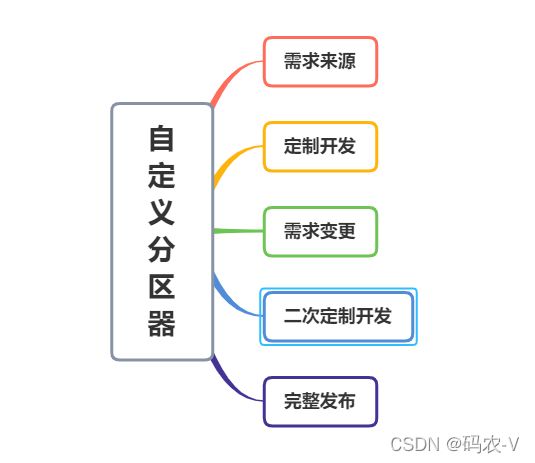
Flink-SQL upset-Kafka自定义分区器
大纲
关注公众号【Code视角】即可获取上百本前沿技术电子书、2021最新面试资料,助力职场无忧。
需求来源
由于生产业务数据比较大,为了提升吞吐量,所以为kafka建立多分区。 但随之带来的问题是:某些数据存在时序问题,需要保证数据有序消费。 这个时候我们就想到自定义发送kafka分区,来保证分区数据的黏着。
定制开发Flink-kakfa
点击阅读官网
遇到这种需求第一反应去看官网中对于自定义分区器是否支持。 然后根据官网进行自定义开发。 官网【连接器参数】中【sink.partitioner】是明确支持的。参看下图,只需要实现【FlinkKafkaPartitioner 即可】。

编写代码 通过阅读官网发现只要实现【FlinkKafkaPartitioner】就可以,那么就开始编码
FlinkKafkaPartitioner源码
package org.apache.flink.streaming.connectors.kafka.partitioner;
import org.apache.flink.annotation.PublicEvolving;
import java.io.Serializable;
@PublicEvolving
public abstract class FlinkKafkaPartitioner<T> implements Serializable {
private static final long serialVersionUID = -9086719227828020494L;
/**
* 初始化的时候会调用的
* @param parallelInstanceId Flink 实例id
* @param flink 并行实例数
*/
public void open(int parallelInstanceId, int parallelInstances) {
// overwrite this method if needed.
}
/**
* 每次发送时进行调用,所以吞吐量大的时候,这块代码必须保持高效
*
* @param 数据 这里是FlinkSql 自己创建的数据体
* @param key
* @param value 实际发送的数据
* @param targetTopic 主题
* @param partitions 分区集合
* @return 目标分区
*/
public abstract int partition(
T record, byte[] key, byte[] value, String targetTopic, int[] partitions);
}
可以看到 我们只要实现partition()方法就行, 自定义自己的发送规则。
package com.xia.flink.base.partitioner;
import org.apache.flink.streaming.connectors.kafka.partitioner.FlinkKafkaPartitioner;
public class MyFlinkPartitioner<T> extends FlinkKafkaPartitioner<T> {
