Patch2Pix(CVPR 2021)特征点检测与匹配论文精读笔记
前言
论文地址
论文补充材料 / 附录
代码地址
翻译并记录阅读每段的感受和写作逻辑。大概了解特征点检测和目标检测的大致方法的话,不用递归式读论文也能基本理解本文的方法。
参考文献
检测:
[5] SuperPoint
[6] D2-Net
[7] Beyond cartesian representations for local descriptors (CVPR 2019)
[16] Contextdesc: Local descriptor augmentation with cross-modality context (CVPR 2019)
[17] Aslfeat
[28] R2D2
[40] Learning feature descriptors using camera pose supervision (ECCV 2020)
匹配:
[3] Neural-guided ransac: Learning where to sample model hypotheses (ICCV 2019)
[10] S2dnet: Learning accurate correspondences for sparse-to-dense feature matching (ECCV 2020)
[22] Learning to find goodcorrespondences (CVPR 2018)
[33] SuperGlue
[38] Acne: Attentive context normalizationfor robust permutation-equivariant learning (CVPR 2020)
[42] Learning two-view correspondences and geometry using order-aware network (ICCV 2019)
检测 + 匹配:
[13] Dual-resolution correspondence networks (NIPS 2020)
[29] Convolutional neural network architecture for geometric matching (CVPR 2017)
[30] Efficient neighbourhood consensus networks via submanifold sparse convolutions (ECCV 2020)
[31] Neighbourhood consensus networks (NIPS 2018)
1. Introduction
寻找图像的对应关系(也就是特征点检测与匹配)是 SfM、SLAM 等任务的基本步骤,包括3个步骤:(1)检测特征点并提取描述符;(2)用描述符匹配特征点;(3)排除错误匹配。任务的适用领域和流程。
传统算法局限性。[5,6,7,16,17,28,40] 用 CNN 学习特征点检测和描述,效果不错。[3,22,38,42] 建议学一个过滤函数来做第三步排除错误匹配,而不是专注于优化第一步的效果。简单描述 SuperGlue 的做法。结合特征检测器和匹配器作为一个完整的 pipeline 是个好方向。传统算法到深度方法,并引出要把检测和匹配合并到一个网络里。
[13,30,31] 已经做了这个工作,用单个网络输入图像对,直接得到对应关系。难点是达到像素级精度并匹配准确。[29] 在低分辨率上做匹配,精度不够。[30] 用稀疏卷积在高分辨率上匹配,但还是不能实现像素级匹配。[30,31] 的优点是用弱监督最大化匹配对的得分并最小化非匹配对的得分,但是在像素级匹配上学习效率太低。和需要 ground truth(GT) 的强监督方法 [SuperPoint, D2-Net, S2dnet, Aslfeat, R2D2, SuperGlue] 对比,GT 虽然很准但也可能增加学习的误差,譬如稀疏的关键点作为 GT 可能会简单的学习这些点而不是更一般的特征(个人理解就是由数据导致的过拟合)。[40] 利用相机姿态做弱监督来解决这种问题,并且和 [30,31] 相比更精确。现有的一些方法和他们的缺点,因为本文用的和 [40] 一样的弱监督,就说明了一下这种训练模式的好处。
本文提出 Patch2Pix,用一个新的角度来设计网络。受目标检测的启发,首先得到 patch-level 的匹配,再细化到 pixel-level 的匹配。网络用相机姿态计算得到的对极几何(epipolar geometry)做弱监督,回归出 patch proposal 中的像素级匹配。和 [40] 相比,本文从匹配位置学匹配,从匹配得分学特征描述符。本文方法 SOTA。本文贡献:(1)提出了一个新的角度来学对应关系,先得到 patch-level 的匹配,再细化到 pixel-level 的匹配。(2)一种新的匹配细化网络,可以同时细化匹配并排除错误匹配,且训练不需要像素级的 GT 对应关系。(3)模型在图像匹配、单应性估计、视觉定位等方面提高了匹配精度。(4)模型可以直接推广到强监督方法,且取得 SOTA 结果。因为训练数据是和 [40] 一样的,而在这个领域感觉做数据的方法是个很重要的部分,这边就提了一句训练策略上的不同,其他的就是常规的本文贡献。从这段来看,本文的核心是一种细化的策略,并且细化策略可以推广到别的方法上的,通常的方法是在低分辨率特征图上得到结果再用插值还原到原图分辨率,而本文用了更好的细化方法。
