机器学习之PyTorch和Scikit-Learn第2章 为分类训练简单机器学习算法
其它章节内容请见机器学习之PyTorch和Scikit-Learn
本章中我们会使用所讲到的机器学习中的第一类算法中两种算法来进行分类:感知机(perceptron)和自适应线性神经元(adaptive linear neuron)。我们先使用Python逐步实现感知机,然后对鸢尾花数据集训练来分出不同花的品种。这有助于我们理解用于分类的机器学习算法概念以及如何用Python进行有效的实现。
接着对自适应线性神经元优化基础的讨论会为我们在第3章 使用Scikit-Learn的机器学习分类器之旅中通过scikit-learn机器学习库使用更高级的分类器奠定基础。
本章中的主要内容有:
- 理解机器学习算法
- 使用pandas、NumPy和Matplotlib读取、处理及可视化数据
- 用Python实现两分类问题的线性分类器
人工神经元-一瞥机器学习早期史
在深入讨论感知机和相关算法前,我们先了解下机器学习起源的简史。为理解生物大脑的工作原理进而设计人工智能(AI),Warren McCulloch和Walter Pitts于1943年发表了第一个简化大脑细胞的概念,称为McCulloch-Pitts(MCP) 神经元(《神经活动内在思想的逻辑演算》W. S. McCulloch和W. Pitts,《数学生物物理学通报》,5(4): 115-133, 1943)。
生物神经元与大脑中处理和传递化学和电信号的神经细胞相互关联,见图2.1:
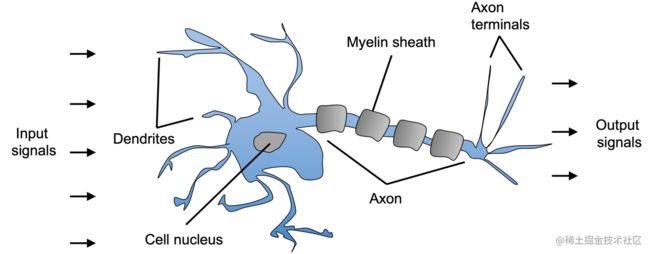
图2.1: 处理化学和电信号的神经元
McCulloch和Pitts将这种神经细胞描述为一个带二元输出的简单逻辑门,多个信号到达树突(dendrites),然后被集成到细胞体中,如果累积的信息超过了某一门槛,会生成一个输出信号由轴突(axon)传递。
几年后,Frank Rosenblatt发表了根据MCP神经模型发表了第一个感知机学习规则的概念(《感知机:一个感知和识别自动机》,F. Rosenblatt, 康奈尔航空实验室, 1957)。根据他的感知机规则,Rosenblatt提出了一种算法,可以自动学习最佳权重系数,然后乘以输入特征来决定神经元是否传输信号。在监督学习和分类领域,这一算法可用于预测新的数据点属于哪一类。
人工神经元的正式定义
更正式些,我们可以将人工神经元放到有两个类(0和1)的二元分类上下文。然后我们可以定义一个决策函数 ,接收一定输入值的线性组合x,以及权重向量w,其中z称为净输入z = w1x1 + w2x2 + … + wmxm:
,接收一定输入值的线性组合x,以及权重向量w,其中z称为净输入z = w1x1 + w2x2 + … + wmxm:
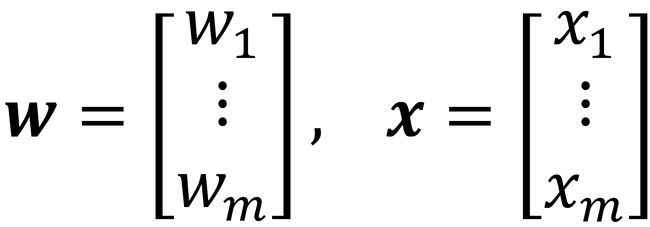
如果我们示例中的净输入x(i)大于所定义的阈值θ,我们预测为类1,否则为类0。在感知机算法中,决策函数 ,是单位阶跃函数的一种变体:
,是单位阶跃函数的一种变体:
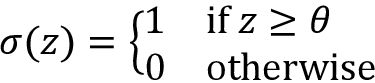
为简化稍后的代码实现,我们可能过几个步骤来修改这一设置。首先,将阈值θ移到等式的左边:
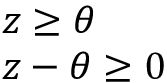
其次,我们将偏置单元(bias unit)定义为 并使其成为净输入的一部分:
并使其成为净输入的一部分:
z = w1x1 + … + wmxm + b = wTx + b
第三,根据所引入的偏置单元以及上面对净输入z的重新定义,可将决策函数重新定义如下:
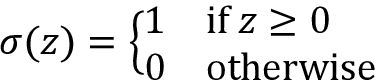
线性代数基础:点乘和矩阵转置
在后面的小节中,我们会频繁使用线性代数中的基本符号。例如,我们会将 x和w值乘积的和简写为向量点乘,而上标T 表示的是转置,是一种将列向量转换为行向量或是行向量转换为列向量的运算。比如,假设有如下两个列向量:

那么,我们可以将向量a的转置写作aT = [a1 a2 a3],并将点乘写作:
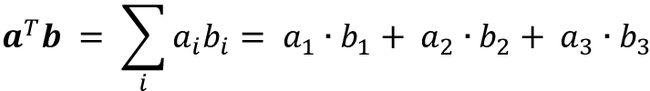
此外,还可以对矩阵应用转置运算将其沿对角线进行翻转,如:

注意转置运算是严格地定义于矩阵之上的,但是在机器学习中,我们使用向量来指代n × 1或1 × m矩阵。
本书中,我们只会使用线性代数中非常基础的概念,但如果读者需要快速补习下线性代数,可以读一下Zico Kolter的《线性代数复习和参考》,非常的不错,可通过http://www.cs.cmu.edu/~zkolter/course/linalg/linalg_notes.pdf免费获取。
图2.2描绘了如何通过感知的决策函数将净输入z = wTx + b压缩为二元输出(0或1) (左图)以及如何使用它来通过线性决策边界区分两个类(右图):

图2.2:为二元分类问题生成线性决策边界的阈值函数
感知机学习法则
MCP神经元以及Rosenblatt的阈值感知机模式整体的概念是使用还原法(reductionist approach)来模仿大脑中单个神经元的工作方法:要么有反应,要么没反应。因此Rosenblatt的经典感知机规则相对简单,感知机算法可总结为如下步骤:
-
将权重和偏置单元初始为0或较小的随机数
-
对于每个训练样本x(i):
- 计算输出值

