Kafka学习笔记(六)· 高级应用~集群~监控
目录
- 八、高级应用
-
- 1、命令行工具
-
- 1、消费组管理
- 2、消费位移管理
- 2、数据管道Connect
-
- 1、概述
- 2、独立模式-文件系统
- 3、SpringBoot Kafka
-
- 1、添加pom文件
- 2、添加application.properties
- 3、消息的发送
- 4、消息的接收
- 5、Kafka事务的支持
- 九、集群管理
-
- 1、集群使用场景
- 2、集群搭建
-
- 1、Kafka集群搭建
- 3、多集群同步
-
- 1、配置
- 十、监控
-
- 1、监控度量指标
-
- 1、JMX
- 2、JConsole
- 3、代码来监控指标
- 2、broker监控指标
-
- 1、活跃控制器
- 2、请求处理器空闲率
- 3、主题流入字节
- 4、主题流出字节
- 5、主题流入的消息
- 6、分区数量
- 7、首领数量
- 3、主题分区监控
-
- 1、主题实例的度量指标
- 2、分区实例的度量指标
- 4、生产者监控指标
- 5、消费者监控指标
八、高级应用
1、命令行工具
1、消费组管理
-
查看消费组
[root@k8s-fengfan bin]# ./kafka-consumer-groups.sh --bootstrap-server 192.168.139.128:9092 --list epic-chopper-0 -
查看消费组详情
[root@k8s-fengfan bin]# /kafka-consumer-groups.sh --bootstrap-server 192.168.139.128:9092 --describe --group groupDemo Consumer group 'epic-chopper-0' has no active members. GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID epic-chopper-0 epic-choppp-receive 0 33 33 0 - - - -
查看消费组当前的状态
[root@k8s-fengfan bin]# ./kafka-consumer-groups.sh --bootstrap-server 192.168.139.128:9092 --describe --group epic-chopper-0 --state Consumer group 'epic-chopper-0' has no active members. GROUP COORDINATOR (ID) ASSIGNMENT-STRATEGY STATE #MEMBERS epic-chopper-0 k8s-fengfan:9092 (0) Empty 0 -
删除消费组,如果有消费者在使用则会失败
[root@k8s-fengfan bin]# ./kafka-consumer-groups.sh --bootstrap-server 192.168.139.128:9092 --delete --group epic-chopper-0
2、消费位移管理
充值消费位移,前提是没有消费者在消费,提示信息如下:
[root@k8s-fengfan bin]# ./kafka-consumer-groups.sh --bootstrap-server 192.168.139.128:9092 --group epic-chopper-0 --all-topics --reset-offsets --to-earliest --execute
Error: Assignments can only be reset if the group 'epic-chopper-0' is inactive, but the current state is Stable.
TOPIC PARTITION NEW-OFFSET
参数:--all-topics指定了所有主题,可以修改为--topics,指定单个主题
2、数据管道Connect
1、概述
Kafka是一个使用越来越广的消息系统,尤其是在大数据开发中(实时数据处理和分析)。为何集成其他系统和解耦应用,经常使用Producer来发送消息到Broker,并使用Consumer来消费Broker中的消息。Kafka Connect是到0.9版本才提供的并极大的简化了其他系统与kafka的集成。kafka Connect运用用户快速定义并实现各种Connector(File,Jdbc,Hdfs等),这些功能让大批量数据导入/导出Kafka很方便。
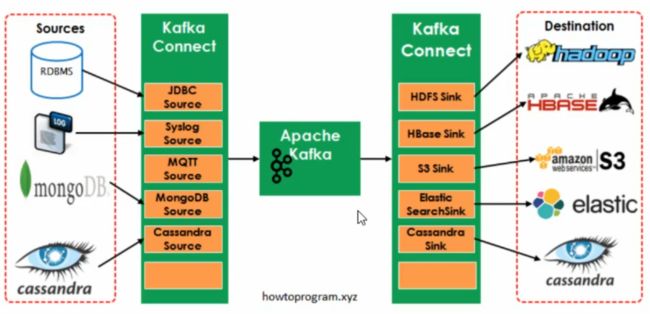
在kafka Connect中还有2个重要的概念:Task和Worker。
Connect中的一些概念
- 连接器:实现了Connect API,决定需要运行多少个任务,按照任务来进行数据复制,从work进程获取任务配置并将其传递下去
- 任务:负责将数据移入或移出kafka
- work进程:相当于connector和任务的容器,用于负责管理连接器的配置、启动连接器和连接器任务,提供RESTAPI
- 转换器:kafka connect和其他存储系统直接发送或者接收数据之间转换数据
2、独立模式-文件系统
场景
以下实例使用到了两个Connector,将文件source.txt中的内容通过Source连接器写入kafka主题中,然后将内容写入source.sink.txt中。
- FileStreamSource:从source.txt中读取并发布到Broker中
- FileStreamSink:从Broker中读取数据并写入到source.sink.txt文件中
步骤详情
worker进程用到的配置文件${KAFKA_HOME}/config/connect-standalone.properties
# kafka集群连接的地址
bootstrap.servers=192.168.139.128:9092
# 格式转换类
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
# json消息中是否包含schema
key.converter.schemas.enable=true
value.converter.schemas.enable=true
# 保存偏移量的文件路径
offset.storage.file.filename=/tmp/connect.offsets
# 设定提交偏移量的频率
offset.flush.interval.ms=10000
Source使用到的配置文件时${KAFKA_HOME}/config/connect-file0source.properties
# 配置连接器的名称
name=local-file-source
# 连接器的全限定名称,设置类名称也是可以的
connector.class=FileStreamSource
# task数量
tasks.max=1
# 数据源的文件路径
file=/tmp/source.txt
# 主题名称
topic=topic1222
Sink使用到的配置文件是${KAFKA_HOME}/config/connect-file-sink.properties
name=local-file-sink
connector.class=FileStreamSink
tasks.max=1
file=/tmp/source.sink.txt
topics=topic1222
启动Source连接器
[root@k8s-fengfan bin]# ./connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties
启动Sink连接器
[root@k8s-fengfan bin]# ./connect-standalone.sh config/connect-standalone.properties config/connect-file-sink.properties
Source写入文本信息
[root@k8s-fengfan bin]# echo "Hello Kafka">>/tmp/source.txt
查看Sink文件
[root@k8s-fengfan bin]# cat /tmo/source.sink.txt
Hello Kafka
3、SpringBoot Kafka
1、添加pom文件
<dependency>
<groupId>org.springframework.kafkagroupId>
<artifactId>spring-kafkaartifactId>
<version>2.2.6.RELEASEversion>
dependency>
2、添加application.properties
spring.kafka.producer.bootstrap-servers=192.168.139.128:9092
spring.kafka.consumer.bootstrap-servers=192.168.139.128:9092
3、消息的发送
/**
* 发送消息
*/
@GetMapping("/send/{input}")
public String sendToKafka(@PathVariable String input){
this.template.send(topic,input);
return "send success";
}
4、消息的接收
/**
* 消息的接收
*/
@KafkaListener(id="",topics=topic,groupId="epic-chopper-0")
public void listener(String input){
log.info("message input value:{}",input);
}
5、Kafka事务的支持
# 事务的支持
spring.kafka.producer.transaction-id-prefix=kafka_tx.