Fig. 1:Patch2Pix 的一个样例。上半张图由匹配的置信度得分来着色,得分越低越蓝,主要在路上和空白的墙上。下半张图说明了靠里的一些匹配可以在这种大视角变化下成功匹配。论文第一幅图是一个结果的可视化,直观地表明论文是干啥的。
2. Related Work
介绍了一下 [6,17,28,40] 的做法,这些都是学局部特征,需要一个匹配步骤得到对应关系。
Matching and Outlier Rejection. 有了特征点和描述符,就可以计算描述符的欧氏距离并用最近邻搜索得到匹配。异常值通常用一致性或匹配得分过滤。 [3,22,38,42] 让网络做二分类来排除异常值,或者用 RANSAC 对输入匹配做加权,这些方法并由让网络学习用来匹配的特征或匹配函数,而是改进已有的匹配和对应关系。[10,33] 学了匹配函数。SuperGlue[33] 用带注意力机制的图神经网络优化 SuperPoint[5] 的描述符,并用 Sinkhorn algorithm 计算匹配。S2DNet[10] 提取一幅图像 SuperPoint[5] 特征点位置的局部特征(稀疏),对另一幅图像全图提取特征(密集),利用相似度得分峰值计算匹配。这些方法主要是优化特征点的描述符,但没有优化特征点检测方面的问题。列举了一些单做匹配和排除异常值的方法,他们的问题是不参与特征点的检测,不过把检测和匹配一起做,匹配效果应该会更好。
End-to-End Matching. [13,30,31] 一个正向传递完成检测、匹配、排除异常值。NC-Net[31] 用一个 correlation layer[29] 做匹配操作,用 4D 卷积层算邻域一致性得分优化匹配得分,但是受内存限制,在下采样16倍的特征图上做匹配精度太低。SparseNCNet[30] 用前10的相似度得分作为相关性张量的稀疏表示,并用稀疏卷积代替密集的 4D 卷积,从而可以在下采样4倍的特征图上做匹配。和本文同期的 DualRC-Net[13] 结合粗分辨率和细分辨率的特征图得到匹配得分。本文和 [13,30] 不一样,是用回归层将匹配细化到原图分辨率。一些也把检测匹配全做了的方法以及和本文的不同。
Full versus Weak Supervision. (个人翻译为强监督和弱监督)作者认为需要精确的 GT 来指导损失为强监督,不需要 GT 为弱监督。大多数方法都是用 GT 的,譬如 D2-Net[6]、S2dnet[10]、Aslfeat[17] 利用相机姿态和深度图,SuperPoint[5]、R2D2[28] 利用合成单应性变换,少数方法如 CAPS[40] 用对极几何做弱监督。S2DNet[10] 和 SuperGlue[33] 也要 GT。[3,22,38,42] 这些排除异常值的方法由图像对间的几何变换做弱监督。DualRC-Net[13] 是强监督,SparseNCNet[30] 和 NC-Net[31] 用弱监督优化图像对的平均匹配得分,而不是单个匹配。本文用对极几何做弱监督,匹配坐标直接回归和优化。相比之下 CAPS[40] 用同样的监督学特征描述符,用匹配得分优化损失,匹配得分的索引给出匹配位置。基于 SparseNCNet[30] 和 NC-Net[31] 作者提出了 two-stage 匹配网络,在原图分辨率上预测匹配。这段像是报菜名,各种方法用的监督策略,不过用弱监督的只有 CAPS[40],并再次强调了一下和 [40] 的区别。
3. Patch2Pix: Match Refinement Network
匹配网络(correspondence network)的好处是可以直接优化特征匹配,而不需要明确定义特征点。网络所发现的匹配关系可以反映出特征点检测和描述。现有匹配网络不准确的两个原因:(1)内存的限制导致要用下采样的特征图做匹配。(2)SparseNCNet[30] 和 NC-Net[31] 用弱监督训练的时候让不是匹配对的匹配得分变低,是匹配对的得分变高,这样并不能让网络识别出好的匹配或坏的匹配,导致无法得到像素级精确的匹配。分析其他方法精度不够的原因。
为了解决这两个问题,提出了一个两阶段的 detect-to-refine 方法,灵感来自 Faster R-CNN。在第一个检测阶段,用一个匹配网络,譬如 NC-Net,得到 patch-level 的匹配。第二个阶段用两种方法细化匹配:(1)用分类得到匹配的置信度;(2)用回归得到以 patch 为中心的像素级分辨率的匹配。作者的直觉是匹配网络用高级特征得到 patch-level 的语义匹配,而细化网络可以关注局部结构的细节,得到精确的匹配位置。网络用弱监督的对极损失训练,使匹配满足相机姿态的几何约束。网络结构看 Fig. 2。下面以 NC-Net 为基线做匹配,本文的方法可以推广到其他类型的匹配方法上。解决问题的方法,并且明确了本文主要是以目标检测为灵感做的一个细化网络,可以代替通常的插值细化,让匹配的精度变高。

Fig. 2
Top:输入一对图像,先用 ResNet34 做 backbone 提取特征,然后送到 correspondence network 网络,譬如 NC-Net 的匹配层得到 match proposals。Patch2Pix 利用之前提取的特征图来细化这些 proposals。
