【C 语言】编译过程 分析 ( 预处理 | 编译 | 汇编 | 链接 | 宏定义 | 条件编译 | 编译器指示字 )
相关文章链接 :
1.【嵌入式开发】C语言 指针数组 多维数组
2.【嵌入式开发】C语言 命令行参数 函数指针 gdb调试
3.【嵌入式开发】C语言 结构体相关 的 函数 指针 数组
4.【嵌入式开发】gcc 学习笔记(一) - 编译C程序 及 编译过程
5.【C语言】 C 语言 关键字分析 ( 属性关键字 | 常量关键字 | 结构体关键字 | 联合体关键字 | 枚举关键字 | 命名关键字 | 杂项关键字)
- 一 编译过程
- 编译过程图解
- 步骤1 编译预处理
- 1 预编译处理内容
- 2 预编译处理代码示例 验证 include define 注释 处理过程
- 步骤2 编译
- 1 编译 中的操作
- 2 编译 示例
- 步骤3 汇编
- 1 汇编 中的操作
- 2 汇编 示例
- 单步编译 示例 预处理 编译 汇编 链接
- 链接器
- 1 链接器简介
- 2 静态链接
- 3 动态链接
- 二 宏定义 使用详解
- 宏定义 常量
- 宏表达式
- 1 宏表达式简介
- 2 宏表达式 代码示例
- 3 宏表达式 与 函数对比
- 宏表达式 或 宏常量 作用域限制
- 1 宏定义 没有作用域限制
- 2 undef 限制宏定义 作用域
- 内置宏
- 1 内置宏 简介
- 2 日志宏 代码示例
- 三 条件编译
- 基本概念
- 1 条件编译简介
- 2 条件编译 示例 简单的条件编译 修改代码实现
- 3 条件编译 示例 使用命令行生成宏定义控制条件编译 不修改代码实现
- include 间接包含
- 1 间接包含 介绍
- 2 include 间接包含 示例 错误示例 解决方案
- 2 include 间接包含 示例 正确的处理方法
- 条件编译控制示例 编译不同产品 控制开发版本和发布版本编译
- 基本概念
- 四 编译指示字 error line
- error 编译指示字
- 1 error 简介
- 2 error warning 代码示例
- line 编译指示字
- 1 line 简介
- 2 line 代码示例
- pragma 编译器指示字
- 1 pragma 简介
- 2 pragma message 参数
- 3 pragma pack 参数
- error 编译指示字
- 五 运算符
- 运算符
- 运算符
一. 编译过程
1. 编译过程图解
编译过程 :

编译过程 : 预处理 -> 编译 -> 汇编 -> 链接;
1. 编译预处理 : 产生 .i 后缀的预处理文件;
2. 编译操作 : 产生 .s 后缀的汇编文件;
3. 汇编操作 : 产生 .o 后缀的机器码二进制文件;
4. 链接操作 : 产生可执行文件 ;
2. 步骤1 : 编译预处理
(1) 预编译处理内容
预编译操作 :
- 1.处理注释 : 删除所有的注释, 使用空格取代注释内容;
- 2.处理宏定义 : 删除所有的 #define 宏定义, 替换 代码中 宏定义 对应 的 内容;
- 3.处理条件编译指令 : 处理 #if, #else, #ifdef, #elif, #endif 等条件编译指令 ;
- 4.处理#include : 处理 #include, 将被包含的文件拷贝到代码中.
- 5.处理#pragma : 编译器使用的 # program 指令 保留下来, 这个指令是 C 代码 到 汇编 代码 进行 处理的指示字.
预处理指令 : gcc -E test_1.c -o test_1.i
(2) 预编译处理代码示例 (验证 #include | #define | 注释 处理过程)
编译预处理示例 :
- 1.代码示例 :
//预编译会将 stdio.h 中的内容拷贝到代码中,
#include - 2.预处理 : 使用 gcc -E test_1.c -o test_1.i 命令进行预处理, 预处理完之后生成 test_1.i 文件.

- 3.查看预处理文件 : 查看 test_1.i 文件 ;
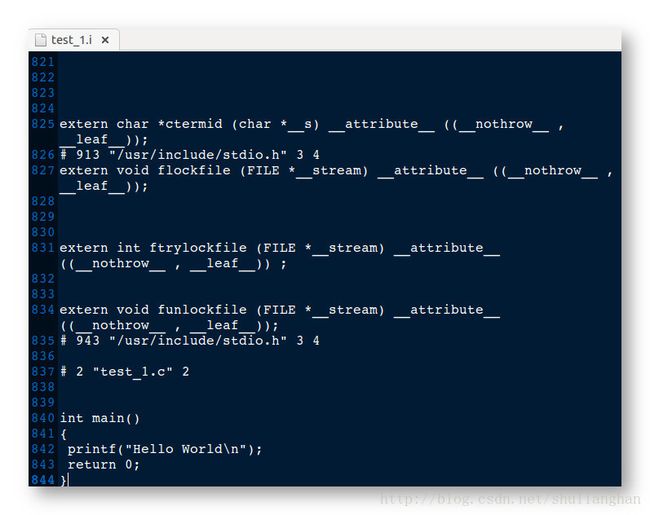
test_1.i 出现了800多行的预处理文件, 原因是 #include < stdio.h >, 将 stdio.h 的文件拷贝了进来, 如果去掉了 #include 声明, 那么预处理文件就很小.
删除了 # include 代码 :
- 1.代码示例 :
- 2.预处理 : 使用 gcc -E test_1.c -o test_1.i 命令进行预处理;
- 3.查看预处理文件 :

