AdaBins: Depth Estimation using Adaptive Bins
摘要
文章的核心思想是,对传统的编码器—解码器体系结构的输出进行全局统计分析,并使用以最高分辨率运行的学习后处理构建块来细化输出。对于处理模块的构建,引入了transformer结构,并通过与cnn的结合,提出了Adabins模型,在单目深度估计上具有一定的优越性。
创新点
解决了如何利用单张RGB图像的输入,估计高质量稠密的深度图的问题,提出了一个基于transformer的架构模块—Adabins,来执行场景信息的全局处理。
性能表现
在KITTI数据集下,目前该方法目前位居第一位,在NYU- Depth-v2数据集下,同样是目前的SOTA模型,证明该方法具有较强的性能优势,值得我们学习和参考。
方法
四种设计选择
作者在设计网络架构时,提出了 四种设计选择。
(1)采用自适应装箱策略来离散化深度区间D=(Dmin,Dmax)为N个单元。这个对于给定的数据集,间隔是固定的,由数据集规范确定或手动设定为合理的范围。这里将最终方案和其他三种可能的设计选择进行对比,如图1。
a. 用统一的单元宽度固定单元:深度间隔D将被划分为尺度相同的N个单元
b. 用对数尺度的单元宽度固定单元:深度间隔D将用对数尺度划分为相同大小的单元
c. 受训练的单元宽度:单元宽度时自适应的,并可以从特定的数据集进行学习,所有图片共享深度间隔D细分出来的单元
d. 最终方案Adabins:每张图片的间隔b是自适应计算出来的。
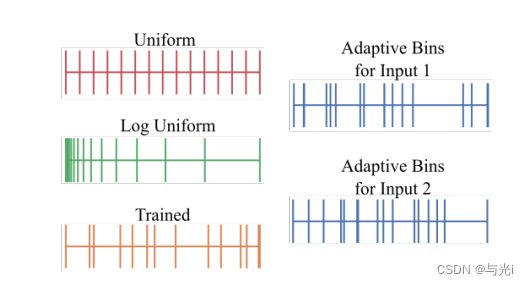
图1
(2)将深度间隔D离散为各个单元并且将每个像素分配到单个单元中形成深度离散伪影,最终深度预测为单元中心的线性组合,从而使得模型能够估计平滑变化的深度值。
(3)作者通过分析发现,在空间分辨率较高的张量上使用注意力可以获得更好的结果。因此,对网络模块的顺序作了调整,为编码器+解码器+注意力机制,而先前的方法大多会将注意力机制放在中间位置。
(4)所提方法使用了一个基线编解码器卷积网络,结合一个基于transformer的架构块block。网络使用预先训练好的Efficientnet B5网络作为编码器主干,解码器方式为标准特征上采样。本文的核心内容是提出的自适应单元宽度估计块—AdaBins,该模块的输入是由前面解码器的输出张量 X d ∈ R ( H × W × C d ) X_d∈R(H×W×C_d) Xd∈R(H×W×Cd),即解码特征,通过Adabins模块处理后,得到 ( H × W × 1 ) (H×W×1) (H×W×1)的张量。
四个子模块
AdaBins的4个子模块分别是:Mini-ViT、Bin-widths、Range attention maps和Hybrid regression。
mini-ViT:该模块是ViT的简化版本,以适应较小的数据集,其作用是使用全局注意力来计算每个输入图像的单元宽度向量。模块的结构图如图2所示,mini-ViT由二个输出:1) bin widths向量,它定义了如何为输入图像划分深度区间;2)大小为H×W×C的范围注意映射,它包含了对于像素级深度计算有用的信息。
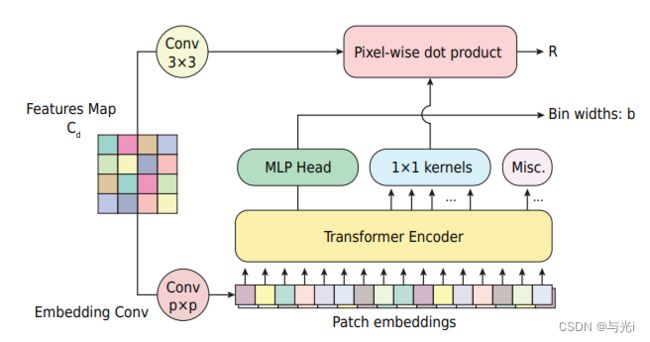
图2
Bin-widths:Transformer需要一个固定大小的向量序列作为输入,而输入的是 X d ∈ R ( H × W × C d ) X_d∈R(H×W×C_d) Xd∈R(H×W×Cd)的解码特征张量。因此,通过一个卷积核大小为 p × p p×p p×p,步长为 p p p,输出通道为E的卷积对输入进行操作,卷积输出结果为 h / p × w / p × E h/p×w/p×E h/p×w/p×E的张量。再将结果reshape成一个空间坦的张量 X p ∈ ( S × E ) X_p∈(S×E) Xp∈(S×E),其中 S = h w / p 2 S=hw/p2 S=hw/p2作为Transformer的有效序列长度,并将这一E维向量作为patch embeddings。向量经过Transformer后的输出为 X o ∈ ( S × E ) X_o∈(S×E) Xo∈(S×E),在第一个输出embedding使用MLP head并对输出b’进行归一化,最终获得bin-widths向量b,如下:
b i = b i ′ + ε ∑ j = 1 N ( b i ′ + ε ) b_i=\frac{b_i^{'}+\varepsilon}{\sum_{j=1}^N(b_i^{'}+\varepsilon)} bi=∑j=1N(bi′+ε)bi′+ε。
range attention maps:解码后的特征代表高分辨率和局部像素级特征,而Transformer输出embeddings包含更多的全局信息。来自Transformer的输出embeddings 2 通过 C + 1 用作一组 1 × 1 卷积核,并与解码特征(在 3 × 3 卷积层之后)进行卷积以获得范围注意图 R。final depth=全局信息R+局部信息b。
Hybrid regression:范围注意图R通过1×1卷积层得到N通道,并进行softmax激活。深度单元中心c(b)从单元宽度向量b计算得到,计算公式如下:
c ( b i ) = d m i n = ( d m a x − d m i n ) ( b i / 2 + ∑ j = 1 i − 1 b i ) c(b_i)=d_{min}=(d_{max}-d_{min})(b_i/2+\sum_{j=1}^{i-1}b_i) c(bi)=dmin=(dmax−dmin)(bi/2+∑j=1i−1bi)。
最终,每个像素的最终的深度值d从该像素的Softmax分数和深度单元中心c(b)的线性组合计算得到,计算公式如下:
d ~ = ∑ k = 1 N c ( b k ) p k \tilde d=\sum_{k=1}^Nc(b_k)p_k d~=∑k=1Nc(bk)pk,
其中 P k P_k Pk为定义的N个softmax的得分。
损失函数
该方法的损失函数由2部分构成,分别是像素级深度损失和单元中心密度损失。
像素级深度损失的定义如下:
L p i x e l = α 1 T ∑ i g i 2 − λ T 2 ( ∑ i g i ) 2 L_{pixel}=\alpha\sqrt{\frac{1}{T}\sum_ig_i^2-\frac{\lambda}{T^2}(\sum_ig_i)^2} Lpixel=αT1∑igi2−T2λ(∑igi)2
其中:
g i = log d ~ i − log d i g_i=\log \tilde d_i -\log d_i gi=logd~i−logdi
单元中心密度损失的定义如下:
L b i n s = c h a m f e r ( X , c ( b ) ) + c h a m f e r ( c ( b ) , X ) L_{bins}=chamfer(X,c(b))+chamfer(c(b),X) Lbins=chamfer(X,c(b))+chamfer(c(b),X)
最终,总损失定义如下:
L t o t a l = L p i x e l + β L b i n s L_{total}=L_{pixel}+\beta L{bins} Ltotal=Lpixel+βLbins。
实验
作者在kitti和NYU-Depth-v2二大数据集下进行了实验,均取得了SOTA的性能表现。
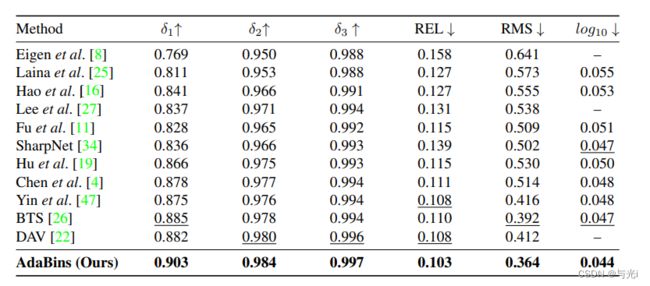
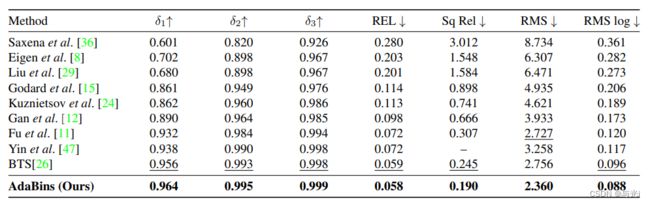
总结
文章通过CNN结合Transformer的方式进行单目深度估计的研究,提出了一个新的模块称为Adabins,并在二大公开数据集上取得了优异的性能表现。主要贡献是用transformer的出色全局信息处理能力,结合CNN的局部特征处理能力,并以取长补短的方式进行网络设计。