Kaggle - LLM Science Exam(四):Platypus2-70B with Wikipedia RAG
文章目录
-
- 一、赛事概述
-
- 1.1 OpenBookQA Dataset
- 1.2 比赛背景
- 1.3 评估方法和代码要求
- 1.4 比赛数据集
- 1.5 优秀notebook
- 1.6 RAG
- 二、Platypus2-70B with Wikipedia RAG(Version8)
-
- 2.1 离线安装依赖
- 2.2 导入库并设置常量
- 2.3设置辅助功能
- 2.4 SentenceTransformer Class
- 2.5 处理测试模式的context
- 2.6 创建从Kaggle数据集到缓存模型的符号链接
- 2.7 自定义ShardedLlama类(语言模型)
- 2.8 在多GPUs上运行模型
- 2.9 版本改进
-
- 2.9.1 Version12:加入WeightsLoader
- 2.9.2 Version14:NUM_TITLES = 3
- 2.9.3 Version15:NUM_TITLES = 5,改进`get_tokens`函数
- 2.9.4 Version16
- 2.9.5 Version17:MAX_CONTEXT = 1200

一、赛事概述
1.1 OpenBookQA Dataset
OpenBookQA Dataset是由美国艾伦人工智能研究院(Allen Institute for AI)发布的一个问答技术评测集,其主要目的是通过选择题考试的方式来测试和评估人工智能系统的问题回答能力,以下是更详细的介绍。
-
发布背景
许多之前的阅读理解数据集都是基于抽取式的方法,只需要从给定的上下文中抽取答案,而没必要进行更深层次的推理。OpenBookQA要求模型需要利用基础知识来回答问题,进行更复杂的推理。 -
数据集构成
OpenBookQA包含5957个四选一的科学常识问题(4,957 train, 500 dev, 500 test)。这些问题需要根据包含1326个科学事实的小“书本”来回答。问题采样自维基百科页面。 -
模型表现
回答OpenBookQA的问题不仅需要给定知识库中的科学常识,还需要额外的广泛常识知识。这些问题既不能通过检索算法回答正确,也不能通过词语共现算法回答正确。Strong neural baselines在OpenBookQA上只能达到约50%的准确率,与人类92%的准确率存在明显差距。 -
附加数据
该数据集还提供了5167个群众贡献的常识知识,以及扩展的训练集、开发集、测试集,每个问题对应其所考察的核心科学事实、人类准确率、清晰度评分等信息。 -
数据集意义
OpenBookQA推动了机器阅读理解从抽取式到推理式的发展,评估了模型在开放域知识下的深层理解和推理能力。
1.2 比赛背景
赛事地址:Kaggle - LLM Science Exam
- LLM的能力:随着大型语言模型的能力不断扩展,研究领域中出现了使用LLMs来表征自身的趋势。因为许多现有的自然语言处理基准测试已经被最先进的模型轻松解决,所以有趣的工作是利用LLMs创建更具挑战性的任务,以测试更强大的模型。
- 数据生成:比赛使用了gpt3.5模型,该模型基于从维基百科中提取的各种科学主题的文本片段,要求它编写一个多项选择问题(附带已知答案),然后过滤掉简单的问题。
- 资源受限:本次比赛是一场代码比赛,GPU和时间都受到限制。
- 挑战性:虽然量化和知识蒸馏等技术可以有效地缩小语言模型以便在更少的硬件资源上运行,但这场比赛仍旧充满挑战。目前,目前在 Kaggle 上运行的最大模型有大约 100 亿个参数,而
gpt3.5有 1750 亿个参数。如果一个问答模型能够轻松通过一个比其规模大10倍以上的模型编写的问答测试,这将是一个真正有趣的结果。另一方面,如果更大的模型能够有效地难住较小的模型,这对LLMs自我评估和测试的能力具有引人注目的影响。 - 竞赛旨在探讨比gpt3.5小10倍以上的问答模型能否有效回答gpt3.5编写的问题。结果将揭示LLM的基准测试和自我测试能力。
1.3 评估方法和代码要求
提交根据平均精度 @ 3 (MAP@3) 进行评估:

其中 , 为测试集中的问题数量,() 为截断值为 时的精确度, 为每个问题的预测数量,() 为指示函数,如果排名为 的项目是相关的(正确的)标签,则等于1,否则为0。
另外,某个问题正确预测后,后续将跳过该标签的其他预测,以防止刷准确度。举例来说,假设有一个测试集,里面有3个问题的正确答案都是A,如果有一个模型对这3个问题给出以下答案,那么以下情况都会得到平均精确度1.0的分数:
[A, B, C, D, E] # 问题1预测
[A, A, A, A, A] # 问题2预测
[A, B, A, C, A] # 问题3预测
这意味着一旦找到正确答案(A),之后的预测不再影响平均精确度分数。
本次比赛必须以notebook提交,且CPU和GPU运行时间少于9小时。禁用互联网,但是允许使用公开的外部数据,包括预先训练的模型。另外提交文件必须命名为 submission.csv。
1.4 比赛数据集
本次比赛是回答由gpt3.5模型生成的4000道多选题组成的测试集。测试集是隐藏的,当提交notebook后,才会有实际的测试数据进行评测。
- train.csv : 200个样本,问题+答案,以显示数据格式,并大致了解测试集中的问题类型。
- test.csv : 测试集,只包含题目,答案省略。
- sample_submission.csv : 提交格式示例
具体的训练集格式如下:
# Let's import the public training set and take a look
import pandas as pd
train_df = pd.read_csv('/kaggle/input/kaggle-llm-science-exam/train.csv')
train_df.head()

对于测试集中的每个 id 标签,您最多可以预测 3 个标签 。submission.csv文件应包含header并具有以下格式:
id,prediction
0, A B C
1, B C A
2, C A B
etc.
1.5 优秀notebook
-
《Starter Notebook: Ranked Predictions with BERT》:Bert Baseline,使用
bert-base-cased和比赛提供的200个训练集样本进行训练,Public Score=0.545。 -
《[EDA, Data gathering] LLM-SE ~ Wiki STEM | 1k DS》(制作训练数据):比赛提供的200个样本太少了,作者
LEONID KULYK先分析了比赛数据集,然后同样使用gpt3.5制作了1000个Wikipedia样本,数据集上传在Wikipedia STEM 1k。 -
《LLM-SE ~ deberta-v3-large -i | 1k Wiki》:
LEONID KULYK将自己收集的1000个Wikipedia样本和比赛训练集合并,一起训练,模型是deberta-v3-large。notebook中有最终模型权重,可直接推理,LB= 0.709。 -
《New dataset + DEBERTA v3 large training!》:
0.723→0.759-
Radek基于方法3,使用自己生成的500个额外数据训练DEBERTA v3 large,Public Score=0.723。 -
Radek后来又生成了6000条数据,跟之前的500条融合为6.5K数据集,并在此基础上进行三次训练,得到了三个模型权重,上传在Science Exam Trained Model Weights中。然后通过下面两种方法,进行推理:-
《Inference using 3 trained Deberta v3 models》:三个模型分别预测之后概率取平均,
Public Score=0.737。 -
An introduction to Voting Ensemble:作者在这个notebook中详细介绍了Voting Ensemble以及使用方法,
Public Score=0.759。
-
-
作者最后上传了15k high-quality train examples。
-
-
《Open Book LLM Science Exam》:
jjinho首次提出了Open Book方法,演示了如何在训练集中,使用faiss 执行相似性搜索,从作者构建的《Wikipedia Plaintext (2023-07-01)》数据集中找到与问答数据最相似的Wikipedia文档作为上下文,以增强问答效果。 -
《Open Book LLM Science Exam - Reduced RAM usage》:
quangbk改进了方法5中的内存效率。 -
《OpenBook DeBERTaV3-Large Baseline (Single Model》):
Anil将方法4和方法6结合起来。他将先测试集数据按照方法6搜索出context,然后将其与prompt合并,得到新的测试集。然后加载方法4训练的模型进行推理,Public Score=0.771。test_df["prompt"] = test_df["context"] + " #### " + test_df["prompt"] -
《Sharing my trained-with-context model》:
Mgoksu同样使用了方法7,只是使用了自己制作的数据集进行离线训练,得到一个更好的模型llm-science-run-context-2,然后进行推理,top publicLB=0.807。 -
《How To Train Open Book Model - Part 1》、《How To Train Open Book Model - Part 2》:
CHRIS DEOTTE在part1中,参照方法8在自己制作的60k数据集进行训练,得到模型model_v2;然后在part2中使用方法8中的模型llm-science-run-context-2以及model_v2分别进行推理,得到的两个概率取平均,得到最终结果(Public Score=0.819)。- 在part1中,作者使用了竞赛指标MAP@3 来评估模型,并讨论了一些训练技巧,例如使用 PEFT或冻结model embeddings&model layers来减少训练参数、增加 LR 并减少 epochs来减少计算量、 使用gradient_checkpointing(这使用磁盘来节省RAM)、使用gradient_accumlation_steps模拟更大的批次等等。
-
《LLM Science Exam Optimise Ensemble Weights》:作者首先使用了方法9训练的模型权重;另外为了增加多样性,还融合了其它几个没有使用Open Book的deberta-v3-large模型,最终
Public Score=0.837。作者还写了以下notebook:- 《Incorporate MAP@k metrics into HF Trainer》:在Trainer中加入MAP@k指标
- 《Introducing Adversarial Weight Perturbation (AWP)》、《Adversarial Weight Perturbation (AWP) Inference》:介绍对抗性权重扰动AWP,以及推理方法。
- 《Using DeepSpeed with HF Trainer》,希望可以节约内存,以便训练更大的模型。
-
《LLM-SciEx Optimise Ensemble Weights(better models)》:类似方法10,通过模型融合,
Public Score=0.846。 -
《with only 270K articles》:作者自己制作了270K Wikipedia数据集(后续比赛基本都使用这个更好的数据集做RAG,效果提升很大),使用
TF-IDF进行相似文本检索,推理使用LongFormer模型而不是deberta-v3-large,Public Score=0.862。 -
《Platypus2-70B with Wikipedia RAG》:使用Platypus2-70B进行推理,一共18个版本,
Public Score从0.832到0.909。- Version 1:参考方法7,使用《Wikipedia Plaintext (2023-07-01)》数据集来做RAG,LB=0.8369,LC=0.8326。
- Version 2: LB=0.3752,LC=0.3569
- Version 8: 参考方法12,使用《270K Wikipedia STEM articles》数据集来做RAG,但使用faiss来做相似度检索。LB=0.8728,LC=0.8867。
ALI在 《Explained Platypus2-70B + Wikipedia RAG》中对这个版本的代码做了详细的注解。 - Version 12:加入了
Weight-loader,LB=0.8335,LC=0.8512。《Patypus2-70b | Wiki retrieval + Weight-loader》也使用了类似方法,提交耗时16到20小时。 - Version 14:NUM_TITLES从5改为3,LB=0.8639,LC=0.8786
- Version 15:NUM_TITLES 改回5,改进
get_tokens函数,LB=0.8726,LC=0.8880 - Version 16:LB=0.9057,LC=0.9124。作者在《Platypus2-70B without Wikipedia RAG》中试验了没有RAG,得分LB=0.8532,LC=0.8587。
- Version 17:MAX_CONTEXT从800改为1200,LB=0.9093,LC=0.9140
-
《Fork of Fork of [86.2] with only 270K articles!》在方法12的基础上改进了预处理函数,并使用方法8 的模型,
Public Score=0.905 -
《RAPIDS TF-IDF - [LB 0.904] - Single Model》:在方法12的基础上,使用RAPIDS TF-IDF加速检索过程,使用双GPU(2xT4 GPU)和双线程来加速推理过程,并微调了部分参数(prepare_answering_input2),最终
LB=0.904。作者说自己参照方法11,融合了另外6个模型,最终得分0.916,代码未公开。
1.6 RAG
Retrieval Augmented Generation(RAG,检索增强生成)是一种大型语言模型技术,通过检索知识库来提取任务相关的上下文,以提高LLM生成的文本的质量和相关性,在对话系统、问答系统等领域有很大应用前景。整个pipeline.可以表示为:
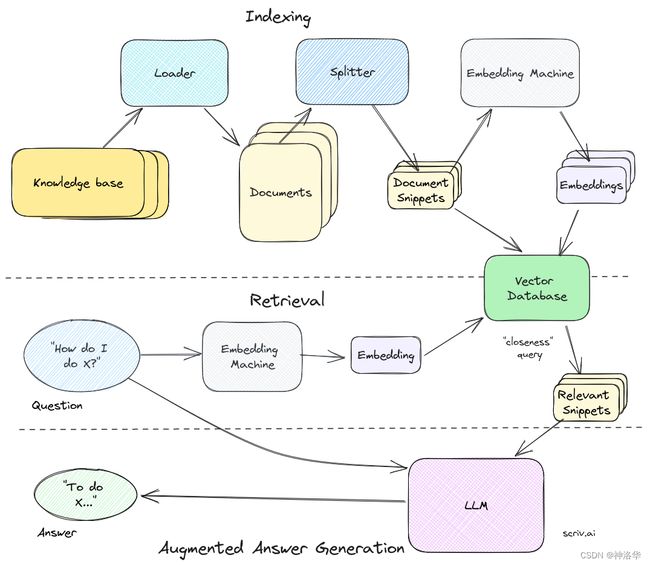
-
为知识库构建索引
- 获取知识源(
knowledge base),使用一个加载器(loader)将其转化为单独的文档(Document) - 使用分割器(
splitters)将其分成易于处理的小块或片段(document snippets)。 - 将这些片段传递给嵌入式机器(
embedding machine),将其转化为可用于语义搜索的向量。 - 将这些片段的embedding保存在我们的矢量数据库中(
vector database),同时保留它们的文本片段。
- 获取知识源(
-
检索
将 问题/任务 输入相同的嵌入式机器得到其嵌入表示,并传递到我们的矢量数据库。然后通过检索得到最匹配的片段,这些片段就是问题最相关的上下文(context),可用于增强LLM生成的回答或响应。 -
加强型的答案生成(augmented answer generation).。
将获取的相关知识片段,与自定义系统提示和问题进行合并,然后一起格式化,并最终得到基于相关上下文的问题答案。
RAG中常用的文本检索方法有faiss、TF-IDF、bm25等。有关此部分详细内容请参考我上一篇帖子《Kaggle - LLM Science Exam(二):Open Book QA&debertav3-large详解》
二、Platypus2-70B with Wikipedia RAG(Version8)
参考《Platypus2-70B with Wikipedia RAG(Version8)》
2.1 离线安装依赖
在此单元中,您将从本地文件安装两个特定的 Python 包。
!pip install命令用于安装Python包。-U标志用于升级软件包(如果已安装)。--no-deps标志用于跳过安装依赖项,因为您是从本地文件安装。.whl文件的路径在 --no-deps 之后提供,以指定包的位置。
!pip install -U --no-deps /kaggle/input/faiss-gpu-173-python310/faiss_gpu-1.7.2-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
!pip install -U --no-deps /kaggle/input/datasets-214/datasets-2.14.5-py3-none-any.whl
2.2 导入库并设置常量
import gc
import logging
from time import time
from pathlib import Path
from concurrent.futures import ThreadPoolExecutor
import ctypes
from functools import partial
import torch
import numpy as np
import pandas as pd
from tqdm.auto import tqdm
# For RAG
import faiss
import torch.nn.functional as F
from torch.utils.data import DataLoader
from datasets import load_from_disk, Dataset
NUM_TITLES = 5
MAX_SEQ_LEN = 512
MODEL_PATH = "/kaggle/input/bge-small-faiss/"
# For LLM
from transformers import AutoConfig, AutoModelForCausalLM, AutoTokenizer, AutoModel
from accelerate import init_empty_weights
from accelerate.utils.modeling import set_module_tensor_to_device
from safetensors.torch import load_file
# With NUM_TITLES = 5, the median lenght of a context if 1100 tokens (Q1: 900, Q3: 1400)
N_BATCHES = 5
MAX_CONTEXT = 1200
MAX_LENGTH = 4096
2.3设置辅助功能
- 此单元定义了一个函数
clean_memory(),用于垃圾收集、清理内存和显存 IS_TEST_SET变量控制笔记本是在完整数据集还是较小的子集上运行(for test),主要作用是save version的时候,不用跑全部代码,花费太多时间- 可以取消注释代码块以加载训练集并相应地调整
IS_TEST_SET和N_BATCHES
# Function to clean RAM & vRAM
def clean_memory():
gc.collect()
ctypes.CDLL("libc.so.6").malloc_trim(0)
torch.cuda.empty_cache()
# 加载测试集
df = pd.read_csv("/kaggle/input/kaggle-llm-science-exam/test.csv", index_col="id")
# 调试时测试集只有200个样本,IS_TEST_SET为False,提交比赛时才为True
IS_TEST_SET = len(df) != 200
# 取消注释以查看在训练集上的结果。
# df = pd.read_csv("/kaggle/input/kaggle-llm-science-exam/train.csv", index_col="id")
# IS_TEST_SET = True
# N_BATCHES = 1
2.4 SentenceTransformer Class
下面设置一个自定义的 SentenceTransformer 类,用于将句子编码为embeddings。
