PELT &load balance
任务优先级、权重
优先级
struct task_struct {
int prio;
int static_prio;
int normal_prio;
unsigned int rt_priority;
}
内核使用 0~139 表示进程优先级,0~99 rt 优先级,100~139给普通进程使用;另外用户空间优先级 nice -20~19 映射到普通进程优先级 100~139。
static_prio 在任务创建时分配,CFS调度的进程中才有意义
normal_prio是根据调度器类型计算出来的
对于实时进程:normal_prio = 99 - rt_priority
对于非实时进程: normal_prio = static_prio
rt_priority 实时优先级,在被实时调度器调度的进程中才会有意义
prio 调度优先级,进程的动态优先级,是调度器使用的优先级
SCHED_NORMAL( 老版本也称SCHED_OTHER): CFS调度:分时调度,不支持优先级,根据负载权重调度
SCHED_FIFO: 实时调度策略 先入先调度 优先级 1~99
SCHED_RR: 实时调度策略 时间片轮转 优先级 1~99


权重
const int sched_prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
sched_prio_to_weight 里面将 用户空间nice 优先级 -20~19 对应cpu 执行时间权重映射,nice =0 对应 1024 ,nice 每差一个优先级,cpu 时间就相应相差 10% ;nice 对应权重约以1.25 比例增加。
A进程nice 0(权重1024),B进程nice0(权重1024),则A 、B的CPU时间,1024/(1024+1024) = 50%
A进程nice 0(权重1024),B进程nice1(权重820),则B的CPU时间,820/(1024+820) = 45%,A 的cpu 时间 55%
这里变化一个nice 优先级,CPU时间 就相差 10%

delta_exec 实际运行的cpu 时间,以nice = 0 对应权重为基准,vruntime 跟权重成反比,CFS 根据vruntime 最小优先进行调度。
负载、PELT
负载跟踪算法:PELT 、WALT
3.8版本之前的内核CFS调度器在计算CPU load的时候采用的是跟踪每个运行队列上的负载(per-rq load tracking)。这种粗略的负载跟踪算法显然无法为调度算法提供足够的支撑。为了完美的满足上面的所有需求,Linux调度器在3.8版中引入了PELT(Per-entity load tracking)实体负载跟踪算法。
per-entity load tracking 从两个方面反映cpu 情况:
- 任务的利用率(task utility)
- 任务的负载(task load)
任务的utility主要是为任务寻找合适算力的CPU,一个任务本身逻辑复杂,需要有很长的执行时间,那么随着任务的运行,内核发现其utility越来越大,那么可以根据utility选择提升其所在CPU的频率,输出更大的算力,或者将其迁移到算力更强的大核CPU上执行。Task load主要用于负载均衡算法,即让系统中的每一个CPU承担和它的算力匹配的负载。
3.8版本之前的内核CFS调度器在负载跟踪算法上比较粗糙,采用的是跟踪每个运行队列上的负载(per-rq load tracking)。它并没有跟踪每一个任务的负载和利用率,只是关注整体CPU的负载。对于per-rq的负载跟踪方法,调度器可以了解到每个运行队列对整个系统负载的贡献。这样的统计信息可以帮助调度器平衡runqueue上的负载,但从整个系统的角度看,我们并不知道当前CPU上的负载来自哪些任务,每个任务施加多少负载,当前CPU的算力是否支撑runqueue上的所有任务,是否需要提频或者迁核来解决当前CPU上负载。因此,为了更好的进行负载均衡和CPU算力调整,调度器需要PELT算法来指引方向。
PELT算法把负载跟踪算法从per rq(runqueue)推进到per-entity的层次,从而让调度器有了做更精细控制。这里per-entity中的“entity”指的是调度实体(scheduling entity),即一个进程或者control group中的一组进程。为了做到Per-entity的负载跟踪,时间被分成了1024us的序列,在每一个1024us的周期中,一个entity对系统负载的贡献可以根据该实体处于runnable状态(正在CPU上运行或者等待cpu调度运行)的时间进行计算。如果在该周期内,runnable的时间是t,那么该任务的瞬时负载应该和(t/1024)有正比的关系。类似的概念,任务的瞬时利用率应该通过1024us的周期窗口内的执行时间(不包括runqueue上的等待时间)比率来计算。
不同优先级的任务对系统施加的负载也不同,在cfs调度算法中,高优先级的任务在一个调度周期中会有更多的执行时间,因此计算任务负载也需要考虑任务优先级,这里引入一个**负载权重(load weight)**的概念。在PELT算法中,瞬时负载Li等于
Li = load weight x (t/1024)
利用率和负载不一样,它和任务优先级无关,不过为了能够和CPU算力进行运算,任务的瞬时利用率Ui使用下面的公式计算,在手机环境中,大核最高频上的算力定义为最高算力,即1024
算力:
/sys/devices/system/cpu/cpuXX/cpu_capacity
这里看到的算力是最高频率对应算力,而当前算力需要根据当前实际频率和最高频率比来确定。
通常超大核 /sys/devices/system/cpu/cpu7/cpu_capacity 对应1024 为基准
Ui = Max CPU capacity x (t/1024)
PELT
一个调度实体的平均负载可以表示为:
L = L0 + L1*y + L2*y2 + L3*y3 + ...