Bottom:设计了两个不同等级但具有相同架构的回归器来逐步细化 match proposals 到原图分辨率。以一个 match proposal m i m_i mi 为中心的一对 S × S S\times S S×S local patches,收集 patches 的特征输入到 mid-level 回归器并输出 (1) 置信得分 c i ^ \widehat{c_i} ci 代表 match proposal 的质量 (2) 在 local patches 中找到的像素级局部匹配 δ i ^ \widehat{\delta_i} δi 。更新后的 match proposal m i ^ \widehat{m_i} mi 通过新的 local patches 更新搜索空间。 fine-level 回归器输出最终的 c i ~ \widetilde{c_i} ci 和 δ i ~ \widetilde{\delta_i} δi 以及像素级匹配 m i ~ \widetilde{m_i} mi 。整个网络在弱监督下训练,不需要明确的 GT 对应关系。
3.1. Refinement: Pixel-level Matching
Feature Extraction: 输入图像对 ( I A , I B ) (I_A,I_B) (IA,IB) 给一个 L L L 层的 CNN 提取特征图。令 f l A , f l B f_l^A,f_l^B flA,flB 为 ( I A , I B ) (I_A,I_B) (IA,IB) 在 l l l 层的特征图, l = 0 l=0 l=0 时为原图,即 f 0 A = I A f_0^A=I_A f0A=IA。特征图只提取一次,用到检测和细化两个阶段。检测只用最后一层特征,包含更多高级信息;细化用最后一层之前的特征,包含更多低级细节。
From match proposals to patches: 给定一个匹配 m i = ( p i A , p i B ) = ( x i A , y i A , x i B , y i B ) m_i=(p_i^A, p_i^B)=(x_i^A,y_i^A,x_i^B,y_i^B) mi=(piA,piB)=(xiA,yiA,xiB,yiB),细化阶段的目标是在 patch-level 匹配的局部区域上找到 pixel-level 的精确匹配。由于在缩小的特征图上匹配,因此在特征图上误差1个像素会导致在原图上有 2 L − 1 2^{L-1} 2L−1 的误差。因此,定义搜索区域为以 p i A p_i^A piA 和 p i B p_i^B piB 为中心的 S × S S \times S S×S local patch,让 S > 2 L − 1 S>2^{L-1} S>2L−1 使其比原来 2 L − 1 × 2 L − 1 2^{L-1}\times2^{L-1} 2L−1×2L−1 的 patch 覆盖更多的区域。从所有的 match proposals 中得到一组 local patch pairs 后,网络从 local patch pairs 的特征图中回归出 pixel-level 的匹配。
Local Patch Expansion: 提出了一个 patch 扩展机制,如 Fig. 3,用邻域扩展搜索区域。将 p i A p_i^A piA 沿 x x x 轴和 y y y 轴4个角各移动 d d d 个像素。这给了我们4个 p i A p_i^A piA 的 anchor points 来匹配 p i B p_i^B piB 得到4个新的 match proposals。同样扩展 p i B p_i^B piB 并与 p i A p_i^A piA 匹配也得到4个新的 match proposals。8个 proposals 确定了8对 S × S S \times S S×S 的 local patches。设置 d = S / 2 d=S/2 d=S/2,扩展的搜索区域大小为 2 S × 2 S 2S \times 2S 2S×2S,并且仍然覆盖原来的 S × S S \times S S×S 区域。patch 扩展 M p a t c h M_{patch} Mpatch 在训练的时候很有用,因为可以强迫网络在空间接近且相似的特征中得到正确的匹配。这个扩展机制可以加快学习过程并提高模型性能。虽然在测试的时候也可以用来扩大搜索范围,但是计算量比较高,所以在测试过程中没用。初看有点懵,没明白是干啥的。
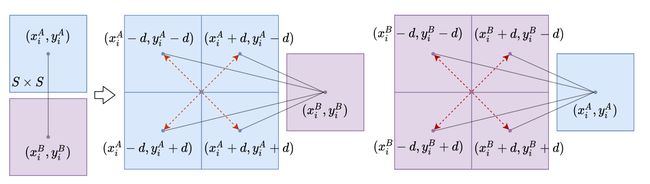
Fig. 3:描述和段落中的基本一样
Progressive Match Regression: 细化任务是在一对 local patches 中找到好的匹配。用了两个相同架构做 mid-level 和 fine-level,逐步得到最终的匹配。给定一对 S × S S \times S S×S 的 patches,先提取特征图中对应的特征信息 f l A , f l B {f_l^A},{f_l^B} flA,flB。patch 上的每个点 ( x , y ) (x,y) (x,y),在 l l l 层特征图上对应的位置为 ( x / 2 l , y / 2 l ) (x/2^l,y/2^l) (x/2l,y/2l)。选择了 { 0 , … , L − 1 } \{0, \dots,L-1\} {0,…,L−1} 层中所有的特征连接成一个特征向量。将两个 feature patches P F i A , P F i B PF_i^A, PF_i^B PFiA,PFiB 沿特征维度拼接并输入到 mid-level 回归器中。回归器首先用两个卷积把输入特征合成为特征向量,然后用两个全连接层处理,最后网络的预测为两个全连接层的输出。