【AI达人创造营】红细胞形状异常检测在Edgeboard上的部署
【AI达人创造营】红细胞形状异常检测在Edgeboard上的部署
此项目是基于PaddleDetection做的红细胞形状异常检测,属于医学中目标检测类的项目。此项目是在由百度大脑研发的EdgeBoard Lite FZ3B硬件上部署的。
一、项目背景
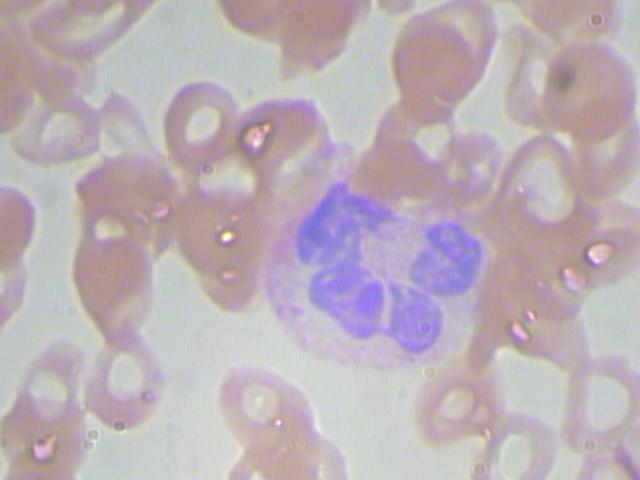
- 此项目可以帮医生减轻负担,提高检测的准确性和速度。一般每张红细胞形状异常检测图都有好多红细胞,并且这个样本量还是成千上万的,这时候医生容易眼花缭乱,甚至可能漏掉一些重叠的红细胞。
- 并且可以让医生避免重复的不必要的工作。
- 将医学与AI科技结合,让科技为医学赋能。
二.项目使用的套件
此项目使用的是PaddleDetection套件,下载地址为:
github:https://github.com/PaddlePaddle/PaddleDetection(因为国外网站,访问比较慢,不太推荐);
飞桨AI Studio平台上:https://aistudio.baidu.com/aistudio/datasetdetail/102742(考虑到大部分用户访问github比较慢,故我从github上搬运过来)。
1.解压PaddleDetection套件
# 将PaddleDetection套件进行解压,路径看具体情况。
# (为了保险起见,将套件保存至work/路径下,千万不要保存在data/下以及这两个文件夹外,作者有过惨痛的经历教训,不希望大家再出现此惨状。)
!unzip -oq /home/aistudio/data/data112279/PaddleDetection-release-0.5.zip -d work/
2.对PaddleDetection套件进行改名
# 将PaddleDetection套件进行改名(改名记得写上套件路径及改名后期望的路径)
!mv work/PaddleDetection-release-0.5 work/PaddleDetection
三、数据集简介
此项目使用了AI Studio平台上RBC数据集,一共有366条数据,数据是xml格式的图片标注文件。

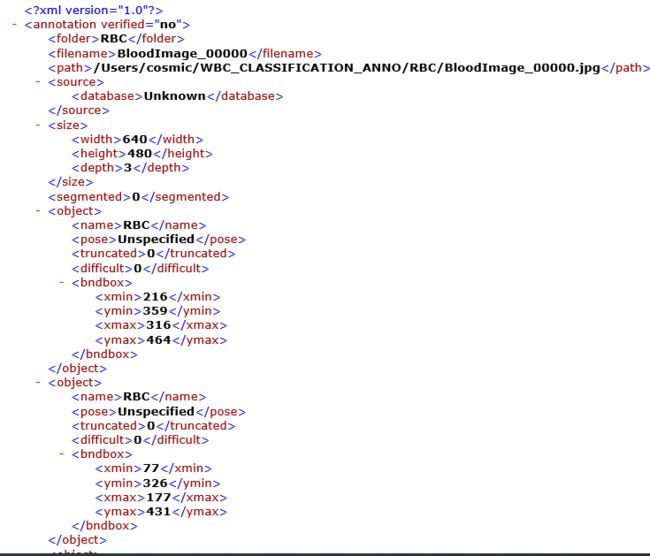
1.解压数据集
!unzip -o data/data85839/RBC.zip -d work/PaddleDetection/dataset/
2.数据集文件夹改名
!mv work/PaddleDetection/dataset/RBC work/PaddleDetection/dataset/test_det
3.将数据集划分为训练集和验证集
import os
import random
# 类别数量
file_saved = [] # 保存数据
random.seed(2021)
# voc数据路径问题
# 根目录信息,子目录信息,files_img--该文件夹下的文件名称
for _, _, files_img in os.walk('work/PaddleDetection/dataset/test_det/JPEGImages'):
random.shuffle(files_img)
for _, _, files_xml in os.walk('work/PaddleDetection/dataset/test_det/Annotations'):
# indexs = 0
# 1.jpg
# 1.xml
for i in range(len(files_img)): # 遍历图片文件--一张一张的
for j in range(len(files_xml)):
# 匹配,与图片前缀名称一致的xml文件
# 前缀是否一致
if files_img[i][:-4] == files_xml[j][:-4]:
# 图片的相对路径 + 空格 + 标注文件的相对路径 + '\n'
# jpeg, img -- join -> jpeg/img
# JPEGImages/files_img[i]
file_maked = os.path.join('JPEGImages', files_img[i]) + ' ' + os.path.join('Annotations', files_xml[j]) + '\n'
file_saved.append(file_maked) # 每一个类别放在对应的缓存空间中
break
# example: 图片的相对路径 + 空格 + 标注文件的相对路径 + '\n'
# 训练集的划分
# 训练集占80%的数据
# 验证集/评估数据集:1-80% = 20%
Train_percent = 0.8
