【论文阅读笔记】One Shot 3D Photography
论文主页:https://facebookresearch.github.io/one_shot_3d_photography/
代码地址:https://github.com/facebookresearch/one_shot_3d_photography
该3D照片方向,由于刚入门,所以会倾向于翻译文章。每个操作上的选择,及为什么不进行另外操作的原因都如数放上。
论文小结
本作的工作是从单张RGB图片生成一个移动视角的3D照片。
其管道大致如下:
- 由RGB图像通过单目深度估计网络估计深度图;
- 将深度图提升为Layered depth image(LDI),并在视差区域合成新的几何形状。通俗讲就是在被遮挡区域启发式地合成深度区域,为着色进行准备;
- 在LDI直接应用inpainting网络来合成视差区域(parallax regions)的颜色纹理和结构。使用Partial Convolution在正常的图片上进行训练,但是在LDI上进行了启发式地推理。(这样可以优化推理环节,后续会介绍原因)
- 最后将inpainting后的LDI(此时已经有重叠的区域)转换为mesh-base的网格表示。
在上面的后三个步骤中,都进行了相应的优化,以在移动设备和较差的网络连接上也可以有效地传输和呈现。
论文介绍
INTRODUCTION
3D照片是在静止的图像上移动视角之后显示对应的图像映射完成的。创建和显示3D照片的挑战:除了颜色之外,还需要有补充密集的深度,视角变化揭露了之前被遮挡的场景部分,所以这部分区域必须被填充。并且必须开发改变视角的可见性;
本文提出了一个系统,提供了一个单张图片生成3D照片的方法。具体来说,解决了如下的设计目标:
- Effort:应该在一次照相下完成3D的捕获,而不需要任何特殊的硬件(之前facebook的方式需要一个双目摄像头);
- Accessibility:该3D照片应该可以在任何移动设备上生成,甚至是带有普通单镜头相机的设备;
- Speed:在浏览和分享3D相片前,所有的后捕捉处理应该只需要花费几秒的时间(移动设备上);
- Compactnesss:最后的表示应该易于在互联网上共享的低端设备上传输和显示;
- Quality:渲染的新视角应该开起来是真实的。实际上,深度图深度不连续性和被遮挡区域应该妥善处理;
- Intuitive Interaction:与3D照片的交互必须是实时的,其导航功能也必须是直观的;
本文方法由四个算法阶段组成,如下图所示。
- 深度估计:深度估计网络采用了一个新的网络结构,由efficient building blocks、自动搜索、int8量化组成,以为了在移动设备上快速推理;
- 深度分层(Layer Generation):深度图的像素被提升到分层深度图像(LDI)上,并使用精心设计的启发式算法在视差区域(被遮挡的区域)合成新的几何图形;
- 颜色填充(Color Inpainting):使用一个inpainting神经网络,在LDI上新合成的几何图形上合成颜色;一个新的神经模块可以使我们能够将这个2D CNN转换为可以直接应用于LDI结构的CNN;
- 网格化(Mesh):产生一个紧凑的表示,使得其甚至可以在低端设备上进行有效率地被渲染,也可以在较差的网络连接上有效地传输;
上面所有的步骤都经过优化,以便在可用资源有限的移动设备上快速运行。

OVERVIEW
3D照片需要场景的集合表示。现在有几种流行的选择,但有些方法对我们的应用存在不利之处。
- 光场。光场可以捕捉非常逼真的场景外观,但需要有很大的存储、内存和处理要求;
- Meshes 和 Voxels。这两者是非常普遍的表示,但不是为特定的视角进行优化的。