如果没有了 #include 声明, 那么预编译后的文件会大大减少.
3. 步骤2 : 编译
(1) 编译 中的操作
编译 步骤中的操作 :
- 1.词法分析 : 分析 关键字, 标识符, 立即数 的合法性;
- 2.语法分析 : 检查 代码 是否遵循 C 语言语法规则;
- 3.语义分析 : 分析表达式是否合法;
编译 需要的指令 : gcc -S test_1.c -o test_1.s ;
(2) 编译 示例
编译 示例 :
- 1.代码内容 :
//预编译会将 stdio.h 中的内容拷贝到代码中,
//如果删除了 include 预编译, 那么代码量会大大减少
#include - 2.执行编译内容 : 执行 gcc -S test_1.c -o test_1.s 命令, 得到 test_1.o 文件.

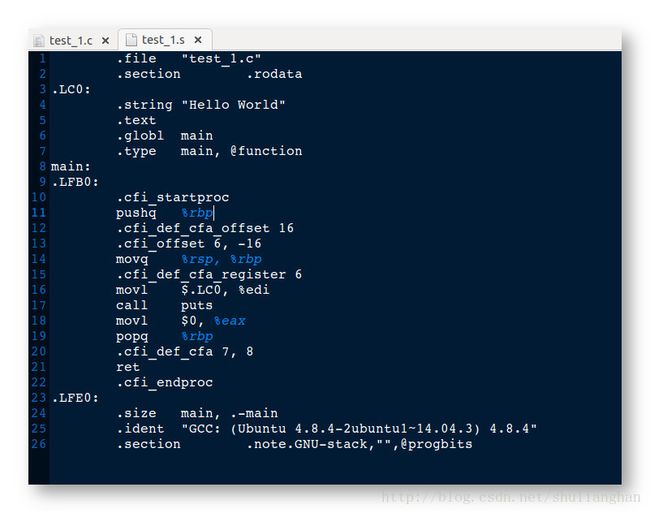
- 3.查看编译结果 : 查看生成的 test_1.s 文件, 是一个汇编文件 ;
4. 步骤3 : 汇编
(1) 汇编 中的操作
汇编 操作 :
- 1.执行者 : 汇编器;
- 2.操作 : 使用 汇编器 将 汇编代码, 转化为 机器可执行的 机器码.
汇编 命令 : gcc -c test_1.s -o test_1.o ;
每条汇编指令都对应着指定的机器码 .
(2) 汇编 示例
汇编 过程示例 :
- 1.代码内容 :
//预编译会将 stdio.h 中的内容拷贝到代码中,
//如果删除了 include 预编译, 那么代码量会大大减少
#include - 2.执行编译内容 : 执行 gcc -S test_1.c -o test_1.s 命令, 得到 test_1.o 文件.
- 3.查看编译结果 : 查看生成的 test_1.s 文件, 是一个汇编文件 ;
- 4.汇编 : 执行 gcc -c test_1.s -o test_1.o 命令, 得到 test_1.o 文件 ;

5. 单步编译 示例 ( 预处理 | 编译 | 汇编 | 链接)
单步编译示例 :
- 1.代码结构: 头文件 test_1.h, 代码文件 test_1.c ;

- 2.头文件代码 :
//定义宏, 在预编译中会被删除, 直接替换到代码中
//预编译过程中 MIN(a,b) 会被 (((a)>(b)) ? (b) : (a)) 替换
#define MIN(a,b) (((a)>(b)) ? (b) : (a))
//定义全局变量
int global_variable = 666;- 3.主要逻辑代码 :
#include "test_1.h"
//定义两个宏
#define SMALL 666
#define BIG 888
int min(int a, int b)
{
//在预编译的步骤中, MIN(a, b) 直接替换为 (((a)>(b)) ? (b) : (a))
return MIN(a,b);
}
int main()
{
//预编译过程中, SMALL 被替换成 666, BIG 被替换成 888
int min_number = min(SMALL, BIG); // Call max to get the larger number
return 0;
}- 4.进行预编译 : 执行 gcc -E test_1.c -o test_1.i 指令, 会生成 test_1.i 文件;

