知识库问题生成(KBQG)技术介绍
作者:陈佳敏、漆桂林、程茜雅、毕胜
1. KBQG背景介绍
问题生成(Question Generation,QG)任务根据给定的事实输入和答案,生成自然语言表述的问题。问题生成可以为QA任务产生训练数据[1];在对话系统中实现主动提问提升对话的流畅性[2];自动合成 FAQ 文档[3]、自动辅导系统(automatic tutoring systems)[4]。一般问题生成研究的事实输入都是文本,而根据输入的不同也衍生了其他任务,如输入知识库(KBQG)、图像(VQG)。
KBQG(Question Generation over Knowledge Base)与一般QG任务主要区别在于输入从知识库来的事实一般以三元组
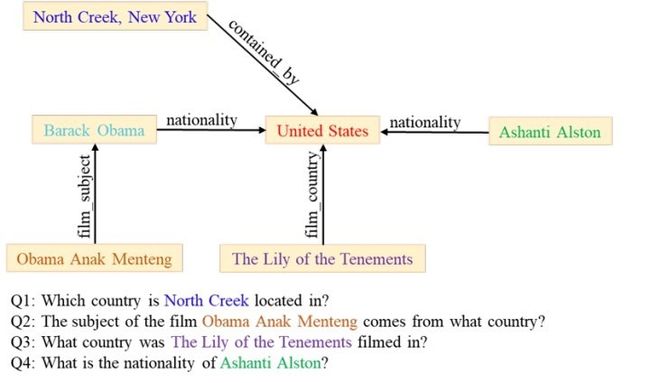
图1:KBQG任务示意
KBQG对比一般QG任务,因为输入的事实是三元组格式,包含的信息过少,如何扩充输入事实信息,更好的支撑中问题生成过程是KBQG的一个主要难点和研究点,具体就是从知识库中额外获取信息的选择,获取后如何处理,在模型中的使用方式;QG任务中,问题提及(如上例中的“美国”)在训练数据中一般是没有出现,也就是OOV(Out Of Vocabulary),因此很难有效对这部分输入进行编码,也就难以在问题中生成这部分信息,在一般基于文本的QG方法中可能采用copy机制缓解这个问题,而在KBQG中可以有效利用在现有的领域KG训练的graph embedding作为实体的表示,同样可以有效解决OOV问题;KBQG区别于一般QG的另一个地方在于KBQG中涉及对复杂问题的研究,在基于文本的QG中同样有关于复杂问题的研究,如《Low-Resource Generation of Multi-hop Reasoning Questions》[5],但是在KBQG中利用三元组链构成图来定义问题复杂性,跟基于文本的QG的问题复杂性定义有较大差异。
2. 评估
KQBG作为文本生成的一个子任务,模型效果一般采用自动评测和人工评测两种方式进行评估。自动评测普遍使用的是bleu,rouge,meteor,最近也有结合BERT进行评估的方法BERTSCORE[6]。针对问题生成任务场景,有研究从问题的可回答性进行评估[7]。
人工评测就比较主观,可以针对性的自定义指标,使用比较多的是从生成问题的流畅性、完整性、可阅读性、可回答性、多样性等角度进行评估。
3. 方法
传统的KBQG方法
目前KBQG研究使用的几个数据集WebQuestions、SimpleQuestions、LC-QuAD、PathQuestion和WebQuestionSP都是通过使用规则、模板和人工标注等方式实现。
Jonathan et al. [8] 借助搜索引擎和人工标注完成数据集WebQuestions的构建。通过谷歌API可以获取由wh开头并包含一个实体的问题,从一个问题开始,然后使用谷歌API查询该问题去除实体部分、实体之前部分和实体之后部分,每个查询得到5个候选问题加到队列中,如此反复进行得到100万问题集,最后将其中一小部分筛选后问题交由AMT回答得到最终问答对。
WebQuestions存在数据规模小,无法全面覆盖使用Freebase之类的知识库可以回答的各种问题,Antoine et al. [9] 提出了SimpleQuestions数据集,对FB2M事实三元组数据[10]进行筛选,然后对每个三元组(subject, predicate, object)人工标注问题,使得该问题与三元组的subject和predicate相关,并以object为答案。