- LDI。本文采用的LDI。LDI如正常图像一样由整数坐标的有规律格状组成。但每个位置可以有0,1或多个像素。每个LDI像素存储一个RGB颜色和一个深度值。和[Zitnick et al. 2004]一样,每个元素设有4个方向的邻居;
这种表示有显著的优点:
- 稀疏性:它只表示场景中表现的特征;
- 拓扑结构:LDI像图像一样,许多快速图像处理算法可以同样应用在LDI上;
- 层次细节:图像空间中的常规采样提供了固有的层次细节:近集合的采样比远几何更为密集;
- Meshing:LDI可以有效地转换为纹理网络,可有效传输和渲染;
前作(Hedman et al. 2017;Hedman and Kopf 2018)也使用了LDI。本文和前作不一样,本文的重要贡献如下:
- 本文采用的LDI不限于产生2层的LDI,在每个位置上都生成0,1,或多个像素;
- 本文更好地利用约束条件,在深度不连续处进行延伸,塑造成了一个无遮挡区域(也就是视差区域);
- 提出了一种新的用于填充遮挡区域LDI像素的网络,以及一种将现有的2D inpainting网络转换为直接操作的方法;
- 提出了一个有效率的算法,用于生成问题图集和简化三角形网络;
- 本文完整的算法管道运行速度更快,在移动设备上运行端到端只需要几秒钟;
Creating 3D Photos
以下几节的结构如下:节4.1 介绍深度估计;节4.2,将深度图升为LDI 和 生成遮挡几何;节4.3 为遮挡层 inpainting 颜色;节4.4 将LDI转换为最终的mesh表示。
Depth Estimation
本文提出的深度估计网络是新的网络结构,称为Tiefenrausch。Tiefenrausch 具有低推理时间,低占有资源,低内存峰值消耗和低模型大小,在这种情况下仍能达到最佳性能。
Tiefenrausch 的改善由3个技术技术实现:(1)efficient block 结构;(2)网络结构搜索技术;(3)8-bit 量化;
Efficient Block Structure.下采样采用stride大于2的depthwise卷积。上采样采用最近邻插值方法。如果一个block上输入尺度和输出尺度相同,添加一个skip-connect连接blokc input和 block output;
Block的结构如下图所示:

组成的结构如下图所示,下采样阶段有5个,即一共32倍下采样,每个阶段有3个block;整个网络结构组合efficient blocks像一个U-Net类似的结果。
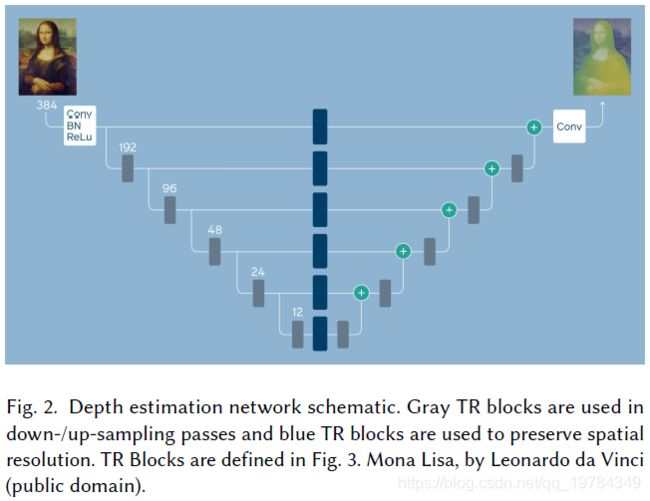
Neural Architecture Search。采用 *Chameleon methodology [Dai et al. 2019]*去找到最优的结构。在搜索空间,改变efficient block中的channel expansion factor 和每个block的输出通道。使用800个 Tesla V100搜索了3天。
Quantization。本架构只有标准的1*1 Conv,depth-wise Conv,BN、ReLU和Resize操作,因此特别适合量化和QAT。在将BN和ReLU融合进模型后,模型只有Conv和Resize结构。
Training Details。用MegaDepth数据集训练网络,使用尺度不变数据损失(scale-invariant data loss)和多尺度尺度不变梯度损失(multi-scale scale-invariant gradient loss),【这两个损失由 Li and Snavely [2018] 提出】,但没有常规的损失项。使用的 batchsize 为32,使用 β 1 = 0.5 \beta_1=0.5 β1=0.5和 β 2 = 0.999 \beta_2=0.999 β2=0.999的 Adam 优化器训练 100 100 100个 epochs。
