2023年金融科技建模大赛(初赛)开箱点评-基于四川新网银行数据集
各位同学大家好,我是Toby老师。2023年金融科技建模大赛(初赛)从今年10月14日开始,11月11日结束。

比赛背景
发展数字经济是“十四五”时期的重大战略规划。2023年,中共中央、国务院印发了《数字中国建设整体布局规划》,提出建设数字中国是数字时代推进中国式现代化的重要引擎,是构筑国家竞争新优势的有力支撑。加快数字中国建设,对全面建设社会主义现代化国家、全面推进中华民族伟大复兴具有重要意义和深远影响。其中,做强做优做大数字经济,推动数字技术和实体经济深度融合,在农业、工业、金融、教育、医疗、交通、能源等重点领域,加快数字技术创新应用。金融科技聚焦数字经济时代之下的金融领域,其在大数据、人工智能、云计算等颠覆性科技在金融行业的创新应用,正在深刻影响金融业务的发展和转型。金融科技正成为金融发展不可或缺的核心要素。
在此背景下,由四川省教育厅主办,西南财经大学承办“2023年全国大学生金融科技建模大赛暨第四届四川省大学生金融科技建模大赛”将于10月14日开赛。本届大赛得到四川新网银行股份有限公司和东方财富信息股份有限公司的大力支持,将金融科技建模大赛定位成全国一流的新财经学科竞赛。现将有关事项通知如下:
一、组织架构
主办单位:四川省教育厅
承办单位:西南财经大学
协办单位:西南财经大学金融学院、西南财经大学教务处、西南财经大学经管实验教学中心、西南财经大学金融建模协会
支持单位:四川新网银行股份有限公司、东方财富信息股份有限公司
二、比赛目的
2023年全国大学生金融科技建模大赛暨第四届四川省大学生金融科技建模大赛面向全国高校全日制专科生、本科生及研究生,提出金融行业的智能决策问题,要求参赛选手利用脱敏数据,自发探索宏观数据,完成建模过程、呈现解决方案。旨在通过赛事帮助参赛者触摸金融科技行业前沿课题,学以致用,培养解决实际问题的综合能力和知识应用能力。
三、赛项说明
1.参赛对象:本次大赛面向全国高校的全日制专科生、本科生和研究生
2.参赛语言:Python
3.赛题设置:本次比赛的主题是“客户复购行为预测”。银行不仅关注新客户获客,也关注老客户的复购行为,希望增加客户黏性。客户在金融产品和服务上的重复购买行为越多,客户黏性越大。银行可以通过识别这些黏性客户,更好地分析他们的需求,并向他们推送新产品,进行客户关系管理。本次比赛的目标是对客户复购频率的三分类预测。比赛选手需要根据客户信息(包括基础客户画像信息、产品购买行为信息以及第三方客户画像补充信息)预测客户复购行为标签:低频(0)、中频(1)、高频(2),并根据客户平均价值(低频1、中频3、高频5),在独立样本上检验预测准确性(加权准确性)。