__init__方法:根据指定的checkpoint加载预训练的模型和分词器。transform方法:使用分词器对句子进行分词和预处理。get_dataloader方法:将句子列表装入 DataLoader。encode方法:将句子编码为embeddings。
class SentenceTransformer:
def __init__(self, checkpoint, device="cuda:0"):
self.device = device
self.checkpoint = checkpoint
self.model = AutoModel.from_pretrained(checkpoint).to(self.device).half()
self.tokenizer = AutoTokenizer.from_pretrained(checkpoint)
def transform(self, batch):
tokens = self.tokenizer(batch["text"], truncation=True, padding=True, return_tensors="pt", max_length=MAX_SEQ_LEN)
return tokens.to(self.device)
def get_dataloader(self, sentences, batch_size=32):
# 为每个句子添加特定前缀:“为此句搜索相关段落”
sentences = ["Represent this sentence for searching relevant passages: " + x for x in sentences]
# 使用datasets模块创建数据集,包含"text"字段
dataset = Dataset.from_dict({"text": sentences})
dataset.set_transform(self.transform)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=False)
return dataloader
# 对输入的句子进行编码,生成文本嵌入
def encode(self, sentences, show_progress_bar=False, batch_size=32):
dataloader = self.get_dataloader(sentences, batch_size=batch_size)
pbar = tqdm(dataloader) if show_progress_bar else dataloader # 显示进度条
embeddings = []
for batch in pbar: # 遍历每个批次
with torch.no_grad():
e = self.model(**batch).pooler_output
e = F.normalize(e, p=2, dim=1)
embeddings.append(e.detach().cpu().numpy()) # 将 e 转换为NumPy数组,并将其从GPU移到CPU上,以便后续处理。
embeddings = np.concatenate(embeddings, axis=0)
return embeddings
np.concatenate(embeddings, axis=0):在处理完所有批次后,将 embeddings 列表中的嵌入连接在一起,得到一个大的嵌入数组。F.normalize是PyTorch中的函数,用于将向量标准化,这有助于确保嵌入在计算相似度或进行其他文本处理任务时具有一致的尺度。p:指定归一化的范数,p=2表示使用L2范数,也就是欧几里德范数,计算向量的模。对于文本嵌入,这通常是一种常见的归一化方式,用于将向量的模(长度)归一化为1。dim:执行归一化的维度。dim=1表示在第1维度(通常是对应于向量中的元素)上执行归一化,即对每个向量进行归一化。
假设有一个二维张量 tensor,其中包含两个向量,然后使用L2范数对每个向量执行归一化:
tensor = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
F.normalize(tensor, p=2, dim=1)
# 0.4472^2+0.8944^2=1,0.6^2+0.8^2=1
tensor([[0.4472, 0.8944],
[0.6, 0.8]])
对结果进行归一化的主要目的是确保嵌入向量具有一致的尺度,从而使它们在计算相似性或进行其他文本处理任务时更具可比性。比如余弦相似度度量了两个向量之间的夹角,而不受它们的模长影响。归一化嵌入使余弦相似度的值范围在-1到1之间,更容易理解。
2.5 处理测试模式的context
如果 IS_TEST_SET = True ,则此单元处理并提取测试集的上下文。
- 加载上面自定义的
SentenceTransformer模型,并初始化一个计时器start - 使用 lambda 函数将prompts 与 answer合并,得到用于嵌入的
inputs。 - 载入 Faiss 索引以执行文本匹配的高效最近邻搜索。
- 使用 Faiss 进行文本搜索,以查找与提示嵌入最接近的句子。
- 从预加载的数据集中提取上下文,然后更新
df中的每个条目以包含提取的上下文。 - 释放内存,包括重置 Faiss 索引、删除变量和运行
clean_memory()函数。 - 打印整个过程的经过时间。
if IS_TEST_SET:
# 加载嵌入模型
start = time()
print(f"开始处理提示嵌入,耗时:{time() - start :.1f}秒")
model = SentenceTransformer(MODEL_PATH, device="cuda:0")
# 获取 prompts embeddings
f = lambda row : " ".join([row["prompt"], row["A"], row["B"], row["C"], row["D"], row["E"]])
inputs = df.apply(f, axis=1).values # 比仅使用提示得到更好的结果
prompt_embeddings = model.encode(inputs, show_progress_bar=False)
# 在维基百科索引中搜索最接近的句子
print(f"加载 faiss index,耗时:{time() - start :.1f}秒")
faiss_index = faiss.read_index(MODEL_PATH + '/faiss.index')
print(f"开始文本搜索,耗时:{time() - start :.1f}秒")
search_index = faiss_index.search(np.float32(prompt_embeddings), NUM_TITLES)[1]
print(f"开始上下文提取,耗时:{time() - start :.1f}秒")
dataset = load_from_disk("/kaggle/input/all-paraphs-parsed-expanded")
for i in range(len(df)):
df.loc[i, "context"] = "-" + "\n-".join([dataset[int(j)]["text"] for j in search_index[i]])