由于MegaDepth数据集的深度图ground truth是没有天空区域的,作者发现这将导致网络不能可靠地将天空置于背景中。为克服这个问题,作者利用 PSPNet 去识别图像中的天空区域,然后用最大的深度值表示天空的区域。
为防止对数据中的特定相机特征过拟合,在训练单目深度预测模型的时候使用的数据增强,包括 color saturation, contrast, image brightness, hue, image area, field of view, and left-right flipping. 所有的图片都有方向比为 4 : 3 4:3 4:3 (或相反),先统一将短边resize到 288 α 288\alpha 288α的长度,其中 α \alpha α在 [ 1 , 1.5 ] [1, 1.5] [1,1.5]中随机采样选择去避免训练数据的过拟合。调整图片和深度图都采用的是最近邻采样(有趣的是,它比适当的反锯齿采样表现得更好)。接下来, 动调整大小后的图片和深度图选择大小为 ( 288 , 288 ) (288, 288) (288,288)的随机抠图区域。
作者还发现早期网络的另一个缺陷:它们不能泛化低质量相机的图像。因为MegaDepth数据集是曝光良好的图像,但其他相机无法提供这么好的曝光。为了使图像颜色更具有鲁棒性,还通过均匀分布因子 [ 0.6 , 1.4 ] [0.6,1.4] [0.6,1.4]的伽马调整来改变图像的亮度【结合上面的数据增强】。相似的,均匀变化对比度( 60 % − 100 % 60\%-100\% 60%−100%),即与一个中灰图像混合,以及均匀变化图像颜色的饱和度。最后,图像转换到HSV颜色空间和色调旋转均匀分布的值在 [ − 25 ° , 25 ° ] [-25°,25°] [−25°,25°]后再转回RGB颜色空间。
提升到分层深度图像
LDI可将深度图表示成多层,以展示在视差区域的细节。这些细节在输入试图中未被观察到,需要被合成。
Depth Pre-processing。3D照片最显著的几何特征是深度不连续。在这些位置上,需要扩展和产生新的几何图形。由于深度估计算法本身的正则化,深度图通常是过度平滑的。这种平滑“洗去”了多个像素上的深度不连续,这显示出了难以表示的虚假特征(如下图4b所示)。所以这个算法的第一个目标就是去杂波深度不连续,并将它们锐化成精确的步长边缘。

锐化边缘的方法:应用加权中值滤波,其滤波核大小为 5 ∗ 5 5*5 5∗5,深度值与 它们与中心点的深度差做高斯核权值进行加权,高斯核标准差为 σ d i s p a r i t y = 0.2 \sigma_{disparity}=0.2 σdisparity=0.2。需要注意的是,滤波器的权值对于保持不连续的局部很重要,例如避免圆角。因为感兴趣的是决定某个像素是前景还是背景,所以禁用了边缘附近像素的权重(如相邻像素的深度值差距大于0.05)。这里的具体实现还存在一些疑问,比如禁用了边缘像素的权重的具体概念,如果不将滤波放在边缘处,怎么得到锐化的边缘。
该算法成功地锐化了不连续点。但是它偶尔会在中深度值区域产生鼓励的特征,如上图c。所以作者执行了一个连通分量分析(阈值为 τ d i s p \tau_{disp} τdisp),并将像素面积小于20的小分量合并到前景和背景中,这取决于和哪个有更大的接触面。
Occluded Surface Hallucination。这个阶段的目标是产生场景遮挡区域部分的新几何。将深度图转为LDI,再依据深度阈值 τ d i s p \tau_{disp} τdisp来阶段邻居对。为了创建表示被遮挡区域的新几何,需要在断联处的前景后面创建新的LDI像素。在 Hedman and Kopf [2018] 有相似的算法,但那篇文章有致命的缺陷:在前景后面的像素允许向各方向扩展,这将导致 T结点(前景、背景、中景交叉)的频繁出现。中景的扩展如果没约束,扩大前景的不连续性,就会创建一个混乱的结果,如下图5b所示。前作通过减去LDI中除最近和最远外的所有层像素来减少不必要的几何形状,这就导致创建不连接的表面,如下图5c所示。
