零代码编程:用ChatGPT批量下载Lex Fridman播客字幕文本
之前文章《零代码编程:用ChatGPT下载lexfridman的所有播客音频和文本》已经说明了Lex Fridman播客和字幕的下载方法。另外,这个网站https://karpathy.ai/lexicap/也有lexfridman播客的字幕文件。如何进行批量下载呢?

查看网页源代码,可以看到所有的字幕网页都在div标签中

相关源代码如下:
打开后的网页地址是:https://karpathy.ai/lexicap/0018-large.html
因此,在ChatGPT中输入提示词:
你是一个Python编程专家,要完成批量下载网页的任务,具体步骤如下:
打开网站https://karpathy.ai/lexicap/,解析源代码;
定位所有div标签;
在div标签中定位a标签,提取其href值,前面加上:https://karpathy.ai/lexicap/,作为网页的下载地址;
提取div标签内容,然后将其中的特殊符号“:\ / : * ? " < > |,”改成“-”,作为网页的标题名称;
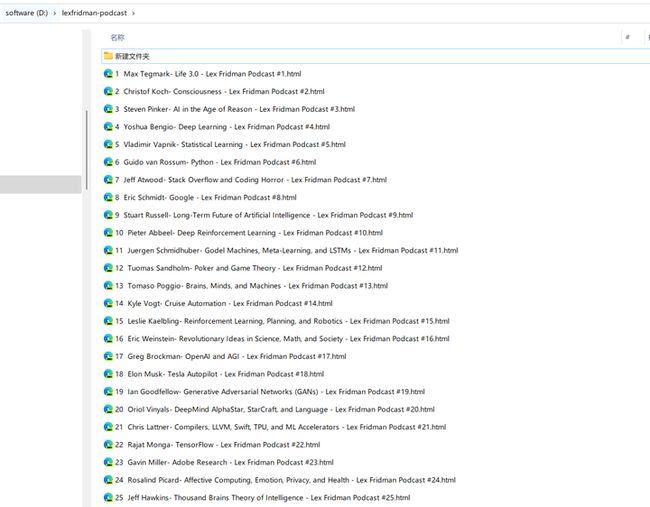
下载网页,保存到D:\lexfridman-podcast
注意:每一步都要输出相关信息
如果网页下载中出现错误,就跳过,继续下载下一个;

源代码:
import os
import requests
from bs4 import BeautifulSoup
def sanitize_filename(s):
"""为文件名清洗特殊字符"""
s = s.replace(":", "-").replace("\\", "-").replace("/", "-")
s = s.replace(":", "-").replace("*", "-").replace("?", "-")
s = s.replace("\"", "-").replace("<", "-").replace(">", "-")
return s.replace("|", "-")
# 打开网站并解析源代码
url = 'https://karpathy.ai/lexicap/'
print(f"访问网站: {url}")
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text, 'html.parser')
# 定位所有div标签
div_tags = soup.find_all('div')
print(f"找到 {len(div_tags)} 个div标签")
# 创建存储文件夹
save_dir = "D:\\lexfridman-podcast"
os.makedirs(save_dir, exist_ok=True)
# 在div标签中定位a标签,提取其href值,前面加上:https://karpathy.ai/lexicap/,作为网页的下载地址;
for div in div_tags:
a_tags = div.find_all('a')
for a in a_tags:
href = a.get('href')
if href:
download_url = 'https://karpathy.ai/lexicap/' + href
# 提取div标签内容,然后将其中的特殊符号“:\ / : * ? " < > |,”改成“-”,作为网页的标题名称;
filename = sanitize_filename(div.text) + '.html'
filename = os.path.join(save_dir, filename)
# 下载网页,保存到D:\\lexfridman-podcast
print(f"下载 {download_url} 到 {filename}")
try:
res = requests.get(download_url)
res.raise_for_status()
with open(filename, 'w', encoding='utf-8') as f:
f.write(res.text)
except Exception as e:
# 如果网页下载中出现错误,就跳过,继续下载下一个;
print(f"下载 {download_url} 时出现错误: {e}")
Continue
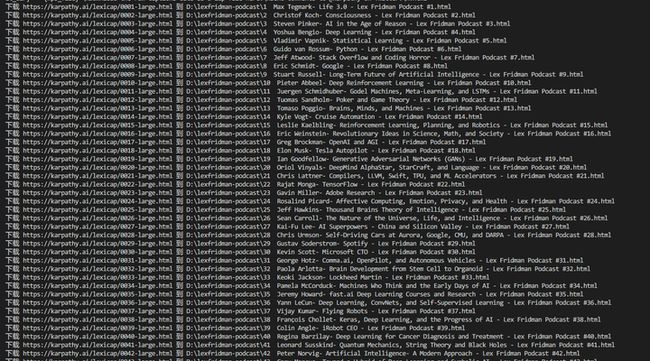
所有播客字幕文件下载完成: