BERT论文精度笔记
前言
最近开始学大模型了,内容好多,所以记得有些混乱,后续可能也会有补充。
一、为什么NLP需要预训练?为什么需要预训练语言模型?
深度学习时代广泛使用的词向量(即词嵌入,Word Embedding)即属于NLP预训练工作。使用深度神经网络进行NLP模型训练时,首先需要将待处理文本转为词向量作为神经网络的输入,词向量的效果会影响最后模型的效果。
词向量的效果取决于训练语料的大小,很多NLP任务中有限的标注语料不足以训练出足够好的词向量,通常使用跟当前任务无关的大规模未标注预料进行词向量训练,因此预训练能够增强模型的泛化能力。目前大部分NLP深度学习任务中都会使用预训练好的词向量进行网络初始化(而非随机初始化),从而加快网络的收敛速度。
单纯预训练词向量通常只编码词汇间的关系,对上下文信息考虑不足,且无法处理一词多义问题,如"bank"一词,根据上下文语境不同,可能表示”银行“,可能表示”岸边“,但是这两种不同的意思却对应相同的词向量,显然是不合理的,因此衍生出预训练语言模型。
预训练语言模型首先使用大量无监督语料进行语言模型预训练(Pre-training),再使用少量标注语料进行微调(Fine-tuning)来完成具体NLP任务(分类、序列标注、句间关系判断和机器阅读理解等)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YhNp4fNr-1689904722393)(https://gitee.com/janjiang/23-summerstudy/raw/master/images/Week5/image.png)]
二、Bert的诞生
在计算机视觉中,很早的时候我们就可以在一个大的数据集(比如ImageNet)上训练好一个CNN模型,这个模型可以帮助我们解决很多计算机视觉的问题来提高它们的性能。但是在NLP自然语言处理领域,在Bert之前一直没有一个深的神经网络使得我们训练好以后能够解决一大片NLP任务,这就导致在NLP中每个人还是自己构建自己的神经网络,在自己的任务上做训练。而Bert的出现使得我们终于可以在一个大的数据集上训练好一个比较深的神经网络,然后能够应用在很多的NLP任务上。这样即简化了这些NLP任务的训练,又提升了它们的性能。
三、Abstract
- 我们引入了一种新的语言表征模型BERT,即Bidirectional Encoder Representations from Transformers(来自Transformers的双向编码器表示)。与最近的语言表征模型不同(ELMo和GPT),BERT旨在通过考虑未标记文本的左右(即双向)上下文(context)来预训练文本的深度双向表征。因此,只需要一个额外的输出层,就可以对预训练的BERT模型进行微调,从而为各种任务(如问题回答和语言推断)创建最先进的模型,而无需对特定于任务的体系结构进行实质性修改。
- BERT在概念上很简单,在实验上很强大。它在11个自然语言处理任务上获得了最新的结果,包括将GLUE得分推至80.5%(绝对提高7.7%),将多MultiNLI accuracy推至86.7%(绝对提高4.6%),将SQuAD v1.1问答测试F1推至93.2(绝对提高1.5分),将SQuAD v2.0测试F1推至83.1(绝对提高5.1分)。
1、查ELMo GPT,简单介绍一下
GPT是一个单向的transformer,它用左边的上下文信息去预测未来;Bert是同时用到了左右侧的上下文信息去预测未来,所以是一个双向的transformer。
ELMo用的是一个基于RNN的架构,而Bert用的是transformer,所以ELMo在用到一些下游任务时,它需要对架构做一些调整,而Bert相对来说就比较简单,只需要修改最上层就可以了。
| 模型 | 模型采用结构 | 预训练形式 | 优点 | 缺点 | 在Glue上的表现 |
|---|---|---|---|---|---|
| ELMO | Bilstm+LM | feature-based | 动态的词向量表征 | 双向只是单纯的concat两个lstm,并没有真正的双向 | 最差 |
| GPT | Transformer Decoder部分(含有sequence mask,去掉中间的Encoder-Decoder的attention | fine-tuning | 在文本生成任务上表现出色,同时采用辅助目标函数和LM(language model)模型 | 单向的transformer结构,无法利用全局上下文信息 | 较差 |
| BERT | Transformer Encoder部分 | fine-tuning | 在各项下游任务中表现出色,采用MLM(masked language model)的实现形式完成真正意义上的双向,增加了句子级别预测的任务 | 在文本生成任务上表现不好 | 最好 |
2、在介绍模型的时候讲清楚
它的一个绝对的精度是多少?它相比于其他近似的模型相对的好是多少?
