树上问题相关笔记
LCA
LCA,即最近公共祖先。
我们用 f ( i , j ) f(i,j) f(i,j) 表示 i i i 的第 2 j 2^j 2j 级父亲,由于 i i i 的第 2 j 2^j 2j 级父亲可以由它的第 2 j − 1 2^{j-1} 2j−1 父亲向上再跳 2 j − 1 2^{j-1} 2j−1 层得到,那么 i i i 的第 2 j 2^j 2j 级父亲就是它 2 j − 1 2^{j-1} 2j−1 级父亲的 2 j − 1 2^{j-1} 2j−1 级父亲,所以预处理 f 数组可以通过递归实现,具体转移方程如下: f ( i , j ) = f ( f ( i , j − 1 ) , j − 1 ) f(i,j)=f(f(i,j-1),j-1) f(i,j)=f(f(i,j−1),j−1)。
于是乎我们可以得到预处理 f 数组的代码,时间复杂度为 O ( n log n ) O(n\log n) O(nlogn)。
for(int i=1;i<=n;i++) f[i][0]=fa[i];//存储每个点的父亲
for(int j=1;j<=20;j++)
for(int i=1;i<=n;i++)
f[i][j]=f[f[i][j-1]][j-1];
注意,预处理代码不要放在求深度的 DFS 里!!!
加下来考虑向上跳的过程。首先我们要进行一个操作,让求 LCA 的两个点跳到同一层,然后再让它们同步往上跳。于是乎,我们要先 DFS 一下统计每个节点的深度,具体代码如下:
void dfs(int x,int fa)
{
dep[x]=dep[fa]+1;//注意这里是dep[fa],之前错写成dep[to[x]]了
for(int i=head[x];i;i=nxt[i])
{
if(to[i]==fa) continue;
dfs(to[i],x);
}
}
然后就可以考虑倍增求 LCA 了。由于每个十进制数一定能拆成不同的几个二进制数的和,于是乎我们可以从大到小枚举 2 i 2^i 2i 层,如果它们的公共祖先不相等,可以选择继续往上跳。对于相等的两个节点 x x x、 y y y,它们的 LCA 一定是 x x x 或 y y y,如果达不到这个效果,那么一定能跳到一个挨着两点 LCA 的点,即它们 LCA 的儿子。这个过程代码实现如下:
int lca(int x,int y)
{
if(dep[x]<dep[y]) swap(x,y);
for(int i=20;i>=0;i--) if(dep[f[x][i]]>=dep[y]) x=f[x][i];//如果x的祖先还比y深,可以跳
if(x==y) return x;
for(int i=20;i>=0;i--)
if(f[x][i]!=f[y][i])
x=f[x][i],y=f[y][i];
return f[x][0];//返回父亲
}
练手板子题
代码如下:
#include 树链剖分
简介
树链剖分,简称树剖,就是把一棵树分成几条链,把树形简化为链状从而简化问题的方法。这玩意儿还要用线段树。
常用问题
- 将树从 x x x 到 y y y 结点最短路径上所有节点的值都加上 z z z
- 求树从 x x x 到 y y y 结点最短路径上所有节点的值之和
- 将以 x x x 为根节点的子树内所有节点值都加上 z z z
- 求以 x x x 为根节点的子树内所有节点值之和
前置芝士
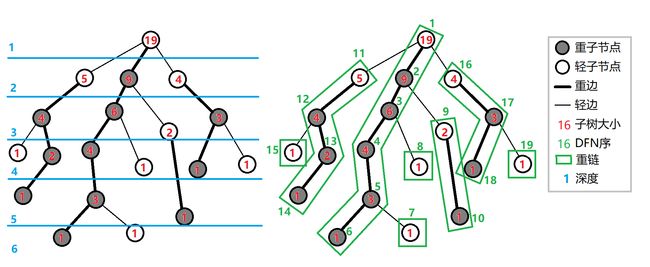
- 重儿子:对于一个非叶子节点,它的所有儿子中,有一个儿子子树最大,这个儿子就是它的重儿子。
- 轻儿子:除重儿子外的所有儿子。
- 重链:除了顶部为轻儿子,其他全部为重儿子的一条路径。

如图所示,红色的为重链和重儿子。
重链剖分
长链剖分
长链剖分和重链剖分类似,只不过更改了重儿子的定义,定义重儿子为其子节点中子树深度最大的子节点。如果存在相同深度的,取其一。从这个节点到重儿子的边为重边。可以把落单的节点也当成重链。
树的重心
定义
对于一个点,以它为根,对于它的子树,如果能使包含最多个点的子树即最大子树中的点数最小,那么这个点为树的重心。(好拗口啊)
性质
-
树的重心可以是一个或两个。
-
以树的重心为根时,所有子树的大小都不大于整棵树大小的一半。(可以用反证法证明)
-
两树相连,重心在两树原重心相连的路径上。
证明(节选自suxxffe的博客,膜拜大佬 orz):
- 树的重心如果不唯一,则至多有两个,且这两个重心相邻
- 先假设有两个重心 u , v u,v u,v 不相邻,考虑它们之间的这条路径,则至少有三个节点(以下的 “它们之间的路径” 都是指 u , v u,v u,v 之间的路径)
