【数据挖掘】数据挖掘、关联分析、分类预测、决策树、聚类、类神经网络与罗吉斯回归
目录
- 一、简介
- 二、关于数据挖掘的经典故事和案例
-
- 2.1 正在影响中国管理的10大技术
- 2.2 从数字中能够得到什么?
- 2.3 一个网络流传的笑话(转述)
- 2.4 啤酒与尿布
- 2.5 网上书店关联销售的案例
- 2.6 数据挖掘在企业中的应用
- 2.7 交叉销售
- 三、数据挖掘入门
-
- 3.1 什么激发了数据挖掘,为什么它是重要的?
- 3.2 什么是数据挖掘?
- 3.3 对何种数据进行挖掘?
- 四、OLAP与数据挖掘
- 五、数据挖掘的功能
-
- 5.1 关联分析
- 5.2 分类和预测
- 5.3 聚类
- 5.4 异常值探测
- 5.5 序列模式挖掘
- 5.6 几种数据挖掘技术
-
- 5.6.1 Decision Tree决策树
- 5.6.2 聚类(Cluster)
-
- 5.6.2.1 Hierarchical Clustering层次聚类法
- 5.6.2.2 K-Means Clustering K-均值聚类方法
- 5.6.2.3 关联规则(Association)
- 5.6.2.4 Neural Network
- 5.6.2.5 Naïve Bayes 分类
- 5.6.2.6 罗吉斯回归(Logistic Regression)
- 5.6.2.7 文本挖掘
- 5.7 Top-10 Algorithm Finally Selected at ICDM’06
- 六、数据挖掘与统计学的关系
- 七、数据挖掘软件
一、简介
数据挖掘是20世纪末兴起的数据智能分析技术,由于有广阔的应用前景而备受重视
广大从事 数据库应用与决策支持,以及 数据分析 等学科的科研工作者和工程技术人员迫切需要了解和掌握。数据挖掘涉及的内容较为广泛,已成为信息社会中广泛应用的一门综合性学科。
二、关于数据挖掘的经典故事和案例
1、正在影响中国管理的10大技术
2、从数字中能够得到什么?
3、一个网络流传的笑话
4、啤酒与尿布
5、网上书店关联销售的案例
6、数据挖掘在企业中的应用
2.1 正在影响中国管理的10大技术
No.5 数据挖掘
2.2 从数字中能够得到什么?


2.3 一个网络流传的笑话(转述)
客服:“东东披萨店您好!请问有什么需要我为您服务?”
顾客:“你好,我想要……”
客服:“先生,请把您的AIC会员卡号码告我。”
顾客:“喔!请等等,12345678。”
客服: “陈先生您好,您是住在泉州街一号二楼,您家的电话是23939889,您的公司电话是23113731, 您的移动电话是939956956。请问您现在是用哪一个电话呢? ”
(1.客户数据库)
顾客: “我家,为什么你知道我所有的电话号码?”
客服: “陈先生,因为我们有连线“AIC CRM 系统”。”