四、Introduction
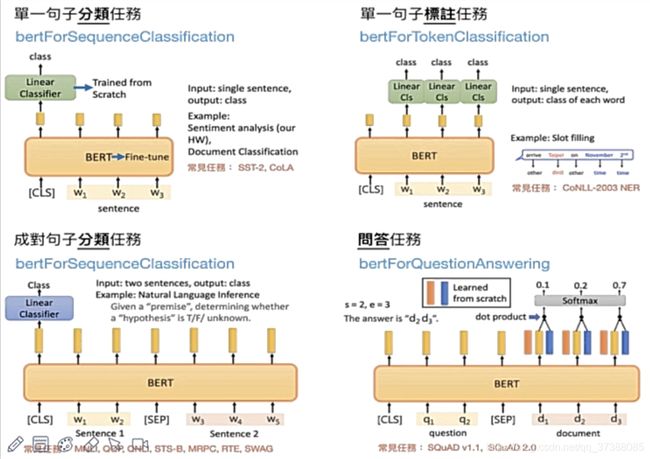
1、NLP任务
NLP任务包括句子级别的任务(建模句子之间的关系)和token级别的任务(实体命名的识别,比如说它是不是一个人名、一个街道名字)。
2、预训练模型策略
在预训练模型做特征表示的时候,一般又两类策略:
- feature-based(基于特征)
代表:ELMO,对每个下游任务构造一个与这个任务有关的神经网络(RNN架构),然后将预训练好的特征作为附加特征加入到下游任务中一起训练。 - fine-tuning(基于微调)
代表:GPT,fine-tuning的过程就是用预训练好的参数初始化自己的网络,然后用自己的数据接着训练,从而对参数进行一个微调。
这两种策略在预训练中使用相同的目标函数,即使用单向语言模型来学习通用的表征。类似GPT,GPT用的时transformer中的解码部分,是从左到右单向的,即我们在看一个句子的时候,只能从左到右看。而平时我们处理问题的时候并不是从左往右一个一个地看,而是全局地去看整个问题再选择答案,因此这种单向地模型结构是有局限性地。
本文地Bert用到的是transformer中地编码部分,是双向的,这也是本文作者认为Bert最大地卖点。Bert使用到了一个带有掩码地语言模型,这个模型每一次随机选择一些字,然后把它们盖住,我们的目标函数就去预测被盖住的字,类似英语考试中的完形填空,因此跟一般的单向模型不同,他是允许看左右的信息,从而训练出一个双向的模型。
除此之外,Bert还训练了另外一个任务,叫做下一个句子的预测。核心思想为给它两个句子,判断这两个句子再原文中是否相邻,还是只是随机采样的。
这样的操作不仅让模型学到了单个字层面上的信息,也学习了句子层面的信息。
Bert的两点贡献
- 展示了双向信息的重要性
之前有工作将从左到右的语言模型额从右到左的语言模型简单地concat在了一起,类似双向地RNN模型。这个简单拼接起来地模型已经再双向信息地应用上有了更好的表现。
- 假设已经有一个比较好的预训练模型,我们就不用对特定任务做一些特定的模型改动
Bert是第一个基于微调的模型,在句子层面和词元层面都取得了一个最好的成绩。
五、Bert
1、结构
根据参数设置的不同,Google 论文中提出了Base和Large两种BERT模型。

2、输入和输出
BERT采用了双向并行输入方式,即将句子整个输入到模型中,而不是将单词一个接一个地输入,这样可以充分利用GPU地性能,大大提升模型的运行效率。
对于下游任务,有些任务是处理一个句子,有些任务是处理两个句子,所以为了使BERT模型能够处理所有的任务,它的输入既可以是一个句子,也可以是一个句子对。
- 这里的一个句子是指一段连续的文字,不一定是真正语义上的一段句子
- 输入的是一个序列,可以是一个句子,也可以是两个句子
- 这和之前文章的transformer不同,transformer在训练的时候输入时一个序列对,因为它的编码器和解码器分别会输入一个序列,但是BERT只有一个编码器,因此为了使它能够处理两个句子的情况,就需要将两个句子变成一个序列。
(1) 序列的构成
这里使用的切词方法使WordPiece,核心思想:
- 假设按照空格切词,一个词作为一个token,数据量就会相对比较大,所以会导致词典大小特别大,可能是百万级别,那么根据之前算模型参数的方法,若为百万级别,就会导致整个可学习参数都在嵌入层上面
- WordPiece是说假设一个词在整个句子里面出现的概率不大的话,那么就应该把它切开看它的子序列,它的某个子序列可能是一个词根,这个词根出现概率比较大的话,那么只保留这个子序列即可。这样就能将一个相对较长的词切成很多一段一段的片段,而这些片段是经常出现的,这样就能用一个较小的词典去表示一个较大的文本。
(2)切好词后如何将两个句子放在一起
- 序列的第一个词永远是一个特殊的记号[CLS],CLS表示classification,这个词的作用是BERT想让它最后的输出代表的是整个序列的信息。因为BERT使用的是transformer的编码器,所以它的自注意力层中的每个词都会去看输入里面自己和所有其他词的关系,就算这个词放在第一的位置,它也有办法看到之后所有的词。
如果是单句子分类,[CLS]表示输入句子的类别;如果是句子对分类,表示两个句子是相关的/不相关的,相似意思/相反意思。
把两个词合在一起,但因为要做句子层面的分类,所以需要区分开来这两个句子,这里有两种方法:
- 在每个句子后面放一个特殊的词[SEP],代表separate
- 让模型去学一个嵌入层,让它去表示是第一个句子还是第二个句子
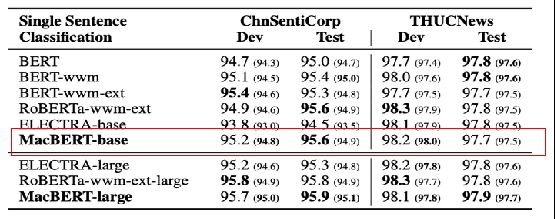
下图粉色方框表示输入的序列,[CLS]是第一个特殊的记号表示分类,中间用一个特殊的记号[SEP]分隔开,每一个token进入BERT得到这个token的embedding表示(对BERT来讲,就是输入一个序列,然后得到另外一个序列),最后transformer块的输出就表示这个词元的BERT表示,最后再添加额外的输出层来得到想要的结果。

对于每一个词元进入BERT的向量表示,它是这个词元本身的embedding+它在哪一个句子的embedding+它在这个句子中位置的embedding
为什么这么做?
