Python学习-----Day09
一、利用装饰器来获取函数运行的时间、
#导入time模块
import time
def decorated(fn):
def inner():
#time.time获取函数执行的时间
a = time.time() # func开始的时间
fn()
b = time.time() # func结束的时间
print(f"{fn.__name__}程序运行的总数时间:{b - a}秒")
return inner
@decorated
def func():
time.sleep(2) #使程序睡眠2秒钟后在执行
print("王者荣耀")
func()
二、装饰器
了解:
*args 理解成传入一个元组
**kwargs 理解成传入一个字典def guanjia(fun):
def inner(*args, **kwargs): # 可变参数 *args接过来是元组 **kwargs 接过来是字典
print("123")
ret = fun(*args, **kwargs) # 解包拆包
print("456")
return ret
return inner
@guanjia
def play1(uname, pwd):
print("静安寺大家")
print(f"用户{uname},密码是{pwd}")
return "你真6"
@guanjia
def play2(uname, pwd, area):
print("案说法")
print(f"用户{uname},密码是{pwd},地区是{area}")
return "哈哈哈"
a = play1("zs", "123456")
print(a)
print()
b = play2("zjj", "123456", "suqian")
print(b)在这段代码中,*args和**kwargs允许函数接受任意数量的位置参数和关键字参数。*args将传入的位置参数打包成一个元组,**kwargs将传入的关键字参数打包成一个字典。
在inner函数中,使用*args和**kwargs来接收传入的参数,并调用原始函数fun时使用解包拆包的方式将这些参数传递给原始函数。
这样做的好处是,guanjia装饰器可以适用于任意数量和类型的参数的函数,而无需提前知道函数的参数个数和名称。
三、多个装饰器的执行顺序
函数外包裹函数的目的是为了向内部函数wrapper传参。
最终都是将原函数func_test换成wrapper函数。
装饰器的加载顺序从下到上。
装饰器的执行顺序从上到下
# 3. func1指向的是原函数wrapper2的内存地址
def deco1(func1):
print('deco1 start')
def wrapper1(*args, **kwargs):
print('wrapper1 start')
res = func1() # 4 func1是wrapper2
print('wrapper1 stop')
return res
print('deco1 stop')
return wrapper1
# 2. func2指向的是原函数wrapper3的内存地址
def deco2(func2):
print('deco2 start')
def wrapper2(*args, **kwargs):
print('wrapper2 start')
res = func2() # 5 func2是wrapper3
print('wrapper2 stop')
return res
print('deco2 stop')
return wrapper2
# 1. func3指向的是原函数func_test的内存地址
def deco3(func3):
print('deco3 start')
def wrapper3(*args, **kwargs):
print('wrapper3 start')
res = func3() # 6 func3是原函数func_test
print('wrapper3 stop')
return res
print('deco3 stop')
return wrapper3
# 装饰器的加载顺序从下到上。
@deco1
# func_test = deco1(func_test)
# => func_test = deco1(wrapper2)
# => func_test = wrapper1
@deco2
# func_test = deco2(func_test)
# => func_test = deco2(wrapper3)
# => func_test = wrapper2
@deco3
# func_test = deco3(func_test)
# => func_test = wrapper3
def func_test():
print('func_test')
# 装饰器的执行顺序从上到下。
func_test()
'''
deco3 start
deco3 stop
deco2 start
deco2 stop
deco1 start
deco1 stop
wrapper1 start
wrapper2 start
wrapper3 start
func_test
wrapper3 stop
wrapper2 stop
wrapper1 stop
'''
四、高阶函数
什么是高阶函数?
- 一个函数的函数名作为参数传给另外一个函数
- 一个函数返回值(return)为另外一个函数(返回为自己,则为递归
实例一:一个函数的函数名作为参数传给另外一个函数
def func():
print("定义一个普通函数")
def high_level(func):
print("定义一个高阶函数")
# 在函数内部,通过传入的函数参数调用
func()
high_level(func)
# 结果
"""
定义一个高阶函数
定义一个普通函数
"""
把一个函数名作为参数传给另外一个函数之后,就可以在高阶函数内部调用这个函数了
实例二:一个函数返回值(return)为另外一个函数
def func():
print("定义一个普通函数")
def high_level(func):
print("定义一个高阶函数")
return func
# return func() 这个是直接返回函数调用,递归函数就是如此
res = high_level(func)
# 高阶函数返回函数之后在调用func函数
res()
# 结果
"""
定义一个高阶函数
定义一个普通函数
"""
要高阶函数的返回值为函数,则必须要把函数作为参数传入
五、python内置的高阶函数
1、map
2、filter
3、reduce:是functools模块中的函数,需要导入
