论文导读 | 最大独立集问题的求解
图的最大独立集问题(MIS problem)是图论研究中的一个重要问题,具有广泛的应用。本文介绍了最大独立集求解相关的三篇工作,包括一篇启发式方法和两篇基于学习的方法,希望能让大家对这个问题有所了解。
问题定义
一个图G(V, E)的顶点集子集I称为图G的一个独立集(independent set)是指:I中任意两点没有边相连。图G中大小最大的独立集(拥有顶点数目最多)称为图G的最大独立集(maximum indepent set,MIS)。
与独立集类似的概念还有顶点覆盖(vertex cover):称G的顶点子集C为G的一个顶点覆盖,是指C中包含G中任意一条边的至少一个顶点。大小最小的顶点覆盖称为图G的最小顶点覆盖(minimum vertex cover,MVC)。
例如下图中,可以找到如下最大独立集和最小顶点覆盖:

需要注意的是一个图的最大独立集和最小顶点覆盖可能不是唯一的。
读者可以容易地根据定义证明如下结论:I为G的(最大)独立集当且仅当V/I为G的(最小)顶点覆盖。
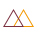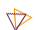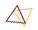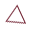
Computing A Near-Maximum Independent Set in Linear Time by Reducing-Peeling

原文《Computing A Near-MaximumIndependent Set in Linear Time by Reducing-Peeling》发表在SIGMOD2017。
文中针对真实图提出了求解MIS问题的框架——Reducing-Peeling框架,并结合该框架提出了四种启发式算法。这些算法可以高效地在线性时间复杂度或者近似线性时间复杂度下,近似求解真实图的独立集,实际实验中较好地验证了这一点。
论文地址:
https://dl.acm.org/doi/10.1145/3035918.3035939
问题引入
近年来,许多学者提出了不同的MIS求解方法,这些方法可以归为如下三类:
(1)精确算法。MIS问题是NP难的,暴力求解并适当剪枝的方法虽然能求出精确解,但通常需要指数时间复杂度,效率不高。
(2)近似算法。近似算法求解MIS的近似解,并给出误差上界,时间复杂度较精确算法得到很大改进。
(3)启发式算法。这是一类线性时间或近似线性时间的算法,通过贪心的方法,逐步扩大顶点集合,使其仍满足独立集的性质。缺点是得到得独立集是近似解,且没有误差估计。
作者通过观察真实图,发现有真实图的三种特征:(a)节点度数服从幂律(power-law),有很多节点度数很小。(b)一些约化规则(reduction rules)(什么是约化规则,下面有进一步介绍)可以高效去除一些度数低的节点,并保持求得独立集的最大性。(c)高度数节点比低度数节点有更小概率出现在最大独立集中。
故作者针对这三个特征,提出了reduction-peeling 框架来求解MIS问题,本质上属于启发式方法。
两种约化规则
本文作者介绍了两种约化规则,通过这两种规则,可以快速删去原图中度数较小的一些顶点以及其相邻的边,在简化问题规模的同时,还确保了原图和新图最大独立集的一致性。作者将这两种约化规则称为度数一约化(degree-one reduction)和度数二约化(degree-two reduction)。
度数一约化是指若删去原图中与度数为1的节点u相邻的节点v以及v的所有相邻边,图的最大独立集不会改变。
度数二约化相对比较复杂:记图中度数为2的节点u的两个邻居为w和v,若w和v有边相连,则可以将w和v两个顶点删除;若w和v没有边相连,则可以将u、v和w三个顶点缩为一点,求解出新图的最大独立集后,将其还原(独立集大小加1)。如下所示:其中G\S表示在图G中删去顶点集S和相邻边,G/S代表将图G中顶点集S收缩为一点,![]() 表示图G的最大独立集大小。
表示图G的最大独立集大小。

Reduction-peeling 框架
这是本文四种算法的框架,主要思想为通过约化缩小问题规模,当没有约化规则适用时,则直接删去度数最大的节点(基于观察c)。最终得到一个只有孤立点的图,其中点构成了原图的一个独立集。框架的伪代码如下所示:

在 reduction-peeling 框架中应用度数一约化和度数二约化,就得到了本文中的BDOne算法和BDTwo算法:


线性时间算法和近似线性时间算法
尽管BDTwo算法可以得到很好的结果,但其时间复杂度较高(后面有时间复杂度比较),为了简化过程,作者又提出了两种约化方法——度数二路径约化(degree-two path reduction)和支配约化(dominance reduction)(具体可参考原文),并结合reduction-peeling 框架,提出了线性时间(linear time)算法和近似线性时间(near linear time)算法,效率有较大提升,伪代码如下所示:


实验分析
作者分析了本文中四种算法的时间和空间复杂度,较精确算法提升很大:

并与其他方法做了对比分析:
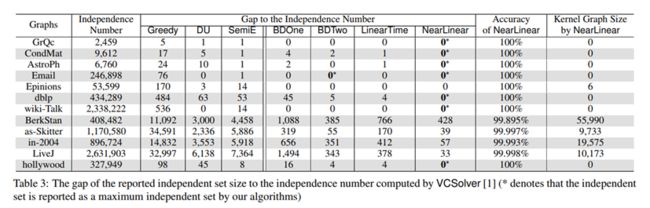
可以发现近似线性算法取得的效果是最优的(求得的独立集大小近似等于最大独立集大小),作者也比较了不同算法的运行时间和内存占用(具体可参考原文),结果表明本文方法具有一定优越性。
Combinatorial Optimization with Graph Convolutional Networks and Guided Tree Search

原文《Combinatorial Optimization with Graph Convolutional Networks and Guided Tree Search》发表在NIPS 2018。
本文通过训练图神经网络,预测图中每个节点出现在问题结果集中的可能性,来解决一类求解NP难的图问题,例如MIS、MVC等(近似解)。
论文地址:
https://dl.acm.org/doi/10.5555/3326943.3326993
问题引入
近年来,出现了很多基于学习(learning based)的方法求解NP难的问题。通常对于NP难的问题,如果在意运行时间,我们只能寄希望于启发式方法。而基于学习的方法通常能通过大量训练数据,发现人类设计者难以察觉的模式和规则帮助问题的求解。
本文主要研究如下四种与图相关的NP难问题:最大独立集(maximum independent set,MIS)、最小顶点覆盖(minimum vertex cover,MVC)、最大团(maximal clique,MC)和可满足性(satisfiability,SAT)。这四类问题可以在多项式时间内相互转化,具体可查看原文附录(MIS和MVC的等价性在问题定义部分已经介绍)。本文主要研究图神经网络解决MIS问题。
初始方法
作者先提出了应用图神经网络解MIS问题的初始方法。
记![]() 为待求解MIS的图,
为待求解MIS的图,![]() 为顶点集合,顶点个数为N,
为顶点集合,顶点个数为N,![]() 为邻接矩阵,是对称阵(图为无向图)。主体思想为训练一个神经网络
为邻接矩阵,是对称阵(图为无向图)。主体思想为训练一个神经网络![]() ,输入为1代表该点应包含在MIS的解中,0代表该点不包含在MIS的解中。但一般这样的直接预测可能不能保证独立性,所以还需要后期处理。网络采用基础的图卷积网络
,输入为1代表该点应包含在MIS的解中,0代表该点不包含在MIS的解中。但一般这样的直接预测可能不能保证独立性,所以还需要后期处理。网络采用基础的图卷积网络
![]()
其中
![]()
为第l层特征(初始赋值为全1向量),
![]()
和
![]()
为第l层可学习的参数,D为图的度数对角矩阵,![]() 为激活函数(除最后一层使用sigmoid,其他层使用ReLU)。可以看出,由于第l层的网络参数与具体图数据无关,故此网络可以适用于任何图MIS的求解。给定训练数据集
为激活函数(除最后一层使用sigmoid,其他层使用ReLU)。可以看出,由于第l层的网络参数与具体图数据无关,故此网络可以适用于任何图MIS的求解。给定训练数据集
![]()
,则可采用交叉熵损失函数

(第i个训练样本的损失)。
虽然我们希望网络 能直接输出1或0代表该点是否应当出现在MIS的解中,但我们并不能直接这样处理,原因有二:(1)最后一层网络的输出是取值是[0, 1]中的数,并不一定恰好等于1或0;(2)即便输出是0或1,这样的解甚至有可能不构成独立集。
为解决这个问题,作者提出了将图中各点按照网络输出值从大到小排序,取值较大代表该点更有可能出现在MIS的解中,由此逐步构造一个独立集,伪代码如下所示:

改进算法
前面提到的基础算法仍有一些细节上没有解决的问题,例如,怎么区别同一图中的多个MIS解?比如下面的图示中,任意对角的两点都构成MIS,网络给出的输出可能四个点值都是相同的:
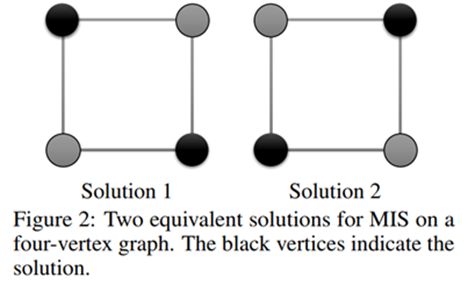
为解决这个问题,作者又提出了初始方法的改进版本:

同时训练M个网络,取训练样本的损失为这M个网络中最小的损失,这使得样本损失只由最适合(损失最小)的那个网络决定,可以学习到多样化的解。伪代码如下:
实验分析
作者对比了不同方法求解MIS和MVC问题的效果和时间(时间比较可查看原文),发现本文提出的方法在选定的数据集上都取得了最好的效果(注意MVC解集越小越好):

Learning What to Defer for Maximum Independent Sets

本文通过强化学习的方式,引入马尔可夫决策过程,逐步往解集中加点解决MIS问题。
论文地址:
https://arxiv.org/abs/2006.09607
学习推迟
本文作者采用学习推迟(learning what to defer,LwD)的方法来逐步生成MIS问题的解集。其主要思想为:当前阶段可以判断是否出现在MIS解集,那我们就先做判断;若当前阶段尚且无法判断某点的归属(是否属于解集),那我们则将这个判断留到之后的阶段。这样的方式比较适合MIS这类跟图局部特征有关的问题,并且效果比一般的贪心算法要好,因为它可以同时对很多点做判断。
框架介绍
设图为![]() ,MIS本质是求一向量
,MIS本质是求一向量![]() ,并且使
,并且使![]() 最大化。
最大化。
我们便可引入马尔可夫决策过程:节点状态空间为
![]()
,其中*代表当前节点状态未定;1代表该节点出现在MIS解集中;0代表不出现在MIS解集中。初始时刻每个节点的状态都是*。终止条件为每个节点都赋有非未定状态,或者运行时间超过设定的阈值。
每一步,我们给未定状态的节点一个行动(action)用来更新节点状态,
![]()
,其中
![]()
代表当前步骤状态未定的节点集。状态更新包含两步:update和clean up。update直接将状态未定的节点赋状态为行动值,clean up主要包含三类操作:(1)将某些只和状态0节点相连的节点的状态置为1。(2)回退两个状态为1且相邻的节点的状态为*。(3)将某些与状态1节点相连的节点的状态置为0。下面的状态图展示了如上的更新步骤:

那如何通过学习的方式得到这样的行动a呢?作者采用了图神经网络的方式:

,初始化H包括每个节点的度数和相应轮次(需要做归一化)。最后一层网络采用softmax就能产生一个行动a。具体训练步骤和过程可以参考原文。
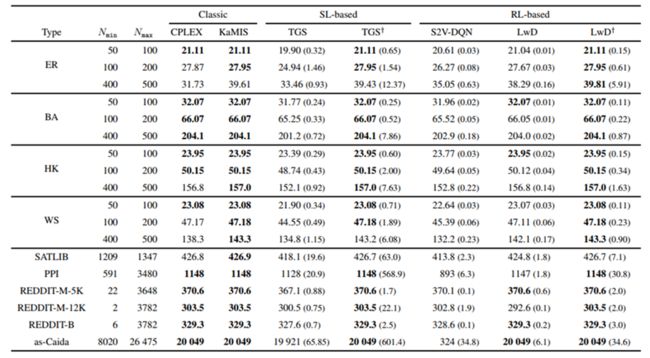
实验分析
作者同样在一些数据集上做了实验,提出的方法在某些场景下能够取得很好的效果:
总结
本文通过介绍三篇与最大独立集计算有关的三篇工作,我们能对这个图计算问题有个简单直观的印象。如何设计效果更好的启发式或学习型的新算法仍需要我们继续探索。