一个做回归,输出一组与 S × S S \times S S×S local patches 中心像素相关的 local matches M ^ Δ : = { δ ^ i } i = 1 N ⊂ R 4 \widehat{M}_{\Delta}:=\left\{\widehat{\delta}_{i}\right\}_{i=1}^{N} \subset R^{4} M Δ:={δ i}i=1N⊂R4,其中 δ i ^ = ( δ x i A ^ , δ y i A ^ , δ x i B ^ , δ y i B ^ ) \widehat{\delta_{i}}=\left(\widehat{\delta x_{i}^{A}}, \widehat{\delta y_{i}^{A}}, \widehat{\delta x_{i}^{B}}, \widehat{\delta y_{i}^{B}}\right) δi =(δxiA ,δyiA ,δxiB ,δyiB )。另一个做分类,用 sigmoid 得到置信得分 C ^ p i x e l = ( c 1 ^ , … , c N ^ ) ∈ R N \widehat{\mathcal{C}}_{pixel}=\left(\widehat{c_{1}}, \ldots, \widehat{c_{N}}\right) \in R^{N} C pixel=(c1 ,…,cN )∈RN,表示匹配的有效性。把 local matches 和 patch matches 加起来从而得到了 mid-level 匹配 M ^ p i x e l : = { m ^ i } i = 1 N \widehat{M}_{pixel}:=\left\{\widehat{m}_{i}\right\}_{i=1}^{N} M pixel:={m i}i=1N, m ^ i = m i + δ ^ i \widehat{m}_{i}=m_i+\widehat{\delta}_{i} m i=mi+δ i。以 mid-level 的匹配为中心得到新的 S × S S \times S S×S patch pairs,把它们的特征输入到 fine-level 回归器,按照 mid-level 回归一样的流程得到 pixel-level 匹配 M ~ p i x e l : = { m i ~ } i = 1 N \widetilde{M}_{pixel}:=\left\{\widetilde{m_{i}}\right\}_{i=1}^{N} M pixel:={mi }i=1N 和置信得分 C ~ p i x e l = ( c 1 ~ , … , c N ~ ) ∈ R N \widetilde{\mathcal{C}}_{pixel}=\left(\widetilde{c_{1}}, \ldots, \widetilde{c_{N}}\right) \in R^{N} C pixel=(c1 ,…,cN )∈RN。
看完这段大致理解了本文的做法,图像对先经过一个 CNN 提取特征,将最后一层特征按 NC-Net 的匹配方式得到一些匹配结果,原本这些匹配结果也是点对点的,但是因为是在低分辨率特征图上得到的结果,所以把它当做两个 S × S S \times S S×S 大小区域的匹配。通过特定方式提取出了这两个区域的特征,并且拼到一起输入到细化网络,经过一些卷积和全连接,得到一个 mid-level 的匹配坐标和匹配置信度;按同样的方式迭代一次得到 fine-level 也就是 pixel-level 的结果。此时也大致明白了 patch 扩展机制,一对匹配扩展成8对,扩大匹配搜索的范围。
此时不太清楚 patch 对应的特征是什么形式的,从 Fig. 2 来看是把原图像和前三层的特征图拼起来,但是这些特征图分辨率都不一样,应该需要采样到一个统一的分辨率。而且把两张图像的特征图拼接起来进去卷积加全连接得到结果总感觉怪怪的,似乎与找到精确的匹配和置信度没有很强的联系。
3.2. Losses
pixel-level 匹配损失 L p i x e l \mathcal{L}_{pixel} Lpixel 包含两项:(1)置信得分的分类损失 L c l s \mathcal{L}_{cls} Lcls,预测是不是真的匹配;(2)几何损失 L g e o \mathcal{L}_{geo} Lgeo 用了判断回归的准确性。最终 L p i x e l = α L c l s + L g e o \mathcal{L}_{pixel} = \alpha\mathcal{L}_{cls}+\mathcal{L}_{geo} Lpixel=αLcls+Lgeo,其中 α = 10 \alpha=10 α=10。
Sampson distance: 为了得到像素级匹配,监督网络寻找图像对上对极几何一致的对应关系。它定义了两个正确匹配的点应该在使用相对相机姿态变换投影到另一个图像时位于它们对应的对极线上。可以通过 Sampson distance 精确测量有多少预测的匹配满足对极几何。给定一个匹配 m i m_i mi 和由图像对的相对相机姿态计算得到的 fundamental matrix F ∈ R 3 × 3 F\in R^{3\times3} F∈R3×3,Sampson distance ϕ i \phi_i ϕi 计算了匹配的几何误差:
ϕ i = ( ( P i B ) T F P i A ) 2 ( F P i A ) 1 2 + ( F P i A ) 2 2 + ( F T P i B ) 1 2 + ( F T P i B ) 2 2 \phi_{i}=\frac{\left(\left(P_{i}^{B}\right)^{T} F P_{i}^{A}\right)^{2}}{\left(F P_{i}^{A}\right)_{1}^{2}+\left(F P_{i}^{A}\right)_{2}^{2}+\left(F^{T} P_{i}^{B}\right)_{1}^{2}+\left(F^{T} P_{i}^{B}\right)_{2}^{2}} ϕi=(FPiA)12+(FPiA)22+(FTPiB)12+(FTPiB)22((PiB)TFPiA)2
其中, P i A = ( x i A , y i A , 1 ) T P_{i}^{A}=\left(x_{i}^{A}, y_{i}^{A}, 1\right)^{T} PiA=(xiA,yiA,1)T, P i B = ( x i B , y i B , 1 ) T P_{i}^{B}=\left(x_{i}^{B}, y_{i}^{B}, 1\right)^{T} PiB=(xiB,yiB,1)T, ( F P i A ) k 2 \left(F P_{i}^{A}\right)_{k}^{2} (FPiA)k2 和 ( F P i B ) k 2 \left(F P_{i}^{B}\right)_{k}^{2} (FPiB)k2 代表向量第 k k k 项的平方。
虽然不懂 Sampson distance 的原理,但感觉可以理解为两个点的间距,完美匹配则间距为0。
Classification loss: 当一对匹配 m i = ( x i A , y i A , x i B , y i B ) m_i=(x_i^A,y_i^A,x_i^B,y_i^B) mi=(xiA,yiA,xiB,yiB) 的 ϕ i < θ c l s \phi_{i}<\theta_{cls} ϕi<θcls 则为正样本, θ c l s \theta_{cls} θcls 为阈值,其他的匹配则为负样本。给定预测的置信度得分 C \mathcal{C} C 和二分类标签 C ∗ \mathcal{C}^* C∗,用交叉熵做损失:
B ( C , C ∗ ) = − 1 N ∑ i = 1 N w c i ∗ log c i + ( 1 − c i ∗ ) log ( 1 − c i ) \mathcal{B}\left(\mathcal{C}, \mathcal{C}^{*}\right)=-\frac{1}{N} \sum_{i=1}^{N} w c_{i}^{*} \log c_{i}+\left(1-c_{i}^{*}\right) \log \left(1-c_{i}\right) B(C,C∗)=−N1i=1∑Nwci∗logci+(1−ci∗)log(1−ci)
其中,权重 w = ∣ { c i ∗ ∣ c i ∗ = 0 } ∣ / ∣ { c i ∗ ∣ c i ∗ = 1 } ∣ w=\left|\left\{c_{i}^{*} \mid c_{i}^{*}=0\right\}\right| /\left|\left\{c_{i}^{*} \mid c_{i}^{*}=1\right\}\right| w=∣{ci∗∣ci∗=0}∣/∣{ci∗∣ci∗=1}∣ 用来平衡正负样本数量。mid-level 和 fine-level 有各自的阈值 θ ^ c l s \widehat{\theta}_{cls} θ cls 和 θ ~ c l s \widetilde{\theta}_{cls} θ cls,求和得到最终的分类损失 L c l s \mathcal{L}_{cls} Lcls。
Geometric loss: 为了避免训练回归器去细化那些不好的匹配,只有当父级匹配的 Sampson distance 小于阈值 θ g e o \theta_{geo} θgeo 才计算损失。Geometric loss 是优化匹配的平均 Sampson distance,同样mid-level 和 fine-level 有各自的阈值 θ ^ g e o \widehat{\theta}_{geo} θ geo 和 θ ~ g e o \widetilde{\theta}_{geo} θ geo,求和得到最终的几何损失 L g e o \mathcal{L}_{geo} Lgeo。
两个损失和检测的也很像,看到这里也能理解 patch 扩展时的 anchor points。分类损失对所有 anchor 计算,检测里面用 IoU 阈值判定正负样本,这里用 Sampson distance 的阈值,明确了正负样本就能正常使用交叉熵了。几何损失对应检测里的 box 回归损失,同样是只计算正样本的损失,检测里通过最小化 IoU,这里最小化 Sampson distance。
4. Implementation Details