# train.txt保存
with open('work/PaddleDetection/dataset/test_det/train.txt', 'w') as f:
# int(Train_percent * len(file_saved))
# final_index = int(len(file_saved)*Train_percent) - 1
f.writelines(file_saved[:int(len(file_saved)*Train_percent)]) # 写入多行数据
print('train.txt Has Writed {0} records!'.format(len(file_saved[:int(len(file_saved)*Train_percent)])))
# eval.txt保存
with open('work/PaddleDetection/dataset/test_det/eval.txt', 'w') as f:
# final_index + 1 == int(len(file_saved)*Train_percent)
f.writelines(file_saved[int(len(file_saved)*Train_percent):])
print('eval.txt Has Writed {0} records!'.format(len(file_saved[int(len(file_saved)*Train_percent):])))
train.txt Has Writed 274 records!
eval.txt Has Writed 69 records!
输出结果为:
train.txt Has Writed 274 records!
eval.txt Has Writed 69 records!
训练集样本量: 274,验证集样本量: 69
三、模型选择、开发、训练和验证
此项目使用的是ppyolo中的ppyolo_r18vd_coco.yml模型。
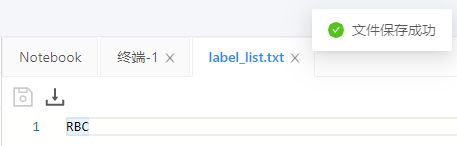
1.新建label_list.txt文件
在dataset/test_det下新建label_list.txt,然后在里面写上你的标注类型(如本项目中的RBC,意思为只标注了红细胞)。
2.下载依赖库
%cd work/PaddleDetection/
!pip install -r requirements.txt
%cd + 路径:进入某路径下。
3.调参
yolov3_darknet_voc.yml文件的配置
architecture: YOLOv3
use_gpu: true
max_iters: 70000
log_iter: 20
save_dir: output
snapshot_iter: 2000
metric: VOC
map_type: 11point
pretrain_weights: https://paddle-imagenet-models-name.bj.bcebos.com/DarkNet53_pretrained.tar
weights: output/yolov3_darknet_voc/model_final
num_classes: 1
use_fine_grained_loss: false
YOLOv3:
backbone: DarkNet
yolo_head: YOLOv3Head
DarkNet:
norm_type: sync_bn
norm_decay: 0.
depth: 53
YOLOv3Head:
anchor_masks: [[6, 7, 8], [3, 4, 5], [0, 1, 2]]
anchors: [[10, 13], [16, 30], [33, 23],
[30, 61], [62, 45], [59, 119],
[116, 90], [156, 198], [373, 326]]
norm_decay: 0.
yolo_loss: YOLOv3Loss
nms:
background_label: -1
keep_top_k: 100
nms_threshold: 0.45
nms_top_k: 1000
normalized: false
score_threshold: 0.01
YOLOv3Loss:
ignore_thresh: 0.7
label_smooth: false
LearningRate:
base_lr: 0.00025
schedulers:
- !PiecewiseDecay
gamma: 0.1
milestones:
- 55000
- 62000
- !LinearWarmup
start_factor: 0.