顾客:“我想要一个海鲜披萨……”
客服:“陈先生, 海鲜披萨不适合您。”
顾客:“为什么?”
客服:“根据您的医疗纪录, 您有高血压和胆固醇偏高。”
(2.医疗数据库)
顾客:“那……你们有什么可以推荐的?”
客服:“您可以试试我们的低脂健康披萨。”
顾客:“你怎么知道我会喜欢吃这种的?”
客服:“喔! 您上星期一在中央图书馆借了一本《低脂健康食谱》。”
(3.图书借阅数据库)
顾客:“哎呀!好……,我要一个家庭号特大披萨,要多少钱?”
客服:“嗯,这个足够您一家十口吃,六百九十九元。”
顾客:“可以刷卡吗?”
客服:“陈先生,对不起,请您付现,因为您的信用卡已经刷爆了,
您现在还欠银行十万四千八百零七元,而且还不包括房贷利息。”
(4.金融数据库-信用卡)
顾客:“喔!那我先去附近的提款机领钱。”
客服:“陈先生,根据您的记录, 您已经超过今日提款机提款限额。”
(5.金融数据库-现金卡)
顾客:“算了!你们直接把披萨送来吧,我这里有现金。你们多久会送到?”
客服:“大约三十分钟, 如果您不想等,可以自己骑车来。”
顾客:“什么?!”
客服:“根据“AIC CRM系统”记录,您有一辆摩托车, 车号是GY-7878。”
(1.客户数据库)
顾客:“#%@^@#&!(@&!!(!!!”
客服:“陈先生,请您说话小心一点。您在2000年四月一日用脏话侮辱警察,被判了十日拘役。”
顾客:“……”
(6.刑事刑案数据库)
客服:“请问还需要什么吗?”
顾客:“没有了,是不是有送三罐可乐?”
客服:“是的!不过根据“AIC CRM系统”您有糖尿病……”
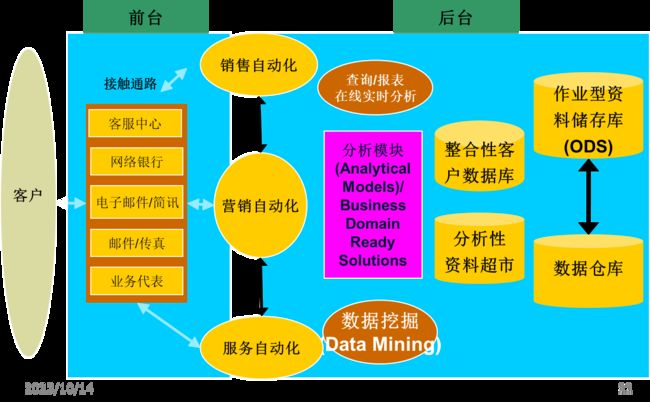
CRM Road MAP
2.4 啤酒与尿布
在一家超市里,有一个有趣的现象:尿布和啤酒赫然摆在一起出售。
但是这个奇怪的举措却使尿布和啤酒的销量双双增加了。
原因何在?
原来,美国的妇女们经常会嘱咐她们的丈夫下班以后要为孩子买尿布。而丈夫在买完尿布之后又要顺手买回自己爱喝的啤酒,因此啤酒和尿布在一起购买的机会还是很多的。
是什么让沃尔玛发现了尿布和啤酒之间的关系呢?
正是商家通过对超市一年多原始交易数字进行详细的分析,通过数据挖掘中的 关联规则 发现了这样的组合。
2.5 网上书店关联销售的案例
现在网上书店为了能够吸引更多读者购买图书,常常会运用一种叫做 关联销售分析 的方法。
这种方法是给客户提供其他的相关书籍,也就是在客户购买了一种书籍之后,推荐给客户应该感兴趣的其他相关书籍。
例如:购买了《月光宝盒(2DVD)》的顾客,对什么样的DVD还比较感兴趣,购买的比较多呢?。
(网上书店现在有了很强的市场和比较固定的大量的客户。为了促进网上书店的销售量的增长,各网上书店采取了各种方式,给客户提供更多更丰富的书籍,提供更优质服务等方式吸引更多的读者)
解决上述问题的步骤:
首先,确定数据源,也就是销售记录。
这里要用到两张表,一张表是该书店的会员,用会员ID号来代替;另一张表是会员买了什么书。然后,应用 Data Mining技术,建立数据挖掘模型。
对上述问题进行挖掘的结果:



结果:购买《月光宝盒(2DVD)》之后,又购买《大圣娶亲(2DVD)》的次数是1317。
2.6 数据挖掘在企业中的应用
数据挖掘所能解决的典型商业问题包括:
银行:反欺诈行为、关联销售、市场竞争分析。客户分类、客户价值分析与预测、客户偏好分析、客户信用分析以及欺诈检测 等。
电信:流失预警、客户分群、关联销售。
网上销售点:购物车交叉销售、网上商品布局。
DM在信用卡欺诈交易中的应用:
应用之一是通过评价交易数目、交易金额、账户信息如姓名变化和地址变迁、换卡申请等非金融信息的组合来实现。这些因素结合起来,描述出持卡人最近交易的大概轮廓,从而评估出是否与持卡人的交易习惯相符。一旦发现交易异常的明显痕迹,发卡行需要联系持卡人,以 确定其信用卡账户最近是否正常,是否被以任何方式遭受损害 。
例如,如果一个持卡人日常生活里,每月交易笔数在3~6笔,这就是其交易模式之一。如果有一天发现当日其信用卡账户有15笔交易,例外报告将要求发卡行联系持卡人进行确认。
DM在大型零售企业中的应用
英国safeway公司,研究发现某一种乳酪产品虽然销售额排名第209,可是消费额最高的客户中有25%都常常买这种乳酪,这些客户可是Safeway最不想得罪的客户。如果使用传统的分析方法的话,这种产品很快就会不卖了,可是事实上这种产品是相当重要的。
Safeway也发现在28种品牌的橘子汁中,有8中特别受到欢迎。因此,该公司重新安排货架的摆设,使橘子汁的销量能够增加到最大。
1、优化商品组合布局,正确安排商品进货与库存
从众多的商品中发现创造价值最大的商品。然后,据此调整商品的结构,安排商品的库存和定货。
商品布局管理即商品摆放位置对销售起着至关重要的作用。
考虑购买者在商店里所穿行的路线、购买时间和地点、货架的使用效率、畅销商品的类别、不同商品一起购买的概率,进行挖掘。
例如,一个超市营销的例子,经由记录客户的消费记录与采购路线,超级市场的厨房用品是按照女性的视线高度来摆放的。
根据研究得出:美国妇女的视线高度是150公分左右,男性是163公分左右,而最舒适的视线角度是视线高度以下15度左右,所以最好的货品陈列位置是在130-135公分之间。 在商业上,有很多特征是很难理解的,但若了解到这些信息就会增加企业的竞争能力。
2、利用数据挖掘技术帮助企业准确制定营销策略,主要表现在:
(1)通过对市场同类产品和销售情况、顾客情况的资料收集和分类分析,明确细分市场,确定本企业差别化的产品和服务定位、目标顾客和市场营销策略。(业绩分析)
(2)正确安排商品进货与库存,降低库存成本。即对各个商品、各色货物进行增减,确保正确的库存;协助企业确定最佳经济批量、最佳定货时机,从而节约进货和库存管理费用。
以顾客为导向
(3)将顾客按照一定的标准进行分类,通过对企业销售数据的序列分析发现顾客基于时间的购买模式,预测顾客需求,及时调整产品的结构和内容,提高不同顾客群的满意度,最大限度的留住顾客。
(4)通过建立顾客会员制度,记录同一顾客在不同时期购买的商品序列,通过统计分析和序列模式挖掘顾客购买趋势或忠诚度的变化。

例如,Safeway在了解客户每次采购时会购买哪些产品以后,就可以利用数据挖掘中的监测功能,监测出长期的经常购买行为。再将这些资料与主数据库的人口统计资料结合在一起,Safeway的营销部门就可以根据每个家庭的特性,也就是哪些季节会购买哪些产品的趋势,发出邮件。
2.7 交叉销售
例如,拥有汽车的新婚夫妻很可能购买儿童专用汽车椅,这个现象很容易被理解,并不需要应用到数据挖掘中。
但如考虑到另一个问题,这些夫妻会购买何种颜色的儿童专用汽车椅?这时可以运用数据挖掘技术以便在新婚夫妻购买汽车的时候销售给他们合适的儿童专用汽车椅。
DM在房地产行业中的应用

关联规则A1:地理位置无关型客户=≥ 重视物业管理
支持率=9.7%;可信度=30.3%;兴趣度=2.4;
关联规则B1:重视物业管理=≥ 地理位置无关型客户
支持率=9.7%;可信度=76.9%;兴趣度=2.4;
对比发现:“重视物业管理的人不关心地理位置”的可能性(76.9%)高于“不关心地理位置的人重视物业管理”的可能性(30.3%)。说明关联规则B1是一条更有意义的关联规则。
DM在公司财务分析中的应用

用比率分析法消除规模影响:


首先,将企业按财务状况分成5类;其次,利用关联分析,找到影响企业财务状况的因素。对公司的财务状况有明显影响的因素有资产负债率、速动比率、总资产周转率、销售毛利率、净资产收益率等。
三、数据挖掘入门
什么激发了数据挖掘,为什么它是重要的?
什么是数据挖掘?
在何种数据上进行数据挖掘?
数据挖掘的功能
几种较为流行的数据挖掘技术
3.1 什么激发了数据挖掘,为什么它是重要的?
数据爆炸性的增长:从兆字节terabytes 到千兆字节petabytes。
多种海量数据源
商业: 网络, 电子商务, 交易, 股票, …
科学: 遥感数据, 生物信息学, 科学模拟, …
社会各个角落: 新闻, 数字影像, 视频,…
“我们被信息淹没却信息贫乏!”
“需要是发明之母”
根据文章中出现的词的相似性,可以把八篇文章分为两个自然簇。第一个簇由前四篇文章组成,对应于经济新闻,而第二个簇包含后四篇文章,对应于卫生保健新闻。