4.参赛形式:参赛形式为个人赛,每人需填报一名指导老师,指导老师需为本校专兼职教师。
四、竞赛流程
(一)竞赛报名
1.报名时间:2023年9月29日-2023年11月11日
(二)竞赛时间
报名阶段:(9月29日-11月11日)
本次大赛使用为该赛区专门搭建的基于Python程序语言的在线竞赛平台Credit Lab线上报名参加,按要求填写、上传相关信息并通过审核后完成报名。
初赛阶段:(10月14日-11月11日)
初赛时间为10月14日至11月11日,选手在报名审核通过后直接在比赛平台提供的云服务器进行模型构建和结果提交,比赛平台会自动对代码进行查重并且生成查重报告。除比赛提供的脱敏数据外,选手可使用choice数据库探索宏观数据优化模型。
复赛阶段:(11月11日-11月22日)
复赛为11月11日至11月22日,初赛阶段选手综合排名(分数计算方式章程中附件2中初赛评分标准)前50%的选手有资格进入复赛。复赛阶段组委会将更换数据集,复赛结束后将进行资格和结果复审,并按奖项设置颁发奖项。综合成绩靠前的选手将被邀请参加决赛。
决赛阶段:(11月30日)
决赛形式为现场或线上答辩,参赛选手对自己的建模思路进行展示,评委会会对知识和能力进行提问,组委会依据决赛最终成绩决出特别奖项。时间暂定为11月30日。
比赛评分规则

参赛数据说明

开箱点评:
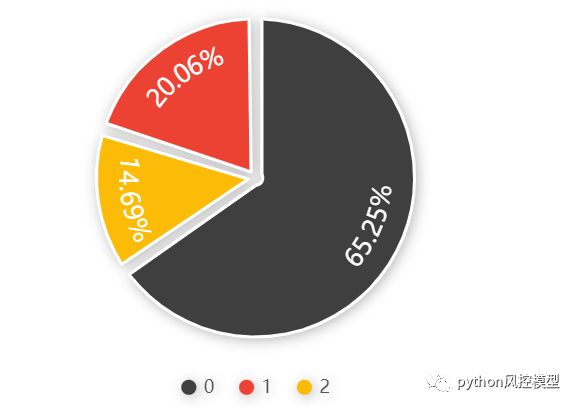
这次模型竞赛目标变量有三个类别,比之前二分类模型要难。分类统计发现属于非平衡数据,0低频,1中频,2高频的人群占比分别为65%,20%,14.6%。看来消费频率高的人群占比并不高,只有14.6%。营销只要抓住了这14.6%高价值人群,即可实现利润最大化,行内人俗称智慧营销。智慧营销具体介绍可以参考之前文章《RMF模型-实现银行信用卡用户分级_电商VIP客户挖掘(精准营销/智慧营销)》,《谁主沉浮?银行,消金,互联网公司的精准营销_智慧营销完全解读(收藏)》。
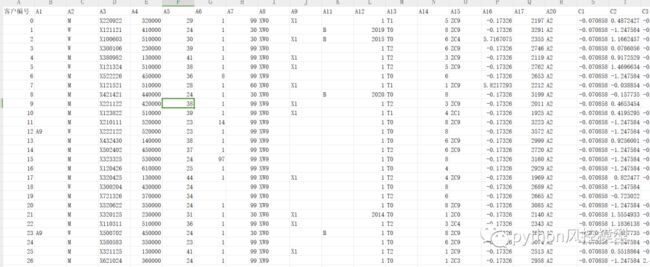
这是比赛数据的表格。

