基于卷积神经网络的图像分类算法讲解
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达转自: 智能计算系统
本期开小灶Heyro将带领大家进入下一趟旅程——基于卷积神经网络的图像分类算法讲解,从而帮助大家了解在卷积神经网络结构下衍生出的被用于图像分类的经典算法。

在了解图像分类算法以前,我们先来了解“何为图像分类”。
图像分类的核心是从给定的分类集合中给图像分配一个标签的任务。简言之,我们需要对一个输入图像进行分析后返回一个对应的分类标签,标签来自预先定义的可能类别集。图像分类的任务即为正确给出输入图像的类别或输出不同类别的概率。例如,我们先假设一个含有可能类别的类别集:
Categories = {cat, dog, fox}
然后,我们向分类系统提供一张狐狸犬的图片。

经过分类系统的处理,最终输出可以是单一标签dog,也可以是基于概率的多个标签,例如cat:1%, dog:94%,fox:5% 。
计算机并不能像人类一样快速通过视觉系统识别出图像信息的语义。对于计算机而言,RGB图像是由一个个像素数值构成的高维矩阵(张量)。计算机识别图像的任务即寻找一个函数关系,该函数可将高维矩阵信息映射到一个具体的类别标签中。利用计算机实现图像分类目的过程随即衍生出图像分类算法。
图像分类算法的起源——神经认知机
传统的图像识别模型一般包括:底层特征学习>特征编码>空间约束>分类器设计>模型融合等几个流程。
2012年Alex Krizhevsky提出的CNN(卷积神经网络)模型在ImageNet大规模视觉识别比赛(ILSVRC)中脱颖而出,其效果大大超越了传统的图像识别方法,该模型被称为AlexNet。
基于卷积神经网络的图像分类算法起源最早可追溯到日本学者福岛邦彦提出的neocognition(神经认知机)神经网络模型。
福岛邦彦于1978年至1984年研制了用于手写字母识别的多层自组织神经网络——认知机。福岛邦彦在认知机中引入了最大值检出等概念。简言之,当网格中某种神经元损坏时,该神经元立即可由其他神经元来代替。由此一来,认知机就具有较好的容错能力。
但是,认知机的网络较为复杂,它对输入的大小变换及平移、旋转等变化并不敏感。虽然它能够识别复杂的文字,但却需要大量的处理单元和连接,这使得其硬件实现较为困难。
而福岛邦彦在1980年提出的“神经认知机”神经网络模型却能够很好地应对以上问题。
该模型借鉴了生物的视觉神经系统。它对模式信号的识别优于认知机。无论输入信号发生变换、失真,抑或被改变大小等,神经认知机都能对输入信号进行处理。但是,该模型被提出后一直未受到较大关注,直至AlexNet在ILSVRC中大获全胜,卷积神经网络的潜力才为业界所认知。
深度学习算法
自AlexNet之后,深度学习的发展极为迅速,网络深度也在不断地快速增长,随后出现了VGG(19层)、GoogleNet(22层)、ResNet(152层),以及SENet(252层)等深度学习算法。
随着模型深度和结构设计的发展,ImageNet分类的Top-5错误率也越来越低。在ImageNet上1000种物体的分类中,ResNet的Top-5错误率仅为3.57%。在同样的数据集上,人眼的识别错误率约为5.1%,换言之,目前深度学习模型的识别能力已经超过了人眼。
在卷积神经网络的历史上,比较有里程碑意义的算法包括AlexNet、VGG、Inception (GoogleNet是Inception系列中的一员),以及ResNet。
在本期开小灶中,我们将首先为大家介绍经典图像分类算法AlexNet。
AlexNet 网络结构
作为G. Hinton代表作的AlexNet是深度学习领域最重要的成果之一。下面让我们一起从左到右依次认识这个结构。