5.预编译目标结果文件 : test_1.i 文件;
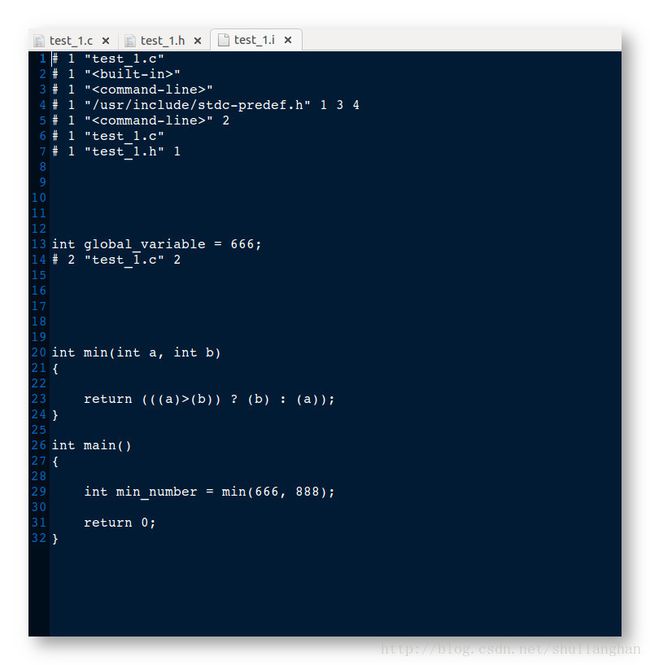
分析 test_1.i 文件:
- 拷贝包含文件 : #include “test_1.h” 直接将 test_1.h 中的内容拷贝到 test_1.i 文件中 , 8 ~ 13 行是 test_1.h 文件拷贝到 test_1.i 中的内容.
- 编译器注释说明 : #部分不管, 是编译器生成的说明 ;
- 处理注释 : 将注释使用空格替换, test_1.i 中 8 ~ 12 行 5 行是空格, 第 8, 9, 12 行对应着 test_1.h 中的注释, 第十行对应着 test_1.h 中的宏定义, 第11行对应着空白行.
- 替换宏定义 : 将宏定义的位置替换到代码中, 宏定义行使用空格替代 , 其中 8 ~ 12 行空行, 第10行就是宏定义删除后的空行 ; 代码中 MIN(a,b) 的位置 被 (((a)>(b)) ? (b) : (a)) 替换, SMALL 被 666 替换, BIG 被 888 替换.
6.编译 产生 汇编文件 : 执行 gcc -S test_1.i -o test_1.s 命令 , 生成了 test_1.s 文件,


- 7.将汇编文件转为机器码 : 执行指令 gcc -C test_1.s -o test_1.o , 生成 test_1.o 文件 , 生成的机器码是二进制的文件, 使用 文本编辑器打不开, 在 Windows 中使用 010Editer 打开查看二进制内容 ;


6. 链接器
(1) 链接器简介
链接器简介 :
- 1.衔接模块引用 : 软件各个模块之前会相互调用, 链接器就是处理这些相互引用的位置之间的衔接 .
链接器 模块拼装 :
- 1.普通链接 : 运行时, 将所有的代码库 .o 文件, 一次性拷贝到内存中, 如果运行多个副本, 那么相同的代码库会各自占用一部分内存, 这些内存中存储的东西是一样的.
- 2.静态链接 : 出于节省内存的考虑, 我们可以将相同的代码封装到静态库中, 那么多个副本同时运行时, 只加载一份静态库即可, 这样相对于普通链接来说节省内存, 内存消耗比动态链接要多.
- 3.动态链接 : 运行开始的时候只加载必要的模块, 当开始调用某一动态链接库时, 才去寻找并加载动态链接库到内存中, 节省内存, 但是运行效率慢.
(2) 静态链接
静态链接 :
- 1.加载时机 : 静态库中的代码, 在运行开始前就全部加载到内存中, 这与动态链接中
- 2.加载份数 : 在内存中, 静态库只加载一次, 第一次执行程序用到静态库时, 加载静态库, 当再次运行时, 继续复用第一次加载静态库, 这样比较节省内存.
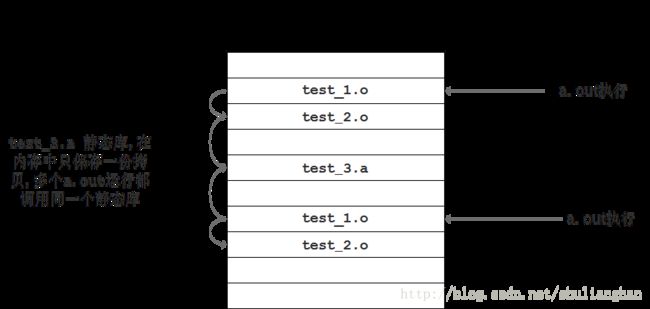
静态链接图示 :

当运行2个a.out 时, 对于静态库 test_3.a 只需要加载 1 次, 但是对于 test_1.o 和 test_2.o 需要各自加载一次.
静态库链接内存图 :
(3) 动态链接
动态链接 :
- 1.加载时机 : 程序运行时不加载动态链接库, 程序执行调用动态链接库函数的时候, 才动态的加载动态链接库 .
- 2.执行效率 : 动态链接效率 比 静态链接要低, 因为其执行的时候, 需要搜索并加载动态链接, 这样会消耗一定的性能 ;
动态链接图解 :

二. 宏定义 使用详解
1. 宏定义 常量
宏定义 常量 :
- 1.#define 定义 常量, 只是进行简单的代码替换.
- 2.#define 定义的不是真正意义的常量, 只是进行简单的代码替换, 下面代码中的内容都是合法的.
//下面的宏定义都是合法的
//在预编译界面都是进行简单的代码文本替换
#define YES 1
#define PI 3.14
#define COUNTRY "China"
//出现 NAME 的位置使用 Bill 替换
#define NAME Bill
//这条宏定义是合法的, \ 是接续符号
#define PATH \root\apue\
io_code
2. 宏表达式
(1) 宏表达式简介
宏表达式 #define :
- 1.本质不是函数 : 使用 # define 表达式, 有函数的假象, 但是其并不是函数;
- 2.功能强大, 但容易出错 : 某些用法 生硬的替换代码 可能导致出现 出错的情况.
- 3.宏使用示例 :
#include
//宏定义表达式 获取数组中元素测试
#define DIM(array) (sizeof(array)/sizeof(*array))
//对比 #define SUM(a,b) (a)+(b) 宏定义, 方法不容易出现歧义
int sum(int a, int b)
{
return a + b;
}
//使用函数计算数组大小, 下面的语句是无法实现的
//array 传入之后, 在函数中会退化成一个指针, 其大小与元素大小一样
//sizeof(array) 是指针所占用的空间大小, 不是数组所占用的空间大小
int dim(int array[])
{
return sizeof(array)/sizeof(*array);
}
int main()
{
//获取 333 和 666 的和
printf("%d\n", SUM(333, 666));
//获取 333 666 之间较小的值
printf("%d\n", MIN(333, 666));
//这里我们想要得到 3 * 3 即 9, 但是编译执行后 结果是 5
//即使用 SUM(1,2) 替换为 (1)+(2)
//预编译后语句变为 : printf("%d\n", (1)+(2) * (1)+(2));
//注意点1 : 不要将宏表达式连续使用
printf("%d\n", SUM(1, 2) * SUM(1, 2));
//MIN(a++, b) 打印结果是 2
//如果出现了 a++ 等自增符号被宏替换
//预编译后替换结果 : printf("%d\n", ((a++
//注意点2 : 不要在宏替换中写 自增 自减 等其他表达式, 只使用简单的单一变量
int a = 1;
int b = 3;
printf("%d\n", MIN(a++, b));
//将 DIM(array) 宏替换, 计算数组大小, 打印结果为 7
//打印的语句被宏替换为 : printf("%ld\n", (sizeof(array)/sizeof(*array)));
//如果使用函数来计算数组大小,是无法实现的,如果函数传入 array, 函数参数 会将 array 当做一个指针,
//该array 数组就退化成了一个指针, 无法计算大小了, 该功能要比函数要强大
int array[] = {0, 1, 2, 3, 4, 5, 6};
printf("%ld\n", DIM(array));
//调用函数计算数组大小, 同样的语句打印出来的结果是1
printf("%d\n", dim(array));
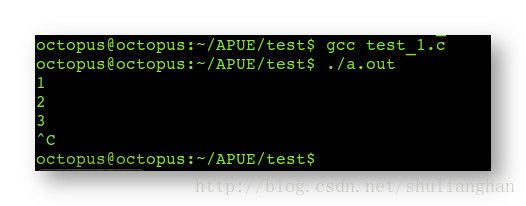
return 0;
} - 4.执行结果 :

(2) 宏表达式 代码示例
宏替换代码示例 :
- 1.原始 C 代码 (含有宏定义) :
#include - 2.预处理宏替换结果 : test_1.c 进行预处理后的 test_1.i, 使用 gcc -E test_1.c -o test_1.i 命令进行预处理;

- 3.执行结果 :
(3) 宏表达式 与 函数对比
宏表达式 与 函数对比 :
- 1.对编译器透明 : 宏表达式在预编译阶段进行替换处理, 编译器不知道宏的存在;
- 2.运算方面 : 宏替换不进行任何运算, 没有实参形参的概念, 全部都是机械的替换, 宏表达式参数可以使变量,也可以是类型;
- 3.调用开销方面 : 宏表达式不消耗任何调用开销, 没有函数调用开销, 其在预处理阶段就被替换了;
- 4.关于递归 : 宏表达式不能使用递归定义宏;
递归代码示例 (错误示例) :
- 1.宏递归代码示例 :
#include - 2.预编译结果 : 宏替换后的结果 ;

