深度学习_7_实战_点集最优直线解_优化版代码解析
完整版优化代码:
import torch
from torch.utils import data
from d2l import torch as d2l # 特定导入
from torch import nn
def load_array(data_arrays, batch_size, is_train=True):
dataset = data.TensorDataset(*data_arrays) #解包传递,转成张量类型
# print(dataset)
return data.DataLoader(dataset, batch_size, shuffle = is_train) #每次挑选batch_size个样本,创建数据加载器
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = d2l.synthetic_data(true_w, true_b,1000) # 造1000点集
batch_size = 10
data_iter = load_array((features, labels), batch_size)#地址
#print(next(iter(data_iter)))#迭代器获取点集
net = nn.Sequential(nn.Linear(2, 1)) #指定好输入维度为2输出维度为1,Line层次,放在容器里
net[0].weight.data.normal_(0, 0.01) #net[0]也就是线性层次,设置w为均值0方差为0.01
net[0].bias.data.fill_(0) #b
loss = nn.MSELoss() #专门求均方误差的函数
trainer = torch.optim.SGD(net.parameters(), lr = 0.03)#求梯度函数也是有的,需要传入,w和b,以及学习率
num_eochs = 3
for epoch in range(num_eochs):
for x, y in data_iter:
l = loss(net(x), y)
trainer.zero_grad()#先清零梯度
l.backward()#算梯度
trainer.step()#模型更新,自动做梯度下降处理
l = loss(net(features), labels)#模型更新完就测试
print(f'epoch{epoch + 1}, loss{l:f}')
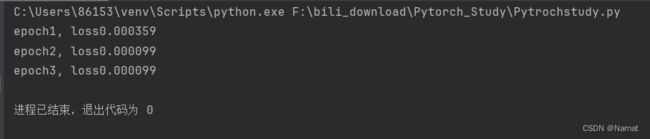
效果:
代码解析:
def load_array(data_arrays, batch_size, is_train=True):
dataset = data.TensorDataset(*data_arrays) #解包传递,转成张量类型
# print(dataset)
return data.DataLoader(dataset, batch_size, shuffle = is_train) #每次挑选batch_size个样本,创建数据加载器
将(features, labels)包装成元组传递给data_arrays,*data_arrays是将元组解包传递给TensorDataset,目的是整合成一个张量数据集,方便后续取出,训练模型,dataset 本质是获取上述数据集所放置的地址
data.DataLoader函数用于管理数据的加载和批次生成,shuffle = is_train,将数据打乱,最后返回数据地址
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = d2l.synthetic_data(true_w, true_b,1000) # 造1000点集
batch_size = 10
data_iter = load_array((features, labels), batch_size)#地址
用真实的w, b造1000个点集,为了后续训练函数,然后将数据打乱返还,每次返还10个
net = nn.Sequential(nn.Linear(2, 1)) #指定好输入维度为2输出维度为1,Line层次,放在容器里
net[0].weight.data.normal_(0, 0.01) #net[0]也就是线性层次,设置w为均值0方差为0.01
net[0].bias.data.fill_(0) #b
loss = nn.MSELoss() #专门求均方误差的函数
nn.Linear(2, 1),line是线性模型的意思,本次优化的模型就是线性模型,2,1表示,输入特征维度是2,输出特征维度为1
例:[[1,2],[3,4]]为输入 [[1],[2]]为输出
输入列数为2代表两个特征,如房子的面积和卧室数量
输出列数为1代表一特征,如房子的总价格
Sequential是容器,net[0]就是调用容器的第一层
net[0].weight.data.normal_(0, 0.01) #net[0]也就是线性层次,设置weight为均值0方差为0.01
net[0].bias.data.fill_(0) #bias,对应第二个参数b
上述分别对模型的w,b进行初始化,只不过这个w,b换成了weight和bias
num_eochs = 3
for epoch in range(num_eochs):
for x, y in data_iter:
l = loss(net(x), y)
trainer.zero_grad()#先清零梯度
l.backward()#算梯度
trainer.step()#模型更新,自动做梯度下降处理
l = loss(net(features), labels)#模型更新完就测试
print(f'epoch{epoch + 1}, loss{l:f}')
所有数据跑三次,分批次取出训练,并查看训练成果