因为BERT是并行输入,可能会带来单词在文本中的位置信息的丢失,因此BERT模型额外需要增加一个位置编码输入,确保位置信息不被丢失。
- 图中演示的是BERT的嵌入层做法,即由一个词元的序列得到一个向量的序列,这个向量的序列会进入transformer块
- 图中每一个方块是一个词元
- token embedding:这是一个正常的embedding层,对每一个词元输出它对应的向量
- segment embedding:表示是第一句话还是第二句话
- position embedding:输入的大小是这个序列的最大长度,它的输入就是每个词元在这个序列中的位置信息(从零开始),由此得到对应的位置的向量
- 在transformer中,位置信息是手动构造出来的一个矩阵,但是在BERT中,不管属于哪个句子,还是具体的位置,它对应的向量表示都是通过学习得来的。

3、Bert有两个步骤:
(1)pre-training(预训练)
BERT采用两个无监督任务进行参数预训练,分别为Masked Language Model和Net Sentence Prediction任务。
①Masked Language Model
对于输入的词元序列,若词元序列是由WordPiece生成的,那么它由15% 的概率会随机替换成掩码(替换为统一标记符[MASK]),然后预测这些被掩盖的词来训练双向语言模型,并且使每个词的表征参考上下文信息(完形填空)。[CLS]和[SEP]不会被替换。这样做会产生两个缺点:
- 会造成预训练和微调时的不一致,因为在微调时[MASK]总是不可见的;
- 优于每个Batch中只有15%的词会被预测,因此模型的收敛速度比起单向的语言模型会慢,训练花费的时间会更长。
对于第一个缺点的解决方法:把80%需要被替换成[MASK]的词进行替换,10%的随机替换为其他词,10%保留原词。由于transformer encoder并不知道哪个词需要被预测,哪个词是被随机替换的,这样就强迫每个词的表达需要参照上下文信息。
对于第二个缺点目前没有有效的解决办法,但是从提升收益的角度来看,付出的代价是值得的。
For example:
- 80%为特殊的[MASK]词元(比如"this movie is great"变为"this movie is < mask >";
- 10%为随机替换词元(比如"this movie is great"变为"this movie is drink“;
- 10%为不变的标签词元(比如“ this movie is great ”变为“ this movie is great ”)
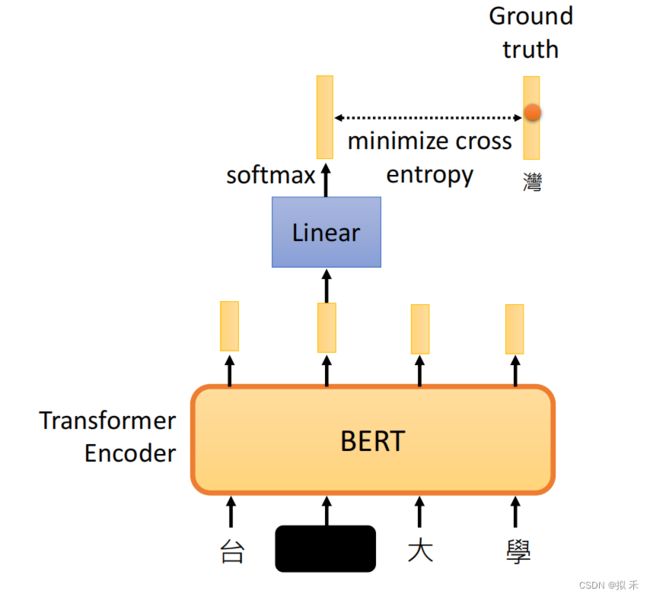
②Next Sentence Prediction
- 为了训练一个理解句子间关系的模型,引入一个下一句预测任务,这个任务的训练语料可以从语料库中抽取句子对包括两个句子A和B来进行生成,其中50%的概率B是A的下一个句子,50%的概率B是语料中的一个随机句子。NSP任务是预测B是否是A的下一句。NSP的目的是获取句子间的信息,这点是语言模型无法直接捕捉的。
Google的论文结果表明,这个简单的任务对问答和自然语言推理任务十分有益,但是后续一些新的研究发现,去掉NSP任务之后模型效果没有下降甚至还有提升。我们在预训练过程中也发现NSP任务的准确率经过1-2个Epoch训练后就能达到98%-99%,去掉NSP任务之后对模型效果并不会有太大的影响。
(2)fine-tuning (微调)
transformer是Encoder-Decoder架构,编码器一般是看不到解码器的东西的,而对于BERT来说,BERT是transformer的编码器部分,因为把整个句子对都一起放进去了,所以self-attention能够在两端之间相互看到。因此BERT在这一块性能更好,但实际上也付出了一定的代价,不能像transformer一样做机器翻译。
相同的预训练模型参数用于初始化不同下游任务的模型。在微调过程中,对所有参数进行微调,Bert对每一个词元返回抽取了上下文信息和特征向量。
即使下游任务各有不同,使用Bert微调时均只需要增加输出层,但根据任务的不同,输入的表示和使用的Bert特征也会有不一样。

4、预训练数据和参数
(1)数据集
BooksCorpus(单词量800M),English Wikipedia(单词量2500M)
(2)主要参数
batch_size=256,epochs=40,max_tokens=512,dropout=0.1
(3)优化参数
优化器Adam,lr=1e-4,β1=0.9,β2=0.999,L2 weight decay=0.01,lr_warmup=10000
(4)激活函数
gelu
(5)训练损失
mean MLM likelihood + mean NSP likelihood
(6)机器配置
BERTbase使用4个云TPUs,BERTlarge使用16个云TPUs
(7)训练时长
4天
(8)加速方式
90%的步数按照128的文本长度训练,剩余10%的步数按照512的文本长度训练
5、微调参数
在fine-tune阶段,大部分模型参数与预训练阶段是一样的,只有batch_size, lr, epochs需要调整,推荐参数如下:
(1)batch size = 16, 32
(2)lr = 5e-5, 3e-5, 2e-5
(3)epochs = 2, 3, 4
六、实验
自然语言处理(NLP)包括自然语言理解(NLU)和自然语言生成(NLG)。
在本节中,我们介绍了BERT在11个NLP任务上的微调结果。