高阶函数:map
map函数接收的是两个参数,一个是函数名,另外一个是序列,其功能是将序列中的数值作为函数的参数依次传入到函数值中执行,然后再返回到列表中。返回值是一个迭代器对象
eg:
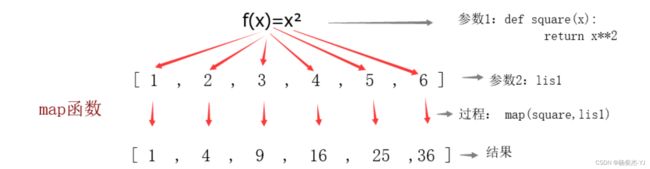
def func(x):
return x**2
map(func, [2,3,4,5])
print(map(func, [2,3,4,5]))
print(type(map(func, [2,3,4,5])))
res = map(func, [2,3,4,5])
for i in res:
print(i)
list(map(func, [2,3,4,5]))
# 结果
"""
- 可以看出,只要用map函数,就可以让列表中的每一个数都完成一次对函数参数的调用,并将结果返回到一个可迭代对象中
- 可以通过 list(map()) 将map函数返回的迭代对象转化为列表
高阶函数map一般 和 匿名函数 lambda联合使用
calc1 = lambda x:x**2
print(calc1(2))
calc2 = lambda x, y : x*y
print(calc2(3, 5))
print(list(map(calc1, [6,7,8,9])))
# 或 # 两者是一样的
print(list(map(lambda x, : x**2, [6,7,8,9])))
print(list(map(calc2, [2,3,4,5], [6,7,8,9])))
# 或 # 两者是一样的
print(list(map(lambda x, y : x*y, [2,3,4,5], [6,7,8,9])))
# 结果
"""
4
15
[36, 49, 64, 81]
[36, 49, 64, 81]
[12, 21, 32, 45]
[12, 21, 32, 45]
"""
对于迭代器Iterator三种方式访问
- next()
- for循环
- 变成列表
res = map(lambda x:x**3, [2,3,4])
next(res)
res = map(lambda x:x**3, [2,3,4])
for i in res:
print(i)
res = map(lambda x:x**3, [2,3,4])
print(list(res))
高阶函数:filter
filter函数 也是接收一个函数和一个序列的高阶函数,其主要功能是过滤。其返回值也是迭代器对象,例如:
,其图示如下:

过滤
对指定的序列进行过滤,若为真,则传入数据 所有非零的数字都为真
filter(lambda x:x % 2,[1,2,3,4])
for i in a:
print(i)高阶函数:reduce
reduce函数也是一个参数为函数,另一个参数为可迭代对象 Iterable Object(eg: list列表)其返回值为一个值而不是迭代器对象,故其常用与叠加、叠乘等,图示例如下

reduce中的函数必须也要接收2个参数,执行时把前一个结果继续和序列的下一个元素做累积计算,其效果就是:
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
from functools import reduce
def func(x, y):
return x*10 + y
reduce(func, [3,4,5,6])
# func(3,4) = 3*10+4 = 34
# func( func(3,4),5) = func(34, 5) = 34*10+5 = 345
# func( func( func(3,4), 5), 6) = 345*10 +6 = 3456
# 结果
# 3456
各个容器的遍历
for i in list: #列表
print(i)
tuple = (1,2,3,4,5,6) #元组
for i in tuple:
print(i)
dict = {
"name": "zhangsan" #遍历字典
}
print(dict.items())
for k, v in dict.items(): # 添加冒号(:)
print(k, ":", v)六、 模块
模块是一个包含所有你定义的函数和变量的文件,其后缀名是.py。模块可以被别的程序引入,以使用该模块中的函数等功能。这也是使用 python 标准库的方法。
import 语句
想使用 Python 源文件,只需在另一个源文件里执行 import 语句
当解释器遇到 import 语句,如果模块在当前的搜索路径就会被导入。
搜索路径是一个解释器会先进行搜索的所有目录的列表。如想要导入模块 support,需要把命令放在脚本的顶端
import 需要引用的模块
import support
from … import 语句
Python 的 from 语句让你从模块中导入一个指定的部分到当前命名空间中,语法如下:
from modname import name1[, name2[, ... nameN]]例如,要导入模块 fibo 的 fib 函数,使用如下语句:
>>> from fibo import fib, fib2
>>> fib(500)
1 1 2 3 5 8 13 21 34 55 89 144 233 377这个声明不会把整个fibo模块导入到当前的命名空间中,它只会将fibo里的fib函数引入进来
from … import * 语句
把一个模块的所有内容全都导入到当前的命名空间也是可行的,只需使用如下声明:
from modname import *
这提供了一个简单的方法来导入一个模块中的所有项目。然而这种声明不该被过多地使用。
七、包、导包
包(package)的概念和结构
当一个项目中有很多个模块时,需要再进行组织。我们将功能类似的模块放到一起, 形成了“包”。本质上,“包”就是一个必须有__init__.py 的文件夹。典型结构如下:

包下面可以包含“模块(module)”,也可以再包含“子包(subpackage)”。就像文件 夹下面可以有文件,也可以有子文件夹一样。

上图中,a 是上层的包,下面有一个子包:aa。可以看到每个包里面都有__init__.py 文件。
导入包操作和本质
上一节中的包结构,我们需要导入 module_AA.py。方式如下:
- 在使用时,必须加完整名称来引用
import a.aa.module_AA- 在使用时,可以直接使用模块名
from a.aa import module_AA- 在使用时,直接可以使用函数名
from a.aa.module_AA import fun_AA- from package import item 这种语法中,item 可以是包、模块(文件),也可以是单个函数、 类、变量。