完全依靠人工标注问题过于消耗人力物力,而且这些数据集都是简单问题,更复杂问题的生成通过人工标注难以形成一定规模。Priyansh et al. [11] 通过模板结合人工修正实现复杂问题数据集LC-QuAD的构建。如图2所示,从候选种子实体集合中选择一个实体,然后在DBpedia中查询得到子图,然后结合SPARQL模板和实际子图,对模板进行实例化,得到SPARQL查询语句,然后将该查询语句转换成自然语言表述问题,再通过人工对问题语法错误、语序不当等问题进行修正,得到最终的问答对。而Alon et al. [12] 则是在WebQuestionSP [13] 的基础上,构建包含复杂算子如连接、最值求解和比较等情况的SPARQL查询及答案,通过模板转化成自然语言问题,再通过人工改写得到最终数据集ComplexWebQuestions。
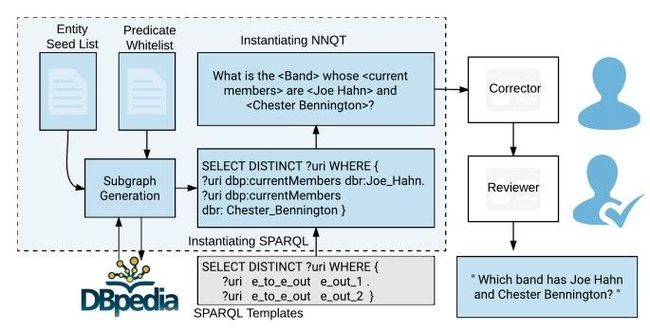
图2:LC-QuAD数据集构建流程
基于深度学习的KBQG方法
随着深度学习技术的发展,结合深度学习的KBQG方法也得到大家的关注,特别是encoder-decoder框架运用于如机器翻译、摘要生成等文本生成任务的成功,给使用深度学习方法实现KBQG带来了很多思路。
Sathish et al. [14] 提出K2Q-RNN模型实现简单问题的生成,对给定三元组{subject, predicate, object},在知识库中查询得到subject的领域和object的范围,将这两个属性与三元组去掉答案object后拼接成一个序列作为模型的输入,模型部分参照Bahdanau et al. [15] 实现。
Elsahar et al. [16] 尝试解决零样本的问题,如图三所示,除了输入三元组(fact encoder)外额外引入上下文信息(context encoder),subject和object的上下文是它们在知识库中的类型信息,而谓语的上下文为在Wikipedia中同时出现subject和object的句子,对这些句子和问题进行词性标注,如此当测试数据中出现训练数据中不存在的零样本数据时,虽然类型是零样本情况,但是它的句法分布信息却能够被训练数据覆盖,同样能生成较好的结果。
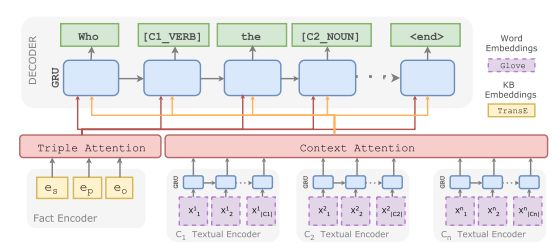
图3:Zero-shot Question Generation模型图
Wang et al. [17] 如图4所示,对三元组进行词性标注,同时添加
图4:Wang et al. 模型
Liu el al. [18] 研究如何保证生成问题和给定三元组谓语相关,并且生成问题具有的答案和给定的一致。实现如图5所示,使用比较火的transformer取代RNN,此外在知识库中获取实体的主题、领域、范围等信息作为分别作为subject、object、predicate的上下文信息,设计独立的encoder编码上下文信息,结合三元组自身信息和知识库的上下文信息提升模型的效果,添加问题与给定答案的answer损失保证生成问题答案与给定的一致性。
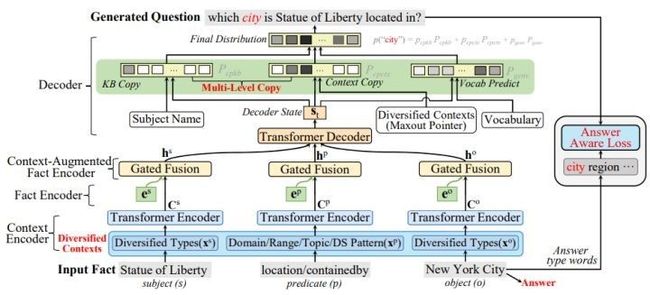
图5 Liu el al.模型
4. 最新工作介绍
下面介绍我们实验室最新发表在COLING2020的一篇与KBQG相关的文章《Knowledge-enriched, Type-constrained and Grammar-guided Question Generation over Knowledge Bases》[19]。
