hive 的相关关键字以及相应的补全规则
hive 查询关键字总结
select查询语句请求。它可以是一条完成的查询语句同时还可以是别的查询语句的子语句。
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_name
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT number]
select_expr:可以为表(table_name) 的多个字段,检测:如果” FROM “ 后加上表名,则需要填充该表包含的字段信息。
table_name:填充 “ FROM “ 之后,需要填充选定数据库的表名。
WHERE:在where查询中支持多个运算符和UDF查询,在自动补全时:需要提示表指点的字段,UDF和常用运算符的查询信息。(常用运算符在后面会介绍)
ALL 和 DISTINCT :All,如果直接select col 则默认会添加ALL,返回所有有关的列。DISTINCT,去除重复列信息。 ALL 和 DISTINCT都是自动补全列名信息。
eg: SELECT DISTINCT col1 FROM t1
LEFT/INNER/OUTER/RIGHT: hive表链接查询使用连接符,后面自动补全表名。
AND :查询多个条件之间的连接符,后面自动补全表相关列(若有链接查询,则补全链接多表的字段信息)
HAVING:在hive 0.7.0之后版本加入支持。后面可以跟GROUP BY的查询条件信息。可以补全列名和常用运算符信息。
GROUP BY:聚合函数,后面自动补全列名信息。
ORDER BY / SORT BY/DITRIBUTE BY /CLUSTER BY:
ORDER BY 后接表字段,依照某一字段排序,在输入字段后,自动补全DESC。
SORT BY ,HIVE 用此函数对列进行排序,然后将列放入reducer执行。后自动补全列名信息。SORT BY 只能给予部分有序的情况。
DITRIBUTE BY 后补全列名,设定哪些列信息会被聚合到REDUCER中。
CLUSTER BY 是SORT BY 和 DITRIBUTE BY 的结合,后接列名信息。注意:CLUSTER BY 只能是降序,不可自动补全DESC ASC。
/*+ MAPJOIN(tableName) */: 如果是join比较小的表,那么在MAP阶段加载到内存中处理。MAPREJOIN 默认会自动补全tableName.如果出现MAPJOIN需要自动补全/* */
UNION:用于多个SELECT语句结果的合并为单个结果集。自动补全ALL(也可以不补)或者SELECT。
eg:SELECT av.uid FROM action_video UNION ALL SELECT uid AS uid
eg:SELECT .... UNION SELECT ....
TABLESAMPLE: HIVE查询信息取样。
eg:SELECT * FROM 表名 TABLESAMPLE (50 PERCENT/rows);
eg: SELECT COUNT(1) FROM lxw1 TABLESAMPLE (BUCKET 1 OUT OF 10 ON rand());
自动补全 TABLESAMPLE取样信息,后接数字则补全PERCENT 或 ROWS ,取50%信息或者50行;还可以补全BUCKET桶取样,这个补全比较麻烦,具体看样例。
EXIST: 表明是否存在,可以接(Select .. from 表名)
虚拟列: INPUT_FILE_NAME.在map task中的输入文件名
BLOCK_OFFSET_INSIDE_FILE 当前全局文件位置
位于select 关键字后自动补全此类关键字。
Lateral view : lateral后自动补全view,横向视图关键字,
与udf函数进行联合使用 : LATERAL VIEW udtf(expression) tableAlias AS columnAlias (',' columnAlias)* view后自动补全udtf函数名(用户选中的)
接from后: from table (lateralView) 字段名 自动补全字段信息
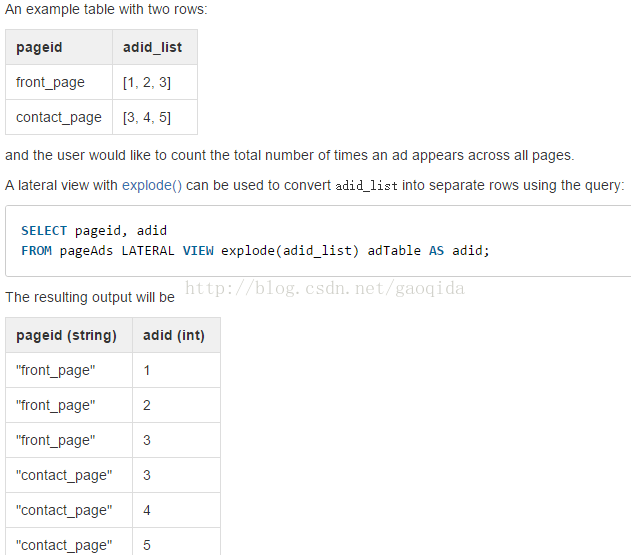
将列拆分开平铺每个对应的值。
OVER: 开窗函数,用法:
over后自动补全
over(order by salary between 2 preceding and 2 following) 加2和减2的范围。
over(partition by deptno)
OVER 前自动补全有 row_number() rank() dense_rank() first_value() last_value() lag() lead()
partition by :分区。后接字段,获取当前字段的分区信息,做order by等。不用全表查字段所有数据。
子查询补全策略:
1.FROM 后补全: from 后接(SELECT)
2.WHERE后补全:后接字段,接运算符和(SELECT) eg where id = (select id from ..)