# 释放内存
faiss_index.reset()
del faiss_index, prompt_embeddings, model, dataset
clean_memory()
print(f"context已添加,耗时:{time() - start :.1f}秒")
-
faiss_index.search(np.float32(prompt_embeddings), NUM_TITLES):使用faiss_index来检索出与prompt_embeddings最相似的NUM_TITLES个向量。它返回一个包含两个元素的元组(search_score, search_index),所以[1]返回相似向量索引。 -
df.loc[i, "context"] = ...:根据上一步的search_index提取出相似文档,并使用换行符和破折号分隔它们,然后将整个文本添加到数据框 df 的 “context” 列中。
2.6 创建从Kaggle数据集到缓存模型的符号链接
# 创建符号链接从Kaggle数据集到虚拟的缓存模型
# 定义缓存模型的路径
checkpoint_path = Path("/root/.cache/")
checkpoint_path.mkdir(exist_ok=True, parents=True) # 如果目录不存在,就创建它
# 循环处理两个part,source_dir是包含数据集文件的目录。
for part in [1, 2]:
# 定义数据集文件所在的源目录
source_dir = Path(f"/kaggle/input/platypus2-70b-instruct-part{part}")
# 遍历源目录中的所有文件
for path in source_dir.glob("*"):
try:
# 在 checkpoint_path 目录中创建一个同名的符号链接,指向 source_dir 中的原始文件。
(checkpoint_path / path.name).symlink_to(path)
except:
pass
上述代码将模型文件创建为符号链接,以便它们可以被模拟的缓存模型目录访问。如果符号链接创建失败,任何异常都会被捕获并忽略。这通常用于设置数据集文件的快速访问,以减少重复下载数据的需求。
2.7 自定义ShardedLlama类(语言模型)
自定义ShardedLlama 类,将LLM模型分成几层,并且每层都按顺序加载以优化内存使用。 __call__ 方法获取一批输入并通过模型对其进行处理,提供结果以供进一步分析。
# 创建 Sharded llama 类
class ShardedLlama:
def __init__(self, checkpoint_path, device="cuda:0", dtype=torch.float16):
"""
创建 ShardedLlama 类的实例,该类是 LlamaForCausalLM 的Sharded 版本:模型被分成layer shards以减少 GPU 内存使用。
在前向传播过程中,输入逐层处理,每层后都释放 GPU 内存。
为了避免多次加载层,可以将所有中间激活保存在 RAM 中,但是由于 Kaggle 加速器的 GPU 内存比 CPU 多,我们只需将输入分批次处理并保留在 GPU 上。
参数
----------
checkpoint_path : str 或 Path
检查点路径
device : str, 可选
设备,默认为 "cuda:0"
dtype : torch.dtype, 可选
数据类型,默认为 torch.float16
"""
# 保存参数
self.checkpoint_path = Path(checkpoint_path)
self.device = device
self.dtype = dtype
# 创建模型
self.config = AutoConfig.from_pretrained(self.checkpoint_path) # 从指定的检查点路径加载配置
# 对于Turing architecture支持的flash attention:https://github.com/Dao-AILab/flash-attention/issues/542
# self.config.auto_map = {"AutoModelForCausalLM" : "togethercomputer/LLaMA-2-7B-32K--modeling_flash_llama.LlamaForCausalLM"}
self.tokenizer = AutoTokenizer.from_pretrained(checkpoint_path) # 从指定的检查点路径加载分词器
self.tokenizer.pad_token = self.tokenizer.eos_token
self.tokenizer.padding_side = "right"
self.init_model()
self.layer_names = ["model.embed_tokens"] + [f"model.layers.{i}" for i in range(len(self.model.model.layers))] + ["model.norm", "lm_head"]
def init_model(self):
# 加载元模型(不使用内存)
with init_empty_weights():
self.model = AutoModelForCausalLM.from_config(self.config, trust_remote_code=True)
# 绑定模型不同部分的权重,以确保它们共享相同的权重矩阵,这可以节省内存,提高模型的效率。
self.model.tie_weights()
# 将model.layers存储在self.layers中
self.layers = [self.model.model.embed_tokens] + list(self.model.model.layers) + [self.model.model.norm, self.model.lm_head]
# 将缓冲区移动到 device(GPU 内存使用不多)
for buffer_name, buffer in self.model.named_buffers():
set_module_tensor_to_device(self.model, buffer_name, self.device, value=buffer, dtype=self.dtype)
# 定义加载模型特定层的方法
def load_layer(self, layer_name):
# 根据 layer_name 和device从文件中加载模型状态字典(state_dict )
state_dict = load_file(self.checkpoint_path / (layer_name + ".safetensors"), device=self.device)
# 迭代状态字典中的参数并将它们移动到指定的设备
for param_name, param in state_dict.items():
assert param.dtype != torch.int8, "int8 不受支持(需要添加 fp16_statistics)"