@GetMapping("/send/{input}")
public String sendToKafka(@PathVariable String input){
this.template.send(topic,input);
//事务的支持
template.executeInTransaction(t->{
t.send(topic,input);
if("error".equals(input)){
throw new RuntimeException("input is error!");
}
t.send(topic,input+" anthor");
return true;
});
return "send success!"+input;
}
@GetMapping("/send2/{input}")
@Transactional(rollbackFor=RuntimeException.class)
public String sendToKafkaTran(@PathVariable String input){
// this.template.send(topic,input);
template.send(topic,input);
if("error".equals(input)){
throw new RuntimeException("input is error!");
}
template.send(topic,input+" anthor");
return "send success!"+input;
}
九、集群管理
1、集群使用场景
Kafka是一个分布式消息系统,具有高水平扩展和高吞吐量的特点。在kafka集群中,没有“中心主节点”的概念,集群中所有的节点都说对等的。
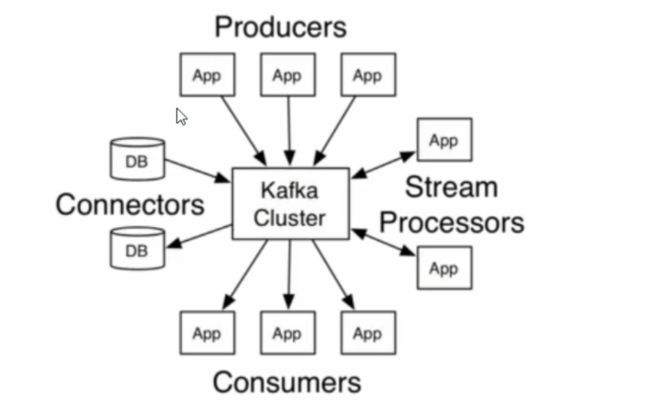
Broker(代理)
每个Broker即一个Kafka服务实例,多个Broker构成一个Kafka集群,生产者发布的消息将保存在Broker中,消费者将从Broker中拉取消息进行消费。
Kafka集群架构图
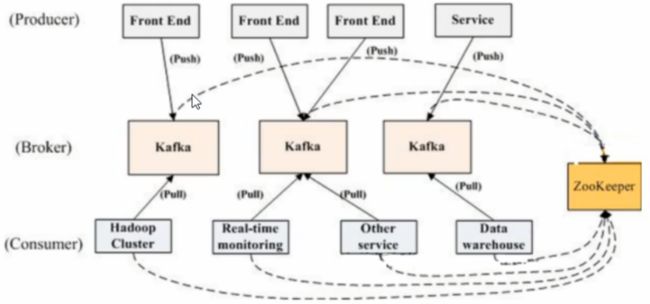
从图中可以看出kafka强以来于zookeeper,通过zookeeper管理自身集群,如:Broker列表管理、Partition与Broker的关系、Partition与Consumer的关系、Producer与Consumer负载均衡、消费进度Offset记录、消费者注册等,所以为了达到高可用,Zookeeper自身也必须是集群。
2、集群搭建
1、Kafka集群搭建
集群目录
[root@k8s-fengfan software]# ll
drwxr-xr-x. 7 root root 101 12月 16 15:30 kafka_2.13-2.6.0
drwxr-xr-x. 7 root root 101 12月 17 09:42 kafka_2.13-2.6.0-copy_9093
drwxr-xr-x. 7 root root 101 12月 17 09:42 kafka_2.13-2.6.0-copy_9094
server.properties
# broker编号,集群内必须唯一
broker.id=1
# host地址
host.name=192.168.139.128
# 端口
port=9092
# 消息日志存放地址
log.dirs=/opt/software/kafka_2.13-2.6.0/logs
# zookeeper地址,多个用,分隔
zookeeper.connect=192.168.139.128:2181,192.168.139.128:2182,192.168.139.128:2183
3、多集群同步
MirrorMaker是为解决kafka跨集群同步、创建镜像集群而存在的,下图展示了其工作原理,该工具消费源集群消息然后将数据重新推送到目标集群。
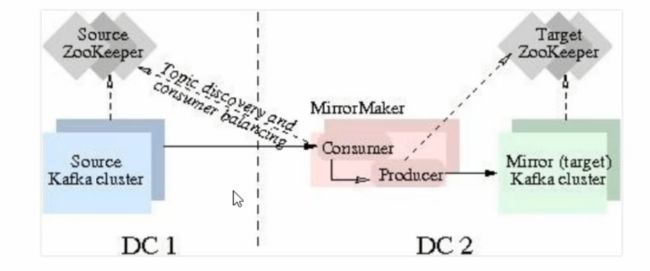
1、配置
创建镜像
使用MirrorMaker创建镜像是比较简单的,搭建好目标kafka集群后,只需要启动mirror-maker程序即可。其中,一个或多个consumer配置文件、一个producer配置文件时必须的,whitelist、blacklist是可选的。在consumer的配置中指定源kafka集群的zookeeper,在producer的配置中指定目标集群的zookeeper(或者broker.list)。
kafka-run-class.sh kafka.tools.MirrorMaker -consumer.config sourceCluster1Consumer.config -consumer.config sourceCluster2Consumer.config -num.streams 2 - producer.config targetClusterProducer.config -whitelist=".*"
