论文阅读:RFAConv: Innovating Spatial Attention andStandard Convolutional Operatio|RFAConv:创新空间注意力和标准卷积操作
-
-
摘要
一、简介
3研究方法
3.1标准卷积操作回顾
3.2空间注意力回顾
3.3 空间注意与标准卷积运算
3.4创新空间注意力和标准卷积操作
入数据
-
- 总结
摘要
空间注意力被广泛用于提高卷积神经网络的性能。但是,它也有一定的局
限性。本文提出了空间注意有效性的新视角,即空间注意机制从本质上解决了
卷积核参数共享问题。然而,空间注意生成的注意图所包含的信息对于大尺寸
卷积核是不够的。因此,我们提出了一种新的注意机制——接受场注意
(RFA)。现有的空间注意,如卷积块注意模块(CBAM)和协调注意模块(CA)只关
注空间特征,没有完全解决卷积核参数共享的问题。相比之下,RFA不仅关注
接收域空间特征,而且为大规模卷积核提供了有效的注意权值。RFA开发的接
受域注意力卷积运算(RFA- Conv)是一种替代标准卷积运算的新方法。它提供
了几乎可以忽略不计的计算成本和参数增量,同时显著提高了网络性能。我们
在ImageNet-1k、COCO和VOC数据集上进行了一系列的实验,以证明我们的
方法的优越性。特别重要的是,我们认为现在是时候将注意力从空间特征转移
到当前的空间注意机制的接受场空间特征。这样可以进一步提高网络性能,达
到更好的效果。相关任务的代码和预先训练的模型可以在 https://github.com/
Liuchen1997/RFAConv上找到。
提示:以下是本篇文章正文内容,下面案例可供参考
一、简介
对于分类、目标检测和语义分割任务,一方面,目标在图像中不同位置的形状、大小、颜色和分布是可变的。而在卷积运算过程中,卷积核在各个接收域使用相同的参数来提取信息,不考虑来自不同位置的差异信息。因此,网络的性能是有限的,正如最近的作品所证明的[11,12,13]。另一方面,卷积过程没有考虑到每个特征的重要性,进一步降低了提取特征的效率,最终限制了模型的性能。此外,注意机制[14,15,16]使模型能够集中于显著特征上,增强了特征提取的效益和卷
积神经网络捕获详细特征信息的能力。
通过考察卷积操作的内在局限性和注意机制的性质,我们认为当前的空间注意机制虽然从根本上解决了卷积操作中的参数共享问题,但仍局限于空间特征的识别。目前的空间注意机制并不能完全解决大卷积核的参数共享问题。此外,他们不能强调每个特征在接受域的重要性,如现有的卷积块注意模块 (Convolutional BlockAttention Module, CBAM)[17]和协调注意模块(Coordinate Attention, CA)[18]。因此,我们提出一种新颖的接受域注意(RFA),它全面地解决了卷积核的参数共享问题,并考虑了接受域中每个特征的重要性。RAF设计的卷积运算(RFAConv)是一种开创性的方法,可以取代目前神经网络中的标准卷积运算。RFAConv只需要一些额外的参数和计算开销,就可以提高网络性能。在 ImagNet- 1k[19]、COCO[20]、VOC[21]上进行的大量实验证明了 RFAConv 的有效性。 RFAConv 作为一种基于注意的卷积运算,其性能优于CAMConv、CBAM- Conv、CAConv(分别由CAM[17]、CBAM、CA构造)以及标准的卷积运算。此外,为了解决现有方法提取接受域特征速度慢的问题,我们提出了一种轻量级操作。在构建 RFAConv的过程中,我们还设计了CBAM和CA的升级版本,并进行了相关实验。我们认为,空间注意机制应关注接受场空间特征,以进一步推进卷积神经网络的发展,增强其优势。
3研究方法
3.1标准卷积操作回顾
标准的卷积操作是构造卷积神经网络的基本构件。它利用具有共享参数的滑动窗口提取特征信息,克服了全连通层构造神经网络固有的参数多、计算开销大的问题。设 X R∈C×H×W
