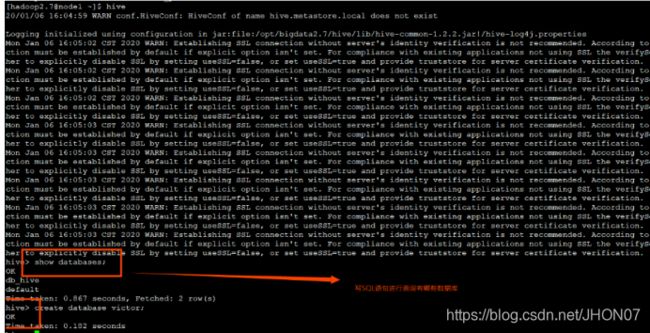
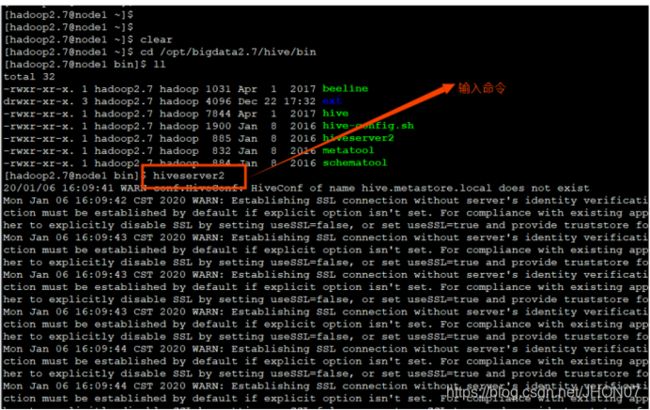
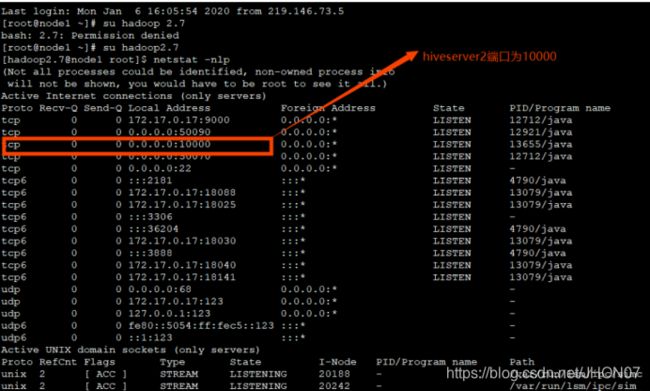
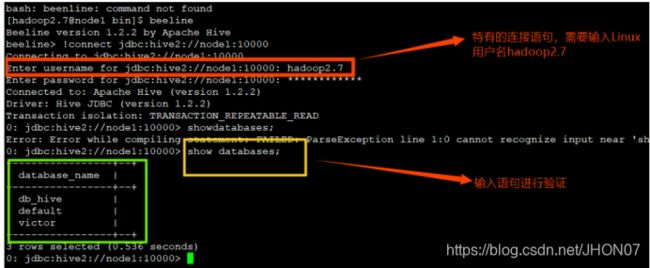
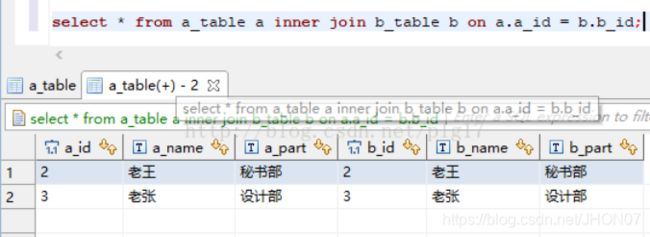
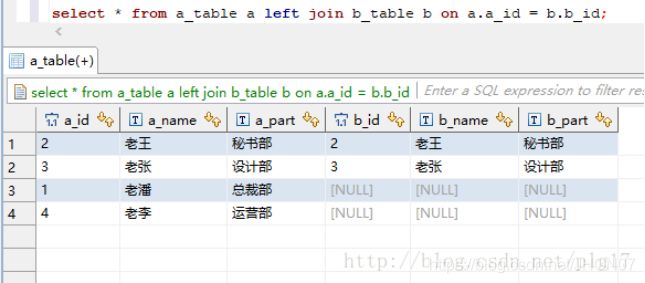
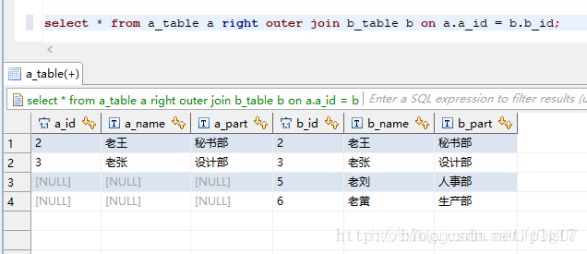
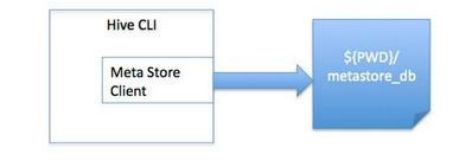
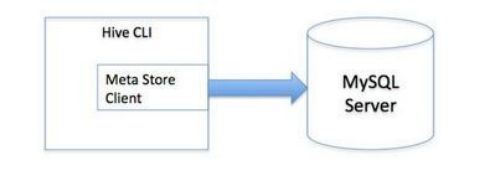
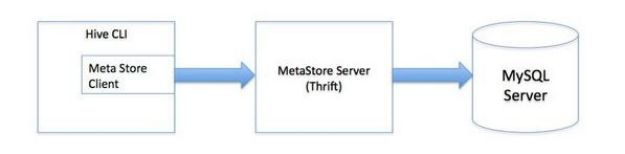
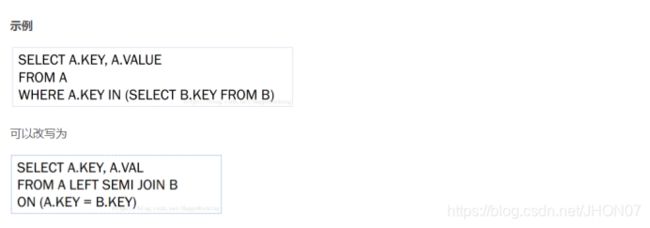
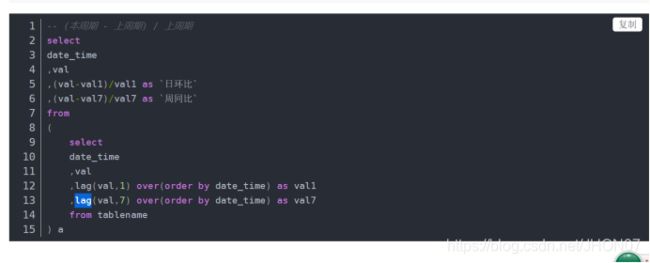
使用sql语句或者sql脚本进行交互 vim hive.sql create database if not exists mytest; use mytest; create table stu(id int,name string); hive -f /export/servers/hive.sql
3.Hive 基础
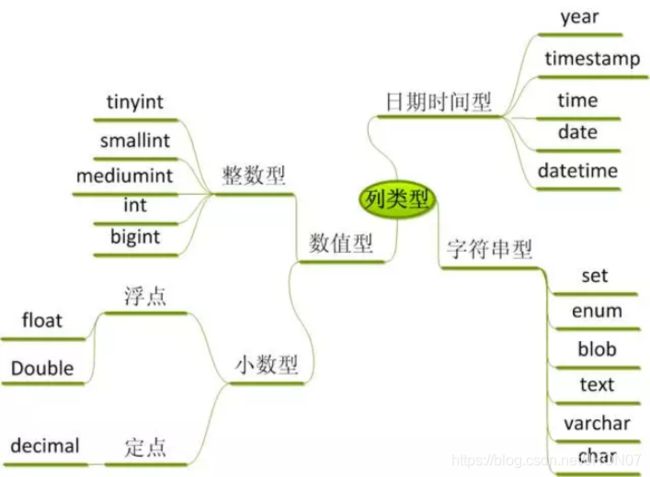
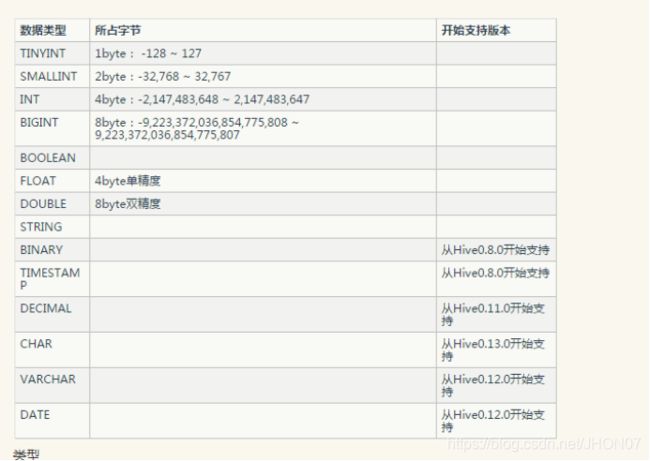
3.1.hive 支持的基本类型
3.2.基本SQL语句
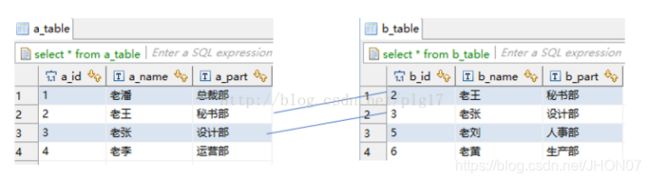
insert、delete、update、select 多表查询与代数运算 内连接 外链接 左连接 右链接 交叉链接 条件查询 Select where Select order by Select group by Select join 目前使用方式: 将sql 封装到 sh 例如:/home/hadoop/sh/bet_rr_indicator_1.0.sh
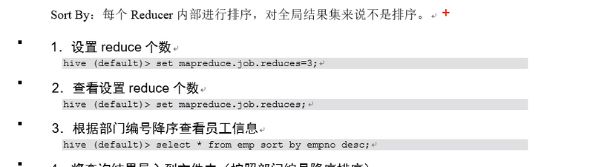
3.3.排序
全局排序: Order by 全局排序,只有一个reducer Sort by 每个reducer 内部配置 需要设置reducer 个数:
CREATE EXTERNAL TABLE test_table(id STRING, name STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,’ LOCATION ‘/data/test/test_table’; – 导入数据到表中(文件会被移动到仓库目录/data/test/test_table) LOAD DATA INPATH ‘/test_tmp_data.txt’ INTO TABLE test_table;
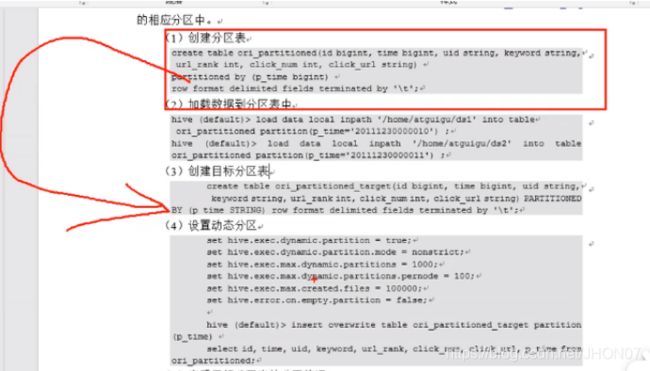
就是在系统上建立文件夹,把分类数据放在不同文件夹下面,加快查询速度 实战 CREATE TABLE logs(ts BIGINT, line string) partitioned BY (dt String, country string) ROW format delimited fields terminated BY ‘\t’;
load DATA LOCAL inpath ‘/Users/Ginger/Downloads/dirtory/doc/7/data/file1’ INTO TABLE logs PARTITION (dt = ‘2001-01-01’, country = ‘GB’);
show partitions logs;
3.11.分桶:
桶是比分区更细粒度的划分:就是说分区的基础上还还可以进行分桶;hive采用对某一列进行分桶的组织;hive采用对列取hash值,然后再和桶值进行取余的方式决定这个列放到哪个桶中; create table if not exists center( id int comment ‘’ , user_id int comment ‘’ , cts timestamp comment ‘’ , uts timestamp comment ‘’ ) comment ‘’ partitioned by (dt string) clustered by (id) sorted by(cts) into 10 buckets ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’ stored as textfile ;
Shell 开启: Update is allowed for ORC file formats only. Also you have to set few properties before performing the update or delete. Client Side set hive.support.concurrency=true; set hive.enforce.bucketing=true; set hive.exec.dynamic.partition.mode=nonstrict; set hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager; Server Side (Metastore) set hive.compactor.initiator.on=true; set hive.compactor.worker.threads=1; After setting this create the table with required properties
CREATE TABLE test_result (run_id VARCHAR(100), chnl_txt_map_key INT) clustered by (run_id) into 1 buckets ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’ STORED AS orc tblproperties (“transactional”=“true” );
hive2.2.0及之后的版本支持使用merge into 语法,使用源表数据批量更新目标表的数据。使用该功能还需做如下配置
1、参数配置 set hive.support.concurrency = true; set hive.enforce.bucketing = true; set hive.exec.dynamic.partition.mode = nonstrict; set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager; set hive.compactor.initiator.on = true; set hive.compactor.worker.threads = 1; set hive.auto.convert.join=false; set hive.merge.cardinality.check=false; – 目标表中出现重复匹配时要设置该参数才行
MERGE INTO AS T USING AS S ON <boolean` `expression1> WHEN MATCHED [AND <booleanexpression2>] THEN UPDATE SET WHEN MATCHED [AND <boolean` `expression3>] THEN DELETE WHEN NOT MATCHED [AND <booleanexpression4>] THEN INSERT VALUES
Example CREATE DATABASE merge_data; CREATE TABLE merge_data.transactions( ID int, TranValue string, last_update_user string) PARTITIONED BY (tran_date string) CLUSTERED BY (ID) into 5 buckets STORED AS ORC TBLPROPERTIES (‘transactional’=‘true’);
CREATE TABLE merge_data.merge_source( ID int, TranValue string, tran_date string) STORED AS ORC;
注意执行 merge into 前设置:set hive.auto.convert.join=false; 否则报:ERROR [main] mr.MapredLocalTask: Hive Runtime Error: Map local work failed 注意! update set 语句后面的 字段不用加表别名否则会报错 示例:SET TranValue = S.TranValue
MERGE INTO merge_data.transactions AS T USING merge_data.merge_source AS S ON T.ID = S.ID and T.tran_date = S.tran_date WHEN MATCHED AND (T.TranValue != S.TranValue AND S.TranValue IS NOT NULL) THEN UPDATE SET TranValue = S.TranValue, last_update_user = ‘merge_update’ WHEN MATCHED AND S.TranValue IS NULL THEN DELETE WHEN NOT MATCHED THEN INSERT VALUES (S.ID, S.TranValue, ‘merge_insert’, S.tran_date);
参考博客1 参考博客2
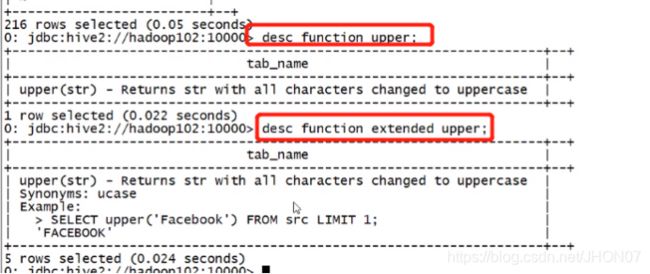
4.5 函数
desc function upper; Desc function extended upper;
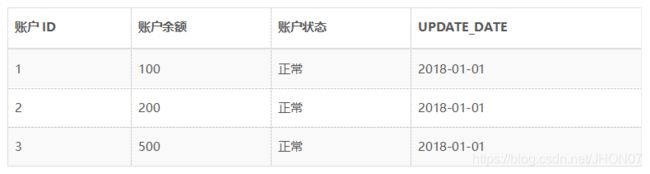
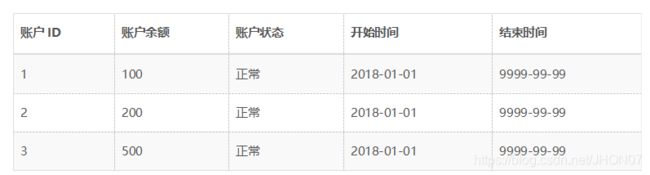
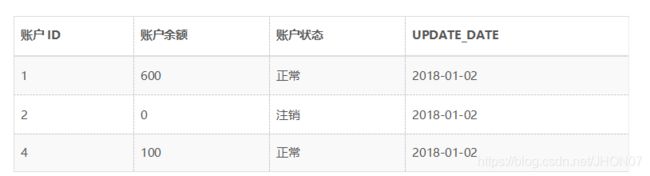
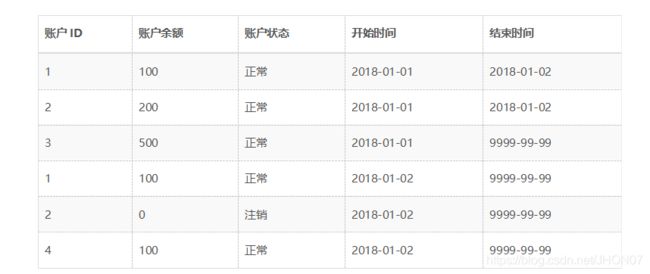