consumer配置文件
# format: host1:port1,host2:port2 ...
bootstrap.servers=192.168.139.128:9092
#consumer group id
group.id=test-consumer-group
producer配置文件
# format: host1:port1,host2:port2 ...
bootstrap.servers=192.168.139.128:9092
# 为生成的所有数据指定压缩编解码器:none、gzip、snappy、lz4、zstd
compression.type=none
十、监控
在开发工作当中,消费kafka集群中的消息时,数据的变动是我们所关心的,当业务并不复杂的前提下,我们可以使用kafka提供的命令工具,配合zookeeper的客户端工具,可以很方便的完成我们的工作。
1、监控度量指标
1、JMX
在实现kafka监控系统的过程中,首先我们要知道监控的数据从哪里来,kafka自身提供的监控指标(包括broker和主题的指标,集群层面的指标通过各个broker的指标累加来获取)都可以通过JMX(Java Managent Extension)来进行获取。在使用JXM之前首先确保kafka开启了JMX的功能(默认是关闭的)
在使用jmx之前需要确保kafka开启了jmx监控,kafka启动时要添加JMX_PORT=9999这一项,也就是:
[root@k8s-fengfan bin]# JXM_PORT=0000 ./kafka-server-start.sh ../config/server.properties
开启JMX之后会在zookeeper的/brokers/ids/节点中有对应的呈现(jmx_port字段对应的值),如下:

2、JConsole
在开启JMX之后最简单的监控指标的方式就是使用JConsole,可以通过JConsole连接service:jmx:rmi:///jndi/rmi://localhost:9999/jmxrmi或者localhost:9999来查看相应的数据值。


3、代码来监控指标
/**
* JMX Connection
*/
public class JmxConnectionDemo{
private MBeanSererConnection conn;
private String jmxURL;
private String ipAndPort;
public JmxConnectionDemo(String ipAndPort){
this.ipAndPort=ipAndPort;
}
public boolean init(){
jmxURL = "service:jmx:rmi:///jndi/rmi://" + ipAndPort + "/jmxrmi";
try{
JMXServiceURL serviceURL = new JMXServiceURL(jmxURL);
JMXConnectot connector = JMXConnectorFactory.connect(serviceURL,null);
conn = connector.getMBeanServerConnection();
if(conn == null){
return false;
}
}catch(IOException e){
e.printStackTrace();
}
return true;
}
public double getMsgInPerSec(){
String objectName = "kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec";
try{
ObjectName objectName1 = n ew ObjectName(objectName);
Object val = conn.getAttribute(objectName1,"OneMinuteRate");
if(val!=null){
return (double)(Double) val;
}
}catch(Exception e){
e.printStackTrace();
}
return 0.0;
}
public static void main(String[] args){
JmxConnection jmxConnection = new JmxConnection("192.168.139.128:9999");
jmxConnection init();
System.out.println(jmxConnection.getMsgInPerSec());
}
private Object GetAttribute(String objName,String objAttr){
ObjectName objectName;
try{
objectName = new ObjectName(objName);
return conn.getAttribute(objectName,objAttr);
}catch(Exception e){
e.printStackTrace();
}
return null;
}
}
2、broker监控指标
1、活跃控制器
该指标表示broker是否就是当前的集群控制器,其值可以时0或1。如果时1,表示broker就是当前的控制器。任何时候,都应该只有一个broker是控制器,而且这个broker必须一致时集群控制器。如果出现了两个控制器,说明有一个本该退出的控制器线程被阻塞了,这会导致管理任务无法正常执行,比如移动分区。为了解决这个问题,需要将这两个broker重启,而且不饿能通过正常的方式重启,因为此时他们无法被正常关闭。