1、GLUE
The General Language Understanding Evaluation (GLUE) 是多个自然语言理解任务的集合。GLUE包含九项NLU任务,涉及到自然语言推断、文本蕴含、情感分析、语义相似等。
这9项主要任务可以归为3大类,
- CoLA和SST-2属于“单句任务”,输入是一个单一的句子,输出是某种分类判断
- MRPC、STS-B、QQP属于“句子相似任务”,输入是一个句子对,输出是这两个句子的相似度衡量
- MNLI、QNLI、RTE、WNLI这几项都是“推断任务”,输入是一个句子对,输出是后句相对于前句语义关系的一个推断。
GLUE官网:https://gluebenchmark.com/
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FaYGwRHP-1689904722396)(https://gitee.com/janjiang/23-summerstudy/raw/master/images/Week5/image-8.png)]
为了在GLUE上进行微调,我们按照第3节所述表示输入序列(对于单句或句对),并使用与第一个输入标记([CLS])相对应的最终隐藏向量C∈ R H
作为总体表示。在微调过程中引入的唯一新参数是分类层权重W∈ R K*H
,其中K是标签的数量。我们用C和W计算一个标准的分类损失,即log(softmax(CWT
))。
(1)CoLA
CoLA(The Corpus of Linguistic Acceptability,语言可接受性语料库),单句子分类任务,预料来自语言理论的书籍和期刊,每个句子被标注为是否合乎语法的单词序列。本任务是一个二分类任务,标签共两个,分别是0和1,其中0表示不合乎语法,1表示合乎语法。
样本个数:训练集8551个,开发集1043个,测试集1063个
任务:可接受程度,合乎语法与不合乎语法二分类。
评价准则: Matthews correlation coefficient
标签为1(合乎语法)的样例:
- She is proud.
- she is the mother.
- John thinks Mary left.
- Will John not go to school?
标签为0(不合乎语法)的样例:
- Mary sent.
- Yes,she used.
- Mary thinks whether Bill will come.
- Mary noticed John’s excessive appreciation of herself.
这里面的句子看起来不是很长,有些错误是性别不符,有些是缺词、少词,有些是加s不加s的情况,各种语法错误。
(2)SST-2
SST-2(The Stanford Sentiment Treebank,斯坦福情感树库),单句子分类任务,包含电影评论中的句子和它们情感的人类注释。这项任务是给定句子的情感,类别分为两类正面情感(positive,样本标签对应为1)和负面情感(negative,样本标签对应为0),并且只用句子级别的标签。也就是,本任务也是一个二分类任务,针对句子级别,分为正面和负面情感。
样本个数:训练集67, 350个,开发集873个,测试集1, 821个。
任务:情感分类,正面情感和负面情感二分类。
评价准则:accuracy。
标签为1(正面情感,positive)的样例:
- two central performances
- a better movie
- the situation in a well-balanced fashion
- a patient viewer
标签为0(负面情感,negative)的样例:
- so pat it makes your teeth hurt
- monotone
- blood work is laughable in the solemnity with which it tries to pump life into overworked elements from eastwood 's dirty harry period
- this new jangle of noise , mayhem and stupidity must be a serious contender for the title .
由于句子来源于电影评论,又有它们情感的人类注释,不同于CoLA的整体偏短,有些句子很长,有些句子很短,长短并不整齐划一。
(3)MRPC
MRPC(The Microsoft Research Paraphrase Corpus,微软研究院释义语料库),相似性和释义任务,是从在线新闻源中自动抽取句子对语料库,并人工注释句子对中的句子是否在语义上等效。类别并不平衡,其中68%的正样本,所以遵循常规的做法,报告准确率(accuracy)和F1值。
样本个数:训练集3, 668个,开发集408个,测试集1, 725个。
任务:是否释义二分类,是释义,不是释义两类。
评价准则:准确率(accuracy)和F1值。
标签为1(正样本,互为释义)的样例(每个样例是两句话,中间用tab隔开):
- The largest gains were seen in prices , new orders , inventories and exports . Sub-indexes measuring prices , new orders , inventories and exports increased .