传统的KBQG方法都是基于编码器-解码器模型实现的,但是这些方法目前仍然存在两个主要的挑战,特别是在较小的子图上:(1)由于子图中只有几个三元组,包含的信息有限,导致生成的问题不够流畅,并且单一、缺乏多样性;如图7所示,给定了两个三元组,生成的问题Q1仅仅包含了给定的三元组中的实体和关系,而没有其他的信息,十分单一。反观问题Q2和Q3,融入了对实体“LeBorn James”的描述 “the American basketball player”,使得问题信息更加丰富,更易于理解。(2)由于解码器忽略了答案实体的语义信息,导致语义漂移。例如图7中的问题Q2,疑问词是提问时间的“when”,而答案是地点名词“Ohio”,应该用“where”提问,所以Q2存在语义漂移,Q3不存在。因此,为了解决这两个挑战,生成类似于Q3这种不仅包含丰富的信息,而且疑问词与答案的语义类型相匹配的问题,我们这篇文章提出了一种基于知识扩充、类型限制和语法指导的KBQG模型,简称KTG。
该文章虽然同样采用了encoder-decoder框架来实现KBQG,但是从encoder、decoder、模型训练三个部分进行了一定的创新。具体的实现思路如图6所示:

图6 KTG模型
例如,对于图7中的例子,在encoder端,对于输入的三元组,实体从知识库中查询得到其对应domain和description,比如对于实体“LeBorn James”就可以得到该实体domain为“person”,description是“the American basketball player”,加上本身embedding(图6左下label),三部分使实体的编码Knowledge-enriched。对于关系,并没有简单的当做一个标签,而是有些利用知识库值对关系层级划分信息,使用一定方法进行编码。


图7 KBQG例子
而Type-constrained是指在生成问题的过程中,在每一个时间步预测词语的时候先预测词语的类型:疑问词,实体词,关系词和其他普通词,重点是疑问词,会根据encoder端输入的给定答案的domain来确定。如这里答案是“Ohio”是一个地点,则疑问词生成Where。
Grammar-guided是指在模型训练的过程中,使用强化学习,并没有采用以往的Bleu、Rouge这些分数作为Reward,这些会使生成的问题与标准在n-gram层次一致,而本文参考DPT使用类似计算文本相似度作为Reward,兼顾生成问题grammar层次的准确性,生成问题的多样性更加丰富。
下面是模型各部分具体实现;
- Encoder端:在KBQG任务中主要的难点在于如何有效利用仅有的几个三元组信息来来得更多有效的信息提升问题生成效果,在这篇文章中,对于实体,引入知识库信息中实体的领域、描述等额外信息进行编码,加上自身的embedding信息,三部分拼接。对于关系,发现数据中不同实体之间的关系具有层级关系,借助Tree-LSTM[20]对关系进行编码,而不同与以往的工作,并没有深入挖掘不同关系之间的联系。
- Decoder端:问题生成核心的三部分:实体、关系、疑问词;其中疑问词本文根据encoder端得到的答案类型进行生成,其他的参考《Learning to ask questions in open-domain conversational systems with typed decoders》[21]的思路,使用type decoder限制生成过程。此外,使用有条件的copy机制,允许模型根据当前单词的类型,从不同的输入源中copy内容,如果是实体类型,就从实体源中copy,如果是关系类型,就从关系源中copy,其他类型就从词汇表中直接生成。
- 模型训练:使用强化学习,不同于以往大部分文本生成工作会使用Bleu、rouge作为reward,这些方法会使模型生成在n-gram与标准相同的问句,但并不能有效提升生成问题的多样性。本文使用DPT[22]计算生成问题和标准问题的句法依存树的相似性,来帮助模型生成与标准问句相似的问句,确保生成问句在句法正确的同时具有多样性。