- 更新权重和偏置单元
- 计算输出值
这里的输出值为稍早定义的单位跃阶函数所预测的类标签,偏置单元会同步更新,权重向量w中的每个权重wj,可更正式地写为:

更新值(Δ值)按如下方式计算:
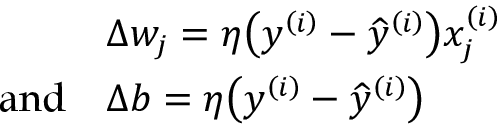
注意与偏置单元一同,每个权重wj都对应一个特征xj,在数据集中,涉及到了对更新值 的决定,定义参见上图。此外η为学习率(通常是0.0 和1.0之间的常量),y(i)是第i个样本的真实类标签,
的决定,定义参见上图。此外η为学习率(通常是0.0 和1.0之间的常量),y(i)是第i个样本的真实类标签,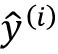 为预测类标签。重要要注意偏置单元和权重向量中的所有权重都同步更新,也就是说只有在通由各自的更新值,
为预测类标签。重要要注意偏置单元和权重向量中的所有权重都同步更新,也就是说只有在通由各自的更新值, 和
和![]() 更新好偏置单元及所有权重之后,才会重新计算预测标签
更新好偏置单元及所有权重之后,才会重新计算预测标签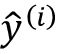 。具体来说,对于二维数据集,我们会将更新写作:
。具体来说,对于二维数据集,我们会将更新写作:

在使用Python实现感知机规则前,我们先通过一个简单实验来描绘这种学习规则的简单和美妙。在感知机正确预估类标签的两个场景中,偏置单元和权重保持不变,因为更新值为0:
(1) ![]()
(2) ![]()
但预测错误时,权重就会被推向正目标类或负目标类的方向:
(3) 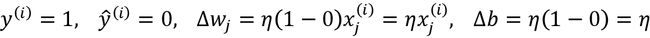
(4) ![]()
为更好理解多重因子特征值, ,我们再来看一个简单示例,其中:
,我们再来看一个简单示例,其中:
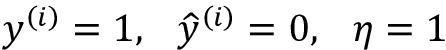
假设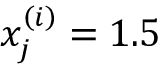 并且我们错误地将该样本归类为0。这时,我们会将相应的权重总共增加2.5,这样其净输入
并且我们错误地将该样本归类为0。这时,我们会将相应的权重总共增加2.5,这样其净输入 会在我们下次遇到这一样本更为正向,因而也更有可能高于单位跃阶函数的阈值并将该样本决定为类1:
会在我们下次遇到这一样本更为正向,因而也更有可能高于单位跃阶函数的阈值并将该样本决定为类1:
![]()
权重的更新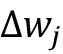 与
与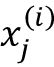 成一定比例。比如,有另一个样本,
成一定比例。比如,有另一个样本, ,被错误地归类为了类0,我们会将决策边界推到更大以让下次能对样本进行正确地归类:
,被错误地归类为了类0,我们会将决策边界推到更大以让下次能对样本进行正确地归类:
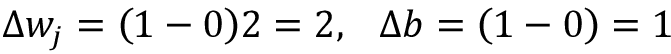
重点要注意感知机收敛的前提是两个类一定是线性可分的,也就是说这两个类必须要能够通过线性决策边界完美分割。(感兴趣的读者可以在作者的讲课笔记中找到收敛的证明:https://sebastianraschka.com/pdf/lecture-notes/stat453ss21/L03_perceptron_slides.pdf)。图2.3中导示了线性可分割和线性不可分割场景的可视化示例:
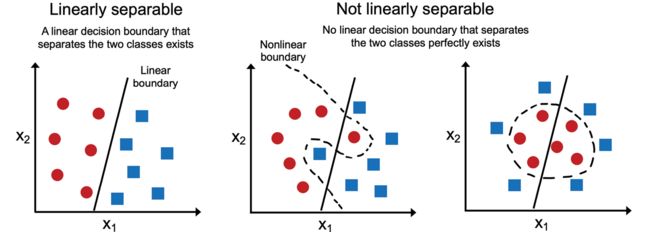
图2.3:线性可分割和线性不可分割类的示例
如果两个不能通过线性决策边界分割,我们可以对训练数据集设置最大迭代次数(epochs)及/或可容忍错误分类的阈值数,否则感知机就会不停地更新权重。本章稍后,我们会讲解Adaline算法(自适应线性神经网络),即使用类无法完美地线性分割仍能产生线性决策边界并收敛。在第3章中我们还会学习生成非线性决策边界的算法。
下载示例代码
读者可通过https://github.com/rasbt/machine-learning-book下载所有的示例代码和数据集。
在我们进入下一节具体实现之前,先使用简单的图表总结下所学习的感知机的综合概念:

图2.4:模型的权重和偏置会根据错误函数进行更新
上图中描绘了感知机如何接收输入样本(x)并结合偏置单元(b)和权重(w) 来计算净输入。然后将净输入传递给阈值函数,生成一个二元输出0或1-样本的预测类标签。在学习期间,输出用于计算预测错误并更新权重和偏置单元。
使用Python实现感知机学习算法
在前一节中,我们学习了Rosenblatt感知机规则的原理,下面使用Python进行实现并使用第1章 赋予计算机学习数据的能力中介绍的鸢尾花数据集进行训练。
面向对象的感知机API
我们采用面向对象的方法将感知机接口定义为一个Python类,这样可初始化新的Perceptron对象,来通过fit方法学习数据并通过单独的predict方法完成预测。按照约定,我们将不在对象初始化期间创建的属性后加上一个下划线(_) ,它们在调用对象的其它方法时创建,比如self.w_。
Python科学计算的其它资源
如果不熟悉Python的机器学习库或是需要复习一下,可以参考如下资源:
- NumPy: https://sebastianraschka.com/blog/2020/numpy-intro.html
- pandas: https://pandas.pydata.org/pandas-docs/stable/user_guide/10min.html
- Matplotlib: https://matplotlib.org/stable/tutorials/introductory/usage.html
以下为使用Python实现的感知机:
import numpy as np
class Perceptron:
"""Perceptron classifier.
Parameters
------------
eta : float
Learning rate (between 0.0 and 1.0)
n_iter : int
Passes over the training dataset.
random_state : int
Random number generator seed for random weight
initialization.
Attributes
-----------
w_ : 1d-array
Weights after fitting.
b_ : Scalar
Bias unit after fitting.
errors_ : list
Number of misclassifications (updates) in each epoch.
"""
def __init__(self, eta=0.01, n_iter=50, random_state=1):
self.eta = eta
self.n_iter = n_iter
self.random_state = random_state
def fit(self, X, y):
"""Fit training data.
Parameters
----------
X : {array-like}, shape = [n_examples, n_features]
Training vectors, where n_examples is the number of
examples and n_features is the number of features.
y : array-like, shape = [n_examples]
Target values.
Returns
-------
self : object
"""
rgen = np.random.RandomState(self.random_state)
self.w_ = rgen.normal(loc=0.0, scale=0.01,
size=X.shape[1])
self.b_ = np.float_(0.)
self.errors_ = []
for _ in range(self.n_iter):
errors = 0
for xi, target in zip(X, y):
update = self.eta * (target - self.predict(xi))
self.w_ += update * xi
self.b_ += update
errors += int(update != 0.0)
self.errors_.append(errors)
return self
def net_input(self, X):
"""Calculate net input"""
return np.dot(X, self.w_) + self.b_
def predict(self, X):
"""Return class label after unit step"""
return np.where(self.net_input(X) >= 0.0, 1, 0)
使用这一感知机实现,现在我们可以按给定的学习率eta(η)、迭代次数n_iter(通过训练数据集传递)来初始化新的Perceptron对象,
借助于fit方法,我们将偏置self.b_初始化为0,并将self.w_中的权重初始化为向量 ,其中的m表示数据集中的维数(特征数)。
,其中的m表示数据集中的维数(特征数)。
注意初始权重向量包含一些小随机数,通过rgen.normal(loc=0.0, scale=0.01, size=1 + X.shape[1])得到0.01标准差(standard deviation )的正态分布中提取,其中rgen是NumPy的随机数字生成器,我们使用了用户指定的随机种子,这样在需要时可以复现之前的结果。
技术上讲,我们应当将权重初始化为零(事实上在原始的感知机算法中就是这么做的)。但是,如果那样的话,学习率![]() (
(eta)就不会对决策边界产生任何效果。如果所有权重都初始化为零,学习率参数,eta,只能影响权重向量的大小,而影响不到方向。如果读者熟悉三角函数的话,思考有一个向量,v1 =[1 2 3],v1与向量v2 = 0.5 × v1之间角度刚好为零,如以下代码所示:
>>> v1 = np.array([1, 2, 3])
>>> v2 = 0.5 * v1
>>> np.arccos(v1.dot(v2) / (np.linalg.norm(v1) *
... np.linalg.norm(v2)))
0.0
这里的np.arccos是三角函数中的反余弦,np.linalg.norm是计算向量长度的函数。(我们决定通过随机正态分布来绘制随机数,却没有使用均匀分布等,以及使用0.01的标准差纯属个人意愿;我们使用了小随机数来避免出现全零向量属性,前面也讨论过了。)
学完本章后读者可以选择做一个练习,修改self.w_ = rgen.normal(loc=0.0, scale=0.01, size=X.shape[1])为self.w_ = np.zeros(X.shape[1]),使用不同的eta值来运行下一节中的感知机训练代码。读者会看到决策边界不会变化。
NumPy数组索引
NumPy一维数组的索引类似于Python列表,使用方括号([]) 符号。对二维数组,第一个索引表示行、第二个表示列。例如,我们使用X[2, 3]来选取二维数组X中第三行第四列的元素。
在初始化权重之后,fit方法遍历训练数据集中的所有样式,并根据前面小节中讨论的感知机学习率更新权重。
类标签由predict方法预测,该方法在训练期间由fit方法调用以获取更新权重后的类标签;但predict也可在我们拟合好模型后用于预测新数据的类标签。此外,我们还在self.errors_列表中收集每次迭代所产生的错误分类数,这样稍后可分析出训练期间感知机的表现。net_input方法中使用的np.dot函数只是用于计算向量的点乘,wTx + b。
向量化:使用向量化代码替换for循环
除了使用NumPy来计算两个数组a和b的向量点乘,如a.dot(b)或np.dot(a, b),我们还可以使用纯Python的sum([i * j for i, j in zip(a, b)])来执行运算。但使用NumPy相对于传统的Python for循环的优势是算术运算被向量化了。向量化意味着基本算术运算自动应用于数组中的所有元素。通过将算术运算公式化为对数组的一系列指令,而不是一次对一个元素执行一组运算,我们可以更好地利用现代中央处理单元(CPU)架构对单指令流多数据流(SIMD) 的支持。此外,NumPy使用了高度优化了的线性代数库,比如使用C或Fortran编写的基础线性代数子程序(BLAS)和线性代数计算子程序包(LAPACK)。最后,NumPy还可以用线性代数的基础如向量及矩阵点乘让代码更简洁也更符合直觉。
对鸢尾花数据集训练感知机模型
为测试我们的感知机实现,在本章剩下部分中的分析和示例中我们会限定为两个特征变量(维度)。虽然感知机规则不只限于两个维度,只考虑两个特征,萼片长度和花瓣长度,让我们可以将训练模型的决策区域可视化为散点图方便学习。
注意我们也只会考虑鸢尾花数据集中的两个类别setosa和versicolor,原因也很实际:感知机是一个二元分类器。但感知机算法也可扩展为多类分类,比如一对剩余(OvA) 技术
用于多类分类的OvA方法
OvA(one-versus-all)有时也称为one-versus-rest (OvR),是一种将二元分类扩展为多类问题的技术。使用OvA,我们可以为每个类训练一个分类器,其中特定的类视为正类,其它类的样本则被划为反类。如果对新的未打标签的数据实例进行分类,我们可以使用n分类器,其中的n是类标签数,对要分类的具体实例打上最确定的分类标签。在感知机示例中,我们使用OvA选择最大绝对净输入值所关联的类标签。
首先我们使用pandas库直接从UCI机器学习仓库加载鸢尾花数据集,放到DataFrame对象中并通过tail方法打印最后五行来检查所加载数据是否正确:
>>> import os
>>> import pandas as pd
>>> s = 'https://archive.ics.uci.edu/ml/'\
... 'machine-learning-databases/iris/iris.data'
>>> print('From URL:', s)
From URL: https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data
>>> df = pd.read_csv(s,
... header=None,
... encoding='utf-8')
>>> df.tail()
执行上述代码后,会看到显示鸢尾花数据集最后五行的如下输出:

图2.5:鸢尾花数据集的最后五行
加载鸢尾花数据集
可在本书的代码仓库中找到一份鸢尾花数据集(以及本书中使用的其它数据集),以妨你离线使用或是UCI服务器https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data临时宕机。通过本地目录加载数据集时可以将如下行
df = pd.read_csv(
'https://archive.ics.uci.edu/ml/'
'machine-learning-databases/iris/iris.data',
header=None, encoding='utf-8')
替换为:
df = pd.read_csv(
'your/local/path/to/iris.data',
header=None, encoding='utf-8')
接下来我们提取与前50个Iris-setosa和50个Iris-versicolor相对应的100个类标签,并将类标签转化为两个整型类标签1 (versicolor)和0 (setosa),赋值给向量y,其中pandas库DataFrame的values方法与NumPy中的相对应。
类似地,我们提取这100个训练样本中每一个特征列(花萼长度)和第三个特征列(花瓣长度),将其赋值给特征矩阵X,可使用二维散点图对其进行可视化:
>>> import matplotlib.pyplot as plt
>>> import numpy as np
>>> # select setosa and versicolor
>>> y = df.iloc[0:100, 4].values
>>> y = np.where(y == 'Iris-setosa', 0, 1)
>>> # extract sepal length and petal length
>>> X = df.iloc[0:100, [0, 2]].values
>>> # plot data
>>> plt.scatter(X[:50, 0], X[:50, 1],
... color='red', marker='o', label='Setosa')
>>> plt.scatter(X[50:100, 0], X[50:100, 1],
... color='blue', marker='s', label='Versicolor')
>>> plt.xlabel('Sepal length [cm]')
>>> plt.ylabel('Petal length [cm]')
>>> plt.legend(loc='upper left')
>>> plt.show()
执行完上述示例代码后,会生成如下的散点图:

图2.6:setosa和versicolor鸢尾花的花萼长度及花瓣长度散点图
图2.6沿纵轴和横轴展示了鸢尾花数据集中样本的分布:纵轴为花瓣长度,横轴为花萼长度(单位厘米)。在这个二维特征子空间中,我们可以看出线性决策边界足够区分出setosa和versicolor花了。因此可以使用感知机这样的线性分类器来对数据集中的花进行完美分类。
下面该对所提取的鸢尾花数据子集训练感知机算法了。我们还会绘制出每次迭代的错误分类,以检查算法是否收敛并找到区分两种鸢尾花类别的决策边界:
>>> ppn = Perceptron(eta=0.1, n_iter=10)
>>> ppn.fit(X, y)
>>> plt.plot(range(1, len(ppn.errors_) + 1),
... ppn.errors_, marker='o')
>>> plt.xlabel('Epochs')
>>> plt.ylabel('Number of updates')
>>> plt.show()
注意分类错误的数量与更新数量相同,因为感知机的权重和偏置在每次错误归类样本时都会进行更新。在执行以上代码后,读者应该会看到如图2.7所示的错误归类数对迭代次数的折线图:

图2.7:错误归类数对迭代次数的折线图
从图2.7中可以看出,在第6次迭代后我们的感知机收敛了,此时应该可以完美地对训练样本进行分类了。我们来实现一个函数对二维数据进行决策边界的可视化:
from matplotlib.colors import ListedColormap
def plot_decision_regions(X, y, classifier, resolution=0.02):
# setup marker generator and color map
markers = ('o', 's', '^', 'v', '<')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
# plot the decision surface
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
lab = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
lab = lab.reshape(xx1.shape)
plt.contourf(xx1, xx2, lab, alpha=0.3, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
# plot class examples
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0],
y=X[y == cl, 1],
alpha=0.8,
c=colors[idx],
marker=markers[idx],
label=f'Class {cl}',
edgecolor='black')
首先我们定义了一些colors和markers并通过ListedColormap创建一个颜色列表。然后我们确定两个特征的最大、最小值,使用这些特征向量通过NumPy的meshgrid函数创建一对栅格数组xx1和xx2。因为是在两个维度上训练感知机分类器,我们需要展平栅格数组、创建相同列数的矩阵为鸢尾花子集,这样就能使用predict方法预测对应栅格点的类标签lab。
在改变预测类标签lab,以xx1和xx2放入相同维度的栅格后,我们就可以通过Matplotlib的contourf函数画一个等高线图,将不同决策树使用不同颜色来对应栅格数组中的每个预测类:
>>> plot_decision_regions(X, y, classifier=ppn)
>>> plt.xlabel('Sepal length [cm]')
>>> plt.ylabel('Petal length [cm]')
>>> plt.legend(loc='upper left')
>>> plt.show()
执行以上示例代码,应该会看到如图2.8所示的决策区域图:

图2.8:感知机决策区域图
如图中所示,感知机学习了一个可对鸢尾花训练子集中样本进行完美分类的决策边界。
感知机收敛
虽然感知机对两种鸢尾花进行了很好的分类,收敛仍是感知机的最大问题之一。Rosenblatt从数学上证明了如果两个类可通过线性超平面分割,感知机学习规则就会收敛。但是,如果类别不能由线性决策边界完全分开,权重在没有设置最大迭代次数时就会不停地进行更新。感兴趣的读者可以阅读作者在授课笔记中所做的证明总结https://sebastianraschka.com/pdf/lecture-notes/stat453ss21/L03_perceptron_slides.pdf。
自适应线性神经元及学习的收敛
本小节中我们会学习另一类型的单层神经网络(NN):自适应线性神经元(ADAptive LInear NEuron (Adaline))。Adaline由Bernard Widrow同其博士学生Tedd Hoff在Rosenblatt发表感知机算法几年后发布,可将其看成是对后者的改进(An Adaptive “Adaline” Neuron Using Chemical “Memistors” , Technical Report Number 1553-2 by B. Widrow and colleagues, Stanford Electron Labs, Stanford, CA, October 1960)。
自适应线性神经元算法有趣之处在于它描绘了定义和最小化连续损失函数的概念。对理解其它分类机器学习算法提供了基础,比如逻辑回归、支持向量机和多层神经网络,以及我们在后面章节中会讨论的线性回归模型。
Adaline学习规则(也称为Widrow-Hoff学习规则)与Rosenblatt的感知机主要的分别是权重根据线性激活函数而不是感知机这样的单位阶跃函数进行更新。在Adaline中,线性激活函数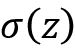 只是净输入的一个恒等函数(identity function),因此
只是净输入的一个恒等函数(identity function),因此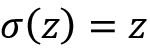 。
。
虽然线性激活函数用于学习权重,我们仍使用阈值函数来做最终决策,这与前面所讨论的单位阶跃函数相类似。
感知机和Adaline算法最主要的区别在图2.9中进行了标注:
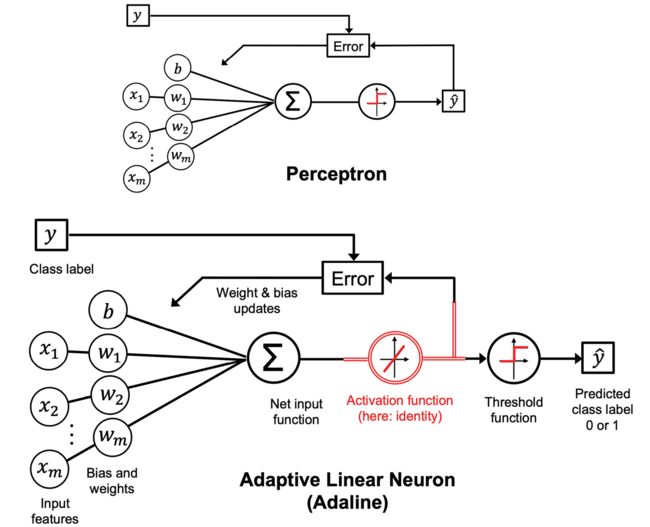
图2.9:感知机和自适应线性神经元算法的对比
在图2.9中可以看出,Adaline算法将真实类标签与线性激活函数的连续值输出对比计算模型错误并更新权重。而大型机使用真实类标签与预测的类标签进行对比。
使用梯度下降最小化损失函数
监督机器学习算法的一个主要组成是所定义的在学习过程中不断优化的目标函数。目标函数通常是我们希望最小化的损失函数或成本函数。对于Adaline算法而言,我们可以定义损失函数L,来以计算结果和真实类标签的平均方差(MSE)学习模型参数:

该连续线性激活函数相对于单位阶跃函数的主要优势是损失函数可微分的。损失函数的另一个优秀属性是它是凸函数,因此我们可以非常简单但强大的优化算法梯度下降来找到最小化损失函数的权重,对鸢尾花数据集中的样式进行分类。
如图2.10中所示,我们可以将梯度下降的主体思想描述为下山,直至抵达本地或全局损失最小值。在每次迭代中,我们沿倾斜的相反方向走一步,步长由学习率的值以及梯度决定(为简化起见,下图只使用了一个权重w):
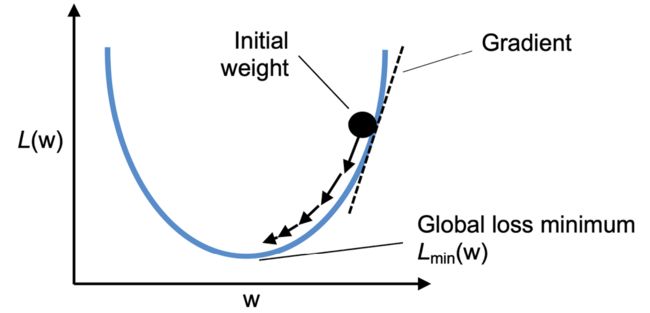
图2.10:梯度下降的原理
使用梯度下降,现在我们可以沿斜坡相反方向一步步更新模型参数 或损失函数L(w, b):
或损失函数L(w, b):
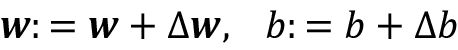
参数变化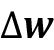 和
和![]() 由负梯度乘上学习率
由负梯度乘上学习率![]() :
:

要计算损失函数的梯度,我们需要计算损失函数与各个权重wj的偏导数:
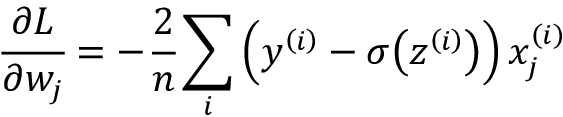
类似地,我们计算损失与偏置的偏导数:

请注意上面分母中的2中是一个恒定比例因子,我们可以省略掉也不影响算法。删除比例因子与按2倍数修改学习率等效。下面会讲解比例因子的来源。
我们可以将权重更新写为:
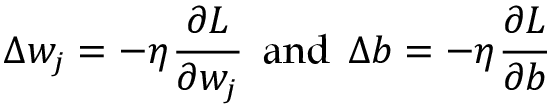
因为我们同步更新了所有参数,Adaline学习规则便变成了:
![]()
均方根误差导数
熟悉微积分的读者会知道,MSE(均方根)损失函数对第j个权重的偏导数可通过如下方式求取:
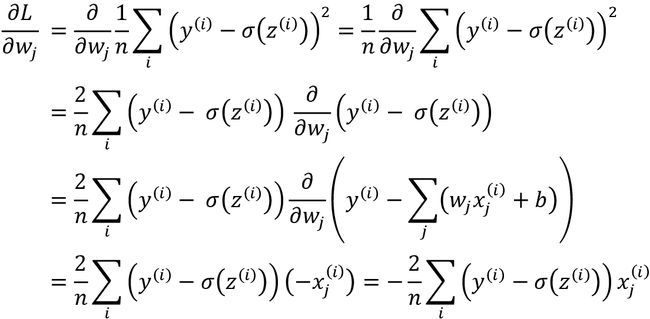
可使用同样的方式未取![]() 的偏导数,只是
的偏导数,只是 等于-1,因此最后一步可简化为
等于-1,因此最后一步可简化为 。
。
虽然Adaline学习规则和感知机规则看起来一样,应该注意是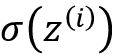 一个真实数字而不是一个整型类标签,其中
一个真实数字而不是一个整型类标签,其中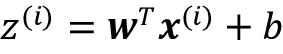 。此外,权重更新根据训练数据集中的所有样本进行计算(而不是在每个训练样本后增量更新参数),这也是为什么这种方法也被称为批量梯度下降。为更加明确以及在本章和本书稍后讨论相关概念时避免混淆,我们会将这一过程称为全批量梯度下降。
。此外,权重更新根据训练数据集中的所有样本进行计算(而不是在每个训练样本后增量更新参数),这也是为什么这种方法也被称为批量梯度下降。为更加明确以及在本章和本书稍后讨论相关概念时避免混淆,我们会将这一过程称为全批量梯度下降。
使用Python实现Adaline算法
因为感知机学习规则和Adaline学习规则非常相似,我们会取之前定义的感知机实现,修改其中的fit方法以使用权重和偏置参数按梯度下降的最小化损失函数更新:
class AdalineGD:
"""ADAptive LInear NEuron classifier.
Parameters
------------
eta : float
Learning rate (between 0.0 and 1.0)
n_iter : int
Passes over the training dataset.
random_state : int
Random number generator seed for random weight initialization.
Attributes
-----------
w_ : 1d-array
Weights after fitting.
b_ : Scalar
Bias unit after fitting.
losses_ : list
Mean squared error loss function values in each epoch.
"""
def __init__(self, eta=0.01, n_iter=50, random_state=1):
self.eta = eta
self.n_iter = n_iter
self.random_state = random_state
def fit(self, X, y):
""" Fit training data.
Parameters
----------
X : {array-like}, shape = [n_examples, n_features]
Training vectors, where n_examples
is the number of examples and
n_features is the number of features.
y : array-like, shape = [n_examples]
Target values.
Returns
-------
self : object
"""
rgen = np.random.RandomState(self.random_state)
self.w_ = rgen.normal(loc=0.0, scale=0.01,
size=X.shape[1])
self.b_ = np.float_(0.)
self.losses_ = []
for i in range(self.n_iter):
net_input = self.net_input(X)
output = self.activation(net_input)
errors = (y - output)
self.w_ += self.eta * 2.0 * X.T.dot(errors) / X.shape[0]
self.b_ += self.eta * 2.0 * errors.mean()
loss = (errors**2).mean()
self.losses_.append(loss)
return self
def net_input(self, X):
"""Calculate net input"""
return np.dot(X, self.w_) + self.b_
def activation(self, X):
"""Compute linear activation"""
return X
def predict(self, X):
"""Return class label after unit step"""
return np.where(self.activation(self.net_input(X))
>= 0.5, 1, 0)
不像感知机中在每个训练样本评估后更新权重,这里我们根据整个训练数据集计算梯度。对于偏置单元,通过self.eta * 2.0 * errors.mean()计算,其中errors是包含偏导数值![]() 的数组。类似地,我们会更新权重。但注意根据偏导数
的数组。类似地,我们会更新权重。但注意根据偏导数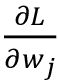 更新权重时涉及到特征值xj,可通过将
更新权重时涉及到特征值xj,可通过将errors乘上每个权重的特征值来计算:
for w_j in range(self.w_.shape[0]):
self.w_[w_j] += self.eta *
(2.0 * (X[:, w_j]*errors)).mean()
要不通过for循环更高效地实现权重更新,我们可以使用特征矩阵和错误向量的矩阵-向量乘法:
self.w_ += self.eta * 2.0 * X.T.dot(errors) / X.shape[0]
请注意activation方法对代码没有效果,因为它只是一个恒等函数。这里我们添加了激活函数(通过activation方法计算)来描述信息如何在单层神经网络中流动的整体概念:来自输入数据的特征、净输入、激活和输出。
下一章中,我们会学习逻辑回归分类器,它使用非恒等、非线性激活函数。我们会发现逻辑回归模型与自适应线性神经元紧密相关,唯一的不同是其激活函数和损失函数。
现在,类似前面的感知机实现,我们将损失值收集到一个self.losses_列表中用于检查在训练后算法是否收敛。
矩阵乘法
执行矩阵乘法类似于计算向量的点乘,矩阵中的每一行都会看成一个单行向量。这一向量化法表现为更简洁的符号并产生了使用NumPy的更高效运算。例如:

注意在上面的等式中,我们用矩阵乘上向量,在数学上并未进行定义。但请记住我们约定过前面的向量会被当成一个3×1矩阵。
实践中,常常要求进行多次实验才能找到对应最佳收敛的学习率![]() 。因此我们先选择两个学习率
。因此我们先选择两个学习率 和
和 ,使用损失函数和迭代次数绘图查看Adaline实现对训练数据学习的效果。
,使用损失函数和迭代次数绘图查看Adaline实现对训练数据学习的效果。
超参数
学习率![]() (
(eta)以及迭代次数(n_iter),也被称作感知机和Adaline学习算法的超参数(或调优参数)。在第6章 学习模型评估和超参数调优的最佳实践中,我们会学习各种技术自动查找产生分类模型最优表现的不同超参数值。
下面绘制两种学习率的损失对迭代次数的图像:
>>> fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(10, 4))
>>> ada1 = AdalineGD(n_iter=15, eta=0.1).fit(X, y)
>>> ax[0].plot(range(1, len(ada1.losses_) + 1),
... np.log10(ada1.losses_), marker='o')
>>> ax[0].set_xlabel('Epochs')
>>> ax[0].set_ylabel('log(Mean squared error)')
>>> ax[0].set_title('Adaline - Learning rate 0.1')
>>> ada2 = AdalineGD(n_iter=15, eta=0.0001).fit(X, y)
>>> ax[1].plot(range(1, len(ada2.losses_) + 1),
... ada2.losses_, marker='o')
>>> ax[1].set_xlabel('Epochs')
>>> ax[1].set_ylabel('Mean squared error')
>>> ax[1].set_title('Adaline - Learning rate 0.0001')
>>> plt.show()
从最终的损失函数图中可以看出,我们遇到了两种类型的问题。左图显示了选择了过大的学习率时的情况。它没有最小化损失函数,而是每次迭代均方误差都在变大,因为超过全局最小值。而另一边,我们可以看到右图的损失在下降,但所选的学习率 太小了,算法需要经过大量的迭代才能收敛至全局最小损失:
太小了,算法需要经过大量的迭代才能收敛至全局最小损失:

图2.11:次优学习率的误差图
图2.12描绘了如果修改具体的权重参数值来最小化损失函数L会发生什么。左图为精选学习率的示例,其中损失递减,沿全局最小值的方向移动。
而右图描绘了如果选择的学习率过大,会超过全局最小值:
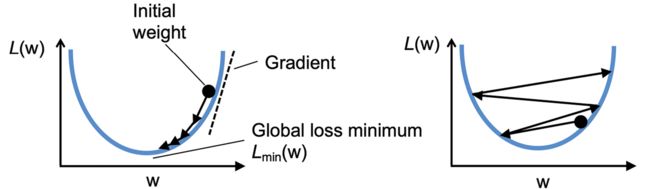
图2.12:精选学习率和学习率过大的对比
通过特征缩放改进梯度下降
我们在全书遇到的很多机器学习算法会需要某种程度的特征缩放以实现最佳效果,这会在第3章 使用Scikit-Learn的机器学习分类器之旅和第4章 构建优秀训练数据集 - 数据预处理中进行详细讨论。
梯度下降是受益于特征缩放的多种算法之一。本小节中,我们会使用称为标准化(standardization)的特征缩放方法。这种归一化处理有助于让梯度下降学习更快速地收敛,但不会让原数据集正态分布。归一化平衡每个特征的均值,让其中心点为零并且每个特征的标准差为1(单位方差)。例如,要归一化第j个特征,可以对每个训练样本减去样式均值![]() 并除以标准差
并除以标准差![]() :
:
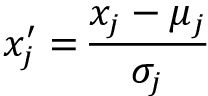
这里xj是包含所有训练样式n第j个特征值的向量,这一标准化技术应用于数据集中的每个特征j。
标准化有助于梯度下降学习的原因之一是它更易于找到对所有权重(及偏置)可良好运作的学习率。如果特征规模很大,可很好更新一个权重的学习率可能对于更新另一个权重就会太大或太小。总的来说,使用标准化的特征可使用训练稳定,这样优化器可经过更少的步骤找到一个好的或最佳解法(全局损失最小)。图2.13描述了未缩放特征(左)和标准化特征(右)可能出现的梯度更新,其中的同心圆表示二维分类问题中两个模型权重函数的损失表面:

图2.13:对比未缩放和标准化特征的梯度更新
标准化可通过NumPy内置的mean和std方法轻松实现:
>>> X_std = np.copy(X)
>>> X_std[:,0] = (X[:,0] - X[:,0].mean()) / X[:,0].std()
>>> X_std[:,1] = (X[:,1] - X[:,1].mean()) / X[:,1].std()
在进行标准化后,我们会再次训练Adaline并看到使用学习率 它会经过很少的迭代就收敛:
它会经过很少的迭代就收敛:
>>> ada_gd = AdalineGD(n_iter=20, eta=0.5)
>>> ada_gd.fit(X_std, y)
>>> plot_decision_regions(X_std, y, classifier=ada_gd)
>>> plt.title('Adaline - Gradient descent')
>>> plt.xlabel('Sepal length [standardized]')
>>> plt.ylabel('Petal length [standardized]')
>>> plt.legend(loc='upper left')
>>> plt.tight_layout()
>>> plt.show()
>>> plt.plot(range(1, len(ada_gd.losses_) + 1),
... ada_gd.losses_, marker='o')
>>> plt.xlabel('Epochs')
>>> plt.ylabel('Mean squared error')
>>> plt.tight_layout()
>>> plt.show()
执行这段代码,应该会看到一个决策区域图,以及一个损失下降图,如图2.14:
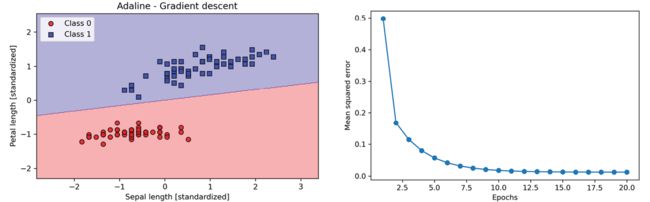
图2.14:Adaline的决策区域及均方差对迭代次数图
从图中可以看出,在通过标准化特征训练后现在Adaline收敛了。但注意虽然所有的样本花分类正确均方差仍不是零。
大规模机器学习和随机梯度下降
在前一小节中,我们学习了如何通过整体训练数据集计算损失梯度相反方向的步骤最小化损失函数,这也是这种方法有时也称作全批量梯度下降的原因。现在想象下我们有几百万数据点的超大数据集,在机器学习应用中这并不罕见。运行全批量梯度下降在这种场景下计算开销很大,因为每朝全局最小走一步就需要重新运算整个训练数据集。
全批量梯度下降一个著名的替代是随机梯度下降(SGD),有时也称为迭代或在线梯度下降。它不是根据全部训练样本x(i)的累积误差总和更新权重:

而是对每个训练样本增量更新参数,比如:

虽然可将SGD看作与梯度下降类似,但通常因更高频次的权重更新它更可以更快速地收敛。因为每个梯度按单个样式计算,其误差面比梯度下降中的噪音更大,在使用非线性损失函数时也就让SGD提前具备了逃脱浅层全局最小值的优势,这在第11章 从零实现多层人工神经网络中会学习到。为通过随机梯度下降获取满意的结果,以随机顺序提供训练数据很重要,同时,我们最好在每次迭代时打乱训练数据集以避免循环。
在训练期间调整学习率
在SGD中,固定的学习率
,通常由随时间下降的自适应学习率替换,例如:
其中c1和c2是常量。注意SGD没有到达全局损失最小值,而是一个非常接近它的区域。并且使用自适应学习率,我们会更接近损失最小值。

SGD的另一个优势是可用于在线学习。在线学习时,新训练数据一到达就实时训练模型。这对于累积大量数据时尤为有用,比如web应用的客户数据。使用在线数据,系统可立即应对变化,并且在存储空间不足时更新完模型就可以删除训练数据。
mini-batch梯度下降
在全批量梯度下降和SGD之间的一个折中称为mini-batch梯度下降。mini-batch梯度下降理解为将全批量梯度下降应用于更小的训练数据子集,比如每次32个训练样本。mini-batch相对全批量梯度下降的优势是收敛更局长,因为权重更新的更频繁。此外mini-batch学习让我们可以将随机梯度下降中的
for循环换成使用线性代数概念的向量化运算(比如通过点乘实现加权和),这可以进一步提升学习算法的计算效率。
我们已经使用梯度下降实现了Adaline学习规则,只需要做很少的就修改就可以通过SGD更新权重。在fit方法中,现在我们在每个训练样本后都会更新权重。此外,我们还会实现一个partial_fit方法,对于在线学习它不会重新初始化权重。为了检查训练后该算法是否收敛,我们会在每次迭代中以训练样本的平均损失计算损失。并且我们会添加一个在每次迭代前打乱训练数据的选项,以避免优化损失函数时的反复循环;通过random_state参数,可以指定用于保障可复现随机种子:
class AdalineSGD:
"""ADAptive LInear NEuron classifier.
Parameters
------------
eta : float
Learning rate (between 0.0 and 1.0)
n_iter : int
Passes over the training dataset.
shuffle : bool (default: True)
Shuffles training data every epoch if True to prevent
cycles.
random_state : int
Random number generator seed for random weight
initialization.
Attributes
-----------
w_ : 1d-array
Weights after fitting.
b_ : Scalar
Bias unit after fitting.
losses_ : list
Mean squared error loss function value averaged over all
training examples in each epoch.
"""
def __init__(self, eta=0.01, n_iter=10,
shuffle=True, random_state=None):
self.eta = eta
self.n_iter = n_iter
self.w_initialized = False
self.shuffle = shuffle
self.random_state = random_state
def fit(self, X, y):
""" Fit training data.
Parameters
----------
X : {array-like}, shape = [n_examples, n_features]
Training vectors, where n_examples is the number of
examples and n_features is the number of features.
y : array-like, shape = [n_examples]
Target values.
Returns
-------
self : object
"""
self._initialize_weights(X.shape[1])
self.losses_ = []
for i in range(self.n_iter):
if self.shuffle:
X, y = self._shuffle(X, y)
losses = []
for xi, target in zip(X, y):
losses.append(self._update_weights(xi, target))
avg_loss = np.mean(losses)
self.losses_.append(avg_loss)
return self
def partial_fit(self, X, y):
"""Fit training data without reinitializing the weights"""
if not self.w_initialized:
self._initialize_weights(X.shape[1])
if y.ravel().shape[0] > 1:
for xi, target in zip(X, y):
self._update_weights(xi, target)
else:
self._update_weights(X, y)
return self
def _shuffle(self, X, y):
"""Shuffle training data"""
r = self.rgen.permutation(len(y))
return X[r], y[r]
def _initialize_weights(self, m):
"""Initialize weights to small random numbers"""
self.rgen = np.random.RandomState(self.random_state)
self.w_ = self.rgen.normal(loc=0.0, scale=0.01,
size=m)
self.b_ = np.float_(0.)
self.w_initialized = True
def _update_weights(self, xi, target):
"""Apply Adaline learning rule to update the weights"""
output = self.activation(self.net_input(xi))
error = (target - output)
self.w_ += self.eta * 2.0 * xi * (error)
self.b_ += self.eta * 2.0 * error
loss = error**2
return loss
def net_input(self, X):
"""Calculate net input"""
return np.dot(X, self.w_) + self.b_
def activation(self, X):
"""Compute linear activation"""
return X
def predict(self, X):
"""Return class label after unit step"""
return np.where(self.activation(self.net_input(X))
>= 0.5, 1, 0)
现在我们在AdalineSGD分类器中使用的_shuffle方法运行方式如下:通过np.random中的permutation函数,我们生成了0到100范围内唯一数的随机序列。然后可使用这些数字作为索引打乱特征矩阵和类标签向量。
之后我们可以使用fit方法训练AdalineSGD分类器,并使用plot_decision_regions来绘训练结果:
>>> ada_sgd = AdalineSGD(n_iter=15, eta=0.01, random_state=1)
>>> ada_sgd.fit(X_std, y)
>>> plot_decision_regions(X_std, y, classifier=ada_sgd)
>>> plt.title('Adaline - Stochastic gradient descent')
>>> plt.xlabel('Sepal length [standardized]')
>>> plt.ylabel('Petal length [standardized]')
>>> plt.legend(loc='upper left')
>>> plt.tight_layout()
>>> plt.show()
>>> plt.plot(range(1, len(ada_sgd.losses_) + 1), ada_sgd.losses_,
... marker='o')
>>> plt.xlabel('Epochs')
>>> plt.ylabel('Average loss')
>>> plt.tight_layout()
>>> plt.show()
执行示例代码后我们获取的两张图如图2.15:
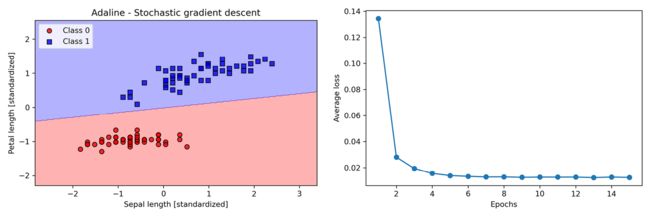
图2.15:使用SGD训练Adaline模型后的决策区域和平均损失图
可以看到,平均损失下降很快,15次迭代后的最终决策边界与批量梯度下降Adaline很类似。举个例子,如果希望使用在线学习场景的流数据更新我们的模型,只需对单独的训练样本调用partial_fit方法,如ada_sgd.partial_fit(X_std[0, :], y[0])。
小结
本章中,我们很好地掌握了监督学习线性分类器的基本概念。在实现了感知机后,我们学习了如何通过梯度下降的向量化实现有效实现自适应线性神经元以及通过SGD实现在线学习。
读者已经学习了如何使用Python实现简单分类器,可以进入下一章的学习了,在其中我们会使用Python的scikit-learn机器学习库来实现更高级、更强大的机器学习分类器,在学术界和工业界都经常使用到。
我们用于实现感知机和Adaline算法的面向对象方法也会有助于对scikit-learn API的学习,其实现同样基于本章中所使用的核心概念:fit和predict方法。根据这些核心概念,我们会学习类概率的逻辑回归建模以及可用于非线性决策边界的支持向量机。此外,我们还会介绍另一种监督学习算法,基于树的算法,常常并入健壮的集成分类器(ensemble classifiers)。