- 3.编译结果 : 编译报错, 提示没有定义 FAC() 方法 ;

3. 宏表达式 或 宏常量 作用域限制
(1) 宏定义 没有作用域限制
宏定义作用域限制 :
- 1.宏定义位置 : 宏定义可以再程序的任意位置定义, 甚至是函数内部;
- 2.宏定义使用位置 : 宏定义可以再任何位置使用;
- 3.代码示例 :
#include - 4.预编译结果 :

- 5.执行结果 :

(2) #undef 限制宏定义 作用域
限制宏定义作用域 #undef 用法 :
- 1.使用方法 : 定义宏 #define MIN 100 之后, 可以使用 #undef MIN 限制其作用范围, 只能在 #define 和 #undef 之间使用该宏, 在 #undef 之后就不可使用该宏了;
- 2.使用示例 (错误示例) :
#include - 3.预编译结果 :

- 4.编译报错内容 :

4. 内置宏
(1) 内置宏 简介
内置宏举例 :
- 1.__FILE__ : 代表被编译的文件名称 ;
- 2.__LINE__ : 代表当前的行号 ;
- 3.__DATE__ : 代表当前的日期 ;
- 4.__TIME__ : 代表编译时的时间 ;
- 5.__STDC__ : 编译器是否遵循 标准 C 规范 ;
(2) 日志宏 代码示例
使用宏定义日志打印 :
- 1.代码示例 :
#include - 2.运行结果 :

日志宏 : 打印日志的同时, 打印当前的文件名称, 代码行号, 当前运行时间 ;
三. 条件编译
1. 基本概念
(1) 条件编译简介
条件编译指令 :
- 1.指令 : #if , #ifdef, #ifndef, #else, #endif 等 ;
- 2.用法 : 与 if else 等用法类似, 具体查看下面的示例, 但是 #if, #else, #endif 是预编译阶段被预编译处理的, if else 是在编译阶段, 被编译器处理, 是要被编译到目标代码中的 ;
- 3.作用 : 条件编译指令是预编译指令, 控制某段代码是否被编译, 可以按照不同的条件选择性编译指定的代码段, 选择性的忽略某段代码, 用以编译出不同功能的可执行目标文件 ;
条件编译的应用环境 :
- 1.软件分支维护 : 维护一个软件的不同分支, 控制软件分支编译;
- 2.区分版本 : 区分软件调试版本 和 正式上线的版本, 开发版本肯定有很多调试信息, 正式版没有冗余的信息;
条件编译 注意点 :
- 1.命令行定义宏 : 可以使用 gcc -D 选项来定义宏, 如 gcc -DDEBUG test_1.c 等价于 #define DEBUG, gcc -DMIN=1 test_1.c 等价于 #define MIN 1 语句 ;
- 2.条件编译处理头文件包含问题 : #include 会出现多重嵌套问题, 使用 #ifndef _HEAD_H_ | #define _HEAD_H_ | #endif 可以解决头文件多次引用的问题 ;
- 3.使用一套代码维护不同产品 : 开发中, 可以条件编译来维护一套代码, 编译出不同的产品 ;
- 4.开发板和正式版区分 : 使用条件编译可以区分产品的开发调试版本 和 正式发布版本 ;
(2) 条件编译 示例 (简单的条件编译 | 修改代码实现)
通过修改代码 控制 条件编译 代码示例 :
- 1.代码1 :
#include - 2.条件编译 预编译结果 : 使用 gcc -E test_1.c -o test_1.i 命令进行预编译 ;

- 3.执行结果 :

修改代码后 删除宏定义 :
- 1.代码2 :
#include - 2.条件编译 预编译结果 :

- 3.执行结果 :
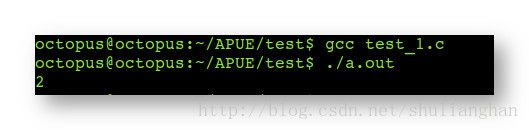
上述两个例子, 主要是通过在代码中定义 宏常量, 来控制条件编译中, 哪些语句需要编译, 哪些语句在预编译阶段就要删除 ;
(3) 条件编译 示例 ( 使用命令行生成宏定义控制条件编译 | 不修改代码实现)
使用命令行定义宏 从而控制条件编译, 代码不变 :
- 1.代码 :
#include - 2.命令行1 : 使用命令行命令 gcc -DC=1 -E test_1.c -o test_1.i, 该命令 等价于 定义 宏 #define C 1, 下面是预编译结果 和 执行结果 ;


- 3.命令行2 : 使用命令行命令*gcc -DC=2 -E test_1.c -o test_1.i, 该命令等价于 定义宏 #define C 2, 下面是预编译结果 和 执行结果 ;