kafka.controller:type=KafkaController,name=ActiveControllerCount
值区间:0或1
2、请求处理器空闲率
kafka使用了两个线程池来处理客户端的请求:网络处理器线程池和请求处理器线程池。网络处理器线程的负责通过网络读入和写出数据。这里没有太多的工作要做,也就是说,不用太过担心这些线程会出现问题。请求处理器线程池负责处理来自客户端的请求,包括从磁盘读取消息和往磁盘写入消息。因此,broker负载的增长对这个线程池有很大的影响。
kafka.server:type=KafkaRequestHandlerPool,name=RequestHandlerAvgIdlePercent
3、主题流入字节
主题流入字节速率使用bis来表示,在对broker接收的生产者客户端消息流量进行度量时,这个度量指标很有用。该指标可以用于确定何时该对集群进行扩展或开展其他与规模增长相关的工作。它也可以用于评估一个broker是否比集群里的其他broker接收了更多的流量,如果出现了这种情况,就需要对分期进行再均衡。
kafka.server:type=BrokerTopicMetrics,name=ByteInPerSec
4、主题流出字节
主题流出字节速率与流入字节速率类似,是另一个与规模增长有关的度量指标。流出字节速率显示的是消费者从broker读取消息的速率。流出速率与流入速率的伸缩方式是不一样的,这要归功于kafka对多消费者客户端的支持
kafka.server:type=BrokerTopicMetrics,name=ByteOutPerSec
5、主题流入的消息
之前介绍的字节速率以字节的方式来表示broker的流量,而消息速率则以每秒生成消息个数的方式来表示流量,而且不考虑消息的大小,这也是一个很有用的生产者流量增长规模度量指标。它也可以与字节速率一起用于计算消息的平均大小
kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec
6、分区数量
broker的分区数量一般不会经常发生改变,它是指分配给broker的分区总数。它包括broker的每一个分区副本,不管是首领还是跟随着
kafka.server:type=ReplicaManager,name=PartitionCount
7、首领数量
该度量指标表示broker拥有的首领分区数量。与broker的其他度量一样,该度量指标也应该在整个集群的broker上保持均等。我们需要对该指标进行周期的检查,并适时的发出京高,即时在副本的数量和大小看起来都很完美的时候,他仍然能够显示出集群的不均衡问题,因为broker有可能出于各种原因释放掉了一个分区的首领身份,比如zookeeper会话过期,而在会话恢复之后,这个分区并不会自动拿回首领身份(除非启用了自动首领再均衡功能)。在这些情况下,该度量指标会显示较少的首领分区数,或者直接显示为零。这个时候需要运行一个默认的副本选举,重新均衡集群的首领
kafka.server:type=ReplicaManager,name=LeaderCount
3、主题分区监控
broker的度量指标描述了broker的一般行为,除此之外,还有很多主题实例和分区实例的度量指标。
1、主题实例的度量指标
主题实例的度量指标与之前描述的broker度量指标非常相似。事实上,他们之前唯一的区别在于这里指定了主题名称,也就是说,这些度量指标属于某个指定的主题。主题实例的度量指标数量取决于集群主题的数量,而且用户极有可能不会监控这些度量指标或设置告警。他们一般提供给客户端使用,客户端依次评估他们对kafka的使用情况,并进行问题调试。
2、分区实例的度量指标
分区实例的度量指标不如主题实例的度量指标那样有用。另外,他们的数量会更加庞大,因为几百个主题就可能包含数千个分区。不过不管怎样,在某种情况下,他们还是有一定有处的。Partition size度量指标表示分区当前在磁盘保留的数据量。如果把他们组合在一起,就可以表示单个主题保留的数据量,作为客户端配额的依据。同一个主题的两个不同分区之间的数据量如果存在差异,说明消息并没有按照生产消息的键进行均匀分布。Logsegment count指标表示保存在磁盘上的日志片段的文件数量,可以与Partition size指标结合起来,用于跟踪资产的使用情况。
4、生产者监控指标
新版本kafka生产者客户端的度量指标经过调整变得更加整洁,只用了少量的MBean。相反,之前版本的客户端(不再受支持的版本)使用了大量的MBean,而且度量指标包含了大量的细节(提供了大量的百分位和各种移动平均数)。这些度量指标提供了很大的覆盖面,但这样会让跟踪异常情况变得更加困难。
生产者度量指标的MBean名字里都包含了生产者的客户端ID。在下面的示例里,客户端ID使用CLIENTID表示,broker ID 使用BROKERID表示,主题的名字使用TOPICNAME表示
kafka.server:type=BrokerTopicMetrics,name=ProduceMessageConversionsPerSec
kafka.server:type=BrokerTopicMetrics,name=TotalProduceRequestsPerSec
5、消费者监控指标
与新版本的生产者客户端类似,新版本的消费者客户端将大量的度量指标属性塞进了少数的几个MBean里
kafka.consumer:type=consumer-metrics,client-id=CLIENTID
kafka.consumer:type=consumer-fetch-manager-metrics,client-id=CLIENTID