这次模型竞赛的建模有3个表格需要整合,分别是X1_train,X2_train,X3_train。X1_train和X3_train是基础客户画像信息和第三方客户画像补充信息,共69个变量,用客户编号即可把这两个表数据链接在一起。X2_train是客户上一年产品购买行为信息,属于行为数据,隐藏了大量重要信息,但没法直接通过客户编号与其它2个表格整合。但我们可以写脚本数据预处理,从X2_train表里提取有价值衍生变量,组合到其它两个表里。
我把数据整理一下,整合为data.xls数据集,给大家看看。
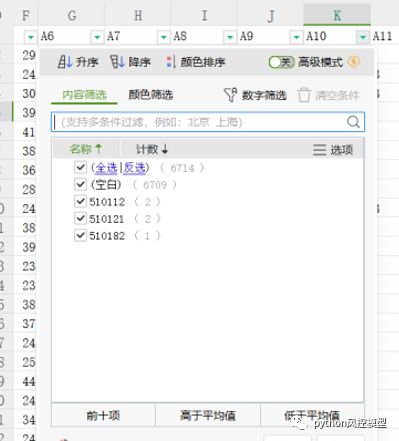
这次竞赛有大量数据预处理工作,包括很多变量没有价值,需要删除。例如下图变量绝大多数值为空缺值,或全部为空缺值,这些变量对模型没有意义,应该删除。
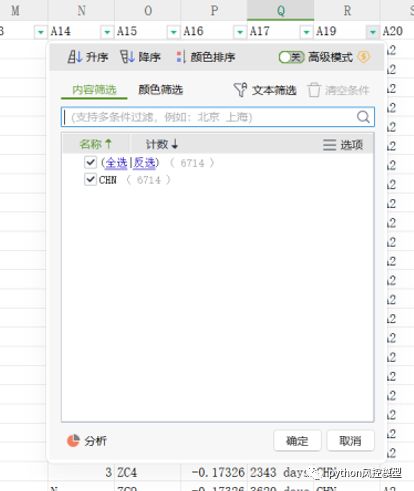
数据存在大量字符串类型数据的变量,需要转换为数值型后才能建模。
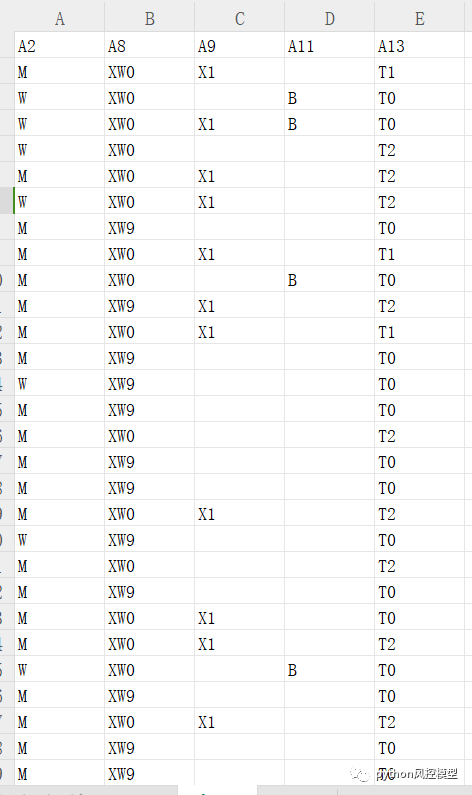
我转换后把数据保存为encode_data.xls,大家看转换后就没有字符串数据类型的值了。
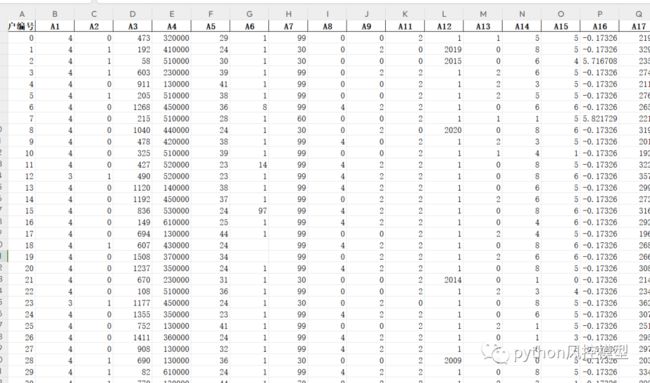
通过变量价值评估,我发现很多变量价值低。我把价值含量低变量删除,只五十五个变量。
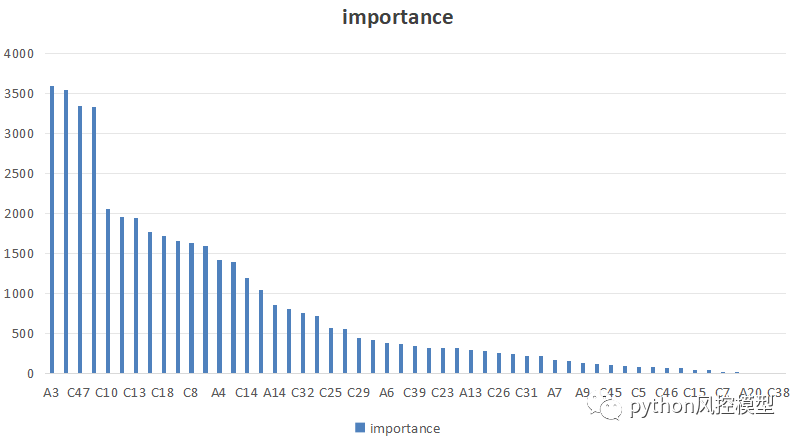
通过相关性分析,发现大量高相关性变量。我们还能删除大量变量,预估20多个变量入模即可。
这次竞赛是三分类器模型,我建模后得到target=0的性能如下
precision :0.90327381
sensitivity:0.70417633
f1_score:0.79139505
具体实现多分类器模型脚本在《python风控建模实战lendingClub》课程的《机器学习多分类模型解决方案-multiClass》章节可以找到,有现成脚本下载。
我把target的0和1合并后,建立筛选VIP客户的信用评分卡模型,下图见AUC: 0.79。模型质量还不错。

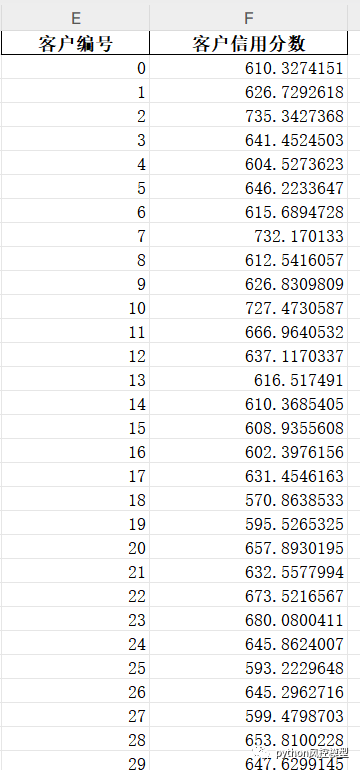
通过设置评分卡,我们可以生成客户信用分数,如果信用分数越高,客户购物意愿越强,反之亦然。我们看客户编号为2的信用分数较高,为735分,购买意愿强,可以发送给营销部门重点推广。我们观察到客户编号为18的客户信用分数为570分,分数较低,购买意愿不强,不需要在这个客户上浪费营销资源。
构建python信用评分卡模型具体代码和理论可以收藏课程了解教程《python信用评分卡建模(附代码)》。