- 设 u u u 的不包含它们之间的这条路径的若干子树中(就是有一个子树是以它们路径上与 u u u 相邻的那个点为根的,先排除那个子树),最小的子树大小是 s i z e u size_u sizeu,则 v v v 的包含它们路径的那个子树的大小为 s i z e u + k , k ≥ 2 size_u+k,k\ge 2 sizeu+k,k≥2。那么这个子树不能是 u u u 的大小最大的子树,否则 v v v 的这个包含它们之间的路径的子树,大小比它还大, v v v 就不是重心了
- 对 v v v 进行相同的分析,得到同样结论
- 那么 u , v u,v u,v 最大的子树就只能分别是包含它们之间路径的那个子树,假设从它们之间的路径上(不包含它们)的点,延伸出去的点的个数为 s i z e size size(这个 s i z e size size 已经把路径上的点算上了),则它们这个最大的子树的大小就分别是 v , u v,u v,u 的不包含它们之间路径的子树的大小和,加 s i z e + 1 size+1 size+1,又因为它们都是重心,最大子树都最小,则上面所述的这个 “ v , u v,u v,u 的不包含它们之间路径的子树的大小和” 应该相等,设其为 s i z e ′ size' size′
- 但是发现,若从它们之间的路径上(不包含它们本身)取一点,则这个点沿着它们之间路径的两个子树应该都小于 s i z e ′ + s i z e + 1 size'+size+1 size′+size+1,而其他子树显然都小于 s i z e ′ size' size′,那么 u , v u,v u,v 都不是重心,矛盾
- 则重心必须相邻,又因为这是一个树,所以最多只有两个点相邻,最多两个重心
- 一个点是重心,等价于,以这个点为根,它的每个子树的大小,都不会超过整个树大小的一半
- 假设重心是 u u u,它的一个子树大小超过整个树大小的一半,设这个子树的根是 v v v(与 u u u 相邻)
- 用 s i z e i size_i sizei 表示以 i i i 为根的子树大小,则 s i z e v > s i z e u 2 size_v>\frac{size_u}{2} sizev>2sizeu
- 那么, u u u 除了子树 v v v 以外的其它所有子树(把 u u u 本身也计算在内)的大小是 s i z e u − s i z e v size_u-size_v sizeu−sizev
- 所以,如果以 v v v 为重心,则它的一个子树是 s i z e u − s i z e v size_u-size_v sizeu−sizev,这个子树就是以 u u u 为根的那个。 s i z e u − s i z e v < s i z e v size_u-size_v
sizeu−sizev<sizev ,此时, v v v “往上”的那个以 u u u 为根的子树小于 u u u 的最大子树大小,而其他“往下”的子树显然也小于,所以可以说明,也说明如果以 v v v 为重心,最大子树的大小小于以 u u u 为根最大子树的大小,则矛盾。得证- 再来推若每个子树都不超过整个树的一半,那么一定是重心
- 设这个每个子树都不超过整个树一半的节点为 u u u,重心为 v v v,考虑 u , v u,v u,v 之间的路径
- v v v 总会有一个子树包含 u u u,(就是包含它们之间路径的那一个),从而包含了, u u u 的除了包含这它们之间路径的那个子树,的所有其他子树,由于 u u u 任意子树大小小于总体的一半,所以 v v v 的这个子树,也就是 u u u 的剩余所有子树,大小 ≥ s i z e u 2 \ge \frac{size_u}{2} ≥2sizeu
- 那么显然 v v v 不是重心,矛盾。这样,对于任意的 v ≠ u v\neq u v=u,都不是重心,则 u u u 是重心(当然可能存在一个相邻的点,使得它们都有一个等于整体一半的子树,那么就是有两个重心的情况)
- 则也就顺带着说明了,只有在总点数为偶数时,才可能会出现有两个重心的情况,这两个重心相邻,且都只有两个子树,大小分别为 n u m 2 , n u m 2 − 1 \frac{num}{2},\frac{num}{2}-1 2num,2num−1
- 树中所有点到某个点的距离和中,到重心的距离和是最小的。如果有两个重心,那么到它们的距离和一样。更进一步,距离和最小与是重心等价