steps: 1000
OptimizerBuilder:
optimizer:
momentum: 0.9
type: Momentum
regularizer:
factor: 0.0005
type: L2
_READER_: 'yolov3_reader.yml'
TrainReader:
inputs_def:
fields: ['image', 'gt_bbox', 'gt_class', 'gt_score']
num_max_boxes: 50
dataset:
!VOCDataSet
dataset_dir: dataset/test_det
anno_path: train.txt
use_default_label: false
with_background: false
EvalReader:
inputs_def:
fields: ['image', 'im_size', 'im_id', 'gt_bbox', 'gt_class', 'is_difficult']
num_max_boxes: 50
dataset:
!VOCDataSet
dataset_dir: dataset/test_det
anno_path: eval.txt
use_default_label: false
with_background: false
TestReader:
dataset:
!ImageFolder
use_default_label: false
with_background: false
yolov3_reader.yml的配置
TrainReader:
inputs_def:
fields: ['image', 'gt_bbox', 'gt_class', 'gt_score']
num_max_boxes: 50
dataset:
!COCODataSet
image_dir: dataset/test_det
anno_path: train.txt
dataset_dir: dataset/test_det
with_background: false
sample_transforms:
- !DecodeImage
to_rgb: True
with_mixup: True
- !MixupImage
alpha: 1.5
beta: 1.5
- !ColorDistort {}
- !RandomExpand
fill_value: [123.675, 116.28, 103.53]
- !RandomCrop {}
- !RandomFlipImage
is_normalized: false
- !NormalizeBox {}
- !PadBox
num_max_boxes: 50
- !BboxXYXY2XYWH {}
batch_transforms:
- !RandomShape
sizes: [320, 352, 384, 416, 448, 480, 512, 544, 576, 608]
random_inter: True
- !NormalizeImage
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
is_scale: True
is_channel_first: false
- !Permute
to_bgr: false
channel_first: True
# Gt2YoloTarget is only used when use_fine_grained_loss set as true,
# this operator will be deleted automatically if use_fine_grained_loss
# is set as false
- !Gt2YoloTarget