2. #include 间接包含
(1) 间接包含 介绍
#include 间接包含 :
- 1.#include作用 : #include 作用是 单纯的 将 文件内容 嵌入 到 当前的 文件 ;
- 2.间接包含 : #include 会有间接包含的情况, 如 包含的 文件中, 有重复包含的情况 ;
(2) #include 间接包含 示例 ( 错误示例 | 解决方案 )
间接包含 结构图示 : test_1.c 文件包含 三个头文件, test_1.h 包含的 test_2.h 头文件 与 test_1.c 包含的该头文件相同, 同一个头文件被导入了2次, 因此编译时会报错;

间接包含 代码示例 :
- 1.test_1.c 代码 :
#include - 2.test_1.h 头文件代码 :
#include - 3.test_2.h 头文件代码 :
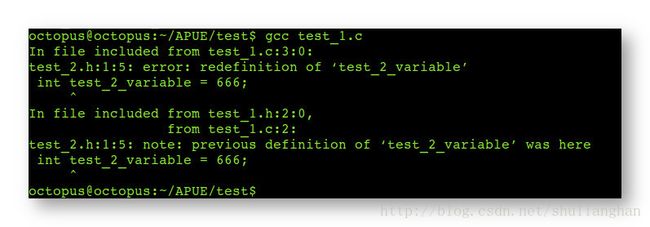
int test_2_variable = 666;- 4.预编译结果 : 同时拷贝了两份 int test_2_variable = 666; 语句, 如果进入编译阶段, 肯定是重复定义变量 ;

- 5.编译报错内容 :
间接包含 简单解决方案 : 下面的代码与上面的唯一区别是, test_1.c 中注释掉了 #include “test_2.h” 语句.
- 1.test_1.c 代码 :
#include - 2.test_1.h 头文件代码 :
#include - 3.test_2.h 头文件代码 :
int test_2_variable = 666;- 4.执行结果 :

(2) #include 间接包含 示例 ( 正确的处理方法 )
使用 #ifndef , #define 和 #endif 语句处理头文件包含情况 :
- 1.主代码 test_1.c :
#include - 2.头文件1 test_1.h :
//如果没有定义 _TEST_2_H_ 宏, 才扩展下面的内容
//如果已经定义了 _TEST_2_H_ 宏, 那么从 #ifndef 到 #endif 之间的内容都要扩展进去
//一般情况下定义的宏名称是 头文件变成大写
#ifndef _TEST_1_H_
#define _TEST_1_H_
#include - 3.头文件2 test_2.h :
//如果没有定义 _TEST_2_H_ 宏, 才扩展下面的内容
//如果已经定义了 _TEST_2_H_ 宏, 那么从 #ifndef 到 #endif 之间的内容都要扩展进去
//一般情况下定义的宏名称是 头文件变成大写
#ifndef _TEST_2_H_
#define _TEST_2_H_
int test_2_variable = 666;
#endif- 4.预编译结果 :
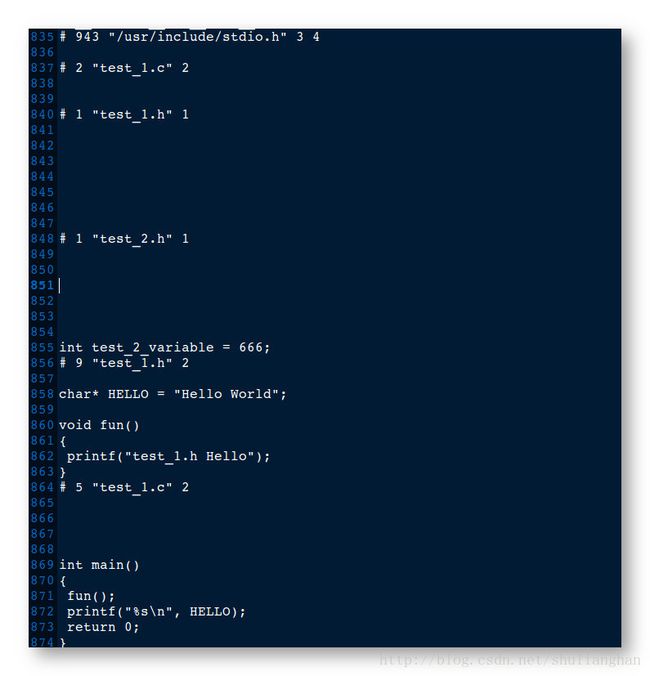
- 5.代码执行结果 :

