跟ChatGPT同源插件,专为测试人的开放,快来看看吧
3 月 23 日,OpenAI 又投出了一枚重磅炸弹:为 ChatGPT 推出插件系统!
此举意味着 ChatGPT 将迎来“APP Store”时刻,也就是围绕它的能力,形成一个开发者生态,打造出基于 AI 的“操作系统”!
插件系统将为 ChatGPT 带来质的飞跃,因为借助于插件服务,它可以获取实时的互联网信息、调用第三方应用(预定酒店航班、点外卖、购物、查询股票价格等等)。
ChatGPT 是一个无比聪明的大脑,而插件会成为它的眼睛、耳朵、手脚、甚至于翅膀,能力惊人,未来不敢想象!
官方目前提供了两个插件:
- 一个网页浏览器。利用新必应浏览器的 API,实时搜索互联网内容,并给出答案和链接
- 一个代码解释器。利用 Python 解释器,可以解决数学问题、做数据分析与可视化、编辑图片、剪辑视频等等,还支持下载处理后的文件
另外,OpenAI 还开源了一个知识库检索插件 chatgpt-retrieval-plugin ,这个插件通过自然语言从各种数据源(如文件、笔记、邮件和公共文档)检索信息。有了开源代码后,开发者可以部署自己的插件版本。
想象一下,假如我提供了一个“Python 知识库插件”,以所有官方文档作为数据源,那以后有任何 Python 使用上的问题,我就只需询问 ChatGPT,然后它调用插件并解析数据,最后返回给我准确的答案。这将节省大量的时间!
不仅如此,你还可以用书籍作为数据源,打造出“西游记知识库”、“红楼梦知识库”、“百科全书知识库”、“个人图书馆知识库”,等等;以专业领域的论文与学术期刊为数据源,创造出一个专家助手,从此写论文查资料将无比轻松;以苏格拉底、乔布斯、马斯克等名人的资料为数据源,创造出人格化的个人顾问……
作为第一个开源的 ChatGPT 插件,chatgpt-retrieval-plugin 项目一经发布,就登上 Github 趋势榜第一,发布仅一周就获得 11K stars。
这个项目完全是用 Python 写的,不管是出于学习编程的目的,还是为了将来开发别的插件作借鉴,这都值得我们花时间好好研究一下。
接下来,我将分享自己在阅读项目文档和源码时,收获到的一些信息。
首先,该项目含 Python 代码约 3 K,规模不算大。项目结构也很清晰,目录如下:

除去示例、测试、配置文件等内容外,最主要的三个目录如下:
datastore 数据存储
数据源的文本数据会被映射到低维度向量空间,然后存储到向量数据库中。官方已提供 Pinecone、Weaviate、Zilliz、Milvus、Qdrant、Redis 这几种数据存储方案的示例。另外,有几个 pull requests 想要加入 PostgreSQL 的支持,大概率将来会合入。
这里使用了抽象工厂设计模式 ,DataStore 是一个抽象类,每种数据存储库是具体的实现类,需要实现三个抽象方法:
(1)_upsert(chunks: Dict[str, List[DocumentChunk]]) -> List[str] 方法,接收一个字典参数,包含有 DocumentChunk 对象列表,将它们插入到数据库中。返回值为文档 ID 的列表。
(2)_query(queries: List[QueryWithEmbedding]) -> List[QueryResult] 方法,接收一个列表参数,包含被 embedding 的查询文本。返回一个包含匹配文档块和分数的查询结果列表。
(3)delete(ids: Optional[List[str]] = None, filter: Optional[DocumentMetadataFilter] = None, delete_all: Optional[bool] = None, ) -> bool
方法,根据 id 和其它过滤条件删除,或者全部删除。返回操作是否成功。
值得注意的是,该目录下的factory.py 模块使用了 Python 3.10 新引入的 match-case 语法,紧跟着 Python 社区的新潮流呢~
server 服务端接口
这个目录只有一个main.py 文件,是整个项目的启动入口。它使用了目前主流的 FastAPI 框架,提供了增删改查的几个 API,另外使用 uvicorn 模块来启动服务。
/upsert-file接口,用于上传单个文件,将其转换为 Document 对象,再进行新增或更新/upsert接口,上传一系列的文档对象,用于新增或更新/query接口,传入一系列的文本条件,转成 QueryWithEmbedding 对象后,再从向量数据库查询/delete接口,根据条件删除或者全部删除数据库中的数据
在这几个接口中,增改删功能主要是给开发者/维护者使用的,ChatGPT 只需调用插件的查询接口。因此,代码中还创建了一个“/sub”子应用,只包含/query 接口,提供给 ChatGPT 调用。
另外,它使用 FastAPI 的 mount 方法挂载了一个“/.well-known”静态文件目录,暴露了关于本插件的基本信息,例如名称、描述、作者、logo、邮箱、提供给 OpenAPI 的接口文档等等。
services 任务处理方法
这个目录下是一些通用的函数,比如下面这些:
(1)chunks.py 文件包含了将字符串和 Document 对象分割成小块、以及为每个块获取嵌入向量的函数。
(2)file.py 文件提供了从上传的文件中提取文本内容及元数据的函数。目前支持解析的文件类型包括 PDF、纯文本、Markdown、Word、CSV 和 PPTX。
(3)openai.py 文件包含两个函数:get_embeddings 函数使用 OpenAI 的 text-embedding-ada-002 模型对给定的文本进行嵌入。get_chat_completion 函数使用 OpenAI 的 ChatCompletion API 生成对话。
整个而言,这个插件的几个接口功能很清晰,代码逻辑也不算复杂。核心的文本嵌入操作是借助于 openai 的 Embedding 接口,文本分块信息的存储及查询操作,则是依赖于各家向量数据库的功能。
YouTube 上有博主手画了一张示意图,字体虽潦草,但大家可以意会一下:
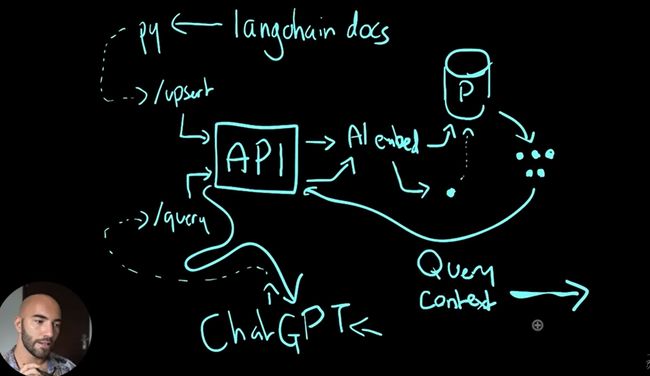
他这个视频 值得推荐一看,因为 up 主不仅简明地介绍了插件的工作原理,还手把手演示如何部署到 Digital Ocean、如何修改配置、如何调试,而且他有 ChatGPT 的插件权限,可以将自己部署的插件接入 ChatGPT,现场演示了知识库插件的使用!
目前,关于 ChatGPT 插件的介绍、开发及配置等资料还比较少,毕竟是新推出的。但是,申请 waitlist 的个人和组织已经数不胜数了,一旦开放使用,各式各样的插件一定会像 Python 社区丰富的开源库一样,也将极大扩展 ChatGPT 的生态。
最后,插件 chatgpt-retrieval-plugin 的官方文档是最为详细的一手资料,推荐大家研究一番。
但是现在国内注册比较困难,这就劝退了很多人。那在国内如何使用呢?旁门左道我就不介绍了,我给大家分享一个软件测试人员专用的GPT平台。chatGPT能做到的,它也可以。需要可以加我下方小卡片交流群哦~
现免费试用
如何利用python实现二叉树?附代码讲解:


还可以继续:


最后:下方这份完整的【软件测试】视频学习教程已经整理上传完成,朋友们如果需要可以自行免费领取 【保证100%免费】