anchor_masks: [[6, 7, 8], [3, 4, 5], [0, 1, 2]]
anchors: [[10, 13], [16, 30], [33, 23],
[30, 61], [62, 45], [59, 119],
[116, 90], [156, 198], [373, 326]]
downsample_ratios: [32, 16, 8]
batch_size: 8
shuffle: true
mixup_epoch: 250
drop_last: true
worker_num: 8
bufsize: 16
use_process: true
EvalReader:
inputs_def:
fields: ['image', 'im_size', 'im_id']
num_max_boxes: 50
dataset:
!COCODataSet
image_dir: dataset/test_det
anno_path: eval.txt
dataset_dir: dataset/test_det
with_background: false
sample_transforms:
- !DecodeImage
to_rgb: True
- !ResizeImage
target_size: 608
interp: 2
- !NormalizeImage
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
is_scale: True
is_channel_first: false
- !PadBox
num_max_boxes: 50
- !Permute
to_bgr: false
channel_first: True
batch_size: 1
drop_empty: false
worker_num: 8
bufsize: 16
TestReader:
inputs_def:
image_shape: [3, 608, 608]
fields: ['image', 'im_size', 'im_id']
dataset:
!ImageFolder
anno_path: dataset/test_det/label_list.txt
with_background: false
sample_transforms:
- !DecodeImage
to_rgb: True
- !ResizeImage
target_size: 608
interp: 2
- !NormalizeImage
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
is_scale: True
is_channel_first: false
- !Permute
to_bgr: false
channel_first: True
batch_size: 1
4.模型训练
%cd work/PaddleDetection/
!python tools/train.py -c configs/yolov3_darknet_voc.yml\
--eval\
--use_vdl True
训练过程中指令解释:
- –c:指定配置文件。
- –eval:边训练边验证。
- –use_vdl True:使用VisualDL记录数据,进而在VisualDL面板中显示。
- !python + 某路径下的python文件:执行某python文件。
训练中出现的问题解决方法: - 断次问题
如果你的模型训练不小心断在了某个轮次,没训练完,可以使用 -r output/模型的yml文件/停在的轮次数(如果你一共要训练200轮次,却停在第20轮次,用的是ppyolo_r18vd_coco模型,你可以使用 -r output/ppyolo_r18vd_coco.yml/20继续进行训练)。 - 指令多的问题