表示输入特征图,其中C、H、W分别表示特征图的通道数、高度、宽度。为了清楚地演示卷积核的特征提取过程,我们使用 C = 1 的例子。从每个接受域滑块中提取特征信息的卷积运算可以表示为: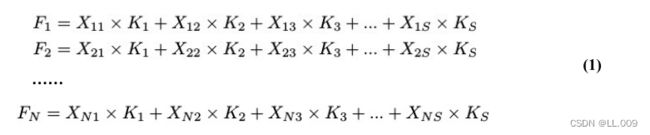
这里,Fi 表示计算后每个卷积滑块得到的值,Xi 表示每个滑块内对应位置的像素值,K表示卷积核,S表示卷积核中的参数个数,N表示接收域滑块的总数。可以看出,每个滑块内相同位置的 feature共享相同的参数Ki。因此,标准的卷积运算并不能捕捉到不同位置所带来的信息差异,这最终在一定程度上限制了卷积神经网络的性能。
3.2空间注意力回顾
目前,空间注意机制是利用学习得到的注意图来突出每个特征的重要性。与前一节类似,这里以 C=1为例。突出关键特征的空间注意机制可以简单表述为: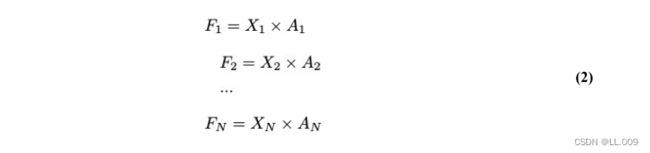 这里,Fi 表示加权运算后得到的值。xi 和Ai 表示输入特征图和学习到的注意图在不同位置的值,N为输入特征图的高和宽的乘积,表示像素值的总数。
这里,Fi 表示加权运算后得到的值。xi 和Ai 表示输入特征图和学习到的注意图在不同位置的值,N为输入特征图的高和宽的乘积,表示像素值的总数。
3.3 空间注意与标准卷积运算
将注意力机制整合到卷积神经网络中,可以提高卷积神经网络的性能。通过对标准卷积运算和现有空间注意机制的研究,我们认为空间注意机制有效地克服了卷积神经网络固有的参数共享的局限性。目前卷积神经网络中最常用的核大小是 1 × 1和3 × 3。在引入空间注意机制后,提取特征的卷积操作可以是 1 × 1或3 × 3卷积操作。为了直观地展示这个过程,在 1 × 1卷积运算的前面插入了空间注意机制。通过注意图对输入特征图(Re-weight“×”)进行加权运算,最后通过 1 × 1卷积运算提取接收域的滑块特征信息。整个过程可以简单地表示如下:
这里卷积核K仅代表一个参数值。如果取A i× ki 的值作为一种新的卷积核参数,有趣的是它解决了 1×1卷积运算提取特征时的参数共享问题。然而,关于空间注意机制的传说到此结束。当空间注意机制被插入到3×3卷积运算前面时。具体情况如下:
如上所述,如果取A的值 i × ki (4)式作为一种新的卷积核参数,完全解决了大规模卷积核的参数共享问题。然而,最重要的一点是,卷积核在提取每个接受域滑块的特征时,会共享一些特征。换句话说,每个接收域滑块内都有一个重叠。仔细分析后会发现A12= a21, a13 = a22, a15 = a24……,在这种情况下,每个滑动窗口共享空间注意力地图的权重。因此,空间注意机制没有考虑整个接受域的空间特征,不能有效地解决大规模卷积核的参数共享问题。因此,空间注意机制的有效性受到限制。
3.4创新空间注意力和标准卷积操作
RFA的提出解决了现有空间注意机制的局限性,为空间处理提供了一种创新的解决方案。受RFA的启发,一系列空间注意机制被开发出来,可以进一步提高卷积神经网络的性能。RFA可以看作是一个轻量级即插即用模块,RFA设计的卷积运算(RFAConv)可以代替标准卷积来提高卷积神经网络的性能。因此,我们预测空间注意机制与标准卷积运算的结合将继续发展,并在未来带来新的突破。
接受域空间特征:为了更好地理解接受域空间特征的概念,我们将提供相关的定义。接收域空间特征是专门为卷积核设计的,并根据核大小动态生成。如图1所示,以3×3卷积核为例。在图1中,“Spatial Feature”指的是原始的Feature map。“接受域空间特征”是空间特征变换后的特征图,
即
图1。通过对空间特征进行变换,得到接收域空间特征。
由不重叠的滑动窗口组成。当使用 3×3卷积内核提取特征时,接收域空间特征中的每个 3×3大小窗口代表一个接收域滑块。接受域注意卷积(RFAConv):针对接受域的空间特征,我们提出了接受域注意卷积(RFA)。该方法不仅强调了接收域滑块内不同特征的重要性,而且对接收域空间特征进行了优先排序。通过该方法,完全解决了卷积核参数共享的问题。接受域空间特征是根据卷积核的大小动态生成的,因此,RFA是卷积的固定组合,不能与卷积操作的帮助分离,卷积操作同时依赖于RFA来提高性能,因此我们提出了接受场注意卷积(RFAConv)。具有3×3大小的卷积核的RFAConv整体结构如图2所示。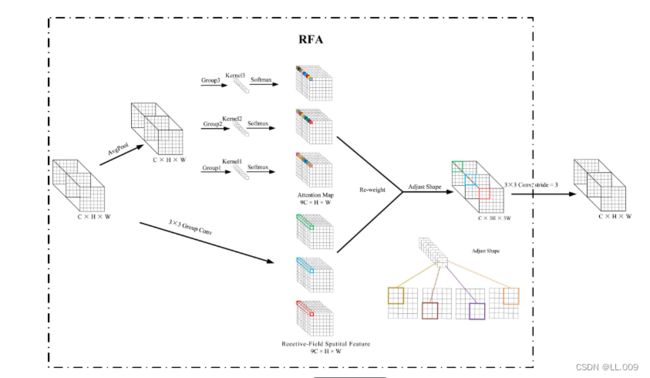