@Override
public void open(int parallelInstanceId, int parallelInstances) {
// 如果想拿到这里的参数 就实现这个
super.open(parallelInstanceId, parallelInstances);
}
@Override
public int partition(T record, byte[] key, byte[] value, String targetTopic, int[] partitions) {
// 这里编写规则
return 0;
}
}
使用 在【WITH】 中指定类全路径,当然这个路径必须你项目启动时可以加载到的类路径。
WITH (
'connector' = 'kafka',
'topic' = 'test-xia',
'sink.partitioner' = 'com.xia.flink.base.partitioner.MyFlinkPartitioner'
)
打包&上测试
需求变更
“小夏,这自定义分区器用不了啊,你这咋写的啊”。 打包测试后,群里反馈很多指标都没法使用,原因这些指标都是使用【Upsert Kafka SQL】。 官网 中可选参数中并没有【sink.partitioner】 这个选项。这个时候就需要参考源码看看能否自定义扩展了。
二次定制开发 upsert-kafka
查找源码
首先我们在idea中找到Flink-SQL的核心jar【flink-connector-kafka_2.11-1.13.1】,找到【org.apache.flink.streaming.connectors.kafka.table.UpsertKafkaDynamicTableFactory】类, 发现在【optionalOptions()】方法中并没有加上sink.partitioner参数的config,而且在下方【createDynamicTableSink(Context context)】方法中在构造【DynamicTableSink】时分区器参数也是null。
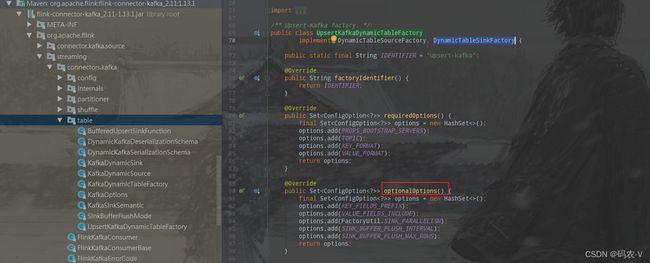
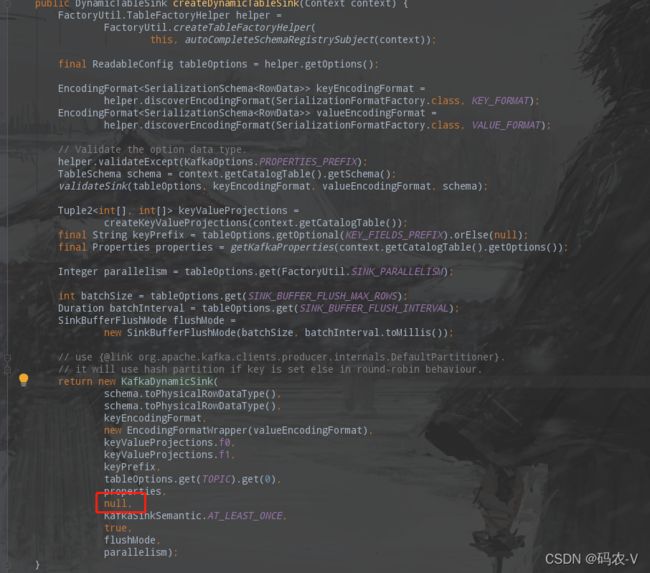
已经找到问题的源头了,那么我们就要分析如何扩展了。
自定义工厂
通过阅读源码得知每个connector对应一个工厂类用于创建。例如【UpsertKafkaDynamicTableFactory】其中根据【factoryIdentifier()】方法来匹配WITH中的connector参数。 那么我们只要继承UpsertKafkaDynamicTableFactory类然后重写
【optionalOptions() 】 添加kafka分区器ConfigOption,用于解析
【factoryIdentifier()】自定义connector名称
【createDynamicTableSink(Context context)】 创建DynamicTableSink添加分区器
这三个方法就可以实现解析【sink.partitioner】参数了。
SPI注册
我们目前已经已经创建了自定义工厂了,那么该如何注册到工厂链表里面,在执行sql是使用呢?