3. 条件编译控制示例 ( 编译不同产品 | 控制开发版本和发布版本编译)
条件编译控制代码示例 :
- 1.代码 :
#include <stdio.h>
//控制开发版本与发布版本 :
//如果定义了 DEBUG 宏, 那么LOG(s) 就会打印调用位置的文件和行号以及对应日志
//如果没有定义 DEBUG 宏, 那么 LOG(s) 就会直接使用 NULL 替换
#ifdef DEBUG
#define LOG(s) printf("%s : %d : %s \n", __FILE__, __LINE__, s)
#else
#define LOG(s) NULL
#endif
//控制不同的产品编译
//如果定义了 PRODUCT_1, 那么编译上面的 fun(), 删除下面的 fun()
//如果没有定义 PRODUCT_1, 那么删除上面的 fun(), 编译下面的 fun()
#ifdef PRODUCT_1
void fun()
{
LOG("product 1 fun start");
printf("product 1 fun() \n");
LOG("product 1 fun end");
}
#else
void fun()
{
LOG("product 2 fun start");
printf("product 2 fun() \n");
LOG("product 2 fun end");
}
#endif
int main()
{
//控制日志打印
LOG("main() start");
//根据当前定义的产品打印不同的结果
#ifdef PRODUCT_1
printf("product 1 welcom\n");
#else
printf("product 2 welcom\n");
#endif
fun();
LOG("main() end");
return 0;
}
- 2.编译产品1代码开发版本(debug)并执行 : 产品1 的 debug 版本需要定义 DEBUG宏 和 PRODUCT_1 宏, 使用命令 gcc -DDEBUG -DPRODUCT_1 test_1.c 进行编译即可 ;

- 3.编译产品2代码开发版本(bebug)并执行 : 产品2 debug 版本, 不需要定义 PRODUCT_1 宏, 但是需要定义 DEBUG 宏, 使用命令 gcc -DDEBUG test_1.c 进行编译即可;
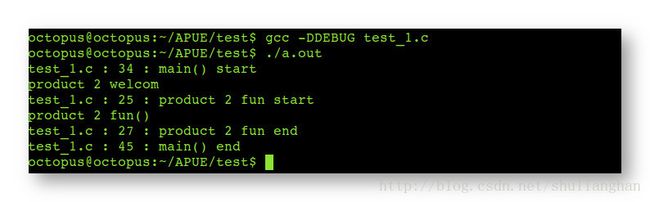
- 4.编译产品1代码发布版本(release)并执行 : 产品1的release 版本, 不定义 DEBUG 宏, 但是需要定义 PRODUCT_1 宏, 使用命令 gcc -DPRODUCT_1 test_1.c 即可 ;

- 5.编译产品2代码发布版本(release)并执行 : 产品2的release版本, 只需要不定义 DEBUG宏 和 PRODUCT_1宏即可, 使用 gcc test_1.c 命令 ;

四. 编译指示字 ( #error | #line )
1. #error 编译指示字
(1) #error 简介
#error简介 :
- 1.#error 作用 : #error 编译指示字 用于生成 编译错误信息, 立即终止编译 ; 这个编译错误是程序员自定义的编译错误信息;
- 2.#error 用法 : #error error_message, 这个 error_message 是字符串, 不需要使用 “” 包起来;
#warning 也是编译指示字, 用于在编译时生成警告信息, 但是编译的过程不会终止, 会继续编译下去 ;
(2) #error #warning 代码示例
#error #warning 代码示例 :
- 1.代码 :
#include - 2.编译结果( 命令行中定义指定的宏 ) : 使用 gcc -DMAX test_1.c 命令编译, 此处定义了 MAX 宏, 编译执行成功.

- 3.编译结果( 命令行中不定义指定的宏 ) : 使用 gcc test_1.c 命令编译, 此处没有命定义 MAX 宏, 编译时报错.

- 4.单步操作预编译结果 (定义宏) : 使用 gcc -DMAX -E test_1.c -o test_1.i 命令, 进行预编译, 结果预编译成功, 查看预编译生成的 test_1.i 文件 ;

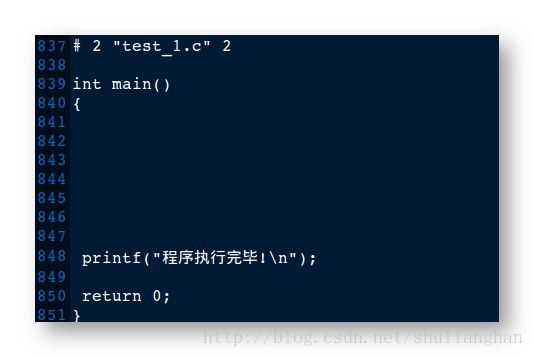
- 5.单步操作预编译结果 (不定义宏) : 使用 gcc -E test_1.c -o test_1.i 命令, 进行预编译, 结果预编译也停止了, 没有生成 test_1.i 文件, 因此#error 和 #warning 是在预编译阶段进行处理的 ;