set_module_tensor_to_device(self.model, param_name, self.device, value=param, dtype=self.dtype)
def __call__(self, inputs, output_token):
# inputs = [(prefix, suffix), ...],其中 prefix.shape[0] = 1,suffix.shape[0] = 5
# 重新初始化模型,确保缓冲区已加载并内存已清空
del self.model
clean_memory()
self.init_model()
# 将批次发送到设备
batch = [(prefix.to(self.device), suffix.to(self.device)) for prefix, suffix in inputs]
n_suffixes = len(batch[0][1])
suffix_eos = [(suffix != self.tokenizer.pad_token_id).sum(1) - 1 for _, suffix in inputs]
# 为largest input创建注意力掩码,以及用于 KV 缓存的位置 ID
attention_mask = torch.finfo(self.dtype).min * torch.ones(MAX_LENGTH, MAX_LENGTH)
attention_mask = attention_mask.triu(diagonal=1)[None, None, ...]
attention_mask = attention_mask.to(self.device)
position_ids = torch.arange(MAX_LENGTH, dtype=torch.long, device=self.device)[None, :]
#使用 ThreadPoolExecutor 并行加载模型层
with ThreadPoolExecutor() as executor, torch.inference_mode():
# 加载第一层
#future = executor.submit(self.load_layer, "model.embed_tokens")
self.load_layer("model.embed_tokens")
for i, (layer_name, layer) in tqdm(enumerate(zip(self.layer_names, self.layers)), desc=self.device, total=len(self.layers)):
# 等待前一层加载完成并加载下一层
#future.result()
if (i + 1) < len(self.layer_names):
#future = executor.submit(self.load_layer, self.layer_names[i + 1])
self.load_layer(self.layer_names[i + 1])
# 运行层
for j, (prefix, suffix) in enumerate(batch):
if layer_name == "model.embed_tokens":
batch[j] = (layer(prefix), layer(suffix))
elif layer_name == "model.norm":
# 此时只保留最后一个标记
batch[j] = (None, layer(suffix[torch.arange(n_suffixes), suffix_eos[j]][:, None]))
elif layer_name == "lm_head":
batch[j] = layer(suffix)[:, 0, output_token].detach().cpu().numpy()
else:
# 运行前缀
len_p, len_s = prefix.shape[1], suffix.shape[1]
new_prefix, (k_cache, v_cache) = layer(prefix, use_cache=True, attention_mask=attention_mask[:, :, -len_p:, -len_p:])
# 运行后缀
pos = position_ids[:, len_p:len_p + len_s].repeat(n_suffixes, 1)
attn = attention_mask[:, :, -len_s:, -len_p - len_s:].repeat(n_suffixes, 1, 1, 1)
kv_cache = (k_cache.repeat(n_suffixes, 1, 1, 1), v_cache.repeat(n_suffixes, 1, 1, 1))
new_suffix = layer(suffix, past_key_value=kv_cache, position_ids=pos, attention_mask=attn)[0]
batch[j] = (new_prefix, new_suffix)
# 从内存中删除前一层(包括缓冲区)
layer.to("meta")
clean_memory() # 由 CPMP 提出的建议
# 获取分数
return batch
__call__方法:- 重新启动模型以确保加载缓冲区且memory is clean。
- 输入批次被发送到指定设备。
- n_suffixes 是批次中后缀的数量, suffix_eos 计算每个后缀中序列结束标记的位置
- 对于每一层,加载当前层并等待上一层加载。
- 对于批次中的每个输入:
- 如果是
model.embed_tokens层,则前缀和后缀将通过该层传递。 - 如果是
model.norm层,则仅保留每个后缀中的最后一个标记。 - 如果它是
lm_head层,则会针对指定的输出标记进行预测。 - 对于其他层,前缀和后缀都被处理,并存储中间结果。
- 如果是
- 处理完每一层后,前一层将从内存中删除。
2.8 在多GPUs上运行模型
定义 get_tokens 函数
# Define a function to get tokens for the model input
def get_tokens(row, tokenizer):
system_prefix = "Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.\n\n### Instruction:\n{instruction}\n\n### Input:\n{input_prefix}"
instruction = "Your task is to analyze the question and answer below. If the answer is correct, respond yes, if it is not correct respond no. As a potential aid to your answer, background context from Wikipedia articles is at your disposal, even if they might not always be relevant."