作者通过将不连续点分组为类曲线特征来解决这些问题。并推断空间约束来获得更好的扩展形状。得到的结果如下图5d所示。作者将相邻的不连续像素分组在一起,但不跨越交叉点,如下图5a的颜色编码;此时,作者移除了像素少于20的(“虚假的”)组。
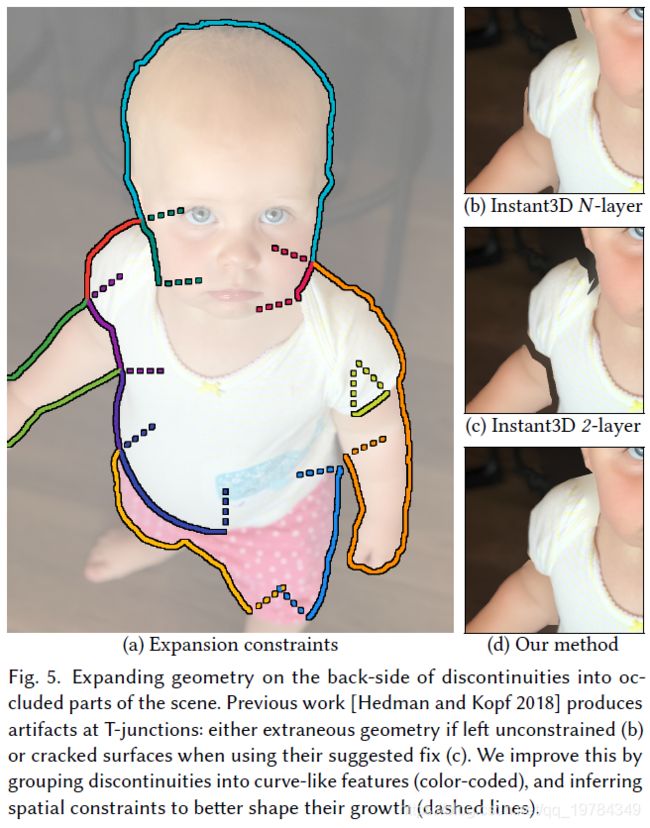
在一次迭代中,一个组作为一个单元一起增长。在新元素位置创建一个像素的“波前”(wave front)。为了避免前面的混乱问题,作者将限制扩展的范围,使其不超过末段的垂直线(如上图5a的虚线)。这一步就避免了前作中每个layer混乱四面扩展的所造成的问题。这扩展的位置,3路交叉需要特别低考虑。在这些点上有3个不同的深度值交汇在一起,但我们只对中间一层感兴趣。而背景应该在前景和中景之下自由地扩展,所以作者只保留了三个约束中的一个:在前景和中景的不连续处,其他地方不增加限制。
新形成的像素的深度被分配为其邻居像素的平均值,此像素的颜色当前还没有定义,这将在之后进行color inpainting。如果相交组的视差(深度差)小于阈值 τ d i s p \tau_{disp} τdisp则进行合并。作者运行这个扩展算法50次迭代,以获得一个多层的LDI。该LDI有足够的重叠,以用视差显示它。
LDI inpainting
一个朴素的方法来填充确实的区域,如在屏幕空间中,可以使用最先进(state-of-the-art)的网络,如 *Partial Conv [Liu et al. 2018b]*进行填补。但这种方法会不会带来理想的结果,原因如下:
- 运行时,填充每个视图都很慢;
- 每个视角都独立地合成,这将会导致不一致的视图;
- 这样的结果将会是前景和背景都连续的,但实际的填充应该只在背景连续,这将会导致强烈的模糊伪影。
一个更好的方法是在LDI结构上进行着色(inpaint)。这样进行一次着色,就能得到每个视图都协调的设计。并且LDI的每个像素都有明确意识的连通性,合成的特征将在真正连续的特征上连续。这样就不会像上面所提到的一样,填充的像素在前景和背景都连续,造成的模糊伪影。但LDI的不规则性使其不易于使用神经网络进行处理。有一个方法是填充投影视图并将结果扭曲回LDI,但这种方法需要从不同角度进行多次迭代,不方便运行。
本文的方法是具有直观上的解决方案:LDI的局部结构和规则的图像是类似的,即LDI像素在基本方向上是4连接的。通过遍历这些连接,我们可以聚集一个像素周围的局部领域(如下面会介绍的),这将允许我妈们将局部操作算子,如卷积等,映射到LDI上。反过来,这种映射让我们可以完全在2D上训练网络,然后使用预训练的权重在LDI上进行inpainting,而不需要在LDI上进行任何训练。
Mapping the PConv Network to LDI。将LDI转换为大小为 C ∗ K C*K C∗K float32 的 “value” tensor P \mathcal{P} P和一个 6 ∗ K 6*K 6∗K的 int32 “index” tensor I \mathcal{I} I。其中 C C C是 channel 数, K K K是LDI像素的个数。value tensor P \mathcal{P} P存储的是颜色值或者activation maps,而 index tensor存储的是像素位置 (x, y) 和(左,右,上,下)邻居在LDI像素中的下标。然后,作者存储了一个大小为 1 ∗ K 1* \mathcal{K} 1∗K的二元 “mask” tensor M \mathcal{M} M,这个 M \mathcal{M} M指示的是哪些像素是已知的,哪些像素是需要被inpainted的。这个inpainted网络,需要被修复的输入图,还需要一个mask来指示修复什么位置。