hive 自带函数:
=, <> , < , <=, >, >=, , +, -, *, /, % ,& ,| , ^, ~, or, and 。基本符号之后补全列名
IS NULL, IS NOTNULL, LIKE, RLIKE, REGEXP 自动补全关键字
round 自动补全关键字 round(col) 后补全列名
round(?), round(?,?) 取整指定精度
http://blog.csdn.net/wisgood/article/details/17376393
时间函数:
1. UNIX 时间戳转日期:from_unixtime from_unixtime(bigint unixtime[, string format])
bigint unixtime可以为 列名或者用户输入的信息,此处需自动补全列名
from_unixtime(expr)
2.获取当前UNIX时间戳 unix_timestamp 自动补全函数
3.日期转UNIX时间戳函数 unix_timestamp(String date) 其中可以接列名
4.指定格式转UNIX时间戳函数: unix_timestamp(string date, string pattern)
unix_timestamp 格式类型:
unix_timestamp()
unix_timestamp(String date)
unix_timestamp(String date, format)
5.时间日期转日期函数 to_date(String timestamp) 返回日期时间字段中日期部分
6.日期转年 year(String date) 返回日期时间中的年
7.日期转月 month(String date)
8.日期转天 day(String date)
9.日期转小时 hour(String date)
10.日期转分钟 minute(String date)
11.日期转秒 second(String date)
12.日期转周函数 weekofyear(String date)
13.日期比较函数 datediff(String enddate, String startdate) 结束日期减开始日期 差几天
14.日期增加函数 date_add(String date, int days)
15.日期减少函数 date_sub(String date, int days)
条件函数:
1. if : if(boolean testCondition, T valueTrue, T valueFalseOrNull)
当条件testCondition为TRUE时,返回valueTrue;否则返回valueFalseOrNull
2. COALESCE 非空查找函数 COALESCE(T v1, T v2,…)
返回参数中的第一个非空值;如果所有值都为NULL,那么返回NULL
3. CASE 条件判断函数 CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END
如果a等于b,那么返回c;如果a等于d,那么返回e;否则返回f
字符串函数:
1. length : length(String A) 返回A的长度
2. reverse : reverse(String A) 字符串反转函数
3. concat : concat(String A, String B) 字符串链接函数
4. concat_ws : concat_ws(string SEP, string A, string B…) SEP分隔符 返回ASEPBSEP..
5. substr,substring: substr(string A, int start),substring(string A, int start) 返回字符串A从start位置到结尾的字符串
6. substr,substring: substr(string A, int start, int len),substring(string A, intstart, int len) 字符串截取函数 返回字符串A从start位置开始,长度为len的字符串
substr,substring: 主要有两种格式:
substr(string A, int start),substring(string A, int start)
substr(string A, int start, int len),substring(string A, intstart, int len)
7. upper, ucase : upper(String A) ucase(String A) 字符串转大写
8. lower, lcase: lower(String A) lcase(String A)字符串转小写
9. trim: trim(String A) 去空格函数
10. ltrim: ltrim(String A) 去左边空格函数
11. rtrim: rtrim(String A) 右边去空格函数
12. regexp_replace: regexp_replace(string A, string B, string C)将字符串A中的符合java正则表达式B的部分替换为C。注意,在有些情况下要使用转义字符,类似oracle中的regexp_replace函数。
13. regexp_extract: 正则表达式解析函数,
格式: regexp_extract(string subject, string pattern, int index) 将字符串subject按照pattern正则表达式的规则拆分,返回index指定的字符。
14. parse_url: URL解析函数
格式:parse_url(string urlString, string partToExtract [, stringkeyToExtract])
返回URL中指定的部分。partToExtract的有效值为:HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, and USERINFO.
15. get_json_object: json解析函数
格式:get_json_object(string json_string, string path) 解析json的字符串json_string,返回path指定的内容。如果输入的json字符串无效,那么返回NULL。
16. space : space(int n) 返回长度为n的字符串
17. repeat :