- He plans to have dinner with troops at Kosovo’s U.S. military headquarters , Camp Bondsteel . After that, he plans to have dinner at Camp Bondsteel with U.S. troops stationed there .
标签为0(负样本,不互为释义)的样例:
- Earnings per share from recurring operations will be 13 cents to 14 cents . That beat the company 's April earnings forecast of 8 to 9 cents a share .
- He beat testicular cancer that had spread to his lungs and brain . Armstrong , 31 , battled testicular cancer that spread to his brain .
本任务的数据集,包含两句话,每个样本的句子长度都非常长,且数据不均衡,正样本占比68%,负样本仅占32%。
(4)STSB
STSB(The Semantic Textual Similarity Benchmark,语义文本相似性基准测试),相似性和释义任务,是从新闻标题、视频标题、图像标题以及自然语言推断数据中提取的句子对的集合,每对都是由人类注释的,其相似性评分为0-5(大于等于0且小于等于5的浮点数,原始paper里写的是1-5,可能是作者失误)。任务就是预测这些相似性得分,本质上是一个回归问题,但是依然可以用分类的方法,可以归类为句子对的文本五分类任务。
样本个数:训练集5,749个,开发集1,379个,测试集1,377个。
任务:回归任务,预测为1-5之间的相似性得分的浮点数。但是依然可以使用分类的方法,作为五分类。
评价准则:Pearson and Spearman correlation coefficients。
一些训练集中的样例句子对及其得分:
- A plane is taking off. An air plane is taking off. 5.000
- A man is playing a large flute. A man is playing a flute. 3.800
- A dog rides a skateboard. A dog is riding a skateboard. 5.000
- A woman is playing the flute. A man is playing the guitar. 1.000
- A man is playing the guitar. A man is playing the drums. 1.556
- A cat is playing a piano. A man is playing a guitar. 0.600
整体句子长度适中偏短,且均衡。
(5)QQP
QQP(The Quora Question Pairs, Quora问题对数集),相似性和释义任务,是社区问答网站Quora中问题对的集合。任务是确定一对问题在语义上是否等效。与MRPC一样,QQP也是正负样本不均衡的,不同是的QQP负样本占63%,正样本是37%,所以我们也是报告准确率和F1值。我们使用标准测试集,为此我们从作者那里获得了专用标签。我们观察到测试集与训练集分布不同。
样本个数:训练集363,870个,开发集40,431个,测试集390,965个。
任务:判定句子对是否等效,等效、不等效两种情况,二分类任务。
评价准则:准确率(accuracy)和F1值。
标签为1(正样本,互为释义,等效)的样例(每个样例是两句话,中间用tab隔开):
- What are the top countries worth visiting? What are the top ten countries you think are most worth visiting in your lifetime, and why?
- How can I improve my communication and verbal skills? What should we do to improve communication skills?
标签为0(负样本,不互为释义,不等效)的样例:
- How do I solve 3^1/3? How do I solve (x^2-1) /(x-3) <0?
- What is the feeling of love? What it feels to be loved?
类似于MRPC,句子对的释义问题。这里突出的除了样本不均衡、训练集测试集分布不一致外,还有这个训练集、测试集都非常大。这里的测试集比其他训练集都要多好几倍。
(6)MNLI
MNLI(The Multi-Genre Natural Language Inference Corpus, 多类型自然语言推理数据库),自然语言推断任务,是通过众包方式对句子对进行文本蕴含标注的集合。给定前提(premise)语句和假设(hypothesis)语句,任务是预测前提语句是否包含假设(蕴含, entailment),与假设矛盾(矛盾,contradiction)或者两者都不(中立,neutral)。前提语句是从数十种不同来源收集的,包括转录的语音,小说和政府报告。
样本个数:训练集392,702个,开发集dev-matched 9,815个,开发集dev-mismatched9,832个,测试集test-matched 9,796个,测试集test-dismatched9,847个。因为MNLI是集合了许多不同领域风格的文本,所以又分为了matched和mismatched两个版本的数据集,matched指的是训练集和测试集的数据来源一致,mismached指的是训练集和测试集来源不一致。
任务:句子对,一个前提,一个是假设。前提和假设的关系有三种情况:蕴含(entailment),矛盾(contradiction),中立(neutral)。句子对三分类问题。
评价准则:matched accuracy/mismatched accuracy。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0FW6DGeV-1689904722396)(https://gitee.com/janjiang/23-summerstudy/raw/master/images/Week5/image-6.png)]
(7) QNLI
QNLI(Qusetion-answering NLI,问答自然语言推断),自然语言推断任务。QNLI是从另一个数据集The Stanford Question Answering Dataset(斯坦福问答数据集, SQuAD 1.0)转换而来的。SQuAD 1.0是由一个问题-段落对组成的问答数据集,其中段落来自维基百科,段落中的一个句子包含问题的答案。
样本个数:训练集104, 743个,开发集5, 463个,测试集5, 461个。
任务:判断问题(question)和句子(sentence,维基百科段落中的一句)是否蕴含,蕴含和不蕴含,二分类。
评价准则:准确率(accuracy)。
标签为蕴含(entailment,正样本)的样例(每个样例是两句话,中间用tab隔开,第一句是问题,第二句是上下文中的一句):
- Which collection of minor poems are sometimes attributed to Virgil? A number of minor poems, collected in the Appendix Vergiliana, are sometimes attributed to him.