PartialConv [Liu et al. 2018b] 网络使用的是一个类似于 U-Net的结构。我们将这个结构映射到LDI中,通过使用接受 LDI( P , I \mathcal{P}, \mathcal{I} P,I)和mask M \mathcal{M} M的 LDIPConv,这个替换了原来 C ∗ H ∗ W C*H*W C∗H∗W的color和 1 ∗ H ∗ W 1*H*W 1∗H∗W的mask image tensor。在U-Net具有相同尺度的value 张量(比如scale 1 / s 1 / s 1/s)共用一样的index 张量 I s \mathcal{I_s} Is。网络中的大多数操作都是point-wise卷积,其输入输出都是单个像素,比如ReLU和BatchNorm,这些操作都可以简单地映射到LDI上。而网络中不平凡的操作,是2D卷积(这个网络使用 3 ∗ 3 , 5 ∗ 5 , 7 ∗ 7 3*3,5*5,7*7 3∗3,5∗5,7∗7的卷积核大小)、下采样(stride为2的卷积)和上采样。
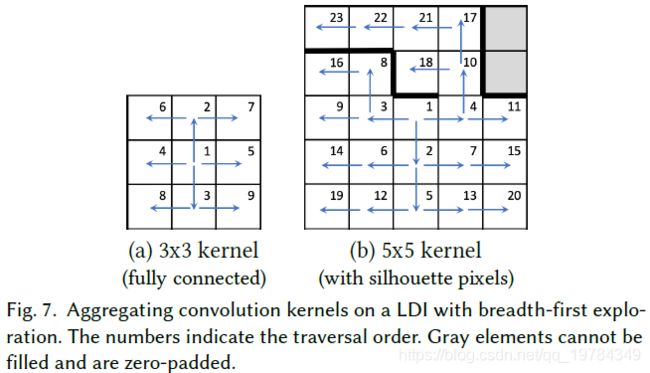
Convolution。将2D卷积核应用于LDI图中时,采用宽度优先搜索的方式,从中心元素开始,按照 上/下/左/右的顺序遍历LDI像素,贪婪地填充核元素。一旦访问了内核元素,就不载遍历到这个位置。若一个LDI像素在一个方向是不连接的,则将其视为像素在图像边缘,即零填充。由于本文使用的是 Partial Convolution,掩码也是零填充的,这就导致了基于padding的部分卷积 [Liu et al. 2018 c]。这是两篇不同的inpatining 论文。下图展示了两个在LDI展开卷积的例子。如图7a所示,对于一个 3 ∗ 3 3*3 3∗3卷积核,所有的LDI像素都是完全连接的展示。如图7b所示的 5 ∗ 5 5*5 5∗5核的例子,有的剪影像素在某些方向上没有邻居。这种情况,宽度优先搜索围绕这些避障进行搜索,除了右上角的两个元素无法以任何方式到达,则被partial-padded。这里也是有疑问的,如果一次只展开一个卷积核的大小,即CK的输入向量,展开成c(55k),这样的话,在边缘无法探索的情况下,如何终止深度优先搜索的迭代呢?如果从23号位置往上能有路径到灰色位置,那是否算填充了卷积核了呢?。
Downscaling or Strided Convolutions。图像版本的卷积网络,如果有stride为2的卷积下采样,则是通过在细尺度上每个 2 ∗ 2 2*2 2∗2块像素只保留左上角的像素作为粗尺度的像素。本文在LDI上应用卷积也使用了相同的策略:每个LDI像素只有满足 x % 2 = 0 x \% 2 =0 x%2=0和 y % 2 = 0 y\%2=0 y%2=0 的条件才被保留下来进行卷积。如果多个像素占据了同一个(x, y)的位置,则他们都被保留。如果两个保留像素间有长度为2的连接路径,则他们也将在粗尺度上连接。下图说明了这个粗化方案。
Upscaling。在图像版本的网络中,上采样是由最近邻插值完成的,一个在生成尺度上的 2 ∗ 2 2*2 2∗2像素块对应粗尺度上的一个像素。在LDI上,作者也对此作了模拟,整个LDI像素组都缩成粗像素取其值(the whole group of LDI pixels that collapsed into a coarse pixel all take its value)。这应该就是为什么使用最近邻上下采样的原因吧。作者使用Caffe2实现了自定义的卷积核缩放算子,从而实现了原始的PConv网络。
