Flink 窗口函数(Window Functions)增量聚合函数
文章目录
- 增量聚合函数(incremental aggregation functions)
-
- 归约函数(ReduceFunction)
- 聚合函数(AggregateFunction)
定义了窗口分配器,我们只是知道了数据属于哪个窗口,可以将数据收集起来了;至于收集起来到底要做什么,其实还完全没有头绪。所以在窗口分配器之后,必须再接上一个定义窗口如何进行计算的操作,这就是所谓的“窗口函数”(window functions)。
经窗口分配器处理之后,数据可以分配到对应的窗口中,而数据流经过转换得到的数据类型是 WindowedStream。这个类型并不是 DataStream,所以并不能直接进行其他转换,而必须进一步调用窗口函数,对收集到的数据进行处理计算之后,才能最终再次得到 DataStream
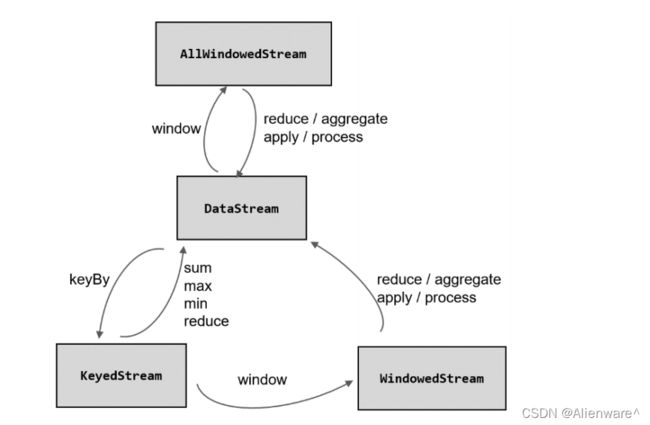
窗口函数定义了要对窗口中收集的数据做的计算操作,根据处理的方式可以分为两类:增量聚合函数和全窗口函数。
增量聚合函数(incremental aggregation functions)
为了提高实时性,我们可以再次将流处理的思路发扬光大:就像 DataStream 的简单聚合一样,每来一条数据就立即进行计算,中间只要保持一个简单的聚合状态就可以了;区别只是在于不立即输出结果,而是要等到窗口结束时间。等到窗口到了结束时间需要输出计算结果的时候,我们只需要拿出之前聚合的状态直接输出,这无疑就大大提高了程序运行的效率和实时性。
典型的增量聚合函数有两个:ReduceFunction 和 AggregateFunction。
归约函数(ReduceFunction)
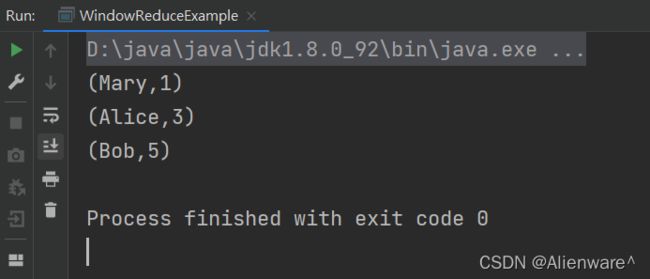
需求:统计当前5秒内访问量最大,也就是点击次数最多的,最活跃的用户是谁
代码:需求实现
结果如下:
代码中我们对每个用户的行为数据进行了开窗统计。与 word count 逻辑类似,首先将数据转换成(user, count)的二元组形式(类型为 Tuple2
对于窗口的计算,我们用 ReduceFunction 对 count 值做了增量聚合:窗口中会将当前的总 count值保存成一个归约状态,每来一条数据,就会调用内部的 reduce 方法,将新数据中的 count值叠加到状态上,并得到新的状态保存起来。等到了 5 秒窗口的结束时间,就把归约好的状态直接输出。
这里需要注意,我们经过窗口聚合转换输出的数据,数据类型依然是二元组 Tuple2
聚合函数(AggregateFunction)
ReduceFunction 可以解决大多数归约聚合的问题,但是这个接口有一个限制,就是聚合状态的类型、输出结果的类型都必须和输入数据类型一样。这就迫使我们必须在聚合前,先将数据转换(map)成预期结果类型;而在有些情况下,还需要对状态进行进一步处理才能得到输出结果,这时它们的类型可能不同,使用 ReduceFunction 就会非常麻烦。
例如,如果我们希望计算一组数据的平均值,应该怎样做聚合呢?很明显,这时我们需要计算两个状态量:数据的总和(sum),以及数据的个数(count),而最终输出结果是两者的商(sum/count)。如果用 ReduceFunction,那么我们应该先把数据转换成二元组(sum, count)的形式,然后进行归约聚合,最后再将元组的两个元素相除转换得到最后的平均值。本来应该只是一个任务,可我们却需要 map-reduce-map 三步操作,这显然不够高效。
于是自然可以想到,如果取消类型一致的限制,让输入数据、中间状态、输出结果三者类型都可以不同,不就可以一步直接搞定了吗?
Flink 的 Window API 中的 aggregate 就提供了这样的操作。直接基于WindowedStream 调 用 .aggregate() 方法,就可以定义更加灵活的窗口聚合操作。这个方法需要传入一个AggregateFunction 的实现类作为参数。AggregateFunction 在源码中的定义如下:
public interface AggregateFunction<IN, ACC, OUT> extends Function, Serializable {
ACC createAccumulator();
ACC add(IN value, ACC accumulator);
OUT getResult(ACC accumulator);
ACC merge(ACC a, ACC b);
}
AggregateFunction 可以看作是 ReduceFunction 的通用版本,这里有三种类型:输入类型(IN)、累加器类型(ACC)和输出类型(OUT)。输入类型 IN 就是输入流中元素的数据类型;累加器类型 ACC 则是我们进行聚合的中间状态类型;而输出类型当然就是最终计算结果的类型了。
接口中有四个方法:
- createAccumulator():创建一个累加器,这就是为聚合创建了一个初始状态,每个聚合任务只会调用一次。
- add():将输入的元素添加到累加器中。这就是基于聚合状态,对新来的数据进行进一步聚合的过程。方法传入两个参数:当前新到的数据 value,和当前的累加器accumulator;返回一个新的累加器值,也就是对聚合状态进行更新。每条数据到来之后都会调用这个方法。
- getResult():从累加器中提取聚合的输出结果。也就是说,我们可以定义多个状态,然后再基于这些聚合的状态计算出一个结果进行输出。比如之前我们提到的计算平均值,就可以把 sum 和 count 作为状态放入累加器,而在调用这个方法时相除得到最终结果。这个方法只在窗口要输出结果时调用。
- merge():合并两个累加器,并将合并后的状态作为一个累加器返回。这个方法只在需要合并窗口的场景下才会被调用;最常见的合并窗口(Merging Window)的场景就是会话窗口(Session Windows)。
所以可以看到,AggregateFunction 的工作原理是:首先调用createAccumulator()为任务初始化一个状态(累加器);而后每来一个数据就调用一次 add()方法,对数据进行聚合,得到的结果保存在状态中;等到了窗口需要输出时,再调用 getResult()方法得到计算结果。很明显,与 ReduceFunction 相同,AggregateFunction 也是增量式的聚合;而由于输入、中间状态、输出的类型可以不同,使得应用更加灵活方便。
举例,想要知道当前每一个用户他访问的那个网站的时间戳的平均数。
源代码如下:需求实现
缺点就是看不到用户的id