模型竞赛总结-僵尸数据
此模型竞赛整体设计较好,有一定难度,特别是在数据预处理上需要花很多功夫,不仅要关联3张表格,还要筛选有价值变量,处理各种数据类型的值。
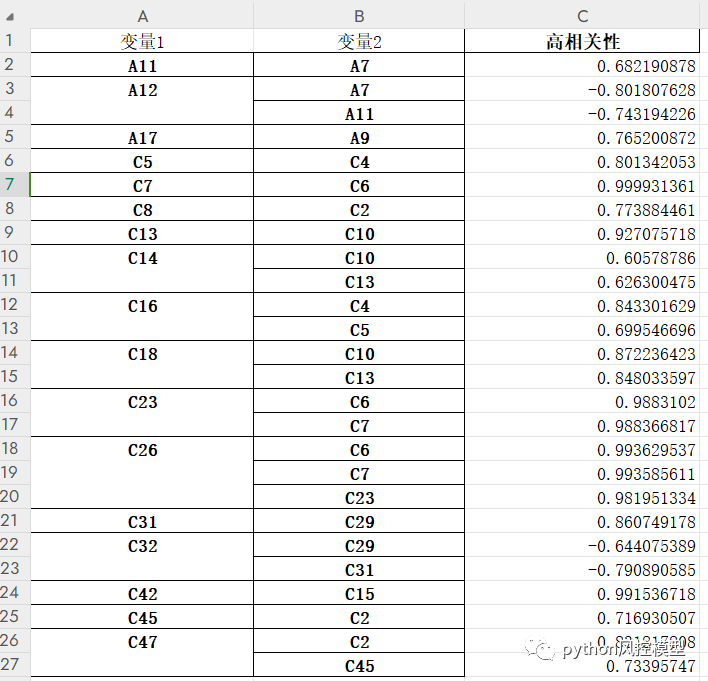
模型竞赛不足的是变量没有中文释义,而且很多变量是脱敏后数据,缺乏实际意义。我们对这样数据称为僵尸数据,这样模型竞赛称为僵尸模型竞赛。参加僵尸模型竞赛不能得到有价值业务意义,只能为了玩数字游戏而玩数字游戏。比如我们在变量重要性分析时候,发现A3是一个非常重要变量,但不知道A3到底是什么,这样结论没法反馈到业务方。
变量没有中文释义,容易产生数据泄露问题。X2_train里存储着行为变量,我们可以从中挖掘大量有价值衍生变量。但这些行为变量可能发生数据泄露情况,需要业务知识来判断。我们不知道变量中文释义,就没法用业务知识筛选数据泄露变量,进而为模型存在隐患埋下伏笔。我之前写过数据泄露的相关文章可参考《数据泄露-揭秘机器学习模型如何作弊》。
我建议模型竞赛举报方以后用真实数据为学生建模,这样学生既能提高建模能力,又能把得到重要结论反馈给业务方,还能加深对业务理解能力。
作为写论文学生,这样模型竞赛很那用于写论文。没有中文释义变量怎么做用户画像?
因为僵尸数据,我不想在这项目花费太多时间,只从X2_train里衍生了一个B3变量入模,这个变量看着像客户评级,根据经验,应该能提升模型。我相信很多参赛者的模型性能比我好,他们从X2_train里提取了更多变量。

唯一能够解释主办方用脱敏数据理由是担心泄露公司内部商业信息,Toby老师觉得主办方大可不必这样担忧。美国lendingclub,捷信举报的模型竞赛能够提供真实数据,我们只要隐藏客户身份证,电话等敏感信息即可,客户编号0,1,2又不能说明客户真实身份。即使我们通过数据挖掘发现一些问题,也可反馈给业务方,做出重大贡献,就像hacker找出bug,这是有利事情。隐瞒糟糕业务不一定是好事,就像恒大集团,不断隐瞒债务风险,最终暴雷。如果恒大集团早点发现和处理公司风险,就不会沦落成过街老鼠的形象了。
总之,我呼吁大家去参加基于真实数据的模型竞赛,可以获取最大收益。我期待明年主办方能提供更好数据为大家参赛。
欢迎学习更多风控建模相关知识《python金融风控评分卡模型和数据分析微专业课》,我们提供专业评分卡模型等知识,实现自动化信用评分功能。
原创作者Toby,文章来源公众号:python风控模型,2023年金融科技建模大赛(初赛)开箱点评