Mobile Optimized Inpainting Network。该网络在LDI上可以高质量地绘制视差区域。但与之前深度估计方面的工作类似,它对于移动设备来说过于庞大和资源密集型了。因此提出了新的网络架构 Farbrausch。与正常的屏幕空间2D PartialConv 网络一样,从5个阶段的下采样开始。然后使用作者自定义的算子转换成了LDI的表现形式。LDI的表现形式,不知道是否就只是说这个网络的输入输出变成了LDI,然后算子是为LDI实现的,即像素的扩展和遍历都是在自定义算子中完成。同时,使用 Chameleon搜索算法找到每个阶段的编码器的最佳输出channel 参数(对应的decoder阶段也一样)。实际上,FLOPS和inpating 损失是一对trade-off的目标,在验证集上挑选模型。这个超参数的搜索,使用了400块V100 GPUs,花了3天的时间进行。在这段时间里,作者训练了150个网络来构建基因搜索的准确率预测器。
转换为最终的表示
这阶段,准备将inpainted好的多层LDI转化为纹理网络(textured mesh)。所以有两部分:创建纹理(creating the texture)和网络创建(mesh generation);
LDI包含多个自重叠的部分,具有复杂的拓扑结构。因此,LDI不能映射到单个连续的纹理图像。因此,我们将其划分为扁平图表(flat charts),这样就可以打包到图集图像中进行纹理处理(can be packed into an atlas image for texturing)。
Chart generation。本文使用一种简单的“种子-生长”算法来创建图标:以扫描线的顺序遍历LDI,每当遇到不属于任何图标的像素时,就会种子生成一个新的图表(a new chart is seeded)。然后依据LDI像素的连接,使用宽度优先的洪水填充算法(breadth-first flood fill algorithm)增长图表。但填充的时候需要考虑几个约束条件:
- 图表(charts)不能在深度上折叠,因为那样不能被表示出来(charts cannot fold over in depth, since that would not be representable)。
- 为了提高包装效率,作者对图表的最大尺寸做了限制(避免大的非凸形状);
- 当在深度边缘的正面遇到像素时(在某些方向上没有相邻的像素),我们在边缘上标记一系列不可用的相邻像素,以避免包括来自不同表面的像素的过滤操作。这些被标记的像素最终会出现在一个单独的图表中。
这个算法是快速的,产生的图表是合理有效的打包(低计数,不复杂的边界,low count, non-complex boundaries)。下图展示了一些经典的例子;

Texture filter padding。When using mipmapping, filtering kernels span multiple consecutive pixels in a texture. We therefore add a few pixel thick pad around each chart. We either copy redundant pixels from neighboring charts, or use isotropic diffusion at stepedges where pixels do not have neighbors across the chart boundary (dark/light red in Figure 6, respectively).