- 一开始想大力推式子然后反证法证明,结果推了半天发现好像假了
- 实际上应该是用调整法
- 就是先假设当前选择一个点 u u u,然后看我们把选择的点调整到一个与 u u u 相邻的点,看能不能使得距离和更小
- 什么样的点能满足上面的性质?那就是以它为根的子树大小大于以 u u u 为根的大小的一半的点,这样让那些其他子树的一共小于一半的点多走 1 1 1,让这大于一半的点少走 1 1 1,总体少走了
- 直到所有相邻节点为根的子树都小于当前的 u u u 的一半,那么无论往哪个点上再进行移动,都只会使距离和更大,而这样的点,就是重心,得证
- 如果一个树增添,或删去一个叶子,则整个树的同一个重心最多移动一个节点
- 如果是增加节点,那么如果需要移动的话,则是沿着重心和新增的节点之间的路径来移动,这种情况肯定是因为新增节点使得包含它们之间路径的那个子树过大(大于整个树的一半,根据第二条性质)。而往那移动一位,就会让这个子树减少的大小大于等于一,那么就又小于等于了这个树的一半,又由于树最多有两个重心且我们讨论的是“同一个重心”的移动,所以移动一次就够了,移动更多就又不是重心了
- 如果是删除节点,删除以后导致包含被删除的节点的子树大小减小,那么其他子树可能就大于整个树大小的一半了。则重心往这个子树上移动一位,至于为什么只移动一位,和上面的分析相似
- 通过连接一条端点分别在两个树的边,来将两个树合并成一个,那么新的重心肯定是在原来这两个树的重心的路径上
- 不妨假设连接的两个点就是两个树原来的根
- 然后可以发现,仍然可以用一种不断调整的方法,假设原先两个重心分别是 u , v u,v u,v,从 u u u 开始调整,当目前仍在 u u u 所在的原先的那颗树中时,肯定是朝着根调整,因为是根那个方向被接入了另一个树导致大小变大
- 如果还没调整到原先的根,就符合了最大子树小于等于总结点数一半的条件,自然符合性质,这就说明了,如果新重心在原来 u u u 所在的那个子树上的话,一定在 u u u 到它原来的根的路径上
- 同理可以说明,如果新重心在 v v v 所在的那个子树上,一定在 u u u 到它原来那个根的路径上
- 把这两个合起来就是本条性质了
求法
可以利用树形 DP 求解,利用性质 2 2 2。
void dfs(int x,int fa)
{
siz[x]=1;//表示以x为根的子树的大小
for(int i=head[x];i;i=nxt[i])
{
if(to[i]==fa) continue;
dfs(to[i],x);
mson[x]=max(mson[x],siz[to[i]]);//表示x的最大子树
}
mson[x]=max(mson[x],n-siz[x]);
if(mson[x]<=n/2) ans=x;
return;
}
树的直径
定义
树上最长路即树的直径。
性质
-
多条树的直径,交点一定在树的重心。
-
距离一个点最远的点一定是树的直径的一个端点。
求法
两种求法,时间复杂度均为 O ( n ) O(n) O(n)。
-
树上 DP 法:
f[i]表示 i i i 的子树内以 i i i 为起点的最长路径。我们用
f[x]统计对于当前搜到的这棵子树,它的前面所有子树的最长路径,用f[to[i]]统计当前儿子的子树最长路。代码如下:
void dfs(int fa,int x) { for(int i=head[x];i;i=nxt[i]) { if(to[i]==fa) continue; dfs(x,to[i]); ans=max(ans,f[x]+f[to[i]]+1);//这里+1是因为还要统计到父亲的长度1 f[x]=max(f[x],f[to[i]]+1); } } -
双 DFS 法:
利用性质 2 2 2 进行两次 DFS,第一次以任意点 i i i 为起点,找距离最远的点 j j j;第二次以 j j j 为起点,找距离最远的点 k k k。路径 j → k j\rightarrow k j→k 即为直径。
代码如下:
void dfs(int fa,int x) { for(int i=head[x];i;i=nxt[i]) { if(to[i]==fa) continue; d[to[i]]=d[x]+1; dfs(x,to[i]); } } int main() { //... dfs(0,1);//钦定根节点1开始搜索 for(int i=1;i<=n;i++) if(d[i]>ans) ans=d[i],now=i; dfs(0,now); //... }
树的中心
树的直径的中点即是树的中心。树的中心可能有一个或两个。
要求树的中心,求树的直径再取中点即可。