以此类推,我们可以查询到2018年1月1日之后的所有生命周期的数据,例如: o查询当前所有有效记录: SELECT * FROM ACCOUNT_HIST WHERE END_DATE = ‘9999-99-99’ o查询2018年1月1日的历史快照:SELECT * FROM ACCOUNT_HIST WHERE START_DATE <= ‘2018-01-01’ AND END_DATE >= ‘2018-01-01’
Annotation: 译为注释或注解
An annotation, in the Java computer programming language, is a form of syntactic metadata that can be added to Java source code. Classes, methods, variables, pa
定义:pageStart 起始页,pageEnd 终止页,pageSize页面容量
oracle分页:
select * from ( select mytable.*,rownum num from (实际传的SQL) where rownum<=pageEnd) where num>=pageStart
sqlServer分页:
hello.hessian.MyCar.java
package hessian.pojo;
import java.io.Serializable;
public class MyCar implements Serializable {
private static final long serialVersionUID = 473690540190845543
回顾简单的数据库权限等命令;
解锁用户和锁定用户
alter user scott account lock/unlock;
//system下查看系统中的用户
select * dba_users;
//创建用户名和密码
create user wj identified by wj;
identified by
//授予连接权和建表权
grant connect to
/*
*访问ORACLE
*/
--检索单行数据
--使用标量变量接收数据
DECLARE
v_ename emp.ename%TYPE;
v_sal emp.sal%TYPE;
BEGIN
select ename,sal into v_ename,v_sal
from emp where empno=&no;
dbms_output.pu
public class IncDecThread {
private int j=10;
/*
* 题目:用JAVA写一个多线程程序,写四个线程,其中二个对一个变量加1,另外二个对一个变量减1
* 两个问题:
* 1、线程同步--synchronized
* 2、线程之间如何共享同一个j变量--内部类
*/
public static