3.2 什么是数据挖掘?
数据挖掘从数据中发现知识。
数据挖掘就是从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。
Data mining: 用词不当?
从数据中挖掘知识
相近的术语
数据库中知识发现(KDD-Knowledge Discovery in Databases)、知识提取、数据/模式识别、 数据考古、数据捕捞、知识获取、商业智能等。

数据挖掘和商务智能
商务智能通常被理解为将企业中现有的数据转化为知识,帮助企业做出明智的业务经营决策的工具。
一般由 数据仓库、联机分析处理、数据挖掘、数据备份和恢复 等部分组成。

3.3 对何种数据进行挖掘?
关系数据库(Relational database)、数据仓库(data warehouse)、事务数据库( transactional database)
关系数据库是表的集合,每个表都赋予一个唯一的名字。
事务数据库由一个文件组成,其中每个记录代表一个事务。
数据仓库是从多个数据源收集的信息存储,存放在一个一致的模式下,并通过数据清理、变换、集成等来构造。
高级数据库和面向特殊应用的数据库
数据流和遥感数据
时间序列数据、时间数据、序列数据(生物序列数据)
结构数据、图、网络和多维链数据
对象-关系数据库(Object-relational databases)
异种数据库和遗产数据库
空间数据和时空数据
多媒体数据库、文本数据、WWW


数据仓库
以面向主题的原则,以个人信用卡消费趋势为主题的星形模式数据仓库。
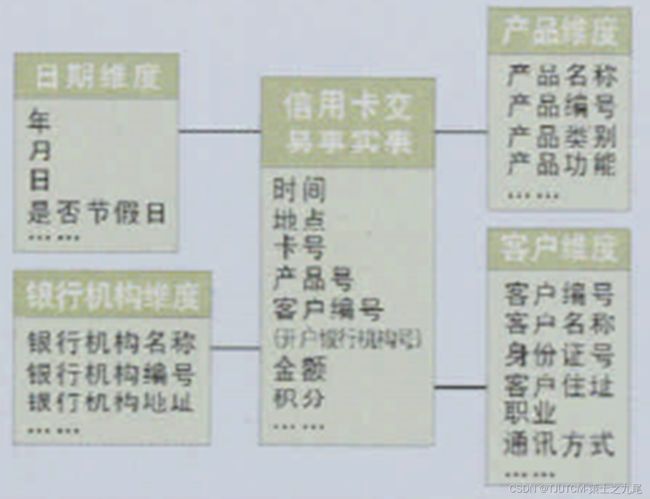
数据仓库是从多个数据源收集的信息存储,存放在一个一致的模式下,并通过数据清理、变换、集成等来构造。