贴图分级细化,滤波该跨越纹理中的多个像素。因此在每个图标上添加了几个像素厚的pad。当进行pad的时候,要么就从相邻图表中复制冗余像素,要么在跨图表边界没有相邻像素的陡坡处使用各向同性扩散(分别为上图6中的暗红色和亮红色)。
Macroblock padding。Another possible source of color bleeding is lossy image compression. We encode textures with JPEG for transmission, which operates on non-overlapping 16 × 16 pixel macroblocks. To avoid bleeding we smoothly inpaint any block that is overlapped by the chart with yet another round of isotropic diffusion (green pixels in Figure 6a). Interestingly, this also reduces the encoded texture size by almost 40% compared to solid color fill, because the step edges are pushed from the chart boundaries to macroblock boundaries where they become “invisible” for the JPEG encoder.
彩色损失(color bleeding)的另一个可能来源是有损的图像压缩。因此,作者采用JPEG编码纹理以进行传输。它在不重叠的16*16像素宏块(macroblock)上操作。为避免损失(bleed),我们使用另一轮的各向同性扩散(图6a的绿色像素)平滑地绘制与图表重叠的任何块。有趣的是,与纯色填充相比,这也减少了将近 40 40% 40的编码纹理大小。因此,step edges被从图表边界推到宏块边界,在那里它们对JPEG编码器来说是“不可见的”。这两块可能是因为计算机图形没入门的原因,所以理解还不够,之后再回头看。
Packing。最后,将被padded的图表进行打包,打包进一个单独的图集中,这样整个mesh可以作为一个人单独的单元进行渲染。我们使用一个简单的tree-base bin packing algorithmhttp://blackpawn.com/texts/lightmaps/。图6c展示了图1中3D照片的完成图集。
Meshing。用之前的图集创建一个三角形网格。用顶点替换像素,用三角形连接,可以简单地从LDI构建一个带有微三角形的密集网络。但对于在网格上渲染、存储和传输来说是非常大的。所以作者在此步也进行了优化。
先将每个图表的轮廓都转换为详细的2D多边形。在像素之间的角上放置顶点(实际上就是那些不是4连通的顶点),如图10a。接下来使用 Douglas-Peucker algorithm [1973] 算法简化多边形,如下图10b所示。如图6a浅红色的边,大部分图表与其他图表共享边界的某些部分。因此,需要小心地用相同的方式简化他们(共享边界,即在不同的地方这部分要保持一致),以确保在组装图表时能够将它们组合在一起。
然后准备三角化图表内部。分布内部顶点能够复制深度变化和实现更有规则的三角形形状是有用的。刚开始,作者准备采用自适应的采样算法,但发现它们的复杂程度是不必要的,因为所有主要的深度不连续已经在图表边界捕获了,其余部分在深度上是相对平滑的。因此,作者简单地生成了垂直的条带。这些条带具有均匀间隔内部顶点的“螺柱”折线,如图10c。考虑到这些条带必须在图表边界顶点开始和结束的约束,螺柱尽可能均匀地放置。然后使用一种快速的平面扫面算法(fast plane-sweep algorithm [de Berg et al. 2008])对复合多边形进行三角剖分,如图10d。

