COCO 格式
coco
- 基本信息
- annotations_trainval2017.zip
-
- 查看标注信息
-
- images: 列表,包含每个图像的信息,如:
- annotations: 列表,包含图像中物体的标注信息。
- categories: 列表,定义数据集中的类别。
- info : 字典,提供有关数据集的一般信息,如版本、描述、发布日期等。
- 适用任务
- pycocotools 的使用
-
- 加载数据集
- 获取某个类别的图像
- 显示图像和标注
- 评估模型性能
- 评估模
-
- pycocotools 适用于语义分割吗?(待确认)
基本信息
coco 数据集格式
COCO数据集的标注格式与PASCAL VOC等其他数据集有所不同,它使用JSON格式存储标注信息。
以下是COCO数据格式的主要组成部分:
train, val 是有标注的,而 test 是未标注的。


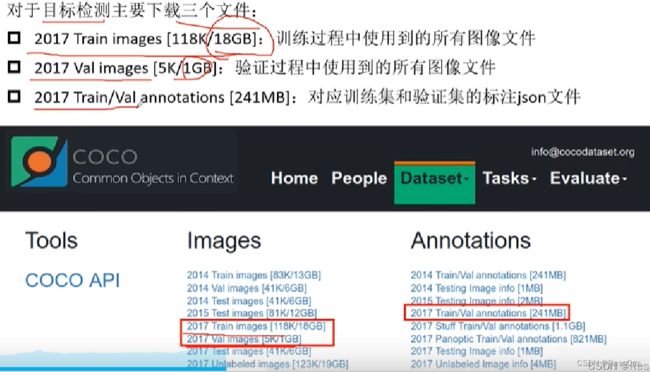
需要自己先对数据进行筛选,bounding box 可能有问题。
annotations_trainval2017.zip

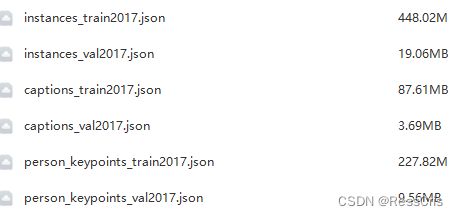
查看标注信息
import json
path = "./annotations_trainval2017/annotations/instances_val2017.json"
js = json.load(open(path, "r"))

images: 列表,包含每个图像的信息,如:
- id: 图像的唯一ID。
- width, height: 图像的尺寸。
- file_name: 图像文件的名称。
- coco_url, date_captured, flickr_url, license: 其他的图像元数据。
annotations: 列表,包含图像中物体的标注信息。
- id: 标注的唯一ID。
- image_id: 与标注关联的图像的ID。
- category_id: 标注物体的类别ID。
- segmentation: 对于分割任务,这是一个形状为[NumOfPolygons][PolygonPoints]的2D列表,表示物体的轮廓。
- bbox: 边界框的坐标[x, y, width, height]。
- iscrowd: 如果是复杂的分割(多个物体重叠),该值为1,否则为0。
- area: 物体的面积。
- keypoints (如果适用): 用于关键点检测的坐标列表。
categories: 列表,定义数据集中的类别。
- id: 类别的唯一ID。
- name: 类别的名称。
- supercategory: 为了方便,相关的类别可以分组到同一个超类别。
- licenses (如果有的话): 列表,定义图像的许可证信息。
info : 字典,提供有关数据集的一般信息,如版本、描述、发布日期等。
适用任务
object detection task
stuff segmentation task: 没有特定的空间范围或者形状的物体
panoptic segmentation: 前两种任务的结合,前景的物体检测+背景的分割
pycocotools 的使用
COCO API 是官方提供的一些处理标注文件的函数。
加载,解析和可视化标注文件。
安装 pip install pycocotools
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
import matplotlib.pyplot as plt
import skimage.io as io
import numpy as np
加载数据集
# 定义数据集的路径
dataDir = '/path/to/coco'
dataType = 'val2017' # 或 'train2017'
annFile = '{}/annotations/instances_{}.json'.format(dataDir, dataType)
# 创建 COCO 对象
coco = COCO(annFile)
获取某个类别的图像
# 获取 "person" 类别的 ID
catIds = coco.getCatIds(catNms=['person'])
# 获取该类别的所有图像 ID
imgIds = coco.getImgIds(catIds=catIds)
# 获取第一张图像的详细信息
img = coco.loadImgs(imgIds[0])[0]
显示图像和标注
I = io.imread('%s/images/%s/%s' % (dataDir, dataType, img['file_name']))
plt.axis('off')
plt.imshow(I)
plt.show()
# 加载并显示标注
plt.imshow(I)
plt.axis('off')
annIds = coco.getAnnIds(imgIds=img['id'], catIds=catIds, iscrowd=None)
anns = coco.loadAnns(annIds)
coco.showAnns(anns)
评估模型性能
# 加载预测结果
resFile = '/path/to/your/results.json'
cocoDt = coco.loadRes(resFile)
# 创建评估对象
cocoEval = COCOeval(coco, cocoDt, 'bbox') # 'bbox' 表示进行边界框评估,你也可以选择 'segm' 或 'keypoints'
cocoEval.params.imgIds = imgIds # 只评估某些图像
cocoEval.evaluate()
cocoEval.accumulate()
cocoEval.summarize()
##
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
# 加载真实标注和预测结果
cocoGt = COCO(ground_truth_annotations_file)
cocoDt = cocoGt.loadRes(predictions_file)
# 创建评估对象
cocoEval = COCOeval(cocoGt, cocoDt, 'bbox')
cocoEval.evaluate()
cocoEval.accumulate()
cocoEval.summarize()
评估模
型效果时的结果格式
物体检测
[
{"image_id": 42, "category_id": 18, "bbox": [258.15,41.29,348.26,243.78], "score": 0.236},
{"image_id": 43, "category_id": 3, "bbox": [125.12,22.33,120.22,143.20], "score": 0.456},
...
]
实例分割
[
{
"image_id": 42,
"category_id": 18,
"segmentation": {...},
"bbox": [x,y,width,height],
"score": 0.236
},
...
]
pycocotools 适用于语义分割吗?(待确认)
语义分割和实例分割是两种不同的任务,它们的评估方式和数据格式也不完全相同。
语义分割的目标是为图像中的每个像素分配一个类别标签,不区分不同的对象实例。因此,两个相邻的相同类别的对象在语义分割掩模中会被视为一个连续的区域。
实例分割的目标是为图像中的每个对象实例分配一个独特的标签,即使两个对象属于同一类。
在 COCO 数据集的上下文中,pycocotools 主要用于实例分割和物体检测任务,而不是语义分割任务。COCO 数据集有其自己的实例分割标注,但没有为全局语义分割提供标注。
如果你想评估语义分割的性能,你可能需要使用其他工具或数据集(例如 PASCAL VOC、Cityscapes 或 ADE20K),并采用专门的评估脚本。
总的来说,尽管 COCOeval 的使用代码结构相似,但根据你的任务(‘bbox’, ‘segm’, 或 ‘keypoints’)你需要稍作调整。对于语义分割,你可能需要使用其他的评估工具。