吞吐量也会降低,反之亦然。通过调整缓存块的超时阈值,用户可根据需求灵活地权衡系统延迟和吞吐量。
主要参考
《MapReduce执行过程(长文)》
《【MapReduce】之 工作原理》
《Spark RDD是什么》
《Spark底层原理—Spark宽依赖和窄依赖深度剖析》
《深入理解Flink核心技术及原理》