试验部分选择了数据集SimpleQuestion和PathQuestion。为了获得辅助信息,本文对数据集进行了处理,将输入子图中的实体和关系链接到开放知识库Wikidata中,获得相应的实体description和domain信息,以及关系的层级信息。特别的,SimpleQuestion中的实体均由对应的Freebase ID表示,因此论文首先将Freebase ID映射到Wikidata ID,然后根据Wikidata ID获得辅助信息。而PathQuestion直接包含了词汇化的实体和关系,可以直接关联辅助信息。最后,我们将实体的description信息添加进问题中,扩充问题。
试验结果图8和图9所示:
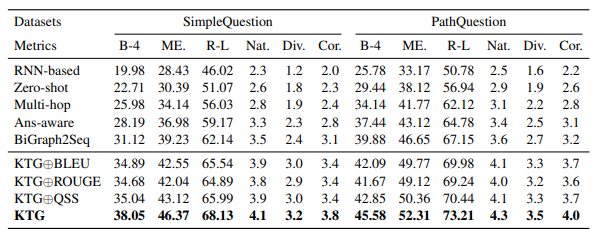
图8
同时论文还分析了不同模型使用的不同部分引入对模型效果的影响,结果如图9:
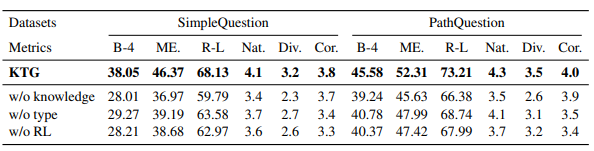
图9
可以分析出引入知识库信息对效果的提升最大,而引入类型限制的帮助最小。
小结:
这篇论文有效利用KB和关系层级关系,在encoder端编码更多有用信息,decoder端对生成词语类型进行限制,确保疑问词以及整体语法正确性,设计基于DPT的文本相似度方法作为reward进行强化学习训练,又保证生成问题的多样性。这篇文章设计方法一定程度上解决了问题生成存在的疑问词难以准确生成、问题提及实体无法准确生成、多样性较低等问题,都是KBQG领域大家比较关注的研究点。这篇文章是为了提升生成问题的多样性和语义准确性,同时生成的高质量问题也可以用来训练QA模型,提升效果。因此,在未来的研究中,我们会使用这篇文章所提的方法生成新的数据集,训练QA模型,从而验证该方法对QA模型是否有提升的效果。
KBQG中还有比较新的工作有关于复杂问题的研究。复杂问题生成是问题生成任务更高层次的一个研究点,基于文本的QG任务中,比较难以对问题的复杂性进行一个合理定义,并在对输入事实文本编码中有效挖掘这部分信息,研究比较少。而在KB领域,问题的复杂性可以通包含三元组的个数,问题提及与答案之间经过的关系跳数、答案和提及的流行度等方式来度量,比如我们实验室的一个工作《Difficulty-controllable multi-hop question generation from knowledge graphs》[23]。另外一点,复杂问题场景输入的三元组具有多个,它们之间具有的拓扑结构信息蕴含难度信息,《Toward Subgraph Guided Knowledge Graph Question Generation with Graph Neural Networks》[24]研究使用图神经网络方面的技术帮助更有效的对输入三元组进行编码,在复杂问题生成场景也具有重要意义。
5. 总结
KBQG作为文本生成、问题生成的一个子任务,有很多研究思路是从这些任务的工作中来的,如文本生成中的copy机制能帮助提升问题中提及实体生成的效果,问题生成中的Type-decoder帮助在KBQG中更有效的生成疑问词,利用KBQG中KB的优势,获取更多额外的知识库信息帮助提升编码效果,使用GCN实现输入事实子图更有效的编码。目前KBQG的研究难点包括文本生成中普遍的多样性问题以及在KB领域涉及的问题复杂性问题。
参考文献
[1] Duan N, Tang D, Chen P, et al. Question generation for question answering[C]//Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. 2017: 866-874.
[2] Lee, Che-Hao, et al. Automatic question generation from Children’s stories for companion Chatbot. 2018 IEEE International Conference on Information Reuse and Integration (IRI). IEEE, 2018.