Li表示在周期pi中的瞬时负载,对于过去的负载需要乘一个衰减因子y,在目前的内核代码中,y是确定值:y ^32约等于0.5。这样选定的y值,一个调度实体的负荷贡献经过32个窗口(1024us)后,对当前时间的的负载贡献值会衰减一半。
第一个周期后 L0
第二个周期后 sum1 = L1 + y * L0
第三个周期后 sum2 = L2 + y * (L1 + y * L0) = L2 + y*sum1
第四个周期后 sum3 = L3 + y(L2 + y * (L1 + y * L0) ) = L3 + y * sum2
PELT算法中定义了一个struct load_weight的数据结构来表示调度实体的负载权重
struct load_weight {
unsigned long weight;
u32 inv_weight;
};
这个数据结构中的weight成员就是负载权重值,inv_weight没有实际的意义,主要是为了快速运算的。
struct load_weight可以嵌入到se或者cfs rq中,分别表示se/cfs rq的权重负载。Cfs rq的load weight等于挂入队列所有se的load weight之和。
我们可以快速计算出一个se的时间片信息:
Sched slice=sched period x se的权重/cfs rq的权重
CFS调度算法的核心就是在target latency(sched period)时间内,保证CPU资源是按照se的权重来分配的,映射到virtual runtime的世界中,cfs rq上的所有se是完全公平的。
kernel-4.19/kernel/sched/sched-pelt.h
4 #ifdef CONFIG_PELT_UTIL_HALFLIFE_32
5 static const u32 runnable_avg_yN_inv[] = {
6 0xffffffff,0xfa83b2da,0xf5257d14,0xefe4b99a,
7 0xeac0c6e6,0xe5b906e6,0xe0ccdeeb,0xdbfbb796,
8 0xd744fcc9,0xd2a81d91,0xce248c14,0xc9b9bd85,
9 0xc5672a10,0xc12c4cc9,0xbd08a39e,0xb8fbaf46,
10 0xb504f333,0xb123f581,0xad583ee9,0xa9a15ab4,
11 0xa5fed6a9,0xa2704302,0x9ef5325f,0x9b8d39b9,
12 0x9837f050,0x94f4efa8,0x91c3d373,0x8ea4398a,
13 0x8b95c1e3,0x88980e80,0x85aac367,0x82cd8698,
14 };
15
16 static const u32 runnable_avg_yN_sum[] = {
17 0, 1002, 1982, 2941, 3880, 4798, 5697, 6576, 7437, 8279, 9103,
18 9909,10698,11470,12226,12966,13690,14398,15091,15769,16433,17082,
19 17718,18340,18949,19545,20128,20698,21256,21802,22336,22859,23371,
20 };
runnable_avg_yN_inv[i]=(2^32-1) * y^i
y^32=1/2
i=0~31
y~=0.9785
Static const u32 runnable_avg_yN_org[] = {
0.999, 0.978, 0.957, 0.937, 0.917, 0.897,
……
0.522, 0.510
}
runnable_avg_yN_org[i]=runnable_avg_yN_inv[i]>>32
static const u32 runnable_avg_yN_sum[] = {
0, 1002, 1982, 2941, 3880, 4798, 5697, 6576, 7437, 8279, 9103, 9909,10698,11470,12226,12966,13690,14398,15091,15769,16433,17082, 17718,18340,18949,19545,20128,20698,21256,21802,22336,22859,23371,
};
runnable_avg_yN_sum[n]=1024*(y^1+y^2+y^3+……+y^n)
1024:1ms
period=1024us
y~=0.9785; y^32=1/2