Viewing 3D Photos
完整体验的3D照片需要移动虚拟视角,以重建人们在现实世界中看到的视差。同时,为移动设备和桌面浏览器设计了桌面,也为头戴式VR显示器设计了界面,其中利用到了立体视觉(在这里,这部分桌面暂时不置理会)。
Results and Evalution
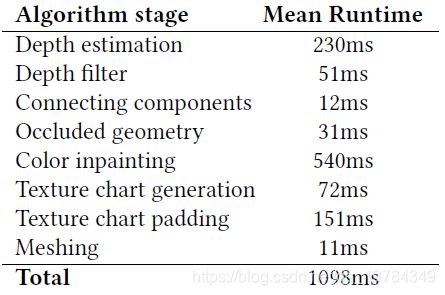
性能
作者在iPhone 11 Pro上随机选择了6张 1152 ∗ 1536 1152*1536 1152∗1536的图片。深度图在 288 ∗ 384 288*384 288∗384的输入分辨率下运行时间为230ms。下表中所有阶段的时间都取的平均值。
深度估计
深度估计网络与当前放的对比结果如下表所示。
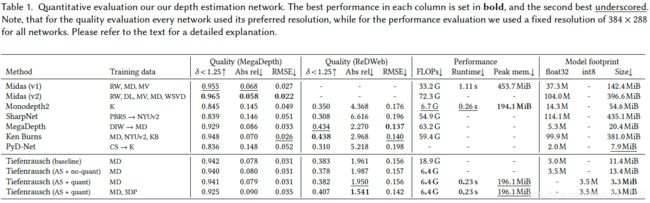
其中大多数的方法没有训练代码,所以也列出了训练所用的数据集。数据集对应的列表如下:
In the training data column RW refers to ReDWeb [Xian et al. 2018], MD to MegaDepth [Li and Snavely 2018], MV to Stereo Movies [Ranftl et al. 2019], DL to DIML Indoor [Kim et al. 2018], K to KITTI [Menze and Geiger 2015], KB to Ken Burns [Niklaus et al. 2019], CS to Cityscapes [Cordts et al. 2016], WSVD [Wang et al. 2019], PBRS [Zhang et al. 2017], and NYUv2 [Silberman et al. 2012]. 3DP refers to a proprietary dataset of 2.0M iPhone dual-camera images of a wide variety of scenes. A → B indicates that a model was pretrained on A and fine-tuned on B.
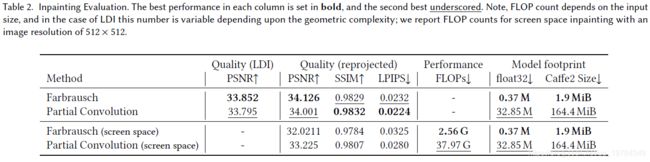
Inpainting
在ReDWeb数据集上验证Inpainting的质量,因为它拥有密集的深度监督。为了评估inpating,有以下的管道:
- 对于数据集的每张图片,都转成单层LDI,及使用微多边形。也就是说,捕捉所有的细节,但不产生任何新细节的hallucinate。如图12a所示。For each image in the dataset we lift input image to single layer LDI (i.e., no extending) and use micro-polygons.
- 从规范化的视角来渲染图像,并且使用所有layer已知颜色的LDI,而不仅仅是第一层(图12b-c显示了前两层)
- 作者认为,出了第一层,其他所有层都是未知的,需要Inpaint他们(图12d)这怎么做监督呢?还是说,正常训练,然后这部分生成的是mask?只是展示的时候以LDI展示,在评估的时候是不进行如此的?
- 将inpaint的LDI重新以原始视角映射。这是有效的。因为在这个视角,所有的inpaint像素(来自LDI层)都是可见的。且因为是一个正常渲染的图像,所以我们可以使用任何图像空间变量。

LDI的质量评估如下表所示,报道的是LDI的质量损失,也就是上图12c和上图12d之间的比较。表2的“映射质量”是PSNR和SSIM的指标。由于PSNR和SSIM是重构误差度量,所以加了LPIPS度量,以便更好地评估inpainted图像和ground truth的感知相似性。