input_prefix = f"Context: {row['context'][:MAX_CONTEXT]}\nQuestion: {row['prompt']}\nProposed answer: "
prompt_prefix = system_prefix.format(instruction=instruction, input_prefix=input_prefix)
prefix = tokenizer(prompt_prefix, return_tensors="pt", return_attention_mask=False, truncation=True, max_length=MAX_LENGTH)["input_ids"]
prompt_suffix = [f"{row[letter]}\n\n### Response:\n" for letter in "ABCDE"]
suffix = tokenizer(prompt_suffix, return_tensors="pt", return_attention_mask=False, truncation=True, max_length=MAX_LENGTH, padding=True)["input_ids"][:, 1:]
return prefix, suffix
system_prefix:system前缀模板,该前缀是一个文本块,描述了任务和输入背景。instruction:包含任务说明的字符串。input_prefix:由输入数据 的context和prompt信息组成。prompt_prefix:使用system_prefix模板,将instruction和input_prefix结合在一起。prefix:使用tokenizer对prompt_prefix进行标记化处理(转换为 PyTorch 张量),获取其中的"input_ids"字段。prompt_suffix:为每个答案选项 A、B、C、D 和 E 生成的字符串列表。suffix:对prompt_suffix进行标记化处理
# Define a function to run the model on a device
def run_model(device, df):
model = ShardedLlama(checkpoint_path, device=f"cuda:{device}")
f = partial(get_tokens, tokenizer=model.tokenizer)
inputs = df.apply(f, axis=1).values
batches = np.array_split(inputs, N_BATCHES)
outputs = []
for i, batch in enumerate(batches):
# Token #4874 is yes.
outputs += model(batch, output_token=4874)
return outputs
- 利用
get_tokens函数和模型的分词器,创建了一个偏函数f。这个偏函数将用于处理输入数据。 - 模型的输入数据是通过将
f函数应用于 DataFramedf的每一行而生成的。 - 利用
np.array_split,将输入数据分成批次。 - 该函数初始化了一个名为
outputs的空列表,用于收集模型的输出结果。 - 然后,它遍历各个批次,对每个批次运行模型,并将结果附加到
outputs列表中。
# Run model
if IS_TEST_SET:
with ThreadPoolExecutor() as executor:
outputs = list(executor.map(run_model, [0, 1], np.array_split(df, 2)))
outputs = sum(outputs, [])
# Save results
n = len(df)
for i, scores in enumerate(outputs):
top3 = np.argsort(scores)[::-1]
df.loc[i, "prediction"] = " ".join(["ABCDE"[j] for j in top3])
# Display performances if train set is used (in this case use IS_TEST_SET=True !)
if "answer" in df.columns:
for i in range(n):
df.loc[i, "top_1"] = df.loc[i, "prediction"][0]
df.loc[i, "top_2"] = df.loc[i, "prediction"][2]
df.loc[i, "top_3"] = df.loc[i, "prediction"][4]
top_i = [(df[f"top_{i}"] == df["answer"]).sum() for i in [1, 2, 3]]
print(f"top1 : {top_i[0]}/{n}, top2 : {top_i[1]}/{n}, top3 : {top_i[2]}/{n} (total={sum(top_i)} / {n})")
print(f"Accuracy: {100*top_i[0]/n:.1f}%, map3: {100*(top_i[0] + top_i[1]*1/2 + top_i[2]*1/3).sum()/n:.1f}%")
else:
df["prediction"] = "A B C"
df[["prediction"]].to_csv("submission.csv")
- 代码的这一部分根据
IS_TEST_SET的值进行条件处理。如果它为True,则在测试集上运行模型。 - 使用
ThreadPoolExecutor来同时在两个GPU上运行run_model函数。 - 从模型中收集输出并将其合并成一个单一的列表。
- 结果被保存回 DataFrame
df,对于每一行,确定并存储前三个预测结果。 - 如果DataFrame包含一个 “answer” 列,将计算和打印性能指标,如准确度和平均平均精度(map3)。
- 如果
IS_TEST_SET为False,则会为DataFrame中的每一行分配默认预测 “A B C”。 - 最后,DataFrame 的 “prediction” 列被保存到名为 “submission.csv” 的CSV文件中。
2.9 版本改进
参考《Platypus2-70B without Wikipedia RAG》(version12)
2.9.1 Version12:加入WeightsLoader
以下是相对于Version8的区别:
!pip install -U --no-deps /kaggle/input/optimum-113/optimum-1.13.2-py3-none-any.whl
from threading import Condition # 在WeightsLoader中用到
from optimum.bettertransformer import BetterTransformer
N_BATCHES = 5
MAX_LENGTH = 4096
MAX_CONTEXT = 1400 # 之前是2750
# MAX_CONTEXT now in tokens instead of characters (1 token ~ 4.3 characters)
# With NUM_TITLES = 5, the median lenght of a context if 1100 tokens (Q1: 900, Q3: 1400)
class WeightsLoader:
"""
Thread-safe class to load the weights of the model.
The weights are loaded in the background and can be accessed with get_state_dict().
All devices must call set_state_dict() before the weights are loaded.