[3] Mass Y, Carmeli B, Roitman H, et al. Unsupervised FAQ retrieval with question generation and BERT[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020: 807-812.
[4] Heilman M, Smith N A. Good question! statistical ranking for question generation[C]//Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics. Association for Computational Linguistics, 2010: 609-617.
[5]Yu J, Liu W, Qiu S, et al. Low-Resource Generation of Multi-hop Reasoning Questions[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020: 6729-6739.
[6] Zhang T, Kishore V, Wu F, et al. Bertscore: Evaluating text generation with bert[J]. arXiv preprint arXiv:1904.09675, 2019.
[7] Nema P, Khapra M M. Towards a better metric for evaluating question generation systems[J]. arXiv preprint arXiv:1808.10192, 2018.
[8] Berant J, Chou A, Frostig R, et al. Semantic parsing on freebase from question-answer pairs[C]//Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. 2013: 1533-1544.
[9] Bordes A, Usunier N, Chopra S, et al. Large-scale simple question answering with memory networks[J]. arXiv preprint arXiv:1506.02075, 2015.
[10] Bordes A, Chopra S, Weston J. Question answering with subgraph embeddings. arXiv: 1406.3676, 2014[J]. 2017.
[11] Trivedi P, Maheshwari G, Dubey M, et al. Lc-quad: A corpus for complex question answering over knowledge graphs[C]//International Semantic Web Conference. Springer, Cham, 2017: 210-218.
[12] Talmor A, Berant J. The web as a knowledge-base for answering complex questions[J]. arXiv preprint arXiv:1803.06643, 2018.
[13] Yih W, Richardson M, Meek C, et al. The value of semantic parse labeling for knowledge base question answering[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2016: 201-206.
[14] Reddy S, Raghu D, Khapra M M, et al. Generating natural language question-answer pairs from a knowledge graph using a rnn based question generation model[C]// CCF International Conference on Natural Language Processing and Chinese Computing,Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers. 2017: 376-385.
[15] Kumar V, Hua Y, Ramakrishnan G, et al. Difficulty-controllable multi-hop question generation from knowledge graphs[C] International Semantic Web Conference. Springer, Cham, 2019: 382-398.
[16] Elsahar H, Gravier C, Laforest F. Zero-shot question generation from knowledge graphs for unseen predicates and entity types[J]. arXiv preprint arXiv:1802.06842, 2018.
[17] Wang H, Zhang X, Wang H. A Neural Question Generation System Based on Knowledge Base[C]//CCF International Conference on Natural Language Processing and Chinese Computing. Springer, Cham, 2018: 133-142.
[18] Liu C, Liu K, He S, et al. Generating Questions for Knowledge Bases via Incorporating Diversified Contexts and Answer-Aware Loss[J]. arXiv preprint arXiv:1910.13108, 2019.
[19] Bi S, Cheng X, Qi G, et al. Knowledge-enriched, Type-constrained and Grammar-guided Question Generation over Knowledge Bases[J]. arXiv e-prints, 2020: arXiv: 2010.03157.
[20] Kai Sheng Tai, Richard Socher, and Christopher D Manning. 2015. Improved semantic representations from tree-structured long short-term memory networks. Annual Meeting of the Association for Computational Linguistics, 2015, Beijing, China, pages 1556–1566.
[21]Wang Y, Liu C, Huang M, et al. Learning to ask questions in open-domain conversational systems with typed decoders[J]. arXiv preprint arXiv:1805.04843, 2018.
[22] Quan Z, Wang Z J, Le Y, et al. An efficient framework for sentence similarity modeling[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019, 27(4): 853-865.
[23]Vishwajeet Kumar, Yuncheng Hua, Ganesh Ramakrishnan, Guilin Qi, Lianli Gao, and Yuan-Fang Li. 2019a Difficulty-controllable multi-hop question generation from knowledge graphs. In International Semantic Web Conference, pages 382–398. Springer.
[24]Chen Y, Wu L, Zaki M J. Toward Subgraph Guided Knowledge Graph Question Generation with Graph Neural Networks[J]. arXiv preprint arXiv:2004.06015, 2020.