首先找到哪里进行加载使用这些工厂类的。这些类主要是在【FactoryUtil】中使用,
【org.apache.flink.table.factories.FactoryUtil#discoverFactory】是加载方法,参看下图。
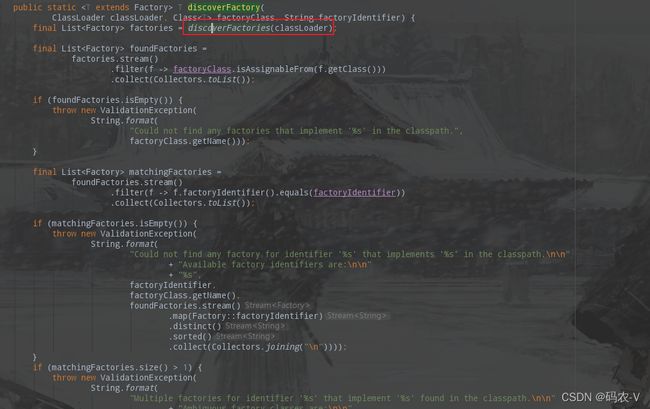
其核心加载工厂的是如下方法:
private static List<Factory> discoverFactories(ClassLoader classLoader) {
try {
final List<Factory> result = new LinkedList<>();
// javaSPI加载
ServiceLoader.load(Factory.class, classLoader).iterator().forEachRemaining(result::add);
return result;
} catch (ServiceConfigurationError e) {
LOG.error("Could not load service provider for factories.", e);
throw new TableException("Could not load service provider for factories.", e);
}
}
这里使用了javaSPI加载,那么扩展就很方便了。
我们只需要在resources目录下新建META-INF/services目录,并且在这个目录下新建org.apache.flink.table.factories.Factory文件,在这个文件中写入接口的实现类的全限定名即可, 如下

源码
import lombok.extern.slf4j.Slf4j;
import org.apache.flink.configuration.ConfigOption;
import org.apache.flink.configuration.ReadableConfig;
import org.apache.flink.streaming.connectors.kafka.partitioner.FlinkKafkaPartitioner;
import org.apache.flink.streaming.connectors.kafka.table.KafkaOptions;
import org.apache.flink.streaming.connectors.kafka.table.UpsertKafkaDynamicTableFactory;
import org.apache.flink.table.connector.sink.DynamicTableSink;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.factories.FactoryUtil;
import java.lang.reflect.Field;
import java.util.Optional;
import java.util.Set;
import static org.apache.flink.streaming.connectors.kafka.table.KafkaOptions.SINK_PARTITIONER;
import static org.apache.flink.streaming.connectors.kafka.table.KafkaOptions.autoCompleteSchemaRegistrySubject;
/**
* 增加自定义工厂
*/
@Slf4j
public class LCBUpsertKafkaDynamicTableFactory extends UpsertKafkaDynamicTableFactory {
@Override
public String factoryIdentifier() {
// 自定义 connector 名称。
return "xia-upsert-kafka";
}
@Override
public Set<ConfigOption<?>> optionalOptions() {
Set<ConfigOption<?>> options = super.optionalOptions();
// 添加kafka分区器ConfigOption,便于后续解析和使用自定义分区器
options.add(SINK_PARTITIONER);
return options;
}
@Override
public DynamicTableSink createDynamicTableSink(Context context) {
final FactoryUtil.TableFactoryHelper helper =
FactoryUtil.createTableFactoryHelper(
this, autoCompleteSchemaRegistrySubject(context));
final ReadableConfig tableOptions = helper.getOptions();
// 通过类路径创建自定义分区器
Optional<FlinkKafkaPartitioner<RowData>> partitioner = KafkaOptions.getFlinkKafkaPartitioner(tableOptions, context.getClassLoader());
// 调用父类创建DynamicTableSink
DynamicTableSink tableSink = super.createDynamicTableSink(context);
// 反射赋值
doSetPartitioner(partitioner, tableSink);
return tableSink;
}
private void doSetPartitioner(Optional<FlinkKafkaPartitioner<RowData>> partitioner, DynamicTableSink tableSink) {
try {
Field field = tableSink.getClass().getDeclaredField("partitioner");
field.setAccessible(true);
field.set(tableSink, partitioner.orElse(null));
} catch (NoSuchFieldException e) {
log.error("反射赋值错误没有改属性:{}", partitioner, e);
} catch (IllegalAccessException e) {
log.error("反射赋值属性错误:{}", e);
}
}
}
使用 在【WITH】 中指定类全路径,当然这个路径必须你项目启动时可以加载到的类路径。
WITH (
'connector' = 'xia-upsert-kafka',
'topic' = 'test-xia',
'sink.partitioner' = 'com.xia.flink.base.partitioner.MyFlinkPartitioner'
)
发布上线
至此,完美解决问题,打包、测试、上线。

关注公众号【Code视角】 关注即可获取上百本前沿技术电子书、最新面试资料。