用预训练的 NC-Net 的匹配层来匹配从 backbone 中提取的特征。细化网络在 MegaDepth 上训练,构建了60661个匹配对。 mid-level 的阈值 θ ^ c l s = θ ^ g e o = 50 \widehat{\theta}_{cls}=\widehat{\theta}_{geo}=50 θ cls=θ geo=50,fine-level 的阈值 θ ~ c l s = θ ~ g e o = 5 \widetilde{\theta}_{cls}=\widetilde{\theta}_{geo}=5 θ cls=θ geo=5。 S = 16 S=16 S=16,即 local patch 的大小在原图分辨率上为 16 个像素。用 Adam 做优化器,开始的5个 epoch 学习率为 5 e − 4 5e^{-4} 5e−4,然后用 1 e − 4 1e^{-4} 1e−4 直到收敛。一个 mini-batch 包含4对 480 × 320 480\times320 480×320 的图像。
5. Evaluation on Geometrical Tasks
5.1. Image Matching
第一个实验是在 HPatches 上做图像匹配,检测输入图像对之间的对应关系。跟 D2Net 一样算了1到10个像素下的平均匹配精度(mean matching accuracy,MMA),包括匹配和特征的数量。
Experimental setup: 用 fine-level 回归得到的置信得分来过滤异常值,用了两个阈值 c = 0.5 / 0.9 c=0.5/0.9 c=0.5/0.9。为了体现细化的有效性,与 baseline NCNet[31] 作比较。还和SparseNCNet[30] 作比较,他是和本文工作最像的,也是在 NCNet 的基础上通过重新定位机制提高匹配准确性。除了与几种使用 NN 搜索匹配局部特征的方法比较外,还考虑了用 SuperGlue[33] 匹配 SuperPoint[5],并研究了他们在默认阈值 c = 0.2 c=0.2 c=0.2 和更高的阈值 c = 0.9 c=0.9 c=0.9 过滤异常值的性能。
Results: 如 Fig. 4 所示,NCNet 在光照变化但视角不变的情况下效果很好,因为它用的是固定上采样,光照变化的性能体现了它在 patch-level 匹配的效率,视角变化的性能体现它在 pixel-level 匹配的不足。本文的细化网络将 NCNet 预测的 patch-level 匹配细化到 pixel-level 匹配,大大提高视角变化下的精度,并进一步提高光照变换下的精度。和所有弱监督方法相比,两个阈值在光照变化下的结果都是最好的。对于视角变化,我们的模型在 c = 0.9 c=0.9 c=0.9 时效果最好,SparseNCNet 的效果和 c = 0.5 c=0.5 c=0.5 时的效果差不多。和强监督方法相比,光照变化下 c = 0.9 c=0.9 c=0.9 时的效果优于所有方法。视角变化下,我们的方法不如 SuperPoint + SuperGlue,但优于其他所有的方法。结合图表可以发现,SuperPoint + SuperGlue 和我们的方法用高阈值过滤低置信度的预测都可以提高性能。
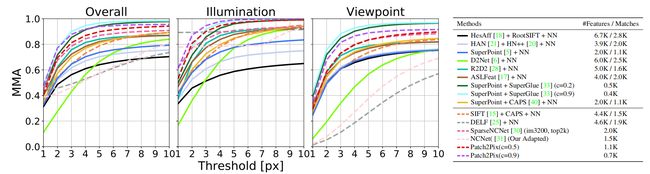
Fig. 4:Image Matching on HPatches
5.2. Homography Estimation
精确的匹配不一定能得到准确的几何关系,因为在估计几何关系的时候匹配的分布和数量也很重要。因此接下来依然在 HPatches 上做单应性估计来评估网络。
Experimental setup: 和 [5,33,40] 一样用 corner correctness metric,并给出单应性估计正确的百分比(平均角误差距离小于 1/3/5 个像素)。实验中,用基于 RANSAC 的求解器来估计几何关系,取 c = 0.25 c=0.25 c=0.25 作为置信度阈值。设置一个较低的阈值是为了过滤掉非常差的匹配,但尽可能留下更多的信息,然后让 RANSAC 自己过滤异常值。我们与在匹配任务中更有竞争力的方法进行比较,这些方法按监督类型分类:强监督(full),弱监督(weak),混合监督(两种都用)。我们在自己的环境下运行了所有的方法,并测量了匹配时间。
Results: 从 Tab. 1 中可以看出,NCNet 依然是在光照变化下效果很好。这里验证了在视角变化下,单应性估计的质量也能反应出 Patch2Pix 对匹配的改进。SparseNCNet 和我们的方法一样,都是通过寻找匹配的 local patches 在更高分辨率的特征图上逐步定位更精确的匹配,从而提高匹配精度。但是我们的方法在原图分辨率上预测匹配并且是完全可学习的(fully learnable),而他们不可学习的(non-learning)方法是在下采样4倍的分辨率上得到的匹配(这里也不知道该咋翻译这个可不可学习)。我们的方法比他们好了很多,1个像素内的整体精度高了 15%。光照变化下,我们是仅次于 NCNet 的第二优方法,但比所有强监督的方法都好。在视角变化下,我们是弱监督方法中1个像素内精度最高的,并得到了非常接近最优的 SuperPoint + SuperGlue 的精度。
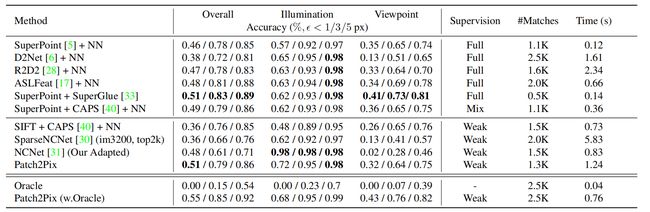
Tab. 1:Homography Estimation on Hpatches
看到这里发现,虽然 Patch2Pix 并不是在所有的方法里面都达到了最优,但是作者按照监督策略分了下类,在同类里面达到效果最好;文字叙述里面主要针对 baseline NCNet 和与自己方法比较相似的 SparseNCNet 做比较;像第一个实验整体没到最优就避开不谈,聊单类的精度,第二个实验整体有一项最优了就点一下。主要还是超不过 SuperPoint + SuperGlue,这个个人感觉是自监督,整体的思路方法都很牛。