标签为不蕴含(not_entailment,负样本)的样例(每个样例是两句话,中间用tab隔开,第一句是问题,第二句是上下文中的一句):
- While looking for bugs, what else can testing do? Although testing can determine the correctness of software under the assumption of some specific hypotheses (see hierarchy of testing difficulty below), testing cannot identify all the defects within software.
总体就是问答句子组成的问答对,一个是问题,一个是句子信息,后者包含前者的答案就是蕴含,不包含就是不蕴含,是一个二分类。
(8)RTE
RTE(The Recognizing Textual Entailment datasets,识别文本蕴含数据集),自然语言推断任务,它是将一系列的年度文本蕴含挑战赛的数据集进行整合合并而来的,包含RTE1,RTE2,RTE3,RTE5等,这些数据样本都从新闻和维基百科构建而来。将这些所有数据转换为二分类,对于三分类的数据,为了保持一致性,将中立(neutral)和矛盾(contradiction)转换为不蕴含(not entailment)。
样本个数:训练集2,491个,开发集277个,测试集3,000个。
任务:判断句子对是否蕴含,句子1和句子2是否互为蕴含,二分类任务。
评价准则:准确率(accuracy)。
标签为蕴含(entailment,正样本)的样例(每个样例是两句话,中间用tab隔开):
- The gastric bypass operation, also known as stomach stapling, has become the most common surgical procedure for treating obesity. Obesity is medically treated.
标签为不蕴含(not_entailment,正样本)的样例(每个样例是两句话,中间用tab隔开):
- No Weapons of Mass Destruction Found in Iraq Yet. Weapons of Mass Destruction Found in Iraq.
(9)WNLI
WNLI(Winograd NLI,Winograd自然语言推断),自然语言推断任务,数据集来自于竞赛数据的转换。Winograd Schema Challenge,该竞赛是一项阅读理解任务,其中系统必须读一个带有代词的句子,并从列表中找到代词的指代对象。为了将问题转换成句子对分类,方法是通过用每个可能的列表中的每个可能的指代去替换原始句子中的代词。任务是预测两个句子对是否有关(蕴含、不蕴含)。训练集两个类别是均衡的,测试集是不均衡的,65%是不蕴含。
样本个数:训练集635个,开发集71个,测试集146个。
任务:判断句子对是否相关,蕴含和不蕴含,二分类任务。
评价准则:准确率(accuracy)。
标签为1(蕴含,entailment,正样本)的样例(每个样例是两句话,中间用tab隔开):
- The actress used to be named Terpsichore, but she changed it to Tina a few years ago, because she figured it was too hard to pronounce. Terpsichore was too hard to pronounce.
标签为0(不蕴含,not_entailment,正样本)的样例(每个样例是两句话,中间用tab隔开):
- Bill passed the half-empty plate to John because he was hungry. Bill was hungry.
可以看到,这个数据集是数量最少,训练集600多个,测试集才100多个。同时目前GLUE上这个数据集还有些问题。
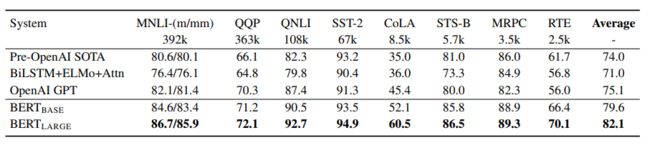


2、SQuAD v1.1
斯坦福的一个QA数据集。在这个Q&A任务中,给定一段话,然后问一个问题,需要在这段话中找出问题的答案(类似于阅读理解),答案在给定的那段话中。只需要把答案对应的小的片段找出来即可(找到这个片段的开头和结尾)。实质上就是对每个次元进行判断,看这个词元是不是答案的开头或者答案的结尾。