static u64 decay_load(u64 val, u64 n)
val表示n个周期前的负载值,n表示第n个周期
t0时刻负载为val,t1时刻,红色历史时间区域衰减负载值是:val*y^n=val* runnable_avg_yN_inv[n]>>32
参考
CFS调度器(原理->源码->总结)_小官学长的博客-CSDN博客
调度器 schedule pelt 介绍【转】 - Sky&Zhang - 博客园 (cnblogs.com)
struct sched_avg {
u64 last_update_time;
u64 load_sum;
u64 runnable_sum;
u32 util_sum;
u32 period_contrib;
unsigned long load_avg;
unsigned long runnable_avg;
unsigned long util_avg;
struct util_est util_est;
} ____cacheline_aligned;

这里很巧妙的使用
1024*(y^p+y^p+1 + y^inf) = 1024 * y^p *(y^0+y^1+...+y^inf) = y^p * LOAD_AVG_MAX
在了解了以上信息后,可以开始研究上一节中计算负载贡献的公式的源码实现。
p-1
u' = (u + d1) y^p + 1024 \Sum y^n + d3 y^0
n=1
= u y^p + (Step 1)
p-1
d1 y^p + 1024 \Sum y^n + d3 y^0 (Step 2)
n=1
以上公式在代码中由两部实现,accumulate_sum()函数计算step1部分,然后调用__accumulate_pelt_segments()函数计算step2部分。
static __always_inline u32
accumulate_sum(u64 delta, int cpu, struct sched_avg *sa,
unsigned long load, unsigned long runnable, int running)
{
unsigned long scale_freq, scale_cpu;
u32 contrib = (u32)delta; /* p == 0 -> delta < 1024 */
u64 periods;
scale_freq = arch_scale_freq_capacity(cpu);
scale_cpu = arch_scale_cpu_capacity(NULL, cpu);
delta += sa->period_contrib; /* 1 */
periods = delta / 1024; /* A period is 1024us (~1ms) */ /* 2 */
/*
* Step 1: decay old *_sum if we crossed period boundaries.
*/
if (periods) {
sa->load_sum = decay_load(sa->load_sum, periods); /* 3 */
sa->runnable_load_sum = decay_load(sa->runnable_load_sum, periods);
sa->util_sum = decay_load((u64)(sa->util_sum), periods);
/*
* Step 2
*/
delta %= 1024;
contrib = __accumulate_pelt_segments(periods, /* 4 */
1024 - sa->period_contrib, delta);
}
sa->period_contrib = delta; /* 5 */
contrib = cap_scale(contrib, scale_freq);
if (load)
sa->load_sum += load * contrib;
if (runnable)
sa->runnable_load_sum += runnable * contrib;
if (running)
sa->util_sum += contrib * scale_cpu;
return periods;
}
period_contrib记录的是上次更新负载不足1024us周期的时间。delta是经过的时间,为了计算经过的周期个数需要加上period_contrib,然后整除1024。
计算周期个数。
调用decay_load()函数计算公式中的step1部分。
__accumulate_pelt_segments()负责计算公式step2部分。
更新period_contrib为本次不足1024us部分。