Oracle Investigation: 由于我们的方法可以过滤掉错误的匹配,但不能产生新的匹配,如果 NCNet 不能产生足够的有效匹配,我们的性能也会受影响,这可能是在视角变化中性能较低的原因。为了验证这个假设,我们用 Oracle matcher 替换 NCNet。给定一对图像,Oracle 从 GT 中随机选择2.5K个匹配,然后在以 GT 为中心的 12 × 12 12\times12 12×12 范围中随机移动匹配点。通过这种方式得到了合成的 match proposals,并且在以他们为中心的 16 × 16 16\times16 16×16 local patches 中至少存在一个 GT 匹配,这样可以测试我们的细化网络的性能。如 Tab. 1 中所示,Oracle 的匹配精度是很低的,说明这个任务还是有一定的挑战性。而我们的结果很好,说明细化网络的性能受到了 NCNet 的限制。因此在接下来的实验中,为了看到我们网络的潜力,也会把 SuperPoint + SuperGlue 作为 baseline 来生成 match proposals。
这个实验有点巧妙,把效果不好的原因归到了 NCNet 上,并且给了打不过就加入一个正当的理由,用 SuperPoint + SuperGlue 做 baseline,可以预想效果是会超过 baseline 的。这也体现了本文方法的优点,在这个领域的各种方法上运用都能有性能提升,用最好的做 baseline 依然提升了,自然也就 SOTA 了。但是此文的创新也就不太算是流程上的创新了,只是提出了一种较好的优化方法,可以提升精度,提升别的网络的上限;而自身的上限依然受到他人的流程所限制。
5.3. Outdoor Localization on Aachen Day-Night
在 Aachen Day-Night benchmark (v1.0) 上测试昼夜光照变化的室外定位的性能。
Experimental setup: 为了 localize Aachen night-time queries,我们参照了 https://github.com/tsattler/visuallocalizationbenchmark 的评估设置。为了同时评估白天和夜晚的图像,我们采用了 https://github.com/cvg/Hierarchical-Localization 中提出的 hierarchical localization pipeline (HLOC)。然后将匹配方法插入到 pipeline 中来估计 2D 对应关系。我们给出了特定阈值下 correctly localized queries 的百分比。用 NCNet 和 SuperPoint + SuperGlue 做 baseline 测试了我们的模型,但是训练只在 NCNet 上。由于 localization pipeline 中的三角测量阶段 (triangulation stage),我们用平均位置间距小于4个像素的特征点来量化匹配。
Results: 在 night-time queries 上测试,由于其他两个弱监督算法。虽然比 SuperPoint + CAPS 差一些,但它同时涉及强监督和弱监督,而我们比其他强监督方法要好点或差不多。对于 full localization on all queries using HLOC,我们证明了比 SuperPoint + NN 要好。通过进一步用 SuperGlue 取代 NCNet ,在日间图像上和 SuperGlue 差不多,并在夜间略超过他。我们的直觉是这是受益于对极几何监督,可以学习更一般的特征,而不会从训练数据中产生偏差,下一个实验进一步证明这个观点。
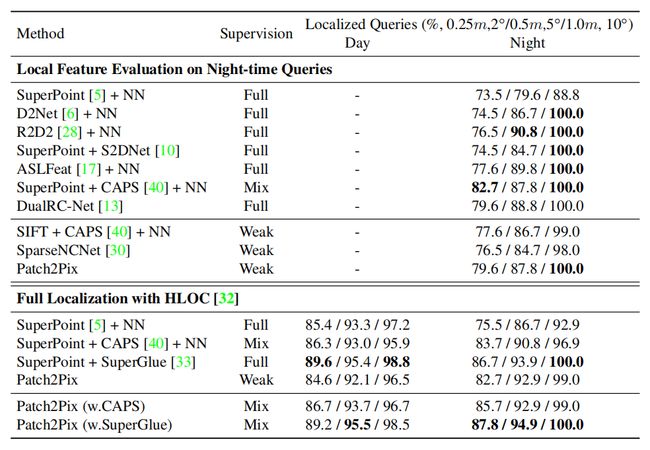
Tab. 2:Evaluation on Aachen Day-Night Benchmark (v1.0)
不太懂这个实验的评估。
5.4. Indoor Localization on InLoc
在 InLoc benchmark 上测试室内定位的性能,数据场景中有大量无纹理和重复结构的区域。
Experimental setup: 和 SuperGlue 一样,用在 HLOC 中预测的对应关系来评估匹配算法。我们给出了特定阈值下 correctly localized queries 的百分比。与在 Aachen Day-Night 上的评估相比,我们的方法由于量化损失了高达4个像素的精度,我们采用了更公平的比较在 InLoc 上(不用 triangulation)。这些结果直接反应我们与其他方法结合时的细化效果。除了 SuperPoint + SuperGlue 以外,我们还评估了其他方法的一些组合,并与他们的最佳结果对比。
Results: Patch2Pix 是弱监督中效果最好的,并优于除 SuperPoint + SuperGlue 以外的所有方法。注意,在 DUC2 上比 SparseNCNet 好了 14.5%,进一步证明了我们的细化网络比他们的手工重新定位方法更有效。表格最后一行,当用 SuperPoint + SuperGlue 取代 NCNet 时取得了最好的整体性能。我们的网络可以找到更准确和鲁棒的匹配,从而优于 SuperPoint + SuperGlue。这说明对极几何监督在匹配任务中很有效。虽然 CAPS 也用这个对极损失训练,但它的性能主要依赖特征点检测阶段。相反,我们是直接处理潜在的匹配绕过了特征点检测的错误。