只要后面有指令,可以在每个指令最末尾后加\(\前不能加空格,最后一个指令末尾不用加\)。
四、模型预测
%cd work/PaddleDetection/
!python tools/infer.py -c configs/yolov3_darknet_voc.yml\
-o weights='output/yolov3_darknet_voc/model_final.pdparams'\
--infer_dir 'dataset/test_det/JPEGImages'\
--output_dir 'output'\
--draw_threshold 0.1\
# --save_txt True
-o:设置或更改配置文件里的参数内容
–infer_dir:用于预测的图片文件夹路径
–output_dir:预测后结果或导出模型保存路径
–draw_threshold:可视化时分数阈值
(–save_txt:是否在文件夹下将图片的预测结果保存到文本文件中)
预测图其中一张(也许是老版本的bug,虽然配置文件设置了不用默认标签预测,但是没用,但是这不影响我们在板子上的部署):
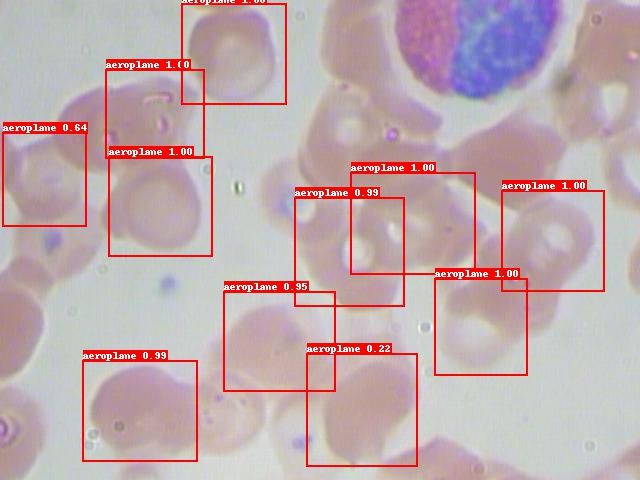
五.模型导出
!python tools/export_model.py -c configs/yolov3_darknet_voc.yml --output_dir=./inference_model \
-o weights=output/yolov3_darknet_voc/best_model
第二个和第三个文件是模型部署要用到的文件,缺一不可,千万不要不小心给删了,最好不要改名。
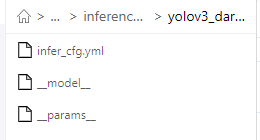
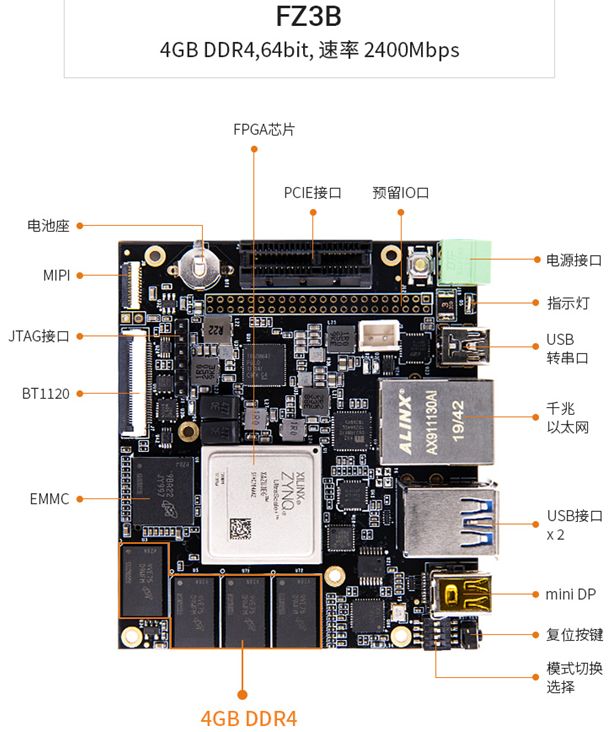
六、模型部署
本项目是在由百度大脑研发的硬件EdgeBoard Lite FZ3B上部署的。

官方文档:
https://ai.baidu.com/ai-doc/HWCE/Yk3b86gvp
拿到EdgeBoard,我们首先要进行windows装驱动操作,接着要对它进行测试。
(本项目只写了一种板子联网方式,也是本人用的一种方式,若对其他联网方式感兴趣,可以点击下文链接,去看看郑博培男神归纳的所有联网方式
https://zhengbopei.blog.csdn.net/article/details/107253560)
首线需要准备一根网线(品牌不限)。
参考链接:https://item.m.jd.com/product/1603934.html?gx=RnFhljFePmaLz9RP–sxPSHz82lJ1rVHVLY&ad_od=share&utm_source=androidapp&utm_medium=appshare&utm_campaign=t_335139774&utm_term=CopyURL
本人使用的是六类原线-0.5米(最好买圆头的,扁头线容易坏,如果为了部署,也不需要买太长的线)。

- 打开控制面板中的“网络连接”。
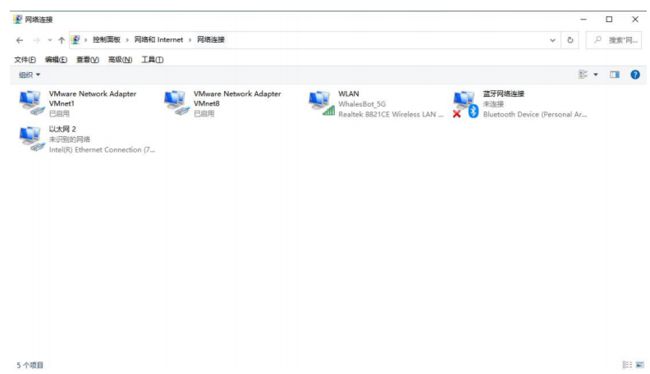 2. 设置以太网(有线网卡)IPv4 地址。
2. 设置以太网(有线网卡)IPv4 地址。 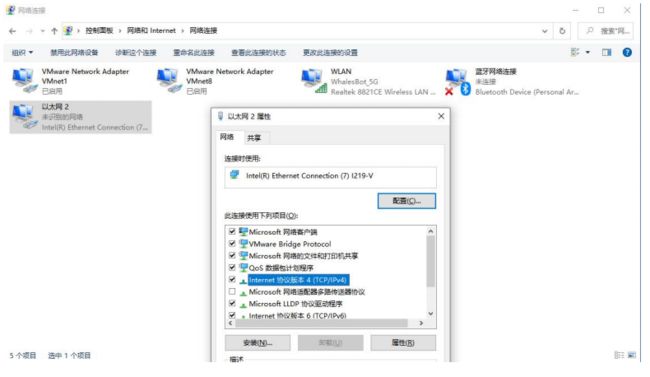
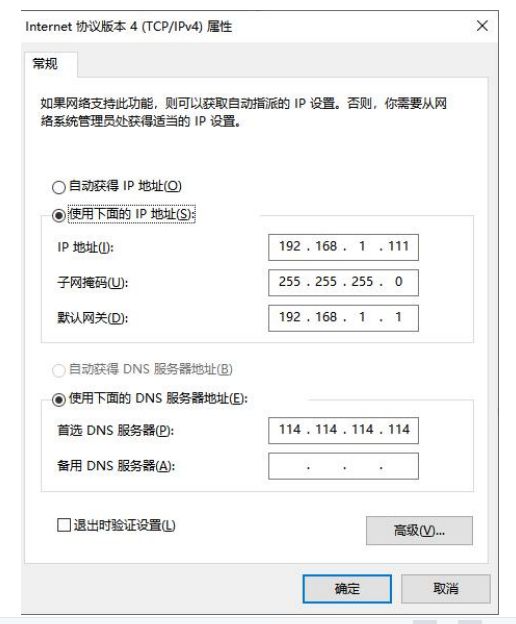
注意:IP 地址前 3 位段必须为 192.168.1,最后一位段为(1~253 或者 255),EdgeBoard 的固定 IP 地址为 192.168.1.254,注意可能发生冲突。