在微调过程中,我们只引入一个开始向量S∈ RH 和一个结束向量E∈ RH 。词i是答案跨度的开始的概率,计算为Ti和S之间的点乘,然后是段落中所有词的softmax。 。同理用公式计算出答案跨度的结尾。
。同理用公式计算出答案跨度的结尾。
Ti表示第 i 个输入词元对应的最后一个隐藏向量。
【注】论文中在做微调的时候的参数设置
- 使用了3个epoch,扫描了3遍数据
- lr是5e-5
- batchsize是32
用BERT做微调的时候结果非常不稳定,同样的参数、同样的数据集,训练十遍,可能会得到不同的结果。最后发现3其实是不够的,可能多学习几遍会好一点。
BERT用的优化器是adam的不完全版,当BERT要训练很长时间的时候是没有影响的,但是如果BERT只训练一小段时间的话,它可能会带来影响(将这个优化器换成adam的正常版就可以解决这个问题了)
表2显示了排行榜上的顶级条目以及已发表的顶级系统的结果(Seo等人,2017;Clark和Gardner,2018;Peters等人,2018a;Hu等人,2018)。SQuAD排行榜上的顶级结果没有最新的公共系统描述,并且在训练他们的系统时允许使用任何公共数据。因此,我们在系统中使用了适度的数据增强,首先在TriviaQA(Joshi等人,2017)上进行微调,然后在SQuAD上进行微调。
我们表现最好的系统在集合时比顶级排行榜上的系统高出+1.5 F1,作为一个单一的系统则高出+1.3 F1。事实上,我们的单一BERT模型在F1 Score方面超过了顶级合集系统。在没有TriviaQA微调数据的情况下,我们只损失了0.1-0.4个F1,仍然以很大的优势超过了所有现有系统。
SQuAD 1.1的结果:
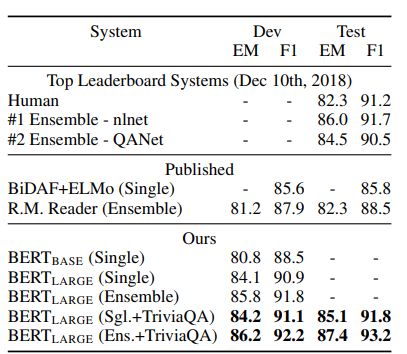
SQuAD 2.0的结果:

3、SQuAD v2.0
SQuAD 2.0任务扩展了SQuAD 1.1的问题定义,允许所提供的段落中不存在简短的答案,使问题更加现实。
我们使用一个简单的方法来扩展SQuAD v1.1 BERT模型来完成这项任务。我们将没有答案的问题视为有一个答案跨度,其起点和终点是[CLS]标记。开始和结束答案跨度位置的概率空间被扩展到包括[CLS]标记的位置。对于预测,我们将无答案跨度的得分: Snull= S ⋅ C S \cdot C S⋅C + E ⋅ C E \cdot C E⋅C与最佳非无答案跨度的得分Si,j = maxj≥i S ⋅ T i S \cdot Ti S⋅Ti + E ⋅ T j E \cdot Tj E⋅Tj 进行比较。当Si,j > Snull + τ 时,我们预测一个非空答,其中阈值τ是在dev set上选择的,以最大化F1。我们在这个模型中没有使用TriviaQA的数据。我们以5e-5的学习率和48的批次大小对2轮进行了微调。
与之前的排行榜条目和顶级发表的工作(Sun等人,2018;Wang等人,2018b)相比,结果显示在表3中,不包括使用BERT作为其组成部分之一的系统。我们观察到,与之前的最佳系统相比,F1提高了+5.1。
4、SWAG
Situations With Adversarial Generations(SWAG)数据集包含11.3万个句子对完成的例子,评估了基础常识推理(Zellers等人,2018)。给定一个句子,任务是在四个选择中选择最合理的续篇。
在对SWAG数据集进行微调时,我们构建了四个输入序列,每个序列都包含给定句子(句子A)和可能的续篇(句子B)的拼接。唯一引入的特定任务参数是一个向量,其与[CLS]标记表示法C的点积表示每个选择的分数,该分数用softmax层归一化。
我们以2e-5的学习率和16的批次大小对模型进行了3次微调。结果列于表4。BERTLARGE比作者的基线ESIM+ELMo系统高出27.1%,比OpenAI GPT高出8.3%。
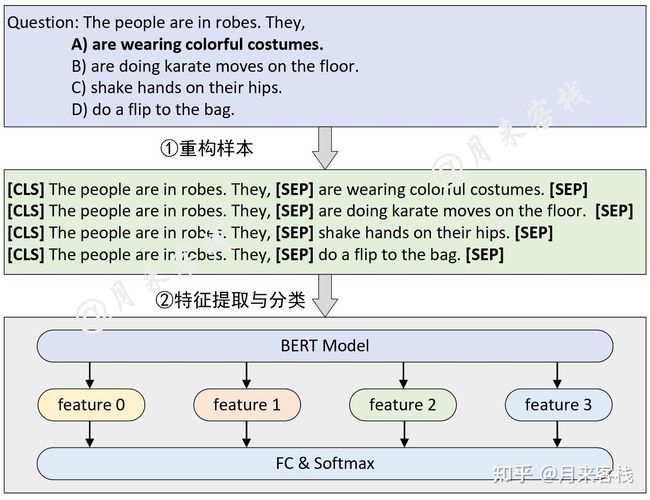
如图所示,是一个基于BERT预训练模型的四选一问答选择模型的原理图。从图中可以看出,原始数据的形式是一个问题和四个选项,模型需要做的就是从四个选项中给出最合理的一个,于是也就变成了一个四分类任务。同时,构建模型输入的方式就是将原始问题和每一个答案都拼接起来构成一个序列中间用[SEP]符号隔开,然后再分别输入到BERT模型中进行特征提取得到四个特征向量形状为[4,hidden_size],最后再经过一个分类层进行分类处理得到预测选项。值得一提的是,通常情况下这里的四个特征都是直接取每个序列经BERT编码后的[CLS]向量。
七、消融实验
ablation study往往是在论文最终提出的模型上,减少一些改进特征(如减少几层网络等),以验证相应改进特征的必要性。