下面分析__accumulate_pelt_segments()函数。
static u32 __accumulate_pelt_segments(u64 periods, u32 d1, u32 d3)
{
u32 c1, c2, c3 = d3; /* y^0 == 1 */
/*
* c1 = d1 y^p
*/
c1 = decay_load((u64)d1, periods);
/*
* p-1
* c2 = 1024 \Sum y^n
* n=1
*
* inf inf
* = 1024 ( \Sum y^n - \Sum y^n - y^0 )
* n=0 n=p
*/
c2 = LOAD_AVG_MAX - decay_load(LOAD_AVG_MAX, periods) - 1024;
return c1 + c2 + c3;
}
__accumulate_pelt_segments()函数主要的关注点应该是这个c2是如何计算的。本来是一个多项式求和,非常巧妙的变成了一个很简单的计算方法。这个转换过程如下。
p-1
c2 = 1024 \Sum y^n
n=1
In terms of our maximum value:
inf inf p-1
max = 1024 \Sum y^n = 1024 ( \Sum y^n + \Sum y^n + y^0 )
n=0 n=p n=1
Further note that:
inf inf inf
( \Sum y^n ) y^p = \Sum y^(n+p) = \Sum y^n
n=0 n=0 n=p
Combined that gives us:
p-1
c2 = 1024 \Sum y^n
n=1
inf inf
= 1024 ( \Sum y^n - \Sum y^n - y^0 )
n=0 n=p
= max - (max y^p) - 1024
LOAD_AVG_MAX其实就是1024(1 + y + y2 + ... + yn)的最大值,计算方法很简单,等比数列求和公式一套,然后n趋向于正无穷即可。最终LOAD_AVG_MAX的值是47742。当然我们使用数学方法计算的数值可能和这个值有点误差,并不是完全相等。那是因为47742这个值是通过代码计算得到的,计算机计算的过程中涉及浮点数运算及取整操作,有误差也是正常的。LOAD_AVG_MAX的计算代码如下。
void calc_converged_max(void)
{
int n = -1;
long max = 1024;
long last = 0, y_inv = ((1UL << 32) - 1) * y;
for (; ; n++) {
if (n > -1)
max = ((max * y_inv) >> 32) + 1024;
/*
* This is the same as:
* max = max*y + 1024;
*/
if (last == max)
break;
last = max;
}
printf("#define LOAD_AVG_MAX %ld\n", max);
}
Task 放置
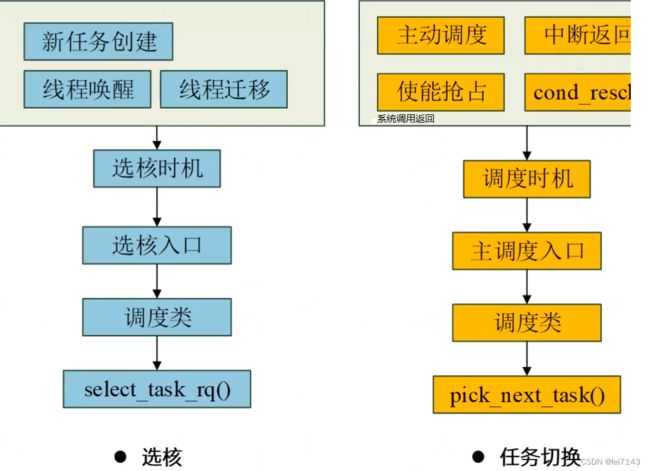
不影响负载摆核:
http://www.wowotech.net/process_management/task_placement.html
linux内核为每个CPU都配置一个cpu runqueue,用以维护当前CPU需要运行的所有线程,调度器会按一定的规则从runqueue中获取某个线程来执行。如果一个线程正挂在某个CPU的runqueue上,此时它处于就绪状态,尚未得到cpu资源,调度器会适时地通过负载均衡(load balance)来调整任务的分布;当它从runqueue中取出并开始执行时,便处于运行状态,若该状态下的任务负载不是当前CPU所能承受的,那么调度器会将其标记为misfit task,周期性地触发主动迁移(active upmigration),将misfit task布置到更高算力的CPU。
上面提到的场景,都是线程已经被分配到某个具体的CPU并且具备有效的负载。如果一个任务线程还未被放置到任何一个CPU上,即处于阻塞状态,又或者它是刚创建、刚开始执行的,此时调度器又是何如做均衡分布的呢?这便是今天我们要花点篇幅来介绍的任务放置场景。
内核中,task placement场景发生在以下三种情况:
(1)进程通过fork创建子进程;
(2)进程通过sched_exec开始执行;
(3)阻塞的进程被唤醒。

load balance
CPU拓扑结构中的Die等级是指什么?