3.EdgeBoard 上电,用网线将 EdgeBoard 与电脑相连,安装 SSH 工具(Xshell,Xftp 等),本 文以 Xshell 为主。EdgeBoard 账户和密码均为 root。
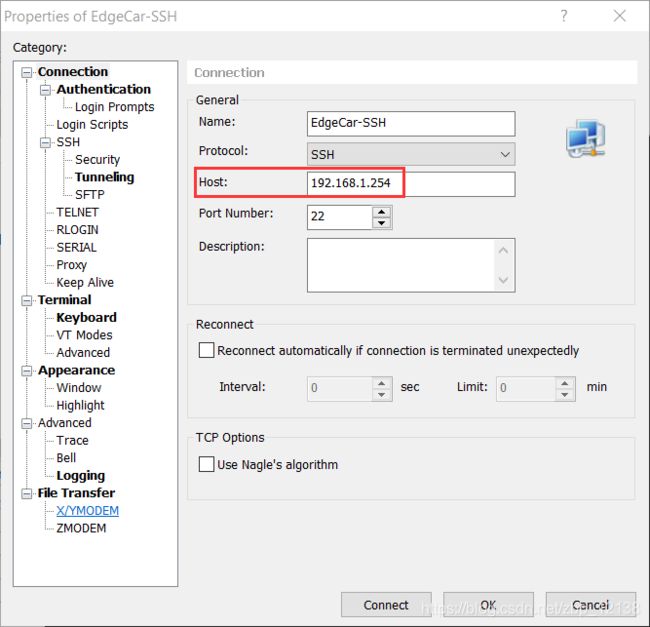
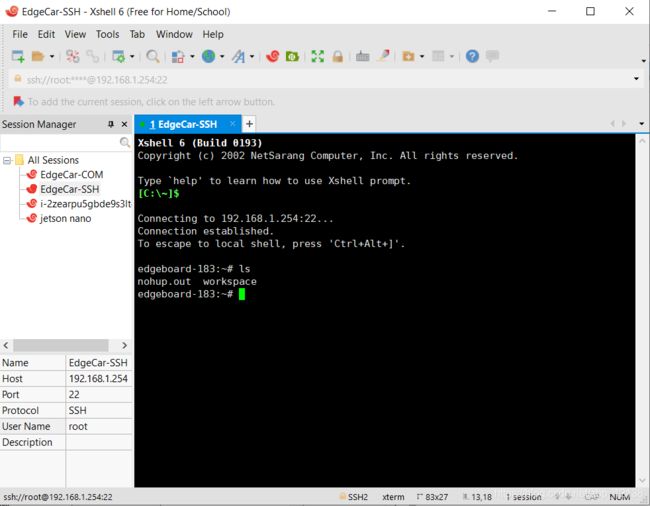
在微软商店下载串口调试助手,如果按reset键,能出现下面的结果,说明板子可以连上,如果输出是空白,则说明板子连不上,可能是板子的tf卡是坏的。)
如果连接不上板子ip,可能是原本的tf卡是坏的,要换张新的,并且烧下板子镜像。(本人收到的tf卡就是坏的,后来自行购买了一张,板子的镜像烧录文档已上传至本项目文件中,镜像文件太大了,所以上传至这个链接:https://91io.cn/s/ppk77i9或https://91io.cn/s/ppk77i9/FZ3B_ubuntu_181_AICreationCamp_210901.rar,两个链接都可以下载,文件有效期30天,或下载9999次到期,文件过期请在评论联系我,请自行下载,镜像文件一定要解压,不然会烧入失败,只需要将img文件传进去,烧录器已上传至项目文件里,具体软件使用教程在压缩包里)
部署所需要的文件:
- model, params(因版本不同,可能文件名会不一样,只要在config.json文件里对上就好,本项目使用的paddle1.8.4、ppdet0.5,所以导出的文件名为—model, params,最好不要改原来的文件名,不然可能会语法运行,本人就遇到过)
- label_list.txt(就是我们之前训练用到的标签文件,如果板子里有这个文件,可以直接改)
- img(放文件的文件夹)
- config.json(eb不支持ppyolo,所以在训练前要注意)
(板子里可能有这个文件,有的话可以直接改,没有的话按下面教程写)
threshold:可以先用默认的,再慢慢调小,叫置信度,也叫阈值,值越小,出现的框会越,其默认为0.3
可以改network_type、model_file_name、params_file_name、labels_file_name、threshold,其他可以默认。
{
"network_type":"YOLOV3",
"model_file_name":"__model__",
"params_file_name":"__params__",
"labels_file_name":"label_list.txt",
"format":"RGB",
"input_width":608,
"input_height":608,
"mean":[123.675, 116.28, 103.53],
"scale":[0.0171248, 0.017507, 0.0174292],
"threshold":0.01
}
- image.json(特别注意路径,本人因使用…/…/而在板子里运行不了)
{
"model_config": "../../../res/models/detection/yolov3",
"input": {
"type": "image",
"path": "../../../res/models/detection/yolov3/img/RBC.jpg"
},
"debug": {
"display_enable": true,
"predict_log_enable": true,
"predict_time_log_enable": false
}
}
2、3、4、5文件可能板子里都有,可以直接改,如果没有,可以自己创建,初学时,文件放置路径最好和板子原始对应文件放置路径一致,以免报错。
怎么把我们的本地文件传进板子里呢?