四、OLAP与数据挖掘
联机分析处理OLAP(On-Line Analytical Processing)是使使用者从多种角度对从原始数据中转化出来的、易理解并真实反映企业特性的信息进行存取,以满足决策支持或多维环境特定的查询和报表需求的一种软件技术。
OLAP除了能够告诉你数据库中都有什么,还能够更进一步告诉你下一步会怎么样以及如果采取这样的措施又会怎么样。
其分析过程在本质上是一个基于用户建立的一系列假设驱动,通过OLAP来证实或者推翻这些假设的演绎推理过程。
实质上是 通过把一个实体的多项重要的属性定义为多个维(dimension),使用户能对不同维上的数据进行比较。因此OLAP也可以说是多维数据分析工具的集合。(旋转、切片(块)、钻取)
钻取:是改变维的层次,变换分析的粒度。它包括向下钻取(Drill-down)和向上钻取(Drill-up)/上卷(Roll-up)。Drill-up是在某一维上将低层次的细节数据概括到高层次的汇总数据,或者减少维数;而Drill-down则相反,它从汇总数据深入到细节数据进行观察或增加新维。
切片和切块:是在一部分维上选定值后,关心度量数据在剩余维上的分布。如果剩余的维只有两个,则是切片;如果有三个或以上,则是切块。
旋转:是变换维的方向,即在表格中重新安排维的放置(例如行列互换)。
比如:一个OLAP分析师可能认为,在某一区域开办信用卡的用户会更主动地进行消费。
对于这个假定,他可能去观察在那些富裕地区申办信用卡的用户的信用卡账户属性。如果结果还不够明显,他也许要将年龄因素考虑进去。一直这样下去,直到他认为他找到了能够决定是否主动进行信用卡消费的各种变量,然后再根据这些变量,策划他的银行产品的营销方式,最大程度上将营销资源放在最可能接受他们产品的客户对象上。
OLAP与数据挖掘的区别
比如,在银行间盛行的CRM的应用中,数据仓库以面向“客户”为主题进行数据筛选、存储;OLAP负责分析客户的基本信息、储蓄账户信息、历史余额信息、银行交易日志等,以动态分析报表、直方图、折线图、饼图等形式展现给管理者,让他们从多方面了解和掌握客户的动态,从而发现客户的交易习性、客户流失形式,更好地针对不同类型的客户,在不同时期进行适应性产品的营销活动。
数据挖掘则可以通过历史数据建立模型,在拟合历史的基础上,分析未来趋势,判断哪些因素的改变将很可能意味着客户的最终流失,进而避免其发生。
五、数据挖掘的功能
关联分析
分类和预测
聚类
异常值探测
序列模式挖掘
5.1 关联分析
关联分析是用于挖掘、发现大量数据中项集之间存在的、重要的、有趣的知识。若两个或多个变量的取值之间存在某种规律性,就称为关联。
在 不知道关联函数 或 关联函数不确定 的情况下,为了反映所发现规则的有用性和确定性,关联分析生成的规则都要满足最小支持度阀值和最小置信度阀值。
关联分析的应用:
比如人寿保险。保险公司在接受保险前,往往需要记录投保人详尽的信息,有时还要到医院做身体检查。保单上记录有投保人的年龄、性别、健康状况、工作单位、工作地址、工资水平等。
通过分析这些数据,可以得到类似以下这样的 关联规则:年龄在40岁以上,工作在A区的 投保人当中, 有45%的人曾经向保险公司索赔过。在这条规则中,“ 年龄在40岁以上”∩“ 工作在A区” →“向保险公司索赔过”
可以看出来,A 区可能污染比较严重,环境比较差,导致工作在该区的人健康状况不好, 索赔率也相对比较高。
5.2 分类和预测
分类是对一个类别进行描述及概括相关特征,并提取出描述重要数据类的模型。
数据挖掘中的分类方法很多,主要有 决策树和决策规则、贝叶斯信念网络、 神经网络以及遗传算法 等。
预测是通过建立连续值函数模型达到预测未来的数据趋势。预测的方法主要有 回归分析、时间序列分析 等。各种分类模型也可以预测,但主要是预测分类标号。
5.3 聚类
聚类是在要划分的类未知的情况下,将数据库中的记录划分为多个类或簇,使得同类内的对象之间具有较高的相似度,不同类间的差异较大。它是 概念描述和偏差分析的先决条件。
数据挖掘中的聚类方法有 划分方法、层次的方法、基于密度的方法、基于网格的方法以及基于模型的方法 等。
5.4 异常值探测
异常值 指的是数据库中不符合数据一般模型的数据对象。
从数据库中探测异常值很有意义,因为它们本身可能隐藏着重要的信息,比正常的数据更有用,忽略或删除它们都会导致信息的丢失。
例如,发现金融和保险领域的欺诈行为、税款的脱逃、通信费用的恶意欠费、网络中的黑客入侵、追寻极低或极高收入者的消费行为以及对多种治疗方式不寻常反映的发现等。
5.5 序列模式挖掘
序列模式挖掘是指 挖掘相对时间或其他序列出现频率高的规律或趋势,并建模。
这里的序列一般指 时间序列数据库和序列数据库(Web日志分析和DNA分析)。
在许多行业产生的数据库都是时间序列数据库,例如,商业交易、电信部门、天气数据等等,因此,序列模式的挖掘是非常有意义的。

序列分析和关联规则的相似之处在于,它们所用的样本数据中,每一个样本都包含了一个项集或状态集合。其不同之处在于 序列分析研究的是项集(或状态)间的转换,而关联规则模型研究的是项集之间的相关性。
在序列分析模型中,先购买计算机再购买音箱,和先购买音箱再购买计算机是两种不同的序列。而在关联规则中这两种行为都表达了一个同样的项集{计算机,音箱}。
5.6 几种数据挖掘技术