2. #line 编译指示字
(1) #line 简介
#line 简介 :
- 1.#line 作用 : 用于修改当前的 __LINE__ 和 __FILE__ 的内置宏 ;
- 2.#line 用法 : #line 行号 文件名 , 即将当前的 内置宏 __LINE__ 设置为 行号, __FILE__ 设置为 文件名 ;
- 3.使用环境 : 调试代码时, 编译 查错 的时候, 设置自己关心的代码, 这是很古老的调试方法, 该技术已经被淘汰 ;
(2) #line 代码示例
#line 使用代码示例 :
- 1.代码示例 :
#include
int main()
{
//使用 #line 设置 行号 和 文件名
#line 100 "test_1_han.c"
printf("行号 : %d , 文件名 : %s \n", __LINE__ , __FILE__);
return 0;
} - 2.执行结果 :

3. #pragma 编译器指示字
(1) #pragma 简介
#pragma 编译器指示字 简介 :
- 1.#pragma 作用 : 该 编译器指示字 指示编译器完成一些特定的操作 ;
- 2.编译器特有, 不可移植 : #pragma 的很多指示字 参数, 这些参数 都是编译器 特有的, 编译器指示字 在 编译器之间不通用, 不可移植 ;
- 3.忽略不识别的指令 : 如果编译器不支持某个 #pragma 指令 参数, 预处理器会忽略这条指令, 并将其删除;
- 4.相同指令 操作不同 : 每个编译器对 #pragma 指令定义都不同, 可能存在两个相同的 #pragma 指令在不同的编译器中执行不同的操作 ;
#pragma 用法 : #pragma 参数
(2) #pragma message 参数
#pragma message 参数 :
- 1.作用 : 编译器编译时将编译信息输出到窗口中 ;
- 2.与 #error 编译器指示字对比 : #error只是在出现错误的时候, 将错误信息输出出来, #pragma message 是单纯的额将所有信息输出出来, 不管对错 ;
- 3.代码示例 :
#include - 4.不定义宏进行编译 : 如果既不定义 MAX 宏, 也不定义 MIN 宏, 那么直接执行 #error 报错;

- 5.定义 MAX 宏并执行 :

(3) #pragma pack 参数
内存对齐 简介 :
- 1.内存对齐概念 : 不同类型的数据存放在内存中, 但是其存放顺序不是顺序存放, 而是按照内存对齐规则进行排列 ;
- 2.内存对齐原因 : ① 出于性能考虑 , CPU 读取内存不是想读取多少就读取多少, 其内存读取是分块读取的, 块大小只能是 2 的n次方字节, 如 1, 2, 4, 8, 16, 字节, 如果被读取的数据没有对齐, 那么需要多次读取, 这样性能就降低了 ; ② 硬件平台限制 : 可能存在某些硬件只能读取偶数地址, 一旦读取奇数地址, 直接出现硬件异常导致程序挂掉;
- 3.内存对齐设置不能高于编译器默认对齐字节数 : GCC 编译器默认支持 4 字节对齐, 那么使用 #pragma pack() 只能设置 1字节 或 2 字节, 4 字节支持, 不能设置其它支持方式; 如果编译器默认是 8 字节, 那么只能设置 1, 2, 4, 8 四种字节对齐方式, 只能往低设置, 不能高于编译器默认的对齐字节数;
结构体 struct 占用内存计算方式 :
- 1.第一个起始位置 : 第一个元素 在 第一个位置, 从 偏移量 0 开始;
- 2.对齐参数 : 对齐数 和 类型大小 之间较小的一个是 对齐参数 ; 这里要注意 如果有结构体元素, 那么该结构体元素的对齐参数就是 结构体中的最大对齐参数;
- 3.从第二个开始的起始位置 : 除第一个之外的起始位置, 都必须整除对应的 对齐参数 ;
- 4.最终计算大小要整除所有的对齐参数 ;
- 5.注意结构体中有结构体元素 : 结构体中的结构体元素对齐数是结构体元素中的最大对齐数 ;
- 5.代码示例 :
#include - 6.执行结果 :
五. #运算符
1. #运算符
#运算符作用 :
- 1.将宏参数转为字符串 : # 运算符 可以在 编译 的 预编译 阶段, 将宏定义中的参数, 转化为 字符串 ;
- 2.预处理器开始符号 : 预处理器 开始处理 的符号 ;
- 3.#运算符代码示例 :
#include - 4.预编译结果 : 使用 “gcc -E test_1.c -o test_1.i” 指令进行预编译, 可以看到 # 运算符将 宏定义参数转为字符串 ;

# 运算符 将 Hello 666 main 转为 “Hello” “666” “main” 字符串, 将 square 转为了 “square” 字符串 ;
- 5.编译执行最终结果 :

2. ##运算符
## 运算符作用 :
- 1.作用 : 在预编译阶段粘连两个符号 ;
- 2.代码示例 :
#include - 3.预编译结果 : 使用 “gcc -E test_1.c -o test_1.i” 命令, 执行预编译 ;

- 4.最终编译执行结果 :