Tab. 3:InLoc Benchmark Results
Generalization: 通过在图像匹配和单应性估计上评估 Patch2Pix,与 NCNet 匹配相比有显著改进,证明了我们的细化策略。虽然我们只在 NCNet 上训练,但是从 NCNet 切换到 SuperPoint + SuperGlue 上不需要再训练。这突出了我们的细化网络所学习的是从一对 local patches 中预测匹配的这种更通用的任务,在不同的场景中都有效,并且与 local patches 的获取方式无关。这种通用的匹配能力可以进一步改进现有方法。如实验中 SuperPoint + SuperGlue 和 SuperPoint + CAPS 都可以用我们的细化网络来改进。
个人总结&想法
选择这篇文章全文翻译精度是因为很多想法不谋而合,在看了一些特征点检测和像素级对齐的论文以后,就产生了两个想法:
(1)用不同分辨率的特征图细化像素级对齐的精度
像素级对齐的精度不够主要也是因为在低分辨率上就得到了结果,再用线性插值回到原图分辨率。这主要也是受到内存限制,因为看过的所有相关方法都离不开计算特征相似度,一些方法在全图计算相似度,那自然特征图的分辨率会比较低;有些方法通过一些方式可以缩小搜索范围,这样就能让特征图分辨率稍微高点。其实这样自然就能有一个思路,先在低分辨率上大致对齐(patch-level),然后利用层级特征逐步细化,细化的时候搜索范围也比较小。不过事实上这样搞计算量也是很大的,做了些简单的实验效果也不太理想。印象中 Dual-resolution[13] 大概就是这样的做法。
(2)利用目标检测网络来检测特征点
起初的想法是把特征点当做目标,譬如设定是个全是 11 × 11 11\times11 11×11 大小的单类目标检测任务,直接套用现成的网络就能训练。但是这样的问题在于 GT 怎么来,看过 SuperPoint 就觉得特征点检测的自学习似乎只能这样做。自学习流程大致是先人工生成数据来训练网络,然后在真实数据上跑出一些结果,对这些结果进行筛选优化当做 GT 继续训练网络,不断迭代来优化网络。这里的难点有两个:(1)第一个人工生成的种子数据,这个数据一般不太自然但是绝对准确,除了 SuperPoint 的方法想不到什么更好的做法;(2)如何过滤网络的结果作为新的 GT,从人工数据转到自然数据以后会有很多的噪声,噪声不能很好的过滤会导致网络越来越差。
另外,用这种强监督的模式训练有个问题,那就是目标检测网络的目标损失,对于一个 anchor 是否存在目标是根据 GT 做的一个交叉熵损失,这样会导致网络是在学 GT 标定的点,而不会去发现潜在的点。
另一种数据类型是只知道两幅图像的像素级对应关系,譬如利用一些深度信息或者是人工做单应性变换等,这种数据可以训练网络提取特征描述符,但是比较难提取特征点,很多都是和 D2-Net 一样人工设计一种规则,特征向量满足一定要求则认为是特征点。通常创新点会在优化网络提取特征的过程和这个规则的设计。
1. Patch3Pix 方法总结
捋一下 Patch2Pix 的方法。输入一对图像,用个 ResNet-34 提取特征,得到4个层级输出的特征图 f 1 , f 2 , f 3 , f 4 f_1,f_2,f_3,f_4 f1,f2,f3,f4, f 0 f_0 f0 代表原图像。把 f 4 f_4 f4 输入到 NCNet 的匹配层中,得到了一些匹配。先跳过扩展机制,以一对匹配点为例,把以这一对点为中心的 S × S S\times S S×S 局部区域拿出来作为一对 local patches,并取出 patch 对应的特征图,即把 f 0 , f 1 , f 2 , f 3 f_0,f_1,f_2,f_3 f0,f1,f2,f3 连在一起,得到 P F i A , P F i B PF_i^A,PF_i^B PFiA,PFiB。再把两个特征图连在一起送到细化网络中,细化网络就是做了些卷积和全连接的操作,输出两个坐标的偏移量和匹配的置信度(这些操作看第3章的图2会比较清楚)。可以感受到上一轮的匹配结果就是下一轮的 anchor。
扩展机制就是原本得到一对点的匹配 ( p 1 , p 2 ) (p_1,p_2) (p1,p2),把它转化成 p 1 p_1 p1 和 p 2 p_2 p2 周围4个点匹配, p 2 p_2 p2 和 p 1 p_1 p1 周围4个点匹配,这样一来一对匹配转为8对匹配。这样就扩大了搜索匹配的范围,并且因为扩展的范围比较小, ( p 1 , p 2 ) (p_1,p_2) (p1,p2) 的匹配结果也在搜索范围内。其实也就是增加了 anchor 的数量。
定义好了输入输出就看怎么设计损失来训练了,而损失是依赖数据集的形式的。这里用的对极几何不是很了解,但总之可以衡量两个点的匹配度。这样就能衡量 anchor 本身的匹配度,用阈值决定这个 anchor 是不是正样本(对应 IoU 判断 anchor 中有没有目标),正样本的话计算输出坐标偏移的损失(对应检测中有目标的 anchor 才算 xywh 的损失)。
2. 疑问&想法
和实验部分说的一样,最终的效果很大程度受了 NCNet 的影响,也就是根本的匹配机制没有变,而是在这基础之上提高匹配的精度,不能挖掘出别的潜在的匹配。当然,要从根本上有创新是很难的。
细化网络按照论文中说的就是卷积+全连接,而输入的是拼接的两个区域特征,通常来说是用两个区域的特征相似度、特征距离来映射出匹配关系,这边直接用两个区域的特征感觉可解释性不强。后面有空看代码的话再补充一些实施细节。