5.6.1 Decision Tree决策树
决策树是 用二叉树形图来表示处理逻辑的一种工具,是对数据进行分类的方法。决策树的目标是针对类别因变量加以预测或解释反应结果。
主要有两个步骤:首先,通过一批已知的样本数据建立一棵决策树;然后,利用建好的决策树,对数据进行预测。
决策树的建立过程可以看成是数据规则的生成过程,因此,决策树实现了数据规则的可视化,其输出结果也容易理解。


5.6.2 聚类(Cluster)
聚类目的在将相似的事物归类。
可以将变量分类,但更多的应用是透过顾客特性做分类,通过将顾客特性进一步分割成若干类别而达到市场区隔之目的。
可以帮助企业了解顾客的特征,将顾客分成新顾客、忠诚顾客、流失顾客、无规律购买顾客、新吸引的顾客等,便于企业针对不同群体的特征,设计出不同的营销策略,更大程度地满足消费者个性化需求。
5.6.2.1 Hierarchical Clustering层次聚类法
该方法是利用距离矩阵作为分类标准,将n个样品各作为一类;计算n个样品两两之间的距离,构成距离矩阵;合并距离最近的两类为一新类;计算新类与当前各类的距离;再合并、计算,直至只有一类为止。

5.6.2.2 K-Means Clustering K-均值聚类方法


5.6.2.3 关联规则(Association)
关联规则是 分析发现数据库中不同变量或个体(例如商品间的关系及年龄与购买行为……)之间的关系程度(概率大小),并用这些规则找出顾客购买行为模式。
例如:购买了桌面计算机对购买其他计算机外设商品(打印机、喇叭、硬盘…)的相关影响。
发现这样的规则可以应用于商品货架摆设、库存安排以及根据购买行为模式对客户进行分类。
啤酒与尿布的关联分析

5.6.2.4 Neural Network

类神经网络,类似人类神经元结构。
神经元的主要功能是接受刺激和传递信息。神经元通过传入神经接受来自体内外环境变化的刺激信息,并对这些信息加以分析、综合和储存,再经过传出神经把指令传到所支配的器官和组织,产生调节和控制效应。

5.6.2.5 Naïve Bayes 分类
单纯贝叶斯分类主要是根据贝叶斯定理(Bayesian Theorem),来预测分类的结果。
贝叶斯定理:P(X)、P(H)和P(X|H)可以由给定的数据计算,是先验概率。贝叶斯定理提供了一种由P(X)、P(H)和P(X|H)计算后验概率P(H|X)的方法。贝叶斯定理是:


判断:X=(女性,年龄介于31~45之间,不具学生身份,收入中等)会不会办理信用卡。
解:首先根据训练样本计算各属性相对于不同分类结果的条件概率:
P(办卡)=7/10 P(不办卡)=3/10
P(女性|办卡)=5/7 P(女性|不办卡)=1/3
P(年龄=31-45|办卡)=3/7 P(年龄=31~45|不办卡)=1/3
P(学生=否|办卡)=5/7 P(学生=否|不办卡)=0/3
P(收入=中|办卡)=2/7 P(收入=中|不办卡)=2/3
其次,再应用 朴素贝氏分类器 进行类别预测:
计算
P(办卡)P(女性|办卡)P(年龄31~45|办卡)P(不是学生|办卡)P(收入中|办卡) =15/343≈0.044
P(不办卡)P(女性|不办卡)P(年龄31~45|不办卡)P(不是学生|不办卡)P(收入中等|不办卡)=0
0.044>0
训练样本中对于(女性,年龄介于31~45之间,不具学生身份,收入中等)的个人,按照朴素贝叶斯分类会将其分到办信用卡一类中。
办卡的概率是(0.044)/(0.044+0)=1
(正规化分类的结果P(会)/(P(会)+P(不会))
5.6.2.6 罗吉斯回归(Logistic Regression)
假设有个科学家想要了解某种毒物对于老鼠死亡率的分析,他做了三次实验,分别使用不同的毒物用量,去计算每一百只老鼠的死亡概率,然后他得到以下的结果:
使用10毫克毒物,死亡率为15%
使用20毫克毒物,死亡率35%
使用30毫克毒物,死亡率55%
从这些数值看起来,毒物的用量与死亡率呈现显著的正比关系,而且我们可以计算出一条非常完美准确的回归线:Y=2X-5(Y为死亡率,X为毒物用量)。
但是,这个方程式包含有一个重大错误。假设我们使用100毫克毒物,根据方程式计算,这些老鼠的死亡率为195%,也就是说每一百只老鼠会死195只,而如果我们完全不放任何毒物时,死亡率为-5%,也就是每一百只老鼠会死负五只。
很显然,这个线性回归模型没有考虑到几个重要的限制,即 当我们使用毒物量降低时,死亡率应该是近于零(不会是负值),而当毒物量增加时,死亡率应该是接近于100%。
当需要把概率限制在0~1时,就可以考虑使用LOGISTIC回归。
Logistic回归模型的构造
现y为发病或未发病,生存与死亡等定性分类变量,不能直接用回归模型进行分析。
能否用发病的概率P来直接代替 y呢?即
不行。但可以
因此,定义logit§= ln[P/(1-P)]为Logistic变换,则Logistic回归模型为:

经数学变换可得:


Logistic回归模型是一种概率模型,它是 以疾病,死亡等结果发生的概率为因变量, 影响疾病发生的因素为自变量建立回归模型。 它特别适用于因变量为二项, 多项分类的资料。
5.6.2.7 文本挖掘

网站文本分析
通过文本挖掘,能够让搜索引擎找到更符合查询者原意的内容;入口网站可以侦测网页文件的关键字,判断哪些网页内容属于限制级;搜索引擎也可以运用关键字将网页内容自动分类,或者是判断哪些电子邮件是垃圾邮件。
文章分群
在Vassar College的唐佛斯教授实验室中,这类利用文字挖掘技术相当成熟,能够从一堆文章中自动找出哪些是莎士比亚写的作品,同时该实验室也发现1823年发表的《圣诞老人》的作者并非是原先宣称的Clement Clark Moore,而是Henry Livingston。
5.7 Top-10 Algorithm Finally Selected at ICDM’06
#1: C4.5 (61 votes)
#2: K-Means (60 votes)
#3: SVM (58 votes)
#4: Apriori (52 votes)
#5: EM (48 votes) expectation maximum 最大期望
#6: PageRank (46 votes) 超链接分析算法
#7: AdaBoost (45 votes)
#7: kNN (45 votes)
#7: Naive Bayes (45 votes)
#10: CART (34 votes)
六、数据挖掘与统计学的关系
为什么数据挖掘不是传统的数据分析?
数据挖掘不是统计学的分支。
统计学是数据挖掘的核心。
为什么数据挖掘不是传统的数据分析?
1、海量数据——高维、高复杂度的数据
算法必须能够处理诸如千兆的海量数据。
2、统计学具有某种保守性,它倾向于尽量地避免出现特殊方法的运用,而偏好于数学上的严格性;数据挖掘分析问题喜欢“冒险”的态度。
3、在现代统计学中,模型是主要的,而对于模型的选择标准、如何计算等则都是次要的。但是 在数据挖掘中,算法也扮演着重要的角色。
4、统计学方法的前提是假设。而数据挖掘是在没有明确假设的前提下去挖掘信息、发现知识。数据挖掘所得到的信息应具有先未知、有效和可实用三个特征。
5、在统计理论方面:
统计推断的基础“总体”和“样本”的概念是否还继续适用?
面对如此大量的数据很难定义总体和样本;
大样本渐近性质是否满足?
由于数据量太大,传统的统计量无论真实情况如何都会变得“显著”;
统计假设检验使用的小概率原理是否还适用?
因为假定小概率事件在一次实验中不会发生是合理的,而数据量大到一定程度之后,小概率事件一定会发生。
数据挖掘不是统计学的分支。
统计学是数据挖掘的核心。
统计学和数据挖掘有着共同的目标。
统计学和数据挖掘有着共同的目标:发现数据中的结构或模式。
统计学在数据挖掘中起着重要的作用。
传统的统计学方法是数据挖掘的经典方法,统计学思想在整个数据挖掘过程都有重要的体现,担负着不可忽视的重任。
数据挖掘技术与统计学集成是必然趋势。
七、数据挖掘软件
SQL2005
Clementine
马克威分析系统
Statistica
SAS
SPSS Modeler