"""
def __init__(self, checkpoint_path, devices):
self.checkpoint_path = Path(checkpoint_path)
self.states = {device: None for device in devices}
self.state_dict = None
self.condition = Condition()
def get_state_dict(self, device):
with self.condition:
while self.states[device] is not None:
self.condition.wait()
result = self.state_dict
self.states[device] = None
if not any(self.states.values()):
self.condition.notify_all()
return result
def set_state_dict(self, layer_name, device):
with self.condition:
self.states[device] = layer_name
if all(self.states.values()):
assert len(set(self.states.values())) == 1, "All devices should load the same layer"
self.state_dict = load_file(self.checkpoint_path / (layer_name + ".safetensors"), device="cpu")
for d in self.states:
self.states[d] = None
self.condition.notify_all()
因为加入WeightsLoader,整个ShardedLlama也对应的做调整,这里就不列出所有代码了。
def init_model(self):
...
self.model = BetterTransformer.transform(self.model) # enable flash attention
get_tokens函数做了一些改动:
def get_tokens(row, tokenizer):
system_prefix = "Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.\n\n### Instruction:\n{instruction}\n\n### Input:\nContext:\n{context}"
instruction = "Your task is to analyze the question and answer below. If the answer is correct, respond yes, if it is not correct respond no. As a potential aid to your answer, background context from Wikipedia articles is at your disposal, even if they might not always be relevant."
prompt_context = system_prefix.format(instruction=instruction, context=row["context"])
context = tokenizer(prompt_context, return_tensors="pt", return_attention_mask=False, truncation=True, max_length=MAX_LENGTH)["input_ids"]
prompt_question = f"\nQuestion: {row['prompt']}\nProposed answer: "
question = tokenizer(prompt_question, return_tensors="pt", return_attention_mask=False, truncation=True, max_length=MAX_LENGTH)["input_ids"][:, 1:]
prompt_suffix = [f"{row[letter]}\n\n### Response:\n" for letter in "ABCDE"]
suffix = tokenizer(prompt_suffix, return_tensors="pt", return_attention_mask=False, truncation=True, max_length=MAX_LENGTH, padding=True)["input_ids"][:, 1:]
context = context[:, :MAX_LENGTH - question.shape[1] - suffix.shape[1]]
prefix = torch.cat([context, question], dim=1)[:, :MAX_CONTEXT]
return prefix, suffix

另外因为加入WeightsLoader,run_model函数和with ThreadPoolExecutor() as executor:前都加了一段。


2.9.2 Version14:NUM_TITLES = 3
NUM_TITLES = 5改为NUM_TITLES = 3,其它不变- 得分
LB=0.8335,LC=0.8512→LB=0.8639,LC=0.8786
2.9.3 Version15:NUM_TITLES = 5,改进get_tokens函数
NUM_TITLES = 3又改为NUM_TITLES = 5get_tokens更改- 得分
LB=0.8639,LC=0.8786→LB=0.8726,LC=0.8880
def get_tokens(row, tokenizer):
system_prefix = "Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.\n\n### Instruction:\n{instruction}\n\n### Input:\nContext:\n{context}"
instruction = "Your task is to analyze the question and answer below. If the answer is correct, respond yes, if it is not correct respond no. As a potential aid to your answer, background context from Wikipedia articles is at your disposal, even if they might not always be relevant."
# max length : MAX_LENGTH
prompt_suffix = [f"{row[letter]}\n\n### Response:\n" for letter in "ABCDE"]
suffix = tokenizer(prompt_suffix, return_tensors="pt", return_attention_mask=False, truncation=True, max_length=MAX_LENGTH, padding=True)["input_ids"][:, 1:]
# max length : max(0, MAX_LENGTH - len(suffix))
prompt_question = f"\nQuestion: {row['prompt']}\nProposed answer: "
question = tokenizer(prompt_question, return_tensors="pt", return_attention_mask=False, truncation=True, max_length=max(0, MAX_LENGTH - suffix.shape[1]))["input_ids"][:, 1:]
# max length : min(MAX_CONTEXT, max(0, MAX_LENGTH - len(suffix) - len(question)))
prompt_context = system_prefix.format(instruction=instruction, context=row["context"])
max_length = min(MAX_CONTEXT, max(0, MAX_LENGTH - question.shape[1] - suffix.shape[1]))
context = tokenizer(prompt_context, return_tensors="pt", return_attention_mask=False, truncation=True, max_length=max_length)["input_ids"]
prefix = torch.cat([context, question], dim=1)
return prefix, suffix
2.9.4 Version16
- 安装transformers-4.32.1
!pip install -U --no-deps /kaggle/input/transformers-432/transformers-4.32.1-py3-none-any.whl
MAX_CONTEXT = 800(之前是1400)- 模型分成三部分
checkpoint_path = Path("/root/.cache/")
checkpoint_path.mkdir(exist_ok=True, parents=True)
# 之前是for part in [1, 2]:
for part in [1, 2, 3]:
source_dir = Path(f'/kaggle/input/platypus2-chuhac2-part{part}')
for path in source_dir.glob("*"):
(checkpoint_path / path.name).symlink_to(path)
ShardedLlama改进:


- 得分
LB=0.8726,LC=0.8880→LB=0.9057,LC=0.9124
2.9.5 Version17:MAX_CONTEXT = 1200
- MAX_CONTEXT = 800→MAX_CONTEXT = 1200
LB=0.9057,LC=0.9124→LB=0.9093,LC=0.9140