1、预训练任务的影响
我们通过使用与 BERTBASE 完全相同的预训练数据、微调方案和超参数来评估两个预训练目标,从而证明 BERT 深度双向性的重要性。
- No NSP:假设去掉对下一个句子的预测
- LTR & No NSP:使用一个从左看到右的单向的语言模型(而不是用带掩码的语言模型),然后去掉对下一个句子的预测
- BiLSTM:在上面加一个双向的LSTM
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oP4KiA2K-1689904722400)(https://gitee.com/janjiang/23-summerstudy/raw/master/images/Week5/image-20.png)]
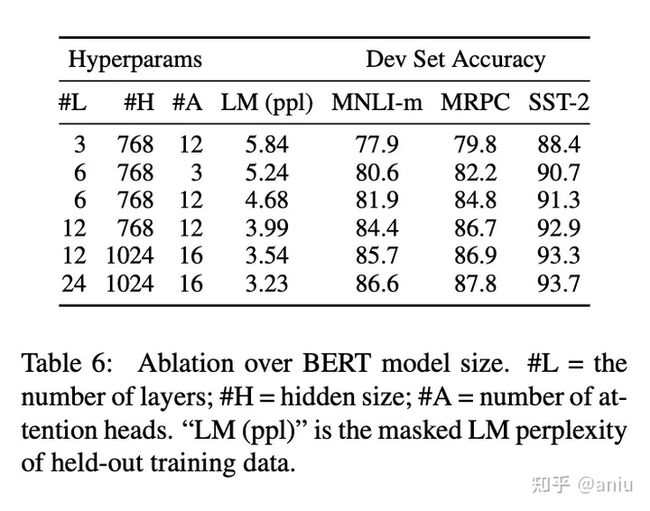
2、模型大小的影响
在本节中,我们探讨了模型大小对微调任务准确性的影响。我们训练了一些具有不同层数、隐藏单元和注意头的BERT模型,除此之外,还使用了与前面所述相同的超参数和训练程序。
BERTbase中有1亿的可学习参数
BERTlarge中有3亿可学习的参数
相对于之前的transformer,可学习参数数量的提升还是比较大的
当模型变得越来越大的时候,效果会越来越好,BERT是第一个对语言模型有较大提升的大规模模型
虽然现在GPT3已经做到1000亿甚至在向万亿级别发展,但是在三年前,BERT确实是开创性地将一个模型推到如此之大,并且引发了之后的模型大战。
3、基于特征的BERT方法
到目前为止,所有提出的BERT结果都使用了微调方法,即在预训练的模型中加入一个简单的分类层,并在下游任务中共同微调所有的参数。现在考虑基于特征的方法,即从预训练的模型中提取固定的特征,在本节中,我们通过将BERT应用于CoNLL-2003命名实体识别(NER)任务(Tjong Kim Sang和De Meulder,2003)来比较这两种方法。
BERTLARGE的表现与最先进的方法相比具有竞争力。表现最好的方法是将预训练好的Transformer的前四个隐藏层的标记表示拼接起来,这比微调整个模型只差0.3个F1。这表明,BERT对微调和基于特征的方法都很有效。

八、BERT的创新和局限性
1、创新点
将双向transformer用于语言模型。
2、局限性
(1)BERT模型的参数量很大,导致存储和训练都比较消耗资源;
(2)BERT模型使用了掩码语言模型(MLM)作为预训练目标,但这种方式会使预训练和微调阶段的输入不一致,因为预训练时有部分词被掩盖,而微调时并没有;
(3)BERT模型使用了下一句预测作为预训练目标,但这种方式并没有真正捕捉到句子之间的连贯性和逻辑关系,而是更倾向于依赖主体信息;
(4)BERT模型对中文的处理是以字为单位的,忽略了词语和短语等更高层次的语义信息;
(5)使用BERT模型时最多只能输入512个词,因为在BERT的config文件中,“max_position_embeddings:512”;
(6)BERT模型在做生成类任务时效果不够好。
3、改进模型
(1)RoBERTa
RoBERTa并没有去更改BERT的网络结构,只是修改了一些预训练时的方法,其中包括:动态掩码(Dynamic Masking)、舍弃NSP(Next Sentence Predict)任务。
RoBERTa也采用更大规模预训练数据,以更大的批次和BPE词表训练更多步数。




(2)ALBERT
ALBERT提出利用「词向量因式分解」、「跨层参数共享」以及「句子顺序预测任务」来减小模型大小并提升模型训练速度。
- 词向量因式分解:词向量只是记忆了相对少量的词语的信息,更多的语义和句法等信息是由隐藏层记忆的。因此词嵌入的维度E不必与隐藏层的维度H一致,引入一个全连接层,将词嵌入维度E映射到隐藏层维度H,词向量部分的复杂度就从O(VH)降到了O(VE+EH),当H≫E的时候参数量明显降低;
- 跨层参数共享:ALBERT中所有transformer layer的参数都是一样的,节省了模型的大小;
- 句子顺序预测任务:positive sample仍然是两个顺序的句子,而negative sample是两个句子调换顺序,让模型学习句子顺序是否正确。

(3)MacBERT
MacBERT提出,可以不使用[MASK]标记,而是将[MASK]标记位置的词替换成「另外一个近义词」,然后让模型去进行「词语纠错」。
和BERT类似,MacBERT对15%的输入单词进行掩蔽,其中80%将替换为相似的单词,10%将替换为随机单词,剩下的10%将保留原始单词(BERT中将80%设置为[MASK],其余一样)。