- import item1.item2 这种语法中,item 必须是包或模块,不能是其他。
导入包的本质其实是“导入了包的__init__.py”文件。也就是说,”import pack1”意味 着执行了包 pack1 下面的__init__.py 文件。 这样,可以在__init__.py 中批量导入我们需要 的模块,而不再需要一个个导入
案例:
import random
#使用方法 对象. 方法
a = random.random()#0-1 [0,1)随机数
print(a)
import threading as th #起别名
th.Thread()
from threading import Thread
Thread()
from random import *
a = randm
perint(a)八、数学模块 math
| 函数 | 返回值 ( 描述 ) |
| abs(x) | 返回数字的绝对值,如abs(-10) 返回 10 |
| ceil(x) | 返回数字的上入整数,如math.ceil(4.1) 返回 5 |
| floor(x) | 返回数字的下入整数,如math.floor(11.3)返回 11 math.floor(-11.6)返回 -12 |
| cmp(x, y) | 如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1 |
| fabs(x) | 返回数字的下舍整数,如math.floor(4.9)返回 4 |
| log(x) | 如math.log(math.e)返回1.0,math.log(100,10)返回2.0 |
| log10(x) | 返回以10为基数的x的对数,如math.log10(100)返回 2.0 |
| max(x1, x2,...) | 返回给定参数的最大值,参数可以为序列 |
| min(x1, x2,...) | 返回给定参数的最小值,参数可以为序列。 |
| modf(x) | 返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。 |
| pow(x, y) | x**y 运算后的值。如math.pow(2,3)表示2的3次方,返回8 |
| round(x [,n]) | 返回浮点数x的四舍五入值,如给出n值,则代表舍入到小数点后的位数。 |
| sqrt(x) | 返回数字x的平方根 |
九、OS模块
os 模块提供了非常丰富的方法用来处理文件和目录
| 方法 | 描述 |
| os.chdir(path) | 改变当前工作目录 |
| os.getcwd() | 获取当前工作路径 |
| os.chmod(path, mode) | 更改权限 |
| os.chdir() | 切换工作路径 |
| os.mkdir() | 创建一个新的文件价夹,不能创建多级的文件夹 |
| os.makedirs() | 创建多级目录 |
| os.rmdir() | 删除空文件夹 |
| s.remove() | 删除文件 |
| os.rename(src, dst) | src 原路径,dst修改后的命名 只能重命名原路径 src 最后的路径或文件的名字,中间路径都必须要存在,否则就会抛出FileNotFoundError |
| os.curdir() | 返回当前目录: ('.') |
| os.listdir() | 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 |
| os.sep | 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" |
| os.environ | 获取系统环境变量 |
| os.getpid() | 获取当前进程编号 |
| os.getppid() | 获取父进程编号 |
| os.kill() | 杀死进程 |
| os.path 模块 | 获取文件的属性信息 |
| os.listdir(path) | 返回指定的文件夹包含的文件或文件夹的名字的列表 |
十、os.path 模块
os 模块是 Python 内置的与操作系统功能和文件系统相关的模块。该模块的子模块 os.path 是专门用于进行路径操作的模块。 常用的路径操作主要有判断目录是否存在、创建目录、删除目录和遍历目录等。
exists()方法——判断路径是否存在(准确)
exists() 方法用于判断路径(文件或目录)是否存在,如果存在则返回 True ;不存在则返回 False。如果是断开的符号链接,也返回 False
os.path.exists(path)
isdir()方法——判断是否为目录
os.path.isdir(path)
isdir() 方法用于判断指定的路径是否为目录
os.path.isfile(path)
如果path是一个存在的文件,返回True。否则返回False path只可以是文件
join()方法——拼接路径
join() 方法用于将两个或者多个路径拼接到一起组成一个新的路径
os.path.join(path, *paths)
参数说明:
- path:表示要拼接的文件路径。
- *paths:表示要拼接的多个文件路径,这些路径间使用逗号进行分隔。如果在要拼接的路径中,没有一个绝对路径,那么最后拼接出来的将是一个相对路径。
- 返回值:拼接后的路径。
实例:
import os.path # 导入os.path模块
print(os.path.join(r"E:\Code\lesson", "main.py")) # 拼接字符串
# 如果要拼接的路径中,存在多个绝对路径,那么按从左到右顺序,以最后一次出现的绝对路径为准,
# 并且该路径之前的参数都将被忽略,代码如下:
# C:/demo
print(os.path.join('E:/Code', 'E:/Code/lesson', 'Code', 'C:/', 'demo')) # 拼接字符串abspath()方法——获取绝对路径
abspath() 方法用于返回文件或者目录的绝对路径
os.path.abspath(path)
basename()方法——从一个路径中提取文件名
basename() 方法用于从一个路径中提取文件名。当指定的路径是一个不包括文件名的路径(如 E:\Code\lesson\) 时,返回空字符串
os.path.basename(path)
dirname()方法——获取路径中的目录
dirname() 方法用于从一个路径中提取目录。它相当于使用 os.path.split() 方法分割路径后,得到的第一个元素