Die 指管芯,在集成电路中制造集成块所用的芯片。说白了,就是把我们买到的CPU片上的保护罩打开,里面放的那块长方形的黑色贴片就是Die,管芯。
那在CPU的拓扑结构中是什么等级呢?应该是在socket与core之间。至于原因,应该从CPU的制作流程看出。
- 首先是一堆沙子经过加热形成一根硅柱。
- 硅柱按横截面切成很多片薄片,这个薄片叫晶圆。
- 晶圆上面经过光刻机的蚀刻后,就会被切成很多片长方形的块,这个块叫晶片。
- 那么这个晶片就是这里讨论的管芯,也就是Die。
- 这个Die与一些外围电路、管脚和保护壳封装在一起就是安装到主板上的CPU芯片。
- CPU芯片是安装到主板上的插槽上才能使用。那这个插槽或者安装到插槽上的CPU芯片就是Socket。
- 而平常经常听到的“双核/四核”CPU中的“核”就是Core,在物理上是指一个物理上的运算核心。
- 而在Core之下,还有HT(Hyper-Threading超线程)这个概念。对应“双核四线程”中的“线程”这个概念。可以看作是在逻辑上的一个核心。
所以,一种简略的CPU拓扑结构如下:Socket --> Die -->Core–>HT(SMT)。
通俗理解,可以认为,在一个Socket可以有多个Die,而在每个Die中可以集成多个Core,而每个Core有可以含有多个HT。
单独的⼀个物理核⼼的标志往往是其独占的私有缓存(Cache)。通常在两级缓存的情况下,每个物理核⼼独享L1 Cache,L2 Cache则为⼏个物理核⼼共享;在三级缓存的情况下,L1与L2为私有,L3为共享。当然前⾯说的是通常情况,不能武断地认为⼆级缓存与三级缓存的情况都是统⼀的。继续往上层⾛就是处理器层级,多个物理核⼼可以共享最后⼀级缓存(LLC),这多个物理核⼼就被称为是⼀个Cluster或者Socket。芯⽚⼚商会把多个物理核⼼(Core)封装到⼀个⽚(Chip)上,主板上会留有插槽,⼀个插槽可以插⼀个Chip。
Cpu 拓扑结构: 调度器14—CPU拓扑结构和调度域建立_51CTO博客_cpu调度方法
CFS任务的负载均衡(框架篇)
https://blog.csdn.net/feelabclihu/article/details/105502168
CFS任务的负载均衡(task placement、active upmigration)
https://blog.csdn.net/feelabclihu/article/details/106435849
负载均衡情景分析(load balance tick balance、nohz idle balance和new idle balance)
https://blog.csdn.net/feelabclihu/article/details/112057633
Load_balance函数情景分析(tick balancing、nohz idle balancing、new idle balancing)
https://blog.csdn.net/feelabclihu/article/details/121173563
CFS任务放置代码详解
https://blog.csdn.net/feelabclihu/article/details/122007603
PELT 算法浅析
https://blog.csdn.net/feelabclihu/article/details/108414156
CFS任务的负载均衡(概述)
分析各种负载均衡的触发和具体的均衡逻辑过程
CFS任务的负载均衡(load balance)
Cpu 相关子系统

Schedtune/Uclamp
Linux Kernel Utilization Clamping简介 - 墨天轮
core ctl
随心所动,厂商的CPU核管理策略介绍_内核工匠的博客-CSDN博客
CpuFreq
参考
性能功耗专题 | 深入浅出CPUFreq - 腾讯云开发者社区-腾讯云
Cpuidle
linux cpu管理(五) cpu idle - 知乎
Linux中的cpuidle子系统 - 知乎