resnet残差网络
resnet这个网络感觉很熟悉又很陌生
ResNet简介
残差网络是由来自Microsoft Research的4位学者(华人之光)提出的卷积神经网络,在2015年的ImageNet大规模视觉识别竞赛(ImageNet Large Scale Visual Recognition Challenge, ILSVRC)中获得了图像分类和物体识别的优胜。 残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。原论文链接

梯度消失和梯度爆炸解释了为什么不是层数越多效果越好的这个问题!
假设每一层的梯度误差是一个小于1的数,每向前传播一层乘以一个小于1的数梯度会越来越小,这就是梯度消失。
同理每一层的梯度误差是一个大于1的数,每向前传播一层乘以一个大于1的数梯度会越来越大,这就是梯度爆炸。
目前针对这种现象已经有了解决的方法:对输入数据和中间层的数据进行归一化操作(化为0~1之间处理),这种方法可以保证网络在反向传播中采用随机梯度下降(SGD),从而让网络达到收敛。但是,这个方法仅对几十层的网络有用,当网络再往深处走的时候,这种方法就没有用了。
ResNet详解
网络中的亮点:
1.超深的网络结构(突破1000层)
2.提出residual模块(残差模块)
3.使用Batch Normalization加速训练(丢弃dropout)
两种不同的resnet模型
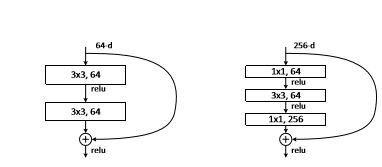
左图针对网络层数较少的网络resnet-34使用,右边这个是对resnet-50/101/152使用。

左图主线通过两个3x3的卷积层得到结果,旁边弧线(原论文叫捷径)连接输入和输出,主线操作形成的特征矩阵和输入的特征矩阵相加再通过激活函数(relu),相加大小(shape)必须一致。
右图多了两个1x1的卷积层,1x1的卷积核用来降维和升维,输入的特征矩阵深度是256,经过第一层1x1的卷积层长宽大小不变,深度变为64(64个卷积核)成功达到了降维目的,同理后面完成升维的目的。(大大的节约了卷积核的个数)
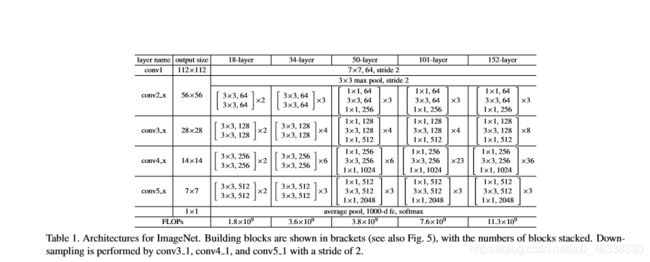
以resnet-34举例

可以发现在整个残差网络中有实线有虚线,为什么呐?

因为为了获得28x28的特征矩阵采用了步长为2的卷积核,为了保证主分支和捷径分支的大小深度完全一样采用一个新的相同步长的卷积层,增加深度完成相加,完成下采样操作。
Batch Normalization原理
我们在图像预处理过程中通常会对图像进行标准化处理,这样能够加速网络的收敛,如下图所示,对于Conv1来说输入的就是满足某一分布的特征矩阵,但对于Conv2而言输入的feature map就不一定满足某一分布规律了(注意这里所说满足某一分布规律并不是指某一个feature map的数据要满足分布规律,理论上是指整个训练样本集所对应feature map的数据要满足分布规律)。而我们Batch Normalization的目的就是使我们的feature map满足均值为0,方差为1的分布规律。

关于此内容我也不是很懂来自另外一篇博客https://blog.csdn.net/qq_37541097/article/details/104434557
感兴趣的盆友点击原博文查看详细内容
'''
导入库
'''
import torch
import torch.nn as nn
import torchvision
import torch.utils.data as Data
import math
from torch.autograd import Variable
from torchvision.transforms import Compose, ToTensor, Resize
import gc
gc.collect()
#对输入图像进行处理,转换为(224,224),因为resnet18要求输入为(224,224),并转化为tensor
def input_transform():
return Compose([
Resize(224), #改变尺寸
ToTensor(), #变成tensor
])
# Mnist 手写数字,数据导入
train_data = torchvision.datasets.MNIST(
root='./mnist/', # 保存或者提取位置
train=True, # this is training data
transform=input_transform(), # 转换 PIL.Image or numpy.ndarray 成
# torch.FloatTensor (C x H x W), 训练的时候 normalize 成 [0.0, 1.0] 区间
download=False, # 没下载就下载, 下载了就不用再下了
)
test_data = torchvision.datasets.MNIST(
root='./mnist/', # 保存或者提取位置
train=False, # this is training data
transform=input_transform(), # 转换 PIL.Image or numpy.ndarray 成
# torch.FloatTensor (C x H x W), 训练的时候 normalize 成 [0.0, 1.0] 区间
download=False, # 没下载就下载, 下载了就不用再下了
)
BATCH_SIZE = 128
'''
进行批处理
'''
loader = Data.DataLoader(dataset=train_data,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=2)
'''
定义resnet18
'''
def conv3x3(in_planes, out_planes, stride=1):
"3x3 convolution with padding"
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
expansion = 1
#inplanes其实就是channel,叫法不同
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
#把shortcut那的channel的维度统一
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=10):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, #因为mnist为(1,28,28)灰度图,因此输入通道数为1
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
#downsample 主要用来处理H(x)=F(x)+x中F(x)和xchannel维度不匹配问题
downsample = None
#self.inplanes为上个box_block的输出channel,planes为当前box_block块的输入channel
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def resnet18(pretrained=False, **kwargs):
"""Constructs a ResNet-18 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
#[2, 2, 2, 2]和结构图[]X2是对应的
model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs)
if pretrained: #加载模型权重
model.load_state_dict(model_zoo.load_url(model_urls['resnet18']))
return model
net = resnet18()
optimizer = torch.optim.Adam(net.parameters(), lr=0.01)
loss_func = torch.nn.CrossEntropyLoss()
for epoch in range(3):
for step, (batch_x, batch_y) in enumerate(loader):
b_x = Variable(batch_x)
b_y = Variable(batch_y)
predict = net(b_x)
loss = loss_func(predict, b_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 5 == 0:
print('epoch:{}, step:{}, loss:{}'.format(epoch, step, loss))
通过resnet-18实现mnist手写数据集的分类问题。