这时候就需要用到xftp了(xftp可以在我上传到文件的压缩包Xshell6_Plus破解版.zip中找到)。可以通过双击左半部分界面里的文件,把本地文件传输到板子里,你点的是哪个路径下,就会传到相应路径下。如果你的文件需要修改,也可以通过相同的方式把板子里的文件传输到本地。注意路径,不然会忘记文件传输到哪里了,就不太好找了。文件修改操作在板子里操不了,必须在本地完成。
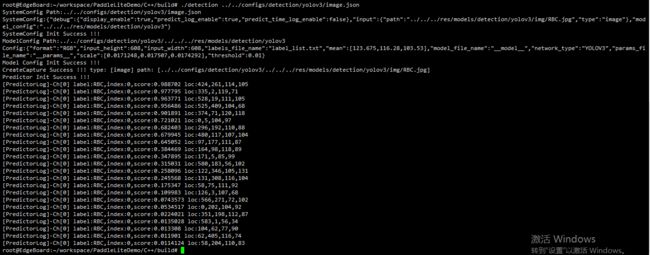
部署代码如下:(在XShell终端分条运行,Xshell软件也是在和Xftp相同的位置找)
cd /root/workspace/PaddleLiteDemo/C++/build
./detection ../../configs/detection/yolov3/image.json
此为部署代码运行后的结果:
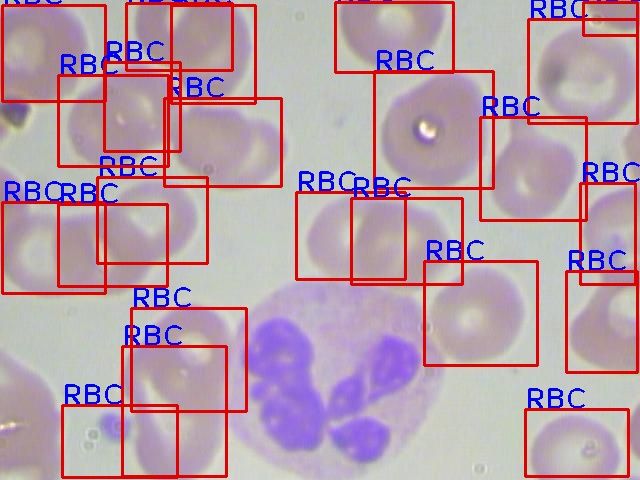
以下为在eb上的单张预测图:(在build目录下)
模型部署可视化视频如下:
b站视频链接:https://www.bilibili.com/video/BV1mF411a7hB?spm_id_from=333.999.0.0
视频输出
接下来需要准备的有
- 树莓派显示屏(如果有台式电脑显示器,就不用买树莓派显示屏了,本人使用的是树莓派显示屏,所以以下操作是针对于树莓派显示屏的)。
参考链接:https://m.tb.cn/h.fiFkmwW?sm=0fdec8
本人使用的是7寸高清屏电容触摸带壳(购买的时候会送minihdmi线,但是不能用,得另外购买)。

- Mini HDMI公转HDMI母转换头(品牌不限):适用于Mini HDMI接口显示器,用来连接EdgeBoard和Mini HDMI显示器(Mini HDMI显示器即本项目中的树莓派显示屏)。
参考链接:https://item.m.jd.com/product/47847791353.html?gx=RnFhljFePmaLz9RP–sxPSHz82lJ1rVHVLY&ad_od=share&utm_source=androidapp&utm_medium=appshare&utm_campaign=t_335139774&utm_term=CopyURL
本人使用的是Mini HDMI公转标准HDMI母。

- 主动式miniDP公转HDMI母转换线:来连接EdgeBoard和HDMI显示器。
参考链接:https://aim.baidu.com/product/649bd2ab-65ef-480d-b1bf-2ba8f10059ab
建议使用eb的原产线,因为市场上的线质量参差不齐。

调用摄像头
1. 安装驱动(在eb终端输入命令)
insmod /root/workspace/driver/driver/ch341.ko