在AlexNet网络结构(如下图所示)中,输入为一个224×224大小的RGB图像。
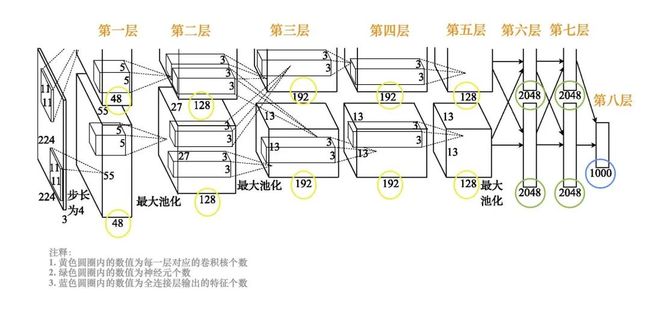
AlexNet网络结构
第一层卷积,用48个11×11×3的卷积核计算出48个55×55大小的特征图,用另外48个11×11×3的卷积核计算出另外48个55×55大小的特征图,这两个分支的卷积步长都是4,通过卷积把图像的大小从224´224减小为55×55。第一层卷积之后,进行局部响应归一化 (LRN) 以及步长为2、池化窗口为3×3的最大池化,池化输出的特征图大小为27×27。
第二层卷积,用两组各128个5×5×48的卷积核对两组输入的特征图分别进行卷积处理,输出两组各128个27×27的特征图。第二层卷积之后,做局部响应归一化和步长为2、池化窗口为3×3的最大池化,池化输出的特征图大小为13×13。
第三层卷积,将两组特征图合为一组。采用192个3×3×256的卷积核对所有输入特征图做卷积运算,再用另外192个3×3×256的卷积核对所有输入特征图做卷积运算,输出两组各192个13×13的特征图。
第四层卷积,对两组输入特征图分别用192个3×3×192的卷积核做卷积运算。
第五层卷积,对两组输入特征图分别用128个3×3×192的卷积核做卷积运算。第五层卷积之后,做步长为2、池化窗口为3×3的最大池化,池化输出的特征图大小为6×6。
第六层和第七层的全连接层都有两组神经元(每组2048个神经元)。
第八层的全连接层输出1000种特征并送到softmax中,softmax输出分类的概率。
AlexNet 技术创新点
相较于传统人工神经网络而言,AlexNet的技术创新体现在四个方面。
其一为Dropout(随机失活)。Dropout于2012年由G. Hinton等人提出。该方法通过随机舍弃部分隐层节点来缓解过拟合。目前,Dropout已经成为深度学习训练常用的技巧之一。
使用Dropout进行模型训练的过程为:a. 以一定概率随机舍弃部分隐层神经元,即将这些神经元的输出设置为0;b.一小批训练样本经过正向传播后,在反向传播更新权重时不更新其中与被舍弃神经元相连的权重;c. 恢复被删除神经元,并输入另一小批训练样本;d. 重复步骤a ~ c ,直到处理完所有训练样本。
其二为LRN(局部响应归一化)。LRN对同一层的多个输入特征图在每个位置上做局部归一化,从而提升高响应特征并抑制低响应特征。LRN的输入是卷积层输出特征图经过ReLU激活函数后的输出。但近年来业界发现LRN层作用有限,因此目前使用LRN的研究并不多。
其三是Max Pooling(最大池化)。最大池化可以避免特征被平均池化模糊,从而提高特征的鲁棒性。在AlexNet之前,很多研究用平均池化;从AlexNet开始,业界公认最大池化的效果比较好。
其四是ReLU激活函数。在AlexNet之前,常用的激活函数是sigmoid和tanh。而ReLU函数很简单,我们在之前的开小灶中为大家讲解过ReLU激活函数的特征,即输入小于0时输出0,输入大于0时输出等于输入。看似非常简单的ReLU函数却在训练时带来了非常好的效果,这是业界在AlexNet之前未曾料想到的。AlexNet在卷积层和全连接层的输出均使用ReLU激活函数,从而有效提高训练时的收敛速度。
AlexNet通过把看似平凡的技术组合起来取得了惊人的显著效果。
正是由于AlexNet采用了深层神经网络的训练思路,并辅以ReLU函数、Dropout及数据扩充等操作,使得图像识别真正走向了与深度学习结合发展的方向。
本文仅做学术分享,如有侵权,请联系删文。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~