图二。RFAConv的详细结构,动态地确定各特征在接受域中的重要性,解决了参数共享问题。
目前,最广泛使用的接受域特征提取方法是缓慢的。经过大量的研究,我们开发了一种快速的方法,用分组卷积来代替原来的方法。具体来说,我们利用相应大小的分组卷积来动态生成基于接受域大小的展开特征。尽管与原始的无参数方法(如PyTorch提供的nn.())相比,该方法增加了一些参数,但它的速度要快得多。注意:如前一节所述,当使用 3×3卷积内核提取特征时,接收域空间特征中的每个 3×3大小窗口表示一个接收域滑块。而利用快速分组卷积提取感受野特征后,将原始特征映射为新的特征。最近的研究表明。交互信息可以提高网络性能,如[40,41,42]所示。同样,对于RFAConv来说,通过交互接受域特征信息来学习注意图可以提高网络性能。然而,与每个接收域特征交互会导致额外的计算开销,因此为了最小化计算开销和参数的数量,我们使用AvgPool来聚合每个接收域特征的全局信息。然后,使用 1×1 组卷积操作进行信息交互。最后,我们使用softmax来强调每个特征在接受域特征中的重要性。一般情况下,RFA的计算可以表示为: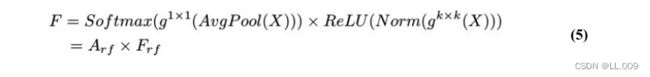
这里gi×i 表示一个大小为 i×i的分组卷积,k表示卷积核的大小,Norm表示归一化,X表示输入的特征图,F由注意图 a相乘得到 rf 与转换后的接受域空间特征 Frf。与CBAM和CA不同,RFA能够为每个接受域特征生成注意图。卷积神经网络的性能受到标准卷积操作的限制,因为卷积操作依赖于共享参数,对位置变化带来的信息差异不敏感。然而,RFAConv通过强调接收域滑块中不同特征的重要性,并对接收域空间特征进行优先级排序,可以完全解决这个问题。通过RFA得到的feature map是接受域空间特征,在“Adjust Shape”后没有重叠。因此,学习到的注意图将每个接受域滑块的特征信息聚合起来。换句话说,注意力地图不再共享在每个接受域滑块。这完全弥补了现有 CA和CBAM注意机制的不足。RFA为标准卷积内核提供了显著的好处。而在调整形状后,特征的高度和宽度是 k倍,需要进行 stride = k的k × k卷积运算来提取特征信息。RFA设计的卷积运算RFAConv为卷积带来了良好的增益,对标准卷积进行了创新。
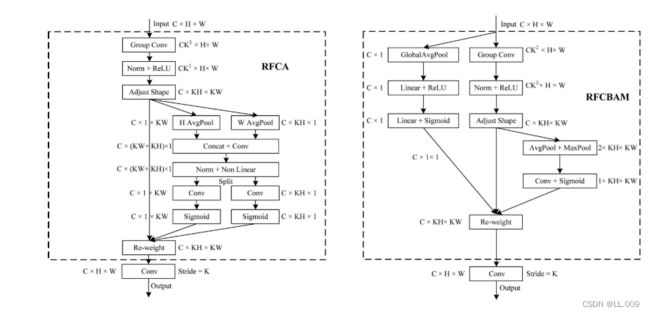
此外,我们认为现有的空间注意机制应该优先考虑接受域空间特征,以提高网络性能。众所周知,基于自注意机制的网络模型[43,44,45]取得了很大的成功,因为它解决了卷积参数共享的问题,并对远程信息进行建模。然而,自注意机制也为模型引入了显著的计算开销和复杂性。我们认为,将现有的空间注意机制的注意力引导到接受场空间特征上,可以以类似于自我注意的方式解决长期信息的参数共享和建模问题。与自我关注相比,这种方法需要的参数和计算资源少得多。答案如下:(1)将以接收场空间特征为中心的空间注意机制与卷积相结合,消除了卷积参数共享的问题。(2)现有的空间注意机制已经考虑了远程信息,可以通过全局平均池或全局最大池的方式获取全局信息,其中明确考虑了远程信息。因此,我们设计了新的 CBAM和CA模型,称为RFCBAM和RFCA,它们专注于接受域空间特征。与RFA类似,使用最终的k × k stride = k 的卷积运算来提取特征信息。这两种新的卷积方法的具体结构如图 3所示,我们称这两种新的卷积操作为 RFCBAMConv和RFCAConv。与原来的CBAM相比,我们在RFCBAM中使用SE attention来代替CAM。因为这样可以减少计算开销。此外,在RFCBAM中,通道注意和空间注意不是分开执行的。相反,它们是同时加权的,使得每个通道获得的注意力地图是不同的。