insmod /root/workspace/driver/driver/usbserial.ko
insmod /root/workspace/driver/driver/fpgadrv.ko
2. 测试摄像头(在eb终端输入命令)
摄像头参考链接:https://m.tb.cn/h.fRe4a6u?sm=0deb57
本人使用的是usb工业摄像头jpg/YUY2高速 HF877_3mm_90度无畸变60帧。

测试脚本:test_onecamera.py(由郑博培男神贡献的脚本,在此感谢郑博培男神,此脚本我已上传至文件中,大家有需要的可以自行下载)。
python3 test_camera.py
能看到显示屏上有个蓝色的圈圈以及eb终端上有test!以及坐标,就说明摄像头测试成功。
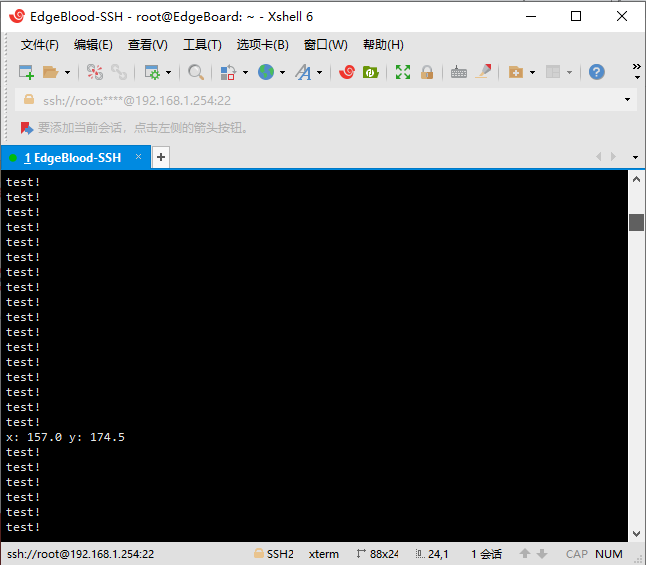
测试完,按Ctrl+C退出。
有点遗憾的是,很抱歉没完成摄像头预测,没能帮到大家。希望有大佬可以解决这个摄像头预测。
model、params(前两个文件名前后都有__,由于打上去会变成字体加粗,就省去了)、detectionResult、config.json、image.json、label.txt文件都上传至项目文件中,大家可以按照步骤自己训练、调参,也可以体验下本项目训练出来的模型参数与在板子上预测出来的结果图。
七、总结与升华
部署首先得把模型训练正常,并且正确导出模型,模型要能用Netronhttps://netron.app/(因此网站用特殊工具才能打开,所以我将PC端启动程序放置在项目文件中)打开,不然可能模型错误。拿到板子前要先测试,看看tf卡是不是好的。板子要注意用1.8.x版本训练,比较稳定,并且要看好板子支持的部署模型,之前上课期间因不知eb不支持ppyolo模型。后来知道了,就换成了yolov3。并且我也由2.1的两个模型换成了1.8.x来运行模型。重要东西一定要保存在work/目录下,防止某一天重启环境,notebook桌面里的文件丢失。特别是训练特别久的模型。模型导出后最好不要改模型文件的名字,以免部署失败。要注意image.json下的文件路径。希望这个项目可以帮助到大家。本以为这个项目要完不成了,突然部署的最后一天来了希望。这真是20岁第一天的好兆头。
个人简介
请大家多多支持。欢迎fork、喜欢、分享、评论。本人能力有限,经验不足,若有不足,欢迎指正,谢谢大家!
姓名:林勇
学校:西安科技大学高新学院
学历:本科二年级在读
专业:智能科学与技术
擅长领域:cv(目标检测)
AI Studio链接:我在AI Studio上获得白银等级,点亮6个徽章,来互关呀~
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/691883
github链接:https://github.com/FZSWJLY
qq:1431364191
微信:programmerxiaoyong