tBERT-BERT融合主题模型
今天分享一个论文ACL2020-tBERT,论文主要融合主题模型和BERT去做语义相似度判定,在特定领域使用这个模型,效果更明显。
掌握以下几点:
- 【CLS】向量拼接两个句子各自的主题模型,效果有提升
- 尤其是在特定领域的数据集合会有更好的表现。
1. 架构图
先看架构图:

模型架构比较简单,BERT这边使用的【CLS】输出向量: C = B E R T ( S 1 , S 2 ) C=BERT(S_{1},S_{2}) C=BERT(S1,S2)
主题模型使用两种,LDA和GSDMM,主要是因为LDA在长文本效果更好;GSDMM在短文本效果更好。
获取主题模型如下所示:
D 1 = T o p i c M o d e l ( [ T 1 , . . . , T N ] ) ∈ R t D_{1} = TopicModel([T_{1},...,T_{N}]) \in R^{t} D1=TopicModel([T1,...,TN])∈Rt
D 2 = T o p i c M o d e l ( [ T 1 , , . . . , T M , ] ) ∈ R t D_{2} = TopicModel([T^{,}_{1},...,T^{,}_{M}]) \in R^{t} D2=TopicModel([T1,,...,TM,])∈Rt
t t t 代表的是主题数量,N是 S 1 S_{1} S1的字数量,M是 S 2 S_{2} S2的字数量
进而我们可以得到单词的主题分布:
w i = T o p i c M o d e l ( T i ) w_{i} = TopicModel(T_{i}) wi=TopicModel(Ti)
W 1 = ∑ i = 1 N w i N ∈ R t W_{1} = \frac{\sum^{N}_{i=1}w_{i}}{N} \in R^{t} W1=N∑i=1Nwi∈Rt
W 2 = ∑ i = 1 M w i , M ∈ R t W_{2} = \frac{\sum^{M}_{i=1}w^{,}_{i}}{M} \in R^{t} W2=M∑i=1Mwi,∈Rt
所以在最后和【CLS】连接的时候,可以使用文档主题 D 1 和 D 2 D_{1}和D_{2} D1和D2,也可以使用单词主题 W 1 和 W 2 W_{1}和W_{2} W1和W2。
2.实验效果
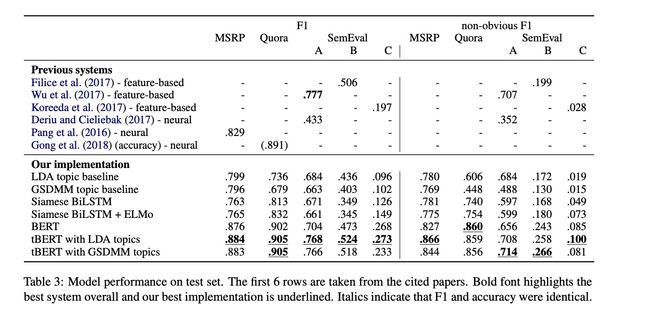
看实验效果,LDA效果会比GSDMM更好一点。
其实有一个比较有意思的点是,BERT的建模能力已经足够强了,为啥加上主题模型还会有提升。
换句话说,主题模型在基于BERT的方向上,能够在哪些方面提升。
作者是这么做的实验,他选了和主题模型相关的三个属性:实体,特定领域词和不规范拼写。根据三个属性抽取样本,总共500个, 然后让BERT和tBERT做预测。

看实验效果是这样的,发现在特定领域tBERT效果更明显一点。
作者认为在预训练的时候,可能是BERT碰到特定领域词汇的机会比较少,没有很好的学习到这些信息,所以主题模型很好的补充了这部分信息。
不过,感觉这个实验并不充分,一个属性这块挑选感觉有点不太充分,还有一个是样本数量感觉太少了,500个…
总结
说一下掌握的知识点:
- 【CLS】向量拼接两个句子各自的主题模型,效果有提升
- 尤其是在特定领域的数据集合会有更好的表现。
说一下我自己的思考,关于特定领域这块。一般来说,微调是可以解决这个问题的。
不过看作者的实验,即使是微调之后的BERT,在特定领域这块,效果也没有tBERT好,说明主题模型在这块还是很有用的。
进一步思考,可不可以这么推论,如果说我们的任务输入越是特定领域,那么假如tBERT越有明显的提升呢?
这个感兴趣的大家可以去试一